
PREDICCIÓN DE INSOLVENCIA Y FRACASO
172b PREDICCIÓN DE INSOLVENCIA Y FRACASO FINANCIERO: MEDIO SIGLO DESPUÉS DE BEAVER (1966). AVANCES Y NUEVOS RESULTADOS Manuel Rodríguez López Carlos Piñeiro Sánchez Pablo de Llano Monelos Grupo de Investigación Finanzas y Sistemas de Información para la Gestión (FISYG) www.udc.es/grupos/fysig Departamento de Economía Financiera y Contabilidad Facultad de Economía y Empresa Finance and Management Information Systems Research Group (FYSIG) Department of financial economy and accounting Faculty of Economics and Business (University of A Coruña) Área temática: b) valoración y finanzas Palabras clave: Pronóstico del fallo financiero, Métodos multivariable paramétricos, Inteligencia Artificial, Soporte de Máquina Virtual. JEL CODE: G33, C19, M4. 1 PREDICCIÓN DE INSOLVENCIA Y FRACASO FINANCIERO: MEDIO SIGLO DESPUÉS DE BEAVER (1966). AVANCES Y NUEVOS RESULTADOS Abstract A lo largo de los últimos sesenta años, se han desarrollado distintos modelos de análisis y determinación de la solvencia empresarial. Herramienta cuyo fin es prever situaciones de fracaso financiero, antes de que este se produzca. El fin último es la minoración de las cargas inherentes al fracaso, sus costes directos e indirectos. Subyace, obviar la desaparición de la empresa, ya que en principio esta nace con ánimo de perdurar, incluso antes del principio torticero de maximización del beneficio. Sin embargo, a lo largo de los años el concepto ha ido modificándose, ha evolucionado. Los modelos se han desarrollados para dar cobertura a las distintas definiciones de solvencia. Presentamos una revisión de la literatura conceptual y práctica de la predicción de la insolvencia, con sus luces y sombras. 1 INTRODUCCIÓN El problema del fracaso empresarial es asunto actual, no ya por la recesión que sufrimos, sino por ser un tema especial de permanente interés para un amplio conjunto de agentes económicos y sociales. El diseño de modelos capaces de detectar precozmente desequilibrios, que pueden desembocar en fracaso, se configura como una exigencia crucial para las Finanzas. Estas herramientas proporcionarían no solo indicios cruciales para los intereses de acreedores e inversores, sino también evidencias útiles para mejorar la calidad de las decisiones y pautas generales para aumentar las oportunidades de supervivencia de empresas que sufren tensiones o anomalías financieras. Ya en 1907, con el pánico generado en la bolsa de Nueva York, empezaron a cuestionarse si habría manera previsional de tales eventos. La posterior quiebra del 29 (hasta el 32) atrajo mayor interés sobre la descripción y detección anticipada de los procesos de fracaso empresarial. La investigación en el área financiera entronca con el análisis financiero tradicional, de ahí el planteamiento metodológico convencional consistente en la derivación de algoritmos de clasificación o estimadores de probabilidad de fallo, a partir de información financiera. Este enfoque quedó definitivamente legitimado tras las evidencias aportadas por Beaver (1966), en relación al perfil estadístico de las empresas sanas y fracasadas. Las técnicas empleadas para esta finalidad son extremadamente variadas: el clásico análisis discriminante, la regresión logística condicional (Logit), y una multitud de metodologías heurísticas y de gestión del conocimiento, como árboles bayesianos, herramientas de 2 inteligencia artificial simbólica (sistemas expertos) y subsimbólica (redes neuronales y máquinas de soporte vectorial), pasando por la teoría de conjuntos difusos y el particionamiento recursivo. Al tiempo que el enfoque metodológico se hace más rico y heterogéneo, se observa también una creciente disonancia en la especificación de las variables dependiente e independiente. Existe un amplio acuerdo en relación a la capacidad predictiva de las ratios financieras, aunque no unanimidad acerca de qué ratios en concreto canalizan la información relevante para el diagnóstico y el pronóstico. Algunos trabajos recientes han examinado el empleo de variables macroeconómicas (Sun y Li, 2009; Tsai et al., 2009), indicios de la calidad de gestión (Lajili y Zéghal, 2011) o evidencias derivadas del proceso de auditoría (Piñeiro et al., 2012 y 2013a). Se observan sin embargo notables disparidades en la naturaleza de la metodología de trabajo y las variables explicativas resultantes del calibrado y optimización de los modelos. En particular, los modelos parecen estar anclados a su marco de referencia, en el sentido de que la calidad de los pronósticos se deteriora rápidamente cuando son empleados en horizontes temporales y/o marcos geográficos diferentes (Arquero et al., 2009). 2 LA METODOLOGÍA DE PRONÓSTICO DEL FRACASO Pese su indudable interés para la teoría y praxis financieras, el pronóstico del fracaso financiero no ocupó lugar reseñable en investigación hasta los setenta. Las dificultades financieras se interpretaban como cuestión accesoria a la solvencia, dentro del contexto general del análisis financiero: no se había planteado el análisis de causas ni factores comunes de los procesos de fallo porque el fracaso se entendía como un evento súbito causado directa y principalmente por las particularidades de cada empresa, no generalizables a otras organizaciones (Greenball, 1971; Gordon, 1971). El fracaso financiero se analizaba desde un enfoque esencialmente contable, identificando las nociones de fracaso financiero e insolvencia. Este planteamiento experimentó un cambio radical en los últimos años sesenta debido a la concurrencia de dos factores: la aparición de evidencias empíricas que demostraban que las ratios financieras de las empresas fallidas tenían un perfil estadístico claramente diferenciado (Beaver, 1966; Dambolena y Khoury, 1980). De manera casi repentina, la literatura supera el enfoque convencional de la solvencia y propone no solo esbozar conceptualmente los procesos de fracaso, sino relacionarlos con decisiones financieras clave como la estructura financiera (Modigliani y Miller, 1958 y 1963) y con el comportamiento del valor de empresa (Baxter, 1967; Altman, 1969; Gordon, 1971, Scott, 1977). 3 Poco después, plantea el interés de formular todas estas relaciones de manera analítica, dentro de modelos matemáticos útiles para describir relaciones clave y evaluar lo que se denominó riesgo de ruina (Altman, 1968; Vinso, 1979; Sharma y Mahajan, 1980). En este nuevo enfoque el fracaso no es ya un evento súbito e imprevisto sino la consecuencia final de un cúmulo de desequilibrios financieros, lo que legitima el desarrollo de modelos de pronóstico y el estudio de la estructura temporal (Hing-Ling, 1987) de estas disfunciones. Actualmente la investigación trata de establecer un marco comprensivo relacionando las evidencias con otros elementos adyacentes de la teoría financiera: hipótesis de eficiencia del mercado, teoría de la decisión, estructura de capital, teoría de agencia, y evidentemente, contabilidad y auditoría (Kahl, 2002). 2.1 LA VARIABLE DEPENDIENTE Probablemente la primera y más trascendental cuestión planteada por la literatura es qué debemos entender por fracaso. Adoptando una perspectiva pragmática, una empresa es financieramente sana cuando los recursos generados son suficientes, como mínimo, para mantener la capacidad de pago, lo que en la práctica se materializa en la ausencia de impagos y/o eventos concursales. De manera más formalizada, la empresa fracasa cuando no logra para sus accionistas un aumento satisfactorio de riqueza que les compense por el riesgo asumido y por la pérdida de la disponibilidad del capital invertido. Esta interpretación es compatible con el enfoque estratégico, que concibe el fracaso como la consecuencia de una incapacidad crónica para mantener la competitividad – y por tanto para generar un volumen de recursos ajustado al riesgo -. Sin embargo, en la literatura financiera dominan las definiciones de naturaleza jurídica y contable: una empresa fracasa cuando es incapaz de perpetuarse como unidad económica independiente, lo que se traduce en la existencia de un proceso extintivo o, en el mejor de los casos, de disfunciones financieras graves que podemos sintetizar en la noción de concurso de acreedores. Pero incluso esta definición jurídica es susceptible de matizaciones: el fracaso puede entenderse referido a una extinción propiamente dicha, a impagos puntuales, a procesos concursales, incluso a cambios en la propiedad que se correspondan con una carencia crónica de recursos o en general con la incapacidad para sobrevivir como unidad económica aislada. Resulta evidente que estas matizaciones elevan sustancialmente la complejidad del problema. La Tabla 1 ofrece un resumen cronológico de esta evolución, basada en algunas aportaciones clave. Año Autores Sistema 1930s financiero 1966 Beaver 4 Definen el fracaso financiero, como; Primeros esfuerzos en la prevención del fracaso, quiebra, impago, partiendo de ratios exclusivamente como indicadores de riesgo. Primer modelo predictivo, y la primera concepción moderna de fracaso, como la dificultad para atender deudas. Centra su estudio en empresas cuya situación de fracaso, coincide con la situación legal de quiebra. La situación de quiebra, insolvencia. Nuevamente en la situación legal de quiebra. Puntualiza la quiebra como insolvencia técnica, falta de liquidez. Liquidación voluntaria, orden legal de liquidación, o intervención estatal. Quiebra legal. Se posiciona en su definición legal, o la situación de suspensión de pagos. La quiebra, como incapacidad para hacer frente a obligaciones con terceros. Empresas que legalmente están en quiebra. Definen el fracaso dentro del sistema financiero, en relación a la y intervención de entidades bancarias por parte de autoridades monetarias. Fracaso como la situación de liquidación voluntaria o judicial. 