
WEKA - Universidad de Jaén
GESTIÓN DE RECURSOS BIOLÓGICOS
EN EL MEDIO NATURAL
Técnicas de obtención y análisis de datos
Juan Navas Ureña
3.- Minería y análisis de datos con WEKA.
Departamento de Matemáticas
Universidad de Jaén
http:/matema.ujaen.es/jnavas
TEMA 1
Modelos matemáticos discretos en biología de campo
1.- Modelos basados en ecuaciones en diferencias
• La sucesión de Fibonacci.
• Ecuaciones en diferencias.
• Sistemas dinámicos discretos
• Puntos de equilibrio.
• Análisis geométrico. Diagramas de Cobweb
• Modelos nolineales. La ruta hacia el caos
• La geometría fractal
2.- Modelos basados en sistemas de ecuaciones en diferencias
• Modelos matriciales de Leslie y Markov.
• Análisis de datos a través de las tablas de vida y los modelos
matriciales.
• Desarrollo, análisis e interpretación de los modelos matriciales
demográficos matriciales para biología de campo.
3.- Minería y análisis de datos con WEKA.
Minería de datos
• Con la denominada sociedad de la
información se está produciendo un fenómeno
paradójico. Día a día se multiplica la cantidad
de datos almacenados. Sin embargo, esta
explosión de datos no supone un aumento de
nuestro conocimiento, puesto que resulta
imposible procesarlos con los métodos
clásicos.
• Los datos tal cual se almacenan no suelen
proporcionar beneficios directos. Su valor real
reside en la información que podamos extraer
de ellos: información que nos ayude a tomar
decisiones o a mejorar nuestra comprensión de
los fenómenos que nos rodean.
3.- Minería y análisis de datos con WEKA
Minería de datos
• Recientemente han surgido una serie de
técnicas que facilitan el procesamiento
avanzado de los datos y permiten realizar
un análisis en profundidad de los mismos
de forma automática, que se conocen con
el nombre de data mining (minería de
datos). Los datos contienen más
información oculta de la que se ve a
simple vista; de ahí la metáfora de la mina.
• La minería de datos o exploración de
datos es un campo de las ciencias de la
computación, referido al proceso que
intenta descubrir patrones en grandes
volúmenes de conjuntos de datos.
3.- Minería y análisis de datos con WEKA
WEKA
• WEKA =(Waikato Environment for
Knowledge Analysis) es una extensa
colección de algoritmos de Máquinas de
Conocimiento desarrollados por la
universidad de Waikato (Nueva Zelanda)
implementados en Java.
• Contiene las herramientas necesarias
para realizar transformaciones sobre los
datos, tareas de clasificación, regresión,
agrupamiento, asociación y visualización.
• Está diseñado para añadir nuevas
herramientas de una manera sencilla.
WEKA
• Una vez que WEKA esté en ejecución
aparecerá una ventana denominada selector
de interfaces que nos permite seleccionar la
interfaz con la que deseemos comenzar a
trabajar.
• Simple CLI (command line interface):
interfaz en modo texto.
• Explorer: interfaz gráfico básico.
• Experimenter:
interfaz
gráfico
con
posibilidad de comparar el funcionamiento
de diversos algoritmos de aprendizaje
• KnowledgeFlow: interfaz gráfico que
permite interconectar distintos algoritmos
de aprendizaje en cascada, creando una red.
WEKA
WEKA
• El modo Explorador es el modo más usado y más descriptivo. Éste
permite procesar, clasificar, asociar y visualizar datos de una manera fácil e
intuitiva sobre un sólo archivo de datos.
WEKA
Explorer: procesamiento de datos
•
Los datos pueden extraerse desde un arhivo en varios formatos:
ARFF, CSV, C4.5, binary,……..
•
También pueden leerse desde una URL
•
Las herramientas de pre-procesamiento en WEKA se llaman
filtros. WEKA contiene filtros para la discretización,
normalización, reemplazamiento y combinación de atributos, etc.
