
Descargar memorias - CITIC - Universidad de Costa Rica
II JORNADAS COSTARRICENSES DE INVESTIGACIÓN EN COMPUTACIÓN E INFORMÁTICA OBJETIVO DE LAS JORNADAS Las II Jornadas Costarricenses de Investigación en Computación e Informática tienen como objetivo difundir la investigación realizada en estas áreas entre la comunidad científica, académica y estudiantil del país. Se espera que se conviertan en un espacio no solo de divulgación sino de encuentro y construcción de redes de investigadores en temas de interés para la comunidad nacional. COMITÉ DEL PROGRAMA Dra. Gabriela Barrantes (UCR, Costa Rica) MSc. Marta Calderón (UCR, Costa Rica) Dr. Arturo Camacho (UCR, Costa Rica) Dra. Yudith Cardinale (USB, Venezuela) Dra. Ileana Castillo (UCR, Costa Rica) Dr. Carlos Castro (UCR, Costa Rica) Dr. Roberto Cortés (TEC, Costa Rica) Dra. Mayela Coto (UNA, Costa Rica) Dr. Ernesto Cuadros (Universidad Católica San Pablo, Perú) Dr. Cesar Garita (TEC, Costa Rica) Dr. Luis Guerrero (UCR, Costa Rica) Dr. Marcelo Jenkins (UCR, Costa Rica) Dr. Ernst Leiss (University of Houston, USA) Dr. Fulvio Lizano (UNA, Costa Rica) Dra. Elzbieta Malinowski (UCR, Costa Rica) Dra. Gabriela Marín (UCR, Costa Rica) Dr. Francisco Mata (UNA, Costa Rica) Dra. Alexandra Martínez (UCR, Costa Rica) Dr. Esteban Meneses, (Universidad de Pittsburgh, Estados Unidos) Dr. Oscar Pastor (Universitat Politècnica de València, España) Dr. Ramon Puigjaner (Universitat de les Illes Balears, España) Dr. Leonid Tineo (USB, Venezuela) Dr. Francisco Torres (TEC, Costa Rica) Dr. Juan José Vargas (UCR, Costa Rica) Dr. Ricardo Villalón (UCR, Costa Rica) COMITÉ ORGANIZADOR Dra. Gabriela Marín (UCR, Costa Rica) Dra. Alexandra Martínez (UCR, Costa Rica) Dr. Luis Guerrero (UCR, Costa Rica) Dr. Vladimir Lara (UCR, Costa Rica) EDITORES M. Sc. Gustavo López (UCR, Costa Rica) Dra. Gabriela Marín (UCR, Costa Rica) © CITIC - PCI Universidad de Costa Rica. Se autoriza hacer copias de este trabajo o partes de él para uso académico, siempre y cuando sea sin fines de lucro. La copia debe contener esta nota y la cita completa en la primera página. La copia bajo otras circunstancias y la distribución o publicación podría requerir permisos adicionales o pago de derechos. TABLA DE CONTENIDOS Comparación de cobertura de rama por los algoritmos SwiftHand y Random: un caso de estudio............................... 1 Abel Méndez-Porras, Giovanni Méndez-Marín y Marcelo Jenkins Testing Strategy for Acceptance and Regression Testing of Outsourced Software....................................................... 5 Gustavo López, Alexandra Martínez y Marcelo Jenkins Propuesta de incorporación de pruebas unitarias a un sistema de código legado usando Microsoft Fakes. ................. 9 Mario Barrantes y Alexandra Martínez Un caso de estudio de aplicación del estándar de OWASP para verificación de la seguridad de aplicaciones............ 13 Enrique Brenes y Alexandra Martínez Construyendo conciencia sobre amenazas a la privacidad............................................................................................. 17 Luis Gustavo Esquivel Quirós y Elena Gabriela Barrantes Sliesarieva Diseño de un proceso de certificación para actores del Sistema Nacional de Certificación Digital de Costa Rica....... 21 Alejandro Mora Castro, Rodrigo A. Bartels y Ricardo Villalón Fonseca Comprensión de la máquina nocional a través de enseñanza tradicional....................................................................... 25 Jeisson Hidalgo-Céspedes, Gabriela Marín-Raventós y Vladimir Lara-Villagrán Representación de estrategias en juegos utilizando un modelo del conocimiento......................................................... 29 Juan Carlos Saborío y Álvaro de la Ossa Modelo u-CSCL basado en la Ingeniería de la Colaboración........................................................................................ 