1968 Altman 1972 1980 1981 Deakin Olshon Altman 1982 Taffler 1984 Zmijewski 1985 Zavgren 1988 Altman 1986 Lo Laffarga, Martín Vasques Goudie García, Riesgo financiero bancario de las empresas que incumplen con el Arqués y nominal o intereses del crédito concedido. Calvo-Flores El fracaso desde el punto de vista de la información de auditoría; Lizarraga empresa solicitante de apertura de expediente concursal de suspensión de pagos. Puntualiza el fracaso como fragilidad, relacionándolo con la empresa Martínez que llega a un acuerdo de refinanciación de su pasivo, o de liquidación. Platt y Platt Relacionan escuetamente el fracaso financiero. Calvo y Modelizan sobre el fracaso, en relación a un riesgo financiero alto. Rodríguez Anzola y El fracaso es una situación definitiva, la desaparición. Puentes Graveline y El fracaso y el impago de la deuda, o con el cumplimiento de las Kokalari condiciones legales previstas para una quiebra. Rubio Empresa en quiebra, con patrimonio negativo, o en quiebra técnica. Modeliza el fracaso, como la situación patrimonial reflejada por una Davydenko valoración reducida en sus activos, o caracterizada por la escasez de flujos de caja. de Llano, La situación de insolvencia, en quiebra legal, en relación a la Piñeiro y existencia (o no) de incidencias previas por impago de obligaciones. Rodríguez El fracaso entendido como la presencia de incertidumbres a la Piñeiro, de continuidad y/o salvedades graves en los informes de auditoría, que Llano y sugieran un riesgo inminente para la supervivencia de la empresa Rodríguez (quiebra), TABLA 1. EVOLUCIÓN DEL CONCEPTO DEL FRACASO FINANCIERO. 1987 1987 1995 1997 2003 2004 2006 2007 2008 2008 2010 2011 2012 2013 2.2 MÉTODOS MATEMÁTICOS, ESTADÍSTICOS Y HEURÍSTICOS Los cambios en la interpretación del fracaso tienen una clara correspondencia en la evolución de las metodologías empleadas en los estudios empíricos. La fundamentación 5 general radica en el trabajo de Beaver (1966), que comunica la existencia de diferencias significativas en los perfiles estadísticos de las ratios de empresas sanas y fracasadas; existen sin embargo diferentes formas de aprehender y formalizar estas diferencias. Altman (1968) diseñó un estudio pionero proponiendo analizar la problemática de solvencia desde un enfoque multivariable, la influencia simultánea de dos o más covariables, mediante un enfoque metodológico concreto, el Análisis Discriminante Múltiple (MDA), sobre una batería de ratios financieras convencionales. Su gran contribución, es la prueba de que el análisis del riesgo de fallo podía abordarse rigurosamente mediante métodos multivariables paramétricos: logrando tasas de acierto del 95% un año antes del fallo, empleando la información contenida en tan solo cinco ratios. Respecto de la teoría financiera, el modelo de Altman arrojó luz sobre la dinámica que deviene en un riesgo financiero incrementado: disfunciones en la actividad reductoras de rentabilidad y recursos generados, que derivan en un déficit de autofinanciación y dificultades para mantener el ciclo de negocios, que las empresas contrarrestan incrementando el endeudamiento. El enfoque discriminante ha sido empleado con profusión en la literatura, y todavía hoy mantiene una notable entidad (Charitou et al., 2004). La principal alternativa a los modelos discriminantes es la regresión logística condicional (Logit). Martin (1977) propuso utilizar estos modelos para evaluar el riesgo de quiebra en entidades financieras, logrando mayor notoriedad tras la difusión del trabajo de Ohlson (1980). Los Logit aportan algunas ventajas comparativas frente a sus competidores discriminantes: independencia de cualquier presunción a priori de la distribución de probabilidad de las variables, siendo una propiedad extraordinariamente interesante dado que las ratios financieras no se adaptan en absoluto al modelo normal supuesto por MDA1; y sus resultados poseen un contenido informacional más rico y potencialmente útil que una simple clasificación: estimación de verosimilitud de fallo, y cuantificación del riesgo relativo (odds-ratio) para cada variable predictora. Los Logit logran niveles equilibrados de errores de tipo I y II; a priori esta es una ventaja de entidad frente a los MDA, los cuales según la literatura, tienden a cometer tasas anormalmente altas de error tipo I: clasificar como fallida cierta proporción de sanas (Altman, 1968; Deakin, 1972; Altman, 1977; Kim, 2011). En sí mismo es un problema práctico de entidad, porque los falsos positivos merman la reputación de la empresa ocasionando un fallo autocumplido; creando una incertidumbre acerca de la 1 Se han descrito distintos procedimientos de transformación que potencialmente podrían dotar a las series de ratios de algunas de las características propias de la distribución normal (véase por ejemplo Kane et al., 1998); sin embargo resulta dudoso que estos cambios no ocasionen también mermas, sesgos, o alteraciones en la información aportada originalmente por las series de ratios. 6 capacidad real de los MDA para proporcionar evidencias fiables de riesgo2: cierta proporción de empresas fallidas puenden ser clasificadas correctamente, no porque el modelo posea buena capacidad de diagnóstico, sino porque padece una tendencia natural a asignarles esa clasificación. Examinando los pronósticos MDA, se pone de manifiesto que los grupos de variables predictivas no son estables en el tiempo (Joy y Tollefson, 1975). Altman (1968) y Altman et al. (1977) muestran predictoras radicalmente diferentes (solo una variable común) logrando ambos modelos destacables tasas de acierto aplicándolos en su propio marco temporal de referencia. La explicación dominante es que los factores de exposición cambian en el transcurso del tiempo. El riesgo (financiero) en general, y el fracaso en particular, no son realidades puramente específicas: no dependen exclusivamente de características individuales, sino de factores sistemáticos, como la coyuntura económica o la situación de los mercados (Tsai et al., 2009). Aunque estos factores se asumen estables de cara a la estimación, sería más correcto afirmar que cambian con lentitud3, y esto explicaría por qué los modelos parecen perder fiabilidad cuando se aplican en períodos temporales diferentes. El tratamiento de esta inestabilidad parece requerir la incorporación de variables expresivas del contexto macroeconómico, aumentando la complejidad del modelo (Rose et al, 1982; Liu, 2004; Bottazzi et al., 2011). Altman et al. (1977) sugieren la incorporación de variables adicionales a las ratios, algunas de ellas predictivas (como el riesgo expresión del grado de inestabilidad del beneficio) y otras, como la dimensión, destinadas a controlar posibles efectos de confusión. Sea como fuere, la estrategia dominante es la estimación recurrente de los modelos MDA, denominado recalibrado. La alternativa a los modelos paramétricos es un conjunto de técnicas de naturaleza heurística, vinculadas al aprendizaje de máquina y a la inteligencia artificial (IA). Su principal ventaja es la independencia de cualquier asunción a priori de la distribución de probabilidad de las variables de trabajo, y su robustez a la presencia de valores atípicos (outliers); además, parecen tener mayor capacidad predictiva que sus equivalentes paramétricos (Tam y Kiang, 1992; Altman et al., 1994). Estas técnicas ofrecen una oportunidad para incluir indicadores que, como la calidad de la gestión (Rose et al., 1982; Peel et al., 1986; Keasey y Watson, 1987; Barr et al., 1993), los pronósticos de analistas externos (Parnes, 2010) o el 2 Esta crítica parece ser extensible a otros modelos más sofisticados, como los de azares en tiempo discreto (Shumway, 2001). Por ejemplo, Tsai et al. (2009) plantean la posibilidad de realizar una selección ad hoc de variables (financieras, macroeconómicas, de auditoría, etc.) atendiendo al objetivo principal del decisor (lograr una elevada fiabilidad media, o minimizar los errores de tipo I). 3 Joy y Tollefson (1975) exponen con gran claridad las consecuencias formales de esta presunción: “bajo la hipótesis de estacionariedad [del entorno] a lo largo del tiempo, la discriminación ex post es equivalente al pronóstico. Pero el investigador debe asegurarse de que esa estacionariedad existe”. De no ser así, las tasas de error observadas y los subconjuntos de variables explicativas no serían generalizables a períodos distintos del de estimación. Por supuesto esta crítica es aplicable a todos los métodos econométricos, y no exclusivamente a MDA. 7 contenido de informes de auditoría (Piñeiro et al., 2012 y 2013a), pueden no ser estrictamente cuantitativos. Probablemente el procedimiento no paramétrico convencional es sintetizar la información relevante de las causas y desarrollo de los procesos de fracaso en una red bayesiana, derivando uno/más clasificadores que valoren la salud financiera de la empresa. Las redes bayesianas son poderosas herramientas para el tratamiento de problemas deficientemente especificados, donde existen variables latentes o valores omitidos; realizan inducciones rápidas y comprensibles incluso con clasificadores ingenuos (Kennedy, 1975). No obstante, las redes bayesianas tienen un coste computacional elevado, comparado con otras herramientas de aprendizaje interactivo. En este campo, la estadística bayesiana se ha empleado preferentemente para evaluar el riesgo de fallo de entidades financieras y los sesgos en el proceso de formación de opinión por parte de auditores y reguladores (Sarkar y Sriram, 2001; Huang et al., 2008). Competidor directo de las redes bayesianas son los árboles de clasificación, estructuras de información que relacionan ciertos atributos/valores de entrada con un conjunto de respuestas/salidas a través de un entramado de relaciones de naturaleza secuencial. Su construcción implica un proceso de aprendizaje basado en una estrategia de particionamiento recursivo, identificando un conjunto jerarquizado de reglas que permita fragmentar la muestra en regiones internamente homogéneas y bien delimitadas del resto de grupos; creando subdivisiones precisas que aseguren que el riesgo total del árbol – el coste esperado de los errores de clasificación – es mínimo, mediante podas oportunas para lograr una solución satisfactoria entre la complejidad de la herramienta, calidad del aprendizaje y fiabilidad del pronóstico (Friedman, 1977). Característica clave de esta técnica es su carácter jerárquico (Breiman et al., 1984), que significa que las variables explicativas están organizadas en capas o niveles: la influencia de una variable depende de los valores que tomen las que le preceden en esta estructura. No es preciso realizar asunciones a priori acerca de la distribución de probabilidad de las variables ni sobre la forma funcional de la relación que vincula a la variable independiente con las explicativas. Los árboles se construyen a partir de una serie de secuencias tipo condicional: “si… entonces”; desarrollando particiones recursivas, los algoritmos de clasificación manejan simultáneamente varias regresiones simples cuyas variables explicativas pueden ser diferentes en función de los valores previos de