WEKA
Explorer: procesamiento de datos
•
•
•
•
•
•
PREPROCESS: visualización y preprocesado de datos (aplicación
de filtros)
CLASSIFY: Aplicación de algoritmos de clasificación y regresión
CLUSTER: Agrupamiento
ASSOCIATE: Asociación
SELECT ATRIBUTES: Selección de atributos
VISUALIZE: Visualización de datos por parejas de atributos
WEKA
FICHEROS .arff
• WEKA trabaja con un formato denominado arff , acrónimo de AttributeRelation File Format. Este formato está compuesto por una estructura
claramente diferenciada en tres partes:
1.- Cabecera. Se define el nombre de la relación. Su formato es el siguiente:
@relation <nombre-de-la-relación>
2.- Declaraciones de atributos. En esta sección se declaran los atributos
que compondrán nuestro archivo junto a su tipo. La sintaxis es la
siguiente:
@attribute <nombre-del-atributo> <tipo>
WEKA
WEKA
3.- Sección de datos. Declaramos los datos que componen la relación
separando entre comas los atributos y con saltos de línea las relaciones.
@data
4,3.2
• En el caso de que algún dato sea desconocido se expresará con un
símbolo de cerrar interrogación (“?").
• Es posible añadir comentarios con el símbolo “ %”, que indicará que
desde ese símbolo hasta el final de la línea es todo un comentario. Los
comentarios pueden situarse en cualquier lugar del fichero.
1.3.- MineríaW
deEdatos
KA
Comentario
Nombre archivo
Cabecera
Declaraciones de atributos
Sección de datos
WEKA
• Se trata de una base de
datos en la que se
pretende
determinar
cuáles son los factores que
hacen que una cierta
persona practique o no el
tenis.
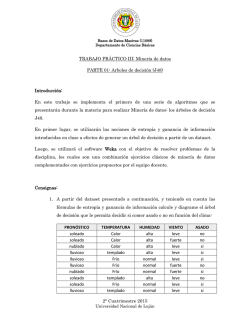
EJEMPLO DE UTILIZACIÓN DE WEKA
WEKA
• Se pretende determinar cuáles son los factores que hacen que una
cierta persona practique o no el tenis.
• Cada instancia de la base de datos se corresponde con un cierto día en
el que la persona se plantea si jugar o no al tenis, y recoge los
siguientes atributos:
•
•
•
•
•
Aspecto del cielo: {soleado, cubierto, lluvioso}.
Temperatura: medida en grados.
Humedad: medida en %
Viento: {si, no}
Juega al tenis: {si, no}
• Se dispone de datos recogidos durante 14 días distintos, y el objetivo es
determinar cuál es la relación entre las condiciones del tiempo y la
decisión de jugar o no al tenis.
EJEMPLO DE UTILIZACIÓN DE WEKA
WEKA
•
La base de datos (archivo .arff) está incluida en el programa
EJEMPLO DE UTILIZACIÓN DE WEKA
WEKA
• Para cargar la base de datos se utilizará el botón OPEN FILE del interfaz
Explorer (pestaña Preprocess), se seleccionará el directorio data y dentro
de él, el fichero weather.arff.
Se muestra
información sobre
cada atributo en la
parte derecha de la
ventana. En el caso de
atributos discretos se
indica el número de
instancias que toman
cada uno de los
valores posibles; y en
el caso de atributos
reales se muestran los
valores máximo,
mínimo, medio y la
desviación estándar.
Asimismo, se muestra
un gráfico
EJEMPLO DE UTILIZACIÓN DE WEKA
WEKA
Para generar
gráficos con los
datos del ejemplo,
se seleccionará la
pestaña Visualize.
Por defecto, se
muestran gráficos
para todas las
combinaciones de
atributos tomadas
dos a dos, de
modo que se
pueda estudiar la
relación entre dos
atributos
cualesquiera
EJEMPLO DE UTILIZACIÓN DE WEKA
WEKA
ALGORITMOS DE CLASIFICACIÓN
• WEKA cuenta con una gran variedad de algoritmos de
clasificación entre los que destacan los métodos bayesianos
(AODE, Bayes Net, Naive Bayes, Naive Bayes Simple, Naive Bayes
Multinomial, etc.), las reglas de clasificación (Tablas de Decisión,
Nnge, OneR, PART, Ridor, ZeroR, etc.), los métodos de regresión
(Regresión Lineal, Regresión Logística, etc.) y los árboles de
decisión (ADTree, Decisión Stump, ID3, J48, LMT, Random Forest,
Random Tree, REP Tree, etc.).
EJEMPLO DE UTILIZACIÓN DE WEKA
WEKA
EL ALGORITMO J48
• El algoritmo J4.8 induce árboles de decisión. Es la implementación
en WEKA del algoritmo C4.5 revisión 8, la cual fue la última versión
pública de esta familia de algoritmos, posteriormente apareció la
primera implementación comercial, es decir, el algoritmo C5.0.
Dentro de las opciones que J4.8 soporta están:
• La poda de árboles
• La especificación de factores de confianza para la poda
• La especificación de un mínimo de instancias en las hojas
• La poda de árboles con error reducido
• La especificación del número de datos en podas con error reducido
• El uso de particiones binarias en atributos nominales
EJEMPLO DE UTILIZACIÓN DE WEKA
WEKA
GENERACIÓN DE UN ÁRBOL DE DECISIÓN
Se seleccionará la
pestaña Classify y se
elegirá un clasificador
pulsando el botón
Choose. Aparecerá
una estructura de
directorios en la que
se seleccionará el
directorio trees y
dentro del él el
algoritmo J48. Se
mantendrán las
opciones por defecto
del clasificador
EJEMPLO DE UTILIZACIÓN DE WEKA
WEKA
El resto de
opciones para el
experimento
también se
mantendrán en los
valores por
defecto: activa la
opción de test
‘cross validation’ e
inactivas las
restantes. Para
generar el árbol se
pulsará Start.
EJEMPLO DE UTILIZACIÓN DE WEKA
WEKA
• En primer lugar, se muestra información sobre el tipo de
clasificador utilizado (algoritmo J48), la base de datos sobre la
que se trabaja (weather) y el tipo de test (cross validation).
EJEMPLO DE UTILIZACIÓN DE WEKA
WEKA
• A continuación se muestra el árbol que se ha generado y el número de
instancias que clasifica cada nodo:
EJEMPLO DE UTILIZACIÓN DE WEKA
WEKA
• Y por ultimo se muestran los resultados del test (indican la capacidad de
clasificación esperable para el árbol y la matriz de confusión):
EJEMPLO DE UTILIZACIÓN DE WEKA
WEKA
También
es
posible
visualizar el árbol de
decisión de una forma más
legible. Para ello se debe
hacer clic con el botón
derecho en la ventana de
resultados,
sobre
el
resultado de la generación
del árbol. Aparecerá un
menú desplegable: Y dentro
de ese menú se deberá
seleccionar
la
opción
‘Visualize tree’.
EJEMPLO DE UTILIZACIÓN DE WEKA
WEKA
EJERCICIO PROPUESTO
• Crear un fichero para WEKA con datos sobre la posibilidad de fallo de una
máquina en función de ciertos atributos medidos: vibraciones,
temperatura, tiempo desde la última revisión y horas de funcionamiento.
EJEMPLO DE UTILIZACIÓN DE WEKA
WEKA
EJERCICIO PROPUESTO
• Crear un fichero para WEKA con datos sobre la posibilidad de fallo de una
máquina en función de ciertos atributos medidos: vibraciones,
temperatura, tiempo desde la última revisión y horas de funcionamiento.
1. Crear un fichero con los datos anteriores en formato WEKA y
guardarlo con la extensión .arff
2. En la cabecera del fichero debe aparecer la línea:
@relation XXXX_YYYY_ZZZZ… donde XXXX, YYYY y ZZZZ deben ser
el nombre y apellidos del alumno.
3. Abrir el fichero .arff creado desde WEKA y generar un árbol de
decisión sobre esos datos. Copiar en el informe tanto el resultado
ofrecido en modo texto como la representación gráfica del árbol de
decisión.
EJEMPLO DE UTILIZACIÓN DE WEKA




© Copyright 2026