otros regresores. Se trata de una técnica matemática bien establecida y que cuenta con algoritmos de trabajo demostradamente eficaces; ID3 y C4.5 (Quinlan, 1986 y 1993); pero las aplicaciones financieras de inducción de árboles son relativamente recientes: Frydman et al. (1985) diseñaron un modelo para clasificar empresas, basado en el planteamiento básico de Friedman (1977), y Marais et al. 8 (1984) lo incluyen como núcleo de una técnica para la evaluación del riesgo en la concesión de préstamos bancarios. Daubie et al. (2002) concluyen que, al menos en este problema en concreto, los árboles inducidos por particionamiento recursivo son más eficaces que las técnicas basadas en conjuntos imprecisos (Slowinski y Zopounidis, 1995; McKee y Lensberg, 2002). En el campo del pronóstico del fracaso empresarial, las herramientas heurísticas de mayor difusión son las redes de neuronas artificiales (RNA) y las máquinas de soporte vectorial (SVM); los sistemas expertos quedaron relegados casi desde el primer momento, habida cuenta de la complejidad inherente en el desarrollo y mantenimiento de sistemas explícitos de reglas (Messier y Hansen, 1988). Las primeras aplicaciones, marcadamente tentativas y experimentales (por ejemplo, Hansen y Messier, 1991) dieron paso a una intensa investigación que en general sugiere que las RNA poseen ventajas comparativas frente a los métodos paramétricos convencionales, en términos de capacidad predictiva (Bell et al.; 1990; Tam y Kiang, 1992; Serrano y Martín, 1993; Wilson y Sharda, 1994; Altman et al., 1994; Koh y Tan, 1999; Yang et al., 1999; Brockett et al., 2006; Tsai, 2008; Boyacioglu et al., 2008; Kim, 2011; Xiaosi et al., 2011); se critica sin embargo que su funcionamiento a modo de caja negra no es el más adecuado para describir las disfunciones financieras ni para proporcionar guías que coadyuven a evitar el fallo. Por otra parte se han hallado algunos problemas de aplicación, tanto disfunciones ocasionadas por el sobreaprendizaje como situaciones en las que el volumen de ratios incluidos en la capa de entrada induce un crecimiento injustificado de la red; estas anomalías requieren la aplicación de algoritmos específicos para controlar el proceso de aprendizaje, y eventualmente procedimientos de poda para reducir la dimensión de la red (Becerra et al., 2002; Rodríguez, 2005) Las máquinas de soporte vectorial o máquinas de vectores soporte (Vapnik y Chervonenkis, 1974; Vapnik, 1982) son la aplicación de IA más novedosa en el campo del pronóstico del fracaso; la evidencia disponible acerca de otras técnicas, como los métodos basados en funciones de base radial, es escasa y sugiere que su complejidad incremental no viene acompaña de mejoras radicales en la capacidad predictiva (Piñeiro et al., 2013a). En términos muy amplios, las SVM pretenden establecer un clasificador lineal, denominado hiperplano de separación óptima, en un espacio de alta dimensionalidad, que permita delimitar con nitidez – con el mayor margen posible - las diferentes clases o categorías en las que están organizados los datos. Su funcionamiento interno es relativamente transparente y son además susceptibles de operaciones de agregación: por ejemplo, una máquina multiclasificadora (es decir, destinada a delimitar n>2 clases o grupos) puede construirse directamente o, también, combinando varias máquinas biclasificadoras; estas últimas pueden ser además de diferente naturaleza: one versus all (por ejemplo, sana vs. todas y cada una de las categorías de inestabilidad financiera) o one versus one (por 9 ejemplo, sana vs. no sana). Las SVM proporcionan en general mejores resultados que los modelos estadísticos ( Shin et al., 2005; Härdle et al., 2005; Tsai, 2008; Kim y Sohn, 2010; Xiaosi et al., 2011), aunque no existe evidencia concluyente que afirme sus ventajas en relación a las RNA en el caso concreto del pronóstico del fracaso. Este grupo de trabajos representa lo que podríamos denominar paradigma contable: un programa de investigación, de naturaleza esencialmente inductiva, que explota la información contable y financiera de las empresas en busca de signos que permitan desvelar disfunciones financieras latentes y eventualmente también anticipar eventos de fallo. Un análisis conjunto de sus resultados indica que i) los pronósticos formulados con base en datos contables son en general muy fiables; ii) la información financiera reúne altos estándares de calidad; y iii) en concordancia con la hipótesis de eficiencia de los mercados, las tensiones financieras acaban trasluciendo en esa información incluso si la empresa introduce ajustes discrecionales o lleva al límite la normativa contable y mercantil (Piñeiro et al., 2012 y 2013a). El enfoque inductivo es claramente mayoritario en la literatura sobre contabilidad y auditoría; por el contrario, en la literatura financiera predomina un planteamiento teórico – deductivo que pretende desarrollar constructos analíticos de tipo normativo que expresen la relación entre el riesgo de fallo, el valor de la empresa, y la variable que tradicionalmente se ha interpretado como la fuente principal de exposición, el apalancamiento (Gordon, 1971)4. Algunos de los resultados más relevantes se materializan en modelos estructurales que estiman la probabilidad de fallo en un momento dado de acuerdo con el nivel de endeudamiento y con el riesgo percibido por los inversores, el cual se evalúa usualmente a través de indicadores de mercado; entre ellos, las primas de riesgo incorporadas al interés de la deuda (Merton, 1974; Longstaff y Schwartz, 1995; Collin-Dufresne y Goldstein, 2001; Bakshi et al., 2006) y el sesgo entre los valores esperados y reales del rendimiento de los títulos de capital (Chava y Purnanandam, 2010). Al asociar el fracaso con una estimación de la probabilidad instantánea de fallo, estos trabajos mantienen en cierto sentido la noción que el fracaso es un evento súbito, a la que nos hemos referido al principio de este apartado (por ejemplo, Collin-Dufresne et al., 2004). Otros modelos más sofisticados plantean relaciones entre las rentas esperadas de las inversiones y las decisiones relativas a la estructura de capital; con frecuencia estos modelos presentan el fracaso como una opción de abandono, y se plantean evaluar la fecha óptima de ejercicio con base en argumentos de arbitraje e información asimétrica (Hotchkiss y Mooradian, 1997; Kahl, 2002). 4 Ambos enfoques, inductivo y deductivo, son inequívocamente complementarios. Por ejemplo, Wilcox (1971) plantea una justificación teórica para los resultados de Beaver (1966). Sin embargo, su alejamiento a lo largo de las dos últimas décadas es patente. 10 La literatura deductiva representa un enfoque de trabajo radicalmente diferente, que pretende soslayar una de las principales críticas imputables al planteamiento inductivo: la dificultad de generalización. Por ejemplo, Morris (1997)5 critica la aparente incapacidad del enfoque contable o inductivo para elucidar leyes o principios financieros universales, y el énfasis en la construcción de modelos ad hoc que pueden perder gran parte de su sentido cuando son empleados fuera de su contexto de estimación; Jiménez (1996) añade que los modelos estimados carecen, mayoritariamente, de sentido económico y que su utilidad en contextos de aplicación real aún no se ha verificado. En efecto, la literatura inductiva tiende a enfatizar las contribuciones de tipo metodológico, y con frecuencia presta poca atención a la discusión sistemática de las evidencias. Se observan notables discrepancias en los conjuntos de variables relevantes, tanto en comparaciones transversales como en estudios de corte temporal (Altman, 1968; Altman et al., 1977). Los modelos, en particular los basados en MDA, parecen perder capacidad predictiva conforme transcurre el tiempo (Joy y Tollefson, 1975), lo que obliga a recalibrarlos regularmente (Moyer, 1977; Altman, 2000). El tratamiento de estas anomalías parece haber recibido muy poca atención: se ha sugerido que podrían deberse a diferencias aleatorias en el muestreo, a singularidades de las poblaciones objeto de estudio, a la influencia del contexto social y económico, y a las características de la técnica de trabajo empleada. También, que los cambios en las variables y sus pesos son compatibles con la concepción del fracaso como un proceso evolutivo: los modelos estarían reflejando el agravamiento y extensión de las disfunciones financieras, y proporcionando evidencias de interés para diseccionar la dinámica interna del fracaso (Dambolena y Khoury, 1980). Tampoco puede desecharse la posibilidad de que el comportamiento aparentemente errático de las variables explicativas se deba a la presencia de ajustes discrecionales en los estados contables de las empresas sometidas a tensiones financieras (Arnedo et al., 2008; Francis y Yu, 2009). Estos trabajos proporcionan un amplio y extraordinariamente rico volumen de evidencias; pero se observan notables disparidades en las técnicas de trabajo, las variables explicativas, y la calidad de los pronósticos. Una consecuencia de ello es la dificultad para sintetizar conclusiones generalizables acerca de i) las metodologías de trabajo más adecuadas; y ii) las variables o procesos que deberían ser objeto de mayor atención para identificar signos precoces de inestabilidad financiera. Desde el punto de vista formal, la heterogeneidad de los resultados plantea una sombra de duda sobre la fiabilidad de los modelos de pronóstico: 5 Esto resulta evidente si tenemos en cuenta que el grueso de los trabajos se basa no en muestras generales, sino en poblaciones muy segmentadas, bien por actividades o bien por áreas geográficas. 11 se trataría de clarificar si ese ruido se debe a factores puramente metodológicos o singularidades de las poblaciones de estudio, o si por el contrario existen incoherencias empíricas que deban ser diagnosticadas. Un claro ejemplo de ello es el anclaje de los modelos a su marco subjetivo y temporal de estimación: esta situación resulta tan embarazosa como lo sería el hallazgo de que la Ley de Gravitación Universal se verifica solo de manera irregular en el tiempo y el espacio. Pretendemos explorar las ventajas relativas de las técnicas más comunes de pronóstico en un entorno de investigación controlado: los modelos son estimados sobre las mismas muestras, con las mismas variables independientes y en el mismo período de tiempo, para controlar los efectos de confusión que, en nuestra opinión, son la fuente principal del ruido que dificulta la síntesis de resultados. Finalmente examinamos la estabilidad temporal de los modelos (Pindado et al., 2008). 3 ESTUDIO EMPÍRICO 3.1 VARIABLE DEPENDIENTE El pronóstico del fracaso empresarial suele plantearse como un problema de clasificación, en que las empresas se dividen en al menos dos categorías: sanas y fallidas. El criterio de delimitación más común es el jurídico, que reputa fallidas a las empresas que o bien se han extinguido o bien se hallan incursas en procesos concursales. A pesar de su indudable importancia para propietarios, inversores y acreedores, estos eventos no son sino puntos terminales de una serie de tensiones financieras que se han ido agudizando a lo largo del tiempo, y que posiblemente han proporcionado algunos signos previos de alerta. En este trabajo empleamos una especificación amplia del concepto de fracaso financiero comprensiva tanto de los colapsos repentinos como de ciertos eventos que, como los impagos recurrentes, están directamente relacionados con tensiones financieras latentes (Hing-Ling, 1987). Definimos como fallidas las empresas que verifican una o más de las siguientes condiciones: • Haber declarado una quiebra o proceso extintivo irreversible durante el período de estudio. • Estar actualmente incursa en procesos concursales • Estar afectada por litigios judiciales vinculados a la reclamación de deudas de cuantía elevada y relevante. • Haber impagado efectos comerciales aceptados, con frecuencia y por cuantía relevantes, de acuerdo con el contenido de las distintas bases de datos de este tipo de incidencias. 12 3.2 VARIABLES EXPLICATIVAS La elección de las variables explicativas está íntimamente relacionada con los objetivos de nuestro trabajo. Pretendimos aplicar diferentes técnicas de análisis a una misma muestra a efecto de analizar posibles concordancias en sus respectivos resultados, y esto exige que las variables sean compatibles con técnicas dispares; en concreto, implica descartar las variables cualitativas y categóricas. Las ratios financieras ocupan un lugar sin duda preeminente entre las variables numéricas continuas; están profundamente enraizadas en la teoría financiera, cuentan con un sólido aval en la literatura sobre fracaso financiero, y son un instrumento absolutamente común en la praxis financiera. El empleo de ratios nos brinda la oportunidad de aportar evidencia indirecta acerca de la calidad de la información contable pública: esta es una cuestión de importancia ya que los usuarios externos deben evaluar el riesgo de crédito sobre la base de la información pública de la empresa, que está constituida fundamentalmente por datos económicos y financieros emanados de la contabilidad. Los modelos estimados en nuestro trabajo emplean como variables independientes una batería de ratios financieras, seleccionadas de acuerdo con tres criterios: su popularidad en la literatura contable y financiera, la frecuencia con la que son empleadas en la literatura relevante en materia de pronóstico del fracaso empresarial, y la significación estadística que les atribuyen estos estudios. Hemos optado por un conjunto amplio de variables independientes para evitar que el diseño experimental pueda imponer restricciones sobre la estimación de los modelos y por tanto causar una convergencia artificial o espuria. 13 ACT03 ACT04 ACT05 Valor Añadido / Ventas APL01 B.A.I.T. / Gastos Financieros Gastos Financieros / Deuda Total Res. Explot. / Gastos APL03 Financieros Resultado Neto / Exigible APL04 Total Deuda Total / Fondos END01 Propios (Pat. Neto – Res. Neto) / END02 Exigible A Corto Fondos Propios / Exigible END03 Total REN01 B.A.I.T. / Activo Total REN02 B.A.I.T. / Ventas Rentabilidad ACT02 Gastos Financieros / Valor Añadido Gastos Personal / Activo Fijo (Gtos. Personal + Amortiz.)/ Val. Añadido Ingresos Explotación / Consumos Explotación APL02 REN03 Resultado Neto / Ventas (Res. Neto - Realizable – Existencias) / Activo Total Resultado Neto / Activo REN05 Total Resultado Neto / Fondos REN06 Propios (Act. circ. – Existencias) / ROT01 Ventas REN04 ROT02 Existencias / Ventas Rotación Endeudam. Apalancam. Actividad ACT01 ROT03 Ventas / Realizable Cierto ROT04 Ventas / Activo Circulante ROT05 Ventas / Activo Fijo ROT06 Ventas / Activo Total EST02 Estructura EST03 EST04 EST05 Capital Circulante / Ventas EST06 Disponible / Activo Total EST07 EST08 LIQ01 LIQ02 LIQ03 Liquidez LIQ04 LIQ05 LIQ06 LIQ07 LIQ08 LIQ09 LIQ10 LIQ11 LIQ12 LIQ13 4 ROT07 Ventas / Capital Circulante ROT08 Ventas / Disponible SOL01 SOL02 SOL03 Solvencia EST01 Pasivo A Largo / Exigible Total Activo Circulante / Activo Total Dot. Amortización / Inmovilizado Neto Capital Circulante / Activo Total Capital Circulante / Exigible Total SOL04 SOL05 (Act. corr. – Existencias) / Exig. c/p Activo Circulante / Exigible Total Activo Circulante / Pasivo Circulante Activo Fijo / Fondos Propios Pasivo Exigible / Activo Total Fondos Propios / Activo Total Fondos Propios / Inmovilizado Exigible A Corto / Activo Total Res. antes de Imp./ Exigible corriente Tesorería / Pasivo Circulante Resultado Neto / Capital SOL06 Circulante Medida Descomposición Del SOL07 Activo Cash Flow Operativo / Activo SOL08 Total Cash Flow Operativo / SOL09 Exigible Total Cash Flow Operativo / TES01 Exigible A Corto Cash Flow Operativo / TES02 Tesorería / Ventas Ventas Cash Flow / Activo Total Cash Flow / Exigible Total Cash Flow / Exigible A Corto Cash Flow Recursos Generados / Ventas Disponible / Pasivo Circulante Existencias / Exigible A Corto Existencias + Realizable / Exigible A Corto Intervalo Sin Crédito Realizable / Exigible A Corto TABLA 2 VARIABLES EXPLICATIVAS Tesor. END04 RESULTADOS 4.1 ANÁLISIS UNIVARIANTE Y REDUCCIÓN DE DATOS Beaver (1966) demostró la existencia de diferencias estadísticamente significativas en los valores medios de cierto número de ratios financieras. Nuestros resultados corroboran la existencia de diferencias significativas (p-valores inferiores al 1%) en más de la mitad de las ratios: las empresas fracasadas padecen una incapacidad crónica para generar recursos a través de la actividad debido a sus bajos niveles de rentabilidad, que suplen recurriendo a un endeudamiento más intenso; todo ello se traduce en tensiones crecientes en el fondo de rotación y en el progresivo estrangulamiento de la cuenta de resultados en lo que respecta 14 tanto al resultado económico o de explotación, como a la cobertura de los gastos financieros y la capacidad para atender el servicio de la deuda. Por tanto la liquidez aparece relacionada con solvencia, la rentabilidad, y el apalancamiento. En cada caso, debimos calibrar un punto óptimo de corte mediante simulación artificial, para seguidamente, interpretar estos umbrales como un criterio ingenuo de clasificación, comprobando qué indicadores delimitan con mayor nitidez a las empresas sanas y fallidas. Las variables más relevantes detectadas están basadas se concentran en: activo total, cash flow, pasivo exigible, patrimonio neto, resultado antes intereses e impuestos, y resultado neto. Este resultado tiene una traducción directa como criterio para la identificación de los procesos y las magnitudes económicas que deberían centrar la atención de directivos, analistas, y auditores, y también como guía para el desarrollo de modelos multivariables. A sensu contrario, los resultados de las pruebas de ANOVA indican también que gran parte de las variables planteadas tiene una incidencia marginal en el pronóstico; por otra parte, la acusada correlación de las ratios está bien documentada. Todo ello sugiere el empleo de técnicas para reducir la dimensión de los datos y sus redundancias (Wu et al., 2006). Debe formularse un análisis factorial exploratorio con el fin de retener aquellos factores que tengan autovalor significativo, puesto que serán combinación lineal de un número reducido de indicadores, con capacidad de explicación amplia del pronóstico del fallo financiero. Cualquiera que sea el horizonte de pronóstico, los factores con más peso (varianza alta) están basados en medidas de rentabilidad, generación de cash flow, endeudamiento y solvencia. En nuestra opinión, debe concluirse que las dificultades para generar recursos, las tensiones de liquidez y las alteraciones en la estructura financiera son disfunciones presentes durante largos períodos de tiempo antes de que el fracaso se manifieste. 4.2 MODELOS MULTIVARIABLES PARAMÉTRICOS 4.2.1 Regresión lineal múltiple Aunque es empleada con cierta profusión en múltiples áreas de las finanzas, como la modelización del rendimiento y el riesgo (por ejemplo Ross, 1976), la regresión lineal múltiple tiene un difícil encaje en el pronóstico del fracaso financiero dado que en este caso la variable dependiente tiene naturaleza dicotómica. Las estimaciones realizadas empleando una estrategia de selección hacia delante para los regresores, obtienen p–valores iguales o inferiores al 1% (Rodríguez, 2002b). En conjunto los modelos son significativos y logran tasas medias de acierto aceptables, entre el 70% y el 100%, sin embargo su fiabilidad como instrumento de pronóstico es cuestionable. En concordancia con la literatura precedente, observamos una reducción progresiva de la capacidad de discriminación a medio y largo plazo (Altman, 1968; Altman, 1977). Los modelos exhiben además una marcada asimetría: logran tasas de acierto aceptables entre las empresas sanas, pero parecen tener 15 dificultades para expresar adecuadamente el perfil financiero de las fallidas. Por otra parte la calidad de los pronósticos se deteriora acusadamente cuando los modelos se aplican a la muestra de validación, que está compuesta por observaciones completamente ajenas a la muestra de estimación, y tiene además una estructura no equilibrada más realista. Fuera de su marco temporal, los MRL cometen llamativos errores de tipo II, los modelos MRL atemporales logran excelentes resultados entre las empresas fallidas, pero nuevamente se demuestran incapaces de identificar el perfil de las empresas sanas (Altman, 1968; Deakin, 1972; Altman, 1977; Bellovary et al 2007; Kim, 2011). Década 1960 1970 1980 1990 2000 Peor Mejor Método pronóstico pronóstico 79% 92% Univariante (Beaver 1966) Probabilidad Lineal (Meyer y Pifer 1970), 56% 100& MDA (Edmister 1972, Santomero y Vinso 1977) MDA (Marais 1980, Betts y Behoul 1982, El Henawy y Morris 1983, Izan 1984, Takahashi et al 1984, Frydman 20% 100% et al 1985); Particionamiento recursivo (Frydman et al 1985); Redes neuronales (Frydman et al 1985). Redes neuronales (Guan 1993, Tsukuda y Baba 1994, El-Temtamy 1995); 27% 100% Crítico (Koudinya y Puri 1992); Aditivo (Theodossiu 1993). 27% 100% MDA (Patterson 2001). TABLA 3 CAPACIDAD PREDICTIVA POR DÉCADAS6 7 4.2.2 Análisis discriminante múltiple Los modelos discriminantes se han estimado empleando el método de inclusión por pasos hacia adelante, en combinación con en el criterio Lambda de Wilks. Los resultados de las estimaciones de todos los modelos resultaron significativos, a la vista de los respectivos valores del estadístico χ2, y los p-valores de las pruebas de significación de los estimadores son inferiores al 1%. En promedio para todos los horizontes y estados financieros, los modelos MDA clasifican correctamente a un alto porcentaje de observaciones. En consecuencia, cometen un error medio significativamente bajo. Se observan las mismas anomalías descritas más arriba para el caso de los modelos de regresión lineal: la fiabilidad del pronóstico es superior a corto plazo, especialmente en el caso de empresas sanas, y empeora drásticamente en los plazos más distantes; tratándose de empresas fallidas, la tasa media de errores en todos los horizontes supera ampliamente niveles aceptables. Una debilidad todavía no aclarada de estas herramientas es su inestabilidad temporal, es decir, su incapacidad para mantener niveles satisfactorios de pronóstico cuando se emplean 6 Bellovary, Giacomino y Akers 2007. 7 Nuestra experiencia en este sentido es haber logrado tasas de acierto superiores al 70%, llegando en algún caso al 100%. 16 fuera del período de estimación (Moyer, 1977; Altman, 2000). La validación extemporánea de los MDA no recalibrados pone de manifiesto que, si bien cometen relativamente pocos errores de tipo I, clasifican incorrectamente a una amplia mayoría de las empresas sanas, y que este sesgo se intensifica conforme crece el horizonte de pronóstico. Así, el modelo MDA no recalibrado clasifica correctamente altos porcentajes de empresas fallidas un año antes del evento, pero por el contrario un bajo acierto en empresas sanas en ese mismo plazo. Estos indicadores corroboran la presencia de una interacción intensa y compleja entre las anomalías financieras, el tiempo, y la capacidad de los modelos para proporcionar diagnósticos de calidad (de Llano et al., 2011a y 2011b). En nuestra opinión, no debe descartarse la posibilidad de que el estrés financiero ocasionado por la crisis de 2007 haya difuminado el perfil de las empresas financieramente sanas, lo que confirmaría la necesidad de recalibrar los modelos cuando se producen circunstancias sistémicas que alteran la exposición al riesgo. 4.2.3 Regresión logística condicional La similitud de los resultados proporcionados por los modelos de regresión lineal y discriminante puede radicar en el hecho de que comparten hipótesis que, como la linealidad, normalidad y homocedasticidad, difícilmente se verifican en series de datos basadas en ratios financieras. La regresión logística condicional es menos dependiente de hipótesis a priori, y por tanto potencialmente más adecuada al problema en curso. Los modelos estimados son globalmente significativos, y sus estimadores son diferentes de cero con pvalores inferiores al 1%. Atendiendo a las razones de posibilidades u odds-ratios (eβ), variables con mayor incidencia en el riesgo de fallo, podemos esbozar una descripción general del proceso de fracaso. Las empresas fallidas tienen dificultades para generar cash flow debido a la combinación de un volumen de negocio y un margen relativamente pequeños, lo que se traduce en un déficit crónico de autofinanciación y en un apalancamiento más intenso. La persistencia de las tensiones de liquidez ocasiona dificultades para atender el servicio de la deuda y un aumento del riesgo financiero, más acusado cuando la actividad comercial afronta períodos de volatilidad y cuando la financiación del fondo de rotación y renovación de la deuda se ven condicionadas por restricciones en el acceso al crédito. En conjunto, los modelos Logit estimados logran una tasa de acierto elevada, en promedio para los distintos horizontes de pronóstico. En el caso concreto de las empresas fallidas, superan en todos los horizontes a los modelos MDA, tanto en la fase de estimación como en la validación; en el subgrupo de empresas sanas los MDA parecen lograr resultados más favorables solo en los plazos de tiempo más cortos, entre 1 y 3 años. Los errores son sustancialmente inferiores a los comunicados por otros trabajos recientes, como Kim (2011), 17 y comparables a los proporcionados por los modelos de regresión logística multinomial (por ejemplo, Hing-Ling, 1987) que, como se sabe, admiten diferentes grados de tensión financiera codificados en forma de variables independientes no dicotómicas. Los resultados de la aplicación de los modelos no recalibrados sugieren que los modelos Logit son en general menos vulnerables a los cambios inducidos por los factores sistemáticos sobre el perfil económico – financiero de las empresas (de Llano et al., 2011a y 2011b; Piñeiro et al., 2013b). Los modelos Logit parecen ser menos vulnerables a los cambios en el contexto económico general, que obligan a recalibrar los MDA, y proporcionar también pronósticos de mejor calidad, si nos atenemos al examen conjunto de las tasas de error de tipo I y II. 4.3 MODELOS HEURÍSTICOS 4.3.1 Particionamiento recursivo: árboles de decisión Los modelos de particionamiento logran tasas de acierto muy satisfactorias en todos los horizontes y en ambas categorías de empresas, sanas y fallidas (Calvo y Rodríguez, 2003); lo hacen además con una extraordinaria parsimonia, ya que requieren únicamente dos variables en cada horizonte. Es interesante observar que, cualquiera que sea el horizonte de pronóstico, el algoritmo de particionamiento recursivo sugiere que las empresas fracasadas muestran una anomalía característica en la estructura financiera: el endeudamiento es anormalmente pequeño en los años inmediatamente anteriores al evento de fallo. Estos resultados indican que las tensiones financieras llevan a las empresas a aplicar acciones desesperadas de supervivencia, entre las que se hallan la liquidación de activos y una contracción del nivel de diversificación de la actividad, y que estas acciones coinciden en el tiempo con caídas abruptas en el nivel de deuda. Es posible que la reducción del exigible responda a un intento por mitigar los gastos financieros y, con ello, el riesgo de incumplimiento; sin embargo, parece más plausible que se deban a ajustes discrecionales dirigidos a enmascarar las dificultades financieras de la empresa y transmitir al entorno una imagen de normalidad (Francis y Yu, 2009). En nuestra experiencia, los resultados que hemos obtenidos al aplicar los criterios de segmentación jerárquica a la muestra de validación extemporánea, sugieren que los árboles conservan una muy elevada capacidad de diagnóstico en un horizonte de un año; la precisión se deteriora sistemáticamente en plazos más prolongados, de manera más acusada en el caso de las empresas sanas. 4.3.2 Herramientas de inteligencia artificial: redes neuronales Las características del problema – concurrencia de múltiples posibles variables explicativas, correlaciones, estructuración incompleta, patrones de clasificación difusos, relaciones no 18 lineales – convierten a las RNA en candidatas idóneas para el desarrollo de instrumentos de análisis y pronóstico. Hemos entrenado y validado una red multicapa de perceptrones con 52 elementos en la capa de entrada, una sola capa oculta de 10 neuronas, y una neurona en la capa de salida (Rodríguez, 2002b). La red logra una tasa de acierto más altas en fase de entrenamiento que en fase de validación, con mejores resultados en los horizontes de pronóstico más próximos. Estos resultados son coherentes con los aportados por trabajos recientes, como Kim (2011) y Xiaosi et al. (2011). Las ratios relevantes enfatizan la relación entre el resultado y la inversión de la empresa, el equilibrio patrimonial por plazos y por origen de la financiación, y la capacidad del negocio para generar flujos en una cuantía proporcionada a la deuda. En los plazos más cortos, el riesgo aparece relacionado con indicadores de la rotación, la liquidez del ciclo de operaciones, la rentabilidad del negocio y, llamativamente, con la estructura de la financiación): creemos que la presencia de la estructura financiera en la RNA para pronósticos a un año es el reflejo las acciones defensivas puestas en práctica por las empresas, y que se materializan en intentos extremos para reducir a toda costa el nivel de endeudamiento y/o renegociar la deuda para aumentar los plazos de pago. Las RNA han sido repetidamente criticadas por su carácter adhocrático, es decir, por tratarse de herramientas que simplemente se adaptan a los datos pero están desconectadas de la teoría; también, que su funcionamiento a modo de caja negra no contribuye a explicar el problema en curso, por tanto tampoco a proporcionar evidencias útiles para el progreso del conocimiento. Hemos formulado un análisis de sensibilidad (Nath et al., 1997) para diseccionar el funcionamiento interno de la red, y aclarar cuáles son las variables con mayor peso en el diagnóstico. En concordancia con lo señalado por otros modelos previos, ratios que miden apalancamiento son las de incidencia. De otra parte, las redes destacan también indicadores como rentabilidad económica y a varias ratios relacionadas con el equilibrio en el ciclo financiero a corto plazo. 4.3.3 Rough sets La ausencia de estructuración, la delimitación difusa de las fronteras entre los grupos de empresas sanas fallidas, y la presencia de redundancias en las variables explicativas hacen que pronóstico del fracaso empresarial sea, a priori, un campo idóneo para la aplicación de la teoría de conjuntos aproximados. Dado que los atributos de condición – las ratios – tienen naturaleza continua, fueron discretizados en diez intervalos. A continuación, y de acuerdo con el principio de longitud de descripción mínima (Rissanen, 1983), se realizó una selección de los atributos potencialmente relevantes mediante el procedimiento de selección automático descrito por Díaz y Corchado (2001), lo que permitió descartar 33 de los 59 atributos originales (Rodríguez y Díaz, 2005). Finalmente, se identificaron los reductos para 19 cada uno de los cuatro horizontes de tiempo considerados en el estudio. Las reglas de decisión asociadas a los reductos permiten realizar clasificaciones con una tasa de acierto que oscila entre el 91,96% a un año, y el 72,14% cuatro años antes del evento, empleando solo 18 de las 59 ratios originales. 4.3.4 Data Envelopment Analysis (DEA) Aunque existen aplicaciones datadas hace más de treinta años, DEA (Charnes et al., 1978; Charnes et al., 1985; Cook y Seiford, 2009) es posiblemente la técnica más atípica en el pronóstico del fracaso (Troutt et al., 1996; Sueyoshi y Goto, 2009a y 2009b). Uno de los principales inconvenientes es la necesidad de calibrar el punto de corte de los modelos Logit, que en aplicaciones generales suele definirse como p=0’5. Algunos autores, entre ellos Premachandra et al (2009), mantienen que este valor no es adecuado cuando el Logit se incardina en el análisis de eficiencia relativa basada en DEA porque puede inducir sesgos, especialmente cuando se utilizan modelos “super-eficientes”; en su lugar, sugieren identificar un valor óptimo entre 0’1 y 0’9 a través de estrategias de simulación. Esta discusión trasciende sin embargo los objetivos de nuestro trabajo de manera que hemos estimado un DEA aditivo que incluye una variable “ck” para representar dinámicas de rendimiento variable (Adler et al., 2002; de Llano et al., 2013). Las fronteras se estimaron con datos del período 1990-99, y a continuación se sometieron a una validación extemporánea con datos de 2000-2009. De acuerdo con nuestros resultados, las variables más relevantes para el análisis de la eficiencia DEA resultan ser la capacidad de generar rentas, medida por los ingresos y el cash flow, y la estructura de las inversiones a corto plazo, representada por el capital circulante y el activo corriente; los modelos sugieren que estas características inciden definitivamente en la relación entre deuda y activo total, y evalúan a partir de ellas el riesgo relativo de cada empresa (de Llano et al., 2013). La herramienta logra clasificar correctamente al 79,85% de las empresas, sin embargo en nuestra opinión el empleo de DEA para formular pronósticos en este contexto es cuestionable. Una primera crítica se refiere a la determinación del papel que debe jugar cada variable en el modelo (Premachandra et al., 2009 citando a Altman, 1968). Muchas de las variables y procesos implicados en las ratios no son, en sentido riguroso, inputs ni outputs sino eslabones de un ciclo financiero retroalimentado; esto hace que su calificación sea en mayor o menor medida arbitraria, y que se precisen modelos DEA multifase (Lit et al., 2012) capaces además de tratar con variables en diferente escala ( Sinuany-Stern y Friedman, 1998). Por otra parte es sabido que la noción de frontera eficiente tiene un marcado sentido relativo: las unidades, en este caso las empresas, no son eficientes en sentido absoluto, sino en relación a otras y en un momento dado del tiempo. Aunque podamos jerarquizar a las empresas en función de 20 su exposición relativa, la conversión de las distancias en medidas del riesgo y de la verosimilitud de un eventual fallo resulta problemática (Liu y Chen, 2009; Shetty et al., 2012). 5 CONCLUSIONES Tres son los pilares de la investigación en la predicción del fracaso financiero; Univariante (Beaver 1966), Multivariante MDA (Altman 1968), y Logit (Olshon 1980). Sobre estos modelos se construyeron distintas variantes, hasta llegar a trabajar con herramientas de redes neuronales y de inteligencia artificial. Nuestro trabajo trata de hacer un repaso de los exponentes más significativos en la literatura en los últimos sesenta años. Podemos inferir de nuestra experiencia la capacidad predictiva de las diferentes técnicas empleadas en el pronóstico del fracaso financiero, del que se derivan conclusiones relevantes acerca de sus respectivas ventajas relativas e indicios acerca de qué ratios y magnitudes poseen mayor contenido informacional y deben ser objeto de una supervisión más rigurosa, con independencia de la técnica matemática o estadística empleada. La importancia de los modelos de estimación, tiene su limitación en la estabilidad temporal de los modelos, largamente debatido. De hecho, es necesario realizar ajustes y recalibrar los modelos regularmente. Lo que en principio podíamos interpretar tras el contraste, como reflejo de la crisis de 2007 en los resultados, apunta a ser la limitación temporal del modelo. Una de las primeras evidencias en este sentido es el trabajo de Joy y Tollefson (1975), quienes critican duramente el hecho de que la inestabilidad de los modelos discriminantes hubiese pasado desapercibida debido a la ausencia de procedimientos de contraste intertemporal en los estudios originales de Altman (1968 y 1977). En este sentido, el modelo z-score aportado por Altman et al. (1977) conserva solo una de las predictoras originales del modelo básico de Altman (1968). Compartimos la opinión, expuesta por Joy y Tollefson (1975), de que esta inconsistencia es científicamente indeseable, ya que supone una amenaza permanente para cualquier constructo teórico que se pueda derivar de la investigación. Desde un punto de vista práctico, es una evidente fuente de riesgo de modelo. El decisor no dispone de criterios para aventurar si los pronósticos obtenidos en un momento dado son fiables o, por el contrario, están sesgados por la degeneración temporal a la que nos hemos referido. Nuestro trabajo a lo largo de los últimos años, corrobora la posibilidad de realizar pronósticos de gran calidad empleando exclusivamente evidencias basadas en magnitudes financieras y económicas básicas. Lo anterior no solo avala la calidad general de información contable difundida por las empresas, sino que también pone de relieve que los esfuerzos para ocultar las disfunciones financieras internas a través de ajustes discrecionales u otras acciones de ocultación son ineficaces. No obstante es interesante observar que, con la única excepción de los modelos basados en particionamiento recursivo, 21 las tasas de error de las técnicas más fiables parecen converger en un nivel en torno al 90%. Resultado indicativo de que la calidad de los pronósticos difícilmente podrá mejorarse a menos que se incluyan variables adicionales, expresivas por ejemplo de la bondad de la gestión o de las condiciones económicas generales, que aporten evidencias para matizar la interpretación de los valores numéricos de las ratios. Las evidencias proporcionadas por la auditoría externa – dictamen, salvedades, etc. – son, de acuerdo con nuestra experiencia, candidatas idóneas para entrar a formar parte de modelos de pronóstico del fracaso, junto con las variables financieras. Los resultados a los que hemos llegado indican que una gran parte de la información financiera que manejan los usuarios (en forma de datos brutos, o de ratios) es prescindible en un diagnóstico de fracaso. Bien porque no contiene evidencias de interés para evaluar el riesgo de fallo, o porque esas evidencias se canalizan a través de otros indicadores, siendo por tanto redundantes. En nuestro caso podemos arrojar luz sobre qué elementos del flujo de información requieren mayor atención; proporciona criterios concretos para seleccionar los datos relevantes, y una guía general para el trabajo en escenarios de información imperfecta. Desde el punto de vista metodológico, al margen del enfoque univariante, de evidentes limitaciones, todas las técnicas proporcionan en general pronósticos de gran calidad. La tasa media de acierto para todos los modelos que hemos estimado, supera el 87%. Los modelos basados en análisis discriminante, los más profusos en la literatura, obtienen los peores resultados en todos los horizontes de tiempo, con tasas de error similares a las de los modelos de regresión lineal convencionales. Su fiabilidad decrece acusadamente con el tiempo, y en el modelo de pronóstico a cuatro años antes del fallo, presenta un error medio del 29%, superior al derivado de un simple análisis univariante. Creemos que esta aparente incapacidad puede estar relacionada con el incumplimiento de algunas de sus hipótesis esenciales, concretamente las relativas a la normalidad y homocedasticidad. Los modelos Logit no logran las mayores tasas de acierto, sin embargo mantienen una excelente parsimonia. Con un número mínimo de variables explicativas, imponen requerimientos hipotéticos realmente laxos, ofrecen resultados de gran interés práctico y teórico, como las medidas de riesgo relativo (odds-ratios). Los árboles han demostrado una capacidad analítica inesperada. En un horizonte de un año antes del fallo, clasifican correctamente todas las empresas, y a cuatros años antes presentan un error del 2%. En nuestra opinión, los métodos de particionamiento recursivo son candidatos idóneos para el desarrollo de modelos para el análisis del riesgo financiero, dadas su naturaleza no paramétrica, el carácter explícito de sus reglas de clasificación, y las oportunidades de informatización. 22 No hemos hallado signos de que exista una relación precisa entre la sofisticación del método de trabajo y la calidad de sus pronósticos. Los modelos basados en conjuntos imprecisos, que junto con las RNA son los que poseen mayor complejidad operativa, no ofrecen ventajas comparativas claras frente a otras técnicas más convencionales como la regresión logística o los propios árboles generados por particionamiento recursivo. De hecho emplean también un número mayor de variables, lo que significa que consumen más información y son por tanto más costosos. Es posible que la complejidad del problema presentado no sea coherente con la capacidad de procesamiento de algunas de las herramientas heurísticas, y que ello haya redundando en una merma aparente de eficacia. En cualquier caso, debemos concluir que la metodología de trabajo empleada no parece alterar significativamente los resultados de los pronósticos, lo que sugiere que el esfuerzo de investigación debería concentrarse más en mejorar la calidad y el contenido informacional de las variables de entrada, que en el diseño de técnicas de análisis sofisticadas. 23 6 BIBLIOGRAFÍA Adler, N., Friedman, L., Sinuany-Stern, Z (2002), “Review of Ranking in the Data Envelopment Analysis Context”, European Journal of Operational Research, 140, 249265. Altman, E. (1968): “Financial Ratios, Discriminant Analysis and Predition of Corporate Bankruptcy”. Journal of Finance: 589 – 609. Altman, E. (1969): Corporate bankruptcy potential, stockholder returns, and share valuation. Journal of Finance Vol. 24, nº 5, pp. 887 – 904. Altman, E. (1977): Some estimates of the cost of lending errors for commercial banks. Journal of Commercial Bank Lending, Octubre. Altman, E. I. (2000): “Predicting Financial Distress of Companies: Revisiting the Z-Score and ZETA Models”. Working Paper. NYU Salomon Center. Altman, E. I.; Haldeman, R. C.; Narayanan, P. (1977): “ZETA Analysis. A New Model to Identify Bankruptcy Risk Corporations”. Journal of Banking and Finance. June: 29-54 Altman, E.; Marco, G.; Varetto, F. (1994): Corporate distress diagnosis: comparisons using linear discriminant analysis and neural networks. Journal of Banking and Finance Vol. 18, pp. 505 – 529. Anzola, O. y Puentes, M, (2007): “Determinantes de las acciones gerenciales en microempresas y empresas Pymes”. Bogotá: Universidad Externado de Colombia, Facultad de Administración de Empresas. Arnedo, L., Lizarraga, F., y Sanchez, S. (2008). Going-concern uncertainties in prebankrupt audit reports: new evidence regarding discretionary accruals and wording ambiguity. International Journal of Auditing, 12(1), 25–44. Arquero, J., Abad, M. y Jiménez, S. (2009). Procesos de fracaso empresarial en Pymes, Identificación y contrastación empírica. Revista Internacional de la pequeña y mediana empresa, 1 (2), 64-77. Arthur Winakor, Raymond Smith (1935) Bakshi, G.; Madan, D.; Xiaoling, F. (2006): Investigating the role of systematic and firmspecific factors indefault risk: lessons from empirically evaluating credit risk models. Journal of Business Vol. 79, nº 4, pp. 1955-1987. Bardia, S. C. (2007): Predicting financial distress and evaluating long-term solvency: an empirical study. The IUP Journal of Accounting Research & Audit Practices Vol. XI, nº 1, pp. 47 – 61. Barr, R. S., Seiford, L. M., and Siems, T. F. (1993); “An Envelopment-Analysis Approach to Measuring the Management Quality of Banks”, Annals of Operations Research, 1993, 38, 1-13. 24 Baxter, N. (1967): Leverage, risk of ruin, and the cost of capital. Journal of Finance Vol. 22, Septiembre, pp. 395 – 404. Beaver, W. H. (1966): “Financial ratios as predictors of failure”. Empirical Research in Accounting: Selected Studies, suplements to V. 4 of Journal of accountant Research: 71 – 111 Becerra, V.; Galvao, R.; Abou-Seada, M. (2002): On the utility of input selection and pruning for financial distress prediction models. Proceedings of the 2002 International Joint Conference on Neural Networks. Hawaii: 1328 – 1333 Bell, T. B.; Ribar, G. S. and J. Verchio (1990), “Neural Nets versus Logistic Regression: A Comparison of Each Model’s Ability to Predict Commercial Bank Failures”, en Srivastava R. P. (editor) Auditing Symposium X Deloitte & Touche, Symposium on Auditing Problems; Kansas: 29-53. Bellovary, J., Giacomino, D., Akers, M. (2007) “A Review of Bankruptcy Prediction Studies: 1930-Present”, Accounting Faculty Research and Publications, College of Business Administration. Bernard, V. I.; Stober, T. I. (1989) The nature and amount of information in cash flows and accruals, Accounting Review, 64(4), pp. 624–652. Bottazzi, G.; Grazzi, M.; Secchi, A.; Tamagni, F. (2011): Financial and economic determinants of firm default. Journal of Evolutionary Economics Vol. 21, Nº 3, pp 373406. Boyacioglu, M., Kara, Y., y Baykan, O. (Ed.). (2008). Predicting bank financial failures using neural networks, support vector machines and multivariate statistical methods: A comparative analysis in the sample of Savings Deposit Insurance Fund (SDIF) transferred banks in Turkey. Experts Systems with Applications, 36(2), 3355–3366 Bradshaw, M. T., Richardson, S. A. y Sloan, R. G., 2001. Do analysts and auditors use information in accruals? Journal of Accounting Research, 39(1), 45 - 74. Breiman, L.; Friedman, J.H.; Olshen, R.A.; Stone, C.J. (1984): Classification and Regression Trees, Chapman & Hall. Brockett, P.; Golden, L.; Jang, J. and C. Yang (2006), “A comparison of neural network, statistical methods, and variable choice for life insurers’ financial distress prediction”, The Journal of Risk and Insurance, 73 (3): 397 – 419. Calvo, A.; Rodríguez, M. (2003): “Aplicación de Técnicas de Segmentación Jerárquica a la predicción del Fracaso Empresarial”, VI Congreso Gallego de Estadística e Investigación Operativa. Calvo-Flores, A., García, D., y Madrid, A. (2006). Tamaño, Antigüedad y Fracaso Empresarial. Working Paper. Cartagena: Universidad Politécnica de Cartagena. 25 Charitou, A.; Neophytou, E.; Charalambous, C. (2004): Predicting Corporate Failure: empirical evidence from the U. European Accounting Review Vol. 13, nº 3, pp. 465 – 497. Charnes, A., Cooper, W.W., Golany, B., Seiford, L. (1985) “Foundations of Data Envelopment Analysis for Pareto-Koopmans Efficient Empirical Production Functions”, Jorunal of Econometrics 30, 1985, 91-107. Charnes, A., Cooper, W.W., Rhodes, E. (1978); “Measuring the efficiency of decision making units”, European Journal of Operations Research, 2, 429-444. Chava, S.; Purnanandam, A. (2010): Is Default Risk Negatively Related to Stock Returns? The Review of Financial Studies Vol. 23, Nº 6, pp. 2523 – 2559. Collin-Dufresne, P.; Goldstein, P.; Hugonnier, J. (2004): A general formula for valuing defautable securities. Econometrica Vol. 72, pp. 1377-1407. Collin-Dufresne, P.; Goldstein, R. (2001): Do credit spreads reflect stationary leverage? Reconciling structural and reduced-form frameworks. Journal of Finance Vol. 56, Nº 5, pp. 1929 – 1957. Cook, W.D., Seiford, L.M. (2009), “Data Envelopment Analysis (DEA) – Thirty Years On”, European Journal of Operation Research Vol. 192, nº 1, pp. 1-17. Dambolena, I.; Khoury, S. (1980): Ratio stability and corporate failure. The Journal of Finance VOl. XXXV, nº 4, Septiembre, pp. 1017 – 1026. Daubie, M., Levecq, P.; Meskens, N. (2002): “A Comparison of the Rough Sets and Recursive Partitioning Induction Approaches: An Application to Commercial Loans”. International Transactions in Operational Research, 9(5), pp. 681 - 694. Davydenko, S. (2010). When do firms default? A study of the default boundary. Toronto: University of Toronto. Recuperado de http://ssrn.com/abstract=672343 de Llano, P.; Piñeiro, C.; Rodríguez, M. (2011a): “Contraste de los modelos de pronóstico del fallo empresarial en las pymes sanas gallegas”. XXV Congreso de AEDEM. Valencia. de Llano, P.; Piñeiro, C.; Rodríguez, M. (2011b): “Modelos de pronóstico del fallo empresarial en las pymes sanas gallegas”. XXV Congreso de AEDEM. Valencia. de Llano, P.; Piñeiro, C.; Rodríguez, M. (2013): DEA as a business failure prediction tool. Revista Contaduría y Administración (próxima publicación). Deakin, E. (1972) A discriminant analysis of predictors of business failure. Journal of Accounting Reearch, Spring, pp. 167 – 179 Díaz, F.; Corchado, J.M. (2001). The Selection of Relevant Features and Rough Sets. Conferencia de la Asociación Española de Inteligencia Artificial. Gijón, 14–16 Noviembre. 26 FitzPatrick, P. 1932. A comparison of ratios of successful industrial enterprises with those of failed companies. The Certified Public Accountant (October, November, December): 598-605, 656-662, and 727-731, respectivamente. Francis, J. R.; Yu, M. D. (2009): The effect of big four office size on audit quality. The Accounting Review, 84(5), 1521 - 1552. Friedman, J. (1977): A recursive partitioning decision rule for nonparametric classification. IEEE Transactions on Computers Vol. 26, nº 4, pp. 404 – 408 Frydman, H.; Altman, E.; Kao, D. (1985): Introducing recursive partitioning for financial classification: the case of financial distress. Journal of Finance Vol. 40, nº 1, pp. 269291 García, D., Arqués, A. y Calvo-Flores, A. (1995); Un modelo discriminante para evaluar el riesgo bancario en los créditos a empresas, Revista Española de Financiación y Contabilidad, XXIV (82), 175-200. Gordon, M. (1971): Towards a theory of financial distress. Journal of Finance Vol. 25, nº 2, pp. 347 – 356. Greenball, M. N. (1971). The predictive-ability criterion: its relevance in evaluating accounting data. Abacus, 1–7. Hansen, J. and W. Messier (1991), “Artificial neural networks: foundations and application to a decision problem”, Expert Systems with Applications, 3: 135–141 Härdle, W.; Moro, R.; Schäfer, D. (2005): Predicting Bankruptcy with Support Vector Machines. SFB 649 Discussion Paper nº 009, 2005. Hing-Ling, A. (1987): A five-state financial distress prediction model. Hotchkiss, E. S.; Mooradian, R. M. (1997): Vulture investors and the market for control of distressed firms, Journal of Financial Economics 43, 401–432. Hotchkiss, E.; Mooradian, R. (1997): Vulture investors and the market for control of distressed firms, Journal of Financial Economics 43, 401–432. Huang, S.; Tsai, C.; Yen, D.; Cheng, Y. (2008): A hybrid financial analysis model for business failure prediction. Expert Systems with Applications 35, pp. 1034–1040. Jiménez, S. (1996): Una evaluación crítica de la investigación empírica desarrollada en torno a la solvencia. Revista Española de Financiación y Contabilidad Vol. XXV, nº 87, pp. 459 – 479. Joy, O; Tollefson, J. (1975): On the financial applications of discriminant analysis. Journal of Financial and Quantitative Analysis Vol. 10, Nº 5, pp. 723-739 Kahl, M. (2002): Economic Distress, Financial Distress, and Dynamic Liquidation. The Journal of Finance Vol. 57, nº 1, pp. 135 – 168. Kane, G., Richardson, F.; Mead, N. (1998). Rank transformation and the prediction of corporate failure. Contemporary Accounting Research, 145–166. 27 Keasey, K. and R. Watson (1987), “Non-Financial Symptoms and the Prediction of Small Company Failure. A Test of Argenti’s Hypotheses”, Journal of Business Finance and Accounting, 14 (3): 335-354. Kennedy, H. A. (1975): A behavioral study of the usefulness of four financial ratios. Journal of Accounting Research Vol. 25, nº 1, pp. 127 – 138. Kim, H.; Sohn, S. (2010). Support vector machines for default prediction of SMEs based on technology credit. European Journal of Operational Research, 201(3), 838–846. Kim, S. (2011): Prediction of hotel bankruptcy using support vector machine, artificial neural network, logistic regression, and multivariate discriminant analysis. The Service Industries Journal Vol. 31, Nº 3, pp. 441–468. Koh, H. and S. Tan (1999), “A neural network approach to the prediction of going concern status”, Accounting and Business Research, 29 (3): 211–216. Lajili, K.; Zéghal, D. (2011): Corporate governance and bankruptcy filing decisions. Journal of General Management Vol. 35, nº 4, pp. 3 – 26. Li, Y.; Chen, Y., Liang, L., Xie, J. (2012): “DEA model for Extended Two-stage Network Structures”, Omega, 40, pp. 611-618. Liu, F.F., Chen, C.L., (2009), “The Worst-Practice DEA Model with Slack-Based Measurement”, Computers & Industrial Engineering Vol. 52, nº 2, pp. 496-505. Liu, J., 2004. Macroeconomic determinants of corporate failures: evidence from the UK. Applied Economics, (36), 939 - 945. Lizarraga, F. (1997). Utilidad de la información contable en el proceso de fracaso: análisis del sector industrial de la mediana empresa española. Revista Española de Financiación y Contabilidad, XXVI (92) 871-915. Lo, A. (1986). Logit versus discriminant analysis: A specification test and application to corporate bankruptcies. Journal of Econometrics, 31, 151-178. Longstaff, f.; Schwartz, E. (1995): A simple approach to valuing risky fixed and floating rate debt. Journal of Finance 50: 789 – 819. Marais, M. L.; Patell, J.; Wolfson, M. (1984): The experimental design of classification models: an application of recursive partitioning and bootstrapping to commercial bank loan classification. Journal of Accounting Research Vol. 22, pp. 87 – 114. Martin, D. (1977): “Early Warning of Bank Failure: a Logit regression approach”. Journal of Banking and Finance. Vol. 1, Núm. 3, pp. 249-276. Martínez, O. (2003). Determinantes de fragilidad en las empresas colombiana. Banco de la República de Colombia, Borradores de Economía 259, 1-24. McKee, T. and T. Lensberg (2002), “Genetic programming and rough sets: a hybrid approach to bankruptcy classification”, European Journal of Operational Research, 138: 436–451. 28 Merton, R. (1974): On the pricing of corporate debt. The risk structure of interest rates. Journal of Finance 29: 449 – 470. Merwin, C. 1942. Financing small corporations in five manufB.cturing industries, 1926- 1936 New York: National Bureau of Economic Research. Messier, W. and J. Hansen (1988), “Inducing rules for expert system development: an example using default and bankruptcy data”, Management Science, 34 (12): 1403– 1415. Modigliani, F.; Miller, M. (1958): The cost of capital, corporation finance, and the theory of investment. American Economic Review Vol. 48, nº 3, pp. 261 – 297. Modigliani, F.; Miller, M. (1963): Corporate Income Taxes and the Cost of Capital: a correction. American Economic Review Vol. 53, nº 3, pp. 433-443. Morris, R. (1997): Early Warning Indicators of Corporate Failure. Aldershot: Ashgate. Moyer, R. C. (1977), “Forecasting Financial Failure: A Reexamination”, Financial Management, 6 (1): 11-17. Nath, R.; Rajagopalan, B.; Ryker, R. (1997): “Determining the saliency of input variables in neural network classifiers. Journal of Computers. 24 (8). Págs. 767-773. Ohlson, J. (1980), “Financial Ratios and Probabilistic Prediction of Bankruptcy”. Journal of Accounting Research, Vol. 18, nº 1, pp. 109 – 131. Parnes, D. (2010): The information content of analysts reports and bankruptcy risk measures. Applied Financial Economics 20, pp. 1499–1513 Peel, M. J.; Peel, D. A. and P. F. Pope (1986), “Predicting Corporate Failure. Some Results for the UK Corporate Sector”, Omega: The International Journal of Management Science, 14 (1): 5-12. Pereira, J.; Basto, M.; Ferreira, A.; Barbas, E. (2011): Propuesta de un modelo de predicción del fracaso empresarial considerando las variables tamaño y antigüedad. XVI Congreso de AECA. Granada. Pindado, J.; Rodrigues, R.; de la Torre, C. (2008): “Estimating Financial Distress Likelihood”. Journal of Business Research Vol. 61, Nº 9, pp. 995–1003. Piñeiro, C.; de Llano, P.; Rodríguez, M. (2012) “La evaluación de la probabilidad de fracaso financiero. Contraste empírico del contenido informacional de la auditoría de cuentas”, Revista Española de Financiación y Contabilidad (AECA), n156, volumen XLI, pp 565588. Piñeiro, C.; de Llano, P.; Rodríguez, M. (2013a): ¿Proporciona la auditoría evidencias para detectar y evaluar tensiones financieras latentes? Un diagnóstico comparativo mediante técnicas econométricas e inteligencia artificial. Revista Europea de Dirección y Economía de la Empresa (próxima publicación) 29 Piñeiro, C.; de Llano, P.; Rodríguez, M. (2013b) “A parsimonious model to forecast financial distress, with base in audit evidences”. Revista Contaduría y Administración (pendiente de publicación). Platt, H. y Platt, M. (2004). Industry-relative ratios revisited: the case of financial distress. Paper presented at the FMA 2004 Meeting, New Orleans (USA), pp. 6-9. Premachandra IM, Bhabra GS, Sueyoshi T. (2009), “DEA as a tool for bankruptcy assessment: a comparative study with logistic regression technique”. European Journal of Operational Research, 193, 412–424. Quinlan, J. R. (1986): “Induction of decision trees”. Machine Learning(1), pp. 81 - 106. Quinlan, J. R. (1993): C4.5: Programs for Machine Learning. Morgan Kaufmann Publishers. Rissanen, J. (1983): “A Universal Prior for Integers and Estimation by Minimum Description Length”, Annals of Statistics, Vol 11, No. 2, 416-431. Rodríguez, M. (2002a): “El fracaso empresarial en Galicia a través del análisis tradicional de la información contable. La capacidad predictiva del análisis univariante”. II Congreso de Economía de Galicia. Rodríguez, M. (2002b): “Modelos de insolvencia en empresas gallegas. Aplicación de Técnicas Paramétricas y de Inteligencia Artificial”. En La gestión del riesgo de crédito. Madrid: AECA, pp. 24 – 59. Rodríguez, M. (2005) “Pruning de las variables en el Modelado Neuronal para la predicción de la insolvencia empresarial y su contraste con el análisis univariante”, IVWS, Sevilla. Rodríguez, M.; Díaz, F. (2005) “La teoría de los Rough Sets y la predicción del fracaso empresarial. Diseño de un modelo para las PYMEs”. XIII Congreso de AECA. Oviedo. Rose, P. S.; Andrews, W. T. and G. A. Giroux (1982), “Predicting Business Failure: A Macroeconomic Perspective”, Journal of Accounting Auditing and Finance, Fall: 20-31. Ross, S. (1976): The arbitrage theory of capital asset pricing. Journal of Economic Theory Vol. 13, Nº 3, pp. 341-360. Sarkar, S., y Sriram, R. (2001). Bayesian models for early warning of bank failures. Management Science, 47(11), 1457–1475. Scott, J. (1977): Bankruptcy, secured debt, and optimal capital structure. Journal of Finance Vol. XXXII, nº 13, No. 1, pp. 1 – 19.97-116 Serrano, C. and B. Martín (1993), “Predicción de la Quiebra Bancaria Mediante el Empleo de Redes Neuronales Artificiales”, Revista Española de Financiación y Contabilidad, 22 (74): 153-176. Sharma, S.; Mahajan, V. (1980): Early warning indicators of business failure. Journal of Marketing, Vol. 44: 80 – 99 30 Shetty, U., Pakkala, T.P.M., Mallikarjunappa, T., (2012), “A Modified Directional Distance Formulation of DEA to Assess Bankruptcy: An Application to IT/ITES Companies in India”, Expert Systems with Applications Vol. 39, nº 2, pp. 1988-1997. Shin, K.; Lee, T.; Kim, H. (2005): An application of support vector machines in bankruptcy prediction model. Expert Systems with Applications (28): 127 – 135. Shumway, T. (2001): “Forecasting Bankruptcy More Accurately: A Simple Hazard Model”, Journal of Business, Vol. 74, N.º 1, January, pp. 101-124 Sinuany-Stern, Z., Friedman, L. (1998), “DEA and the Discriminant Analysis of Ratios for Ranking Units, European Journal of Operational Research Vol. 111, Nº 3, pp. 470-478. Slowinski R. and C. Zopounidis (1995), “Application of the rough set approach to evaluation of bankruptcy risk”, International Journal of Intelligent Systems In Accounting, Finance & Management, 4 (1): 27–41. Sueyoshi, T., Goto, M. (2009a), “Methodological Comparison between DEA (data envelopment analysis) and DEA–DA (discriminant analysis) from the Perspective of Bankruptcy Assessment”, European Journal of Operation Research Vol. 199, nº 2, pp. 561-575. Sueyoshi, T., Goto, M. (2009b), “DEA-DA for Bankruptcy-based Performance Assessment: Misclasification Analysis of Japanese Construction Industry”, European Journal of Operation Research Vol. 199, nº 2, pp. 576-594. Sun, J. and H. Li (2009), “Financial distress early warning based on group decision making”, Computers & Operations Research, 36: 885 – 906. Taffler, R. (1982). Forecasting company failure in the UK using discriminant analysis and financial ratio data. Journal of the Royal Statistical Society, 145, 342-358. Tam, K.; Kiang, M. (1992): Managerial applications of neural networks: the case of bank failure predictions. Management Science Vol. 38, nº 7, pp. 926 - 947 Troutt, M., Rai, A.; Zhang, A. (1996): “The Potential use of DEA for Credit Applicant Acceptance Systems”, Computer & Operations Research Vol 23, Nº 4, pp. 405-408. Tsai, B.; Lee, C.; Sun, L. (2009): The Impact of Auditors’ Opinions, Macroeconomic and Industry Factors on Financial Distress Prediction: An Empirical Investigation. Review of Pacific Basin Financial Markets and Policies Vol. 12, No. 3, pp. 417–454 Tsai, C. (2008). Financial decision support using neural networks and support vector machines. Expert Systems, 25(4), 380–393. Vapnik, V. (1982). Estimation of Dependences Based on Empirical Data. Berlín: Springer Verlag Vapnik, V. y Chervonenkis, A. (1974): Pattern Recognition Theory, Statistical Learning Problems (en ruso). Moscú: Nauka. 31 Vinso, J. (1979): A determination of the risk of ruin. Journal of Financial and Quantitative Analysis Vol. XIV, Nº 1, Marzo, pp. 77 – 100 Wilcox, J. (1971): A simple theory of financial ratios as predictors of failure. Journal of Accounting Research 9, pp. 389 – 395. Wilson, R., y Sharda, R. (1994). Bankruptcy prediction using neural networks. Decision Suport Systems, V 11, Issue 5, June 1994, pp. 545-557. Wu, W.; Siong, V.; Yean, T. (2006): Data preprocessing and data parsimony in corporate failure forecast models: evidence from Australian materials industry. Accounting and Finance 46, pp. 327–345 Xiaosi, X.; Ying, C.; Haitao, Z. (2011): The comparison of enterprise bankruptcy forecasting method. Journal of Applied Statistics Vol. 38, No. 2, 301–308. Yang, Z., Platt, M., y Platt, H. (1999). Probabilistic neural networks in bankruptcy prediction. Journal of Business Research, 44, 67–74. Zavgren, C. (1985). Assessing the vulnerability of failure of American industrial firms: A logistic analysis. Journal of Banking and Finance (Spring), 19-45. DOI: 10.1111/j.14685957.1985.tb00077.x Zmijewski, M. E. (1984), “Methodological Issues Related to the Estimation of Financial Distress Prediction Models”, Journal of Accounting Research Vol. 22, pp. 59-82. 32 33



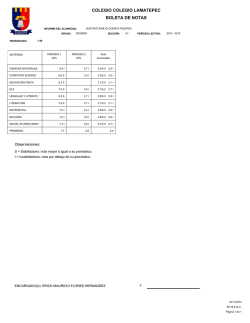

© Copyright 2026