33 Mayela Coto, Sonia Mora, Alexander Moreno, Maria Fernanda Yandar y César A. Collazos A Political Sentiment Analysis System using Spanish Postings.................................................................................... 37 Edgar Casasola Murillo y Gabriela Marín Raventos Plataforma para el reconocimiento facial: aspectos de percepción y cognición social.................................................. 41 Janio Jadán-Guerrero, Kryscia Ramírez y Shirley Romero Bonilla Diseño de una interfaz para la evaluación del rango articular en terapias tumbadas..................................................... 45 Kaiser Williams, Karla Arosemena, Christopher Francisco y Eric De Sedas Troyóculus: Gafas electrónicas para potenciar la visón de personas con problemas de visión baja.............................. 49 Paúl Fernández Barrantes y Adrián Fernández Malavasi Improving the performance of OpenFlow Rules Interactions Detection........................................................................ 52 Oscar Vasquez-Leiton, J. de Jesus Ulate-Cardenas y Rodrigo Bogarin Metodología CNCA de Servicios de Computación Científica de Alto Rendimiento..................................................... 56 Alvaro de la Ossa, Daniel Alvarado, Renato Garita, Ricardo Román, Juan C. Saborío, Andrés Segura Uso de simulaciones para encontrar el número y rango óptimos de los retrasos en un modelo computacional de la sensación de altura basado en la autocorrelación........................................................................................................... 60 Sebastián Ruiz Blais y Arturo Camacho Cancelación del Ruido de Ambiente en Grabaciones de Vocalizaciones de Manatíes Antillanos................................ 64 Jorge Castro, Arturo Camacho y Mario Rivera Detección de voces y otros ruidos en ambientes de trabajo y estudio............................................................................ 68 Juan Fonseca Solís Reconocimiento automático de acordes musicales usando un enfoque holístico........................................................... Arturo Camacho 72 1 Comparación de cobertura de rama por los algoritmos SwiftHand y Random: un caso de estudio Abel Méndez-Porras Instituto Tecnológico de Costa Rica Universidad de Costa Rica [email protected] Giovanni Méndez-Marı́n Instituto Tecnológico de Costa Rica [email protected] RESUMEN Para realizar pruebas de software automáticas en aplicaciones móviles, una técnica empleada es la creación de un modelo de la aplicación a partir de su interfaz gráfica. Esta técnica presenta dos desafı́os: la creación de un modelo de calidad y la exploración de la aplicación a partir de dicho modelo. Dos algoritmos existentes para explorar dichos modelos son el algoritmo SwiftHand y el algoritmo Random. En este trabajo se comparan ambos algoritmos, con el objetivo de saber cual algoritmo ofrece mejor exploración del modelo de la aplicación, mediante el uso de la métrica de cobertura de rama. Un aspecto clave para la cobertura de rama es la cantidad de veces que la aplicación debe ser reiniciada. Reiniciar la aplicación es una operación significativamente más costosa en tiempo y recursos computacionales, que la ejecución de la aplicación con una secuencia de entradas. Los resultados demuestran que el algoritmo SwiftHand logra una mejor cobertura de rama que el algoritmo Random. Además, el algoritmo SwiftHand requiere reiniciar la aplicación menos veces que el algoritmo Random. INTRODUCCIÓN La calidad de las aplicaciones móviles es más baja de lo esperada. Según Amalfitano y Fasolino [2] la falta de calidad de las aplicaciones móviles se debe a procesos de desarrollo rápidos, donde la actividad de pruebas de software se descuida o se lleva a cabo de una manera superficial. Realizar pruebas de software a una aplicación móvil es una tarea compleja. Las aplicaciones móviles reciben una variedad de entradas de usuario, de contexto y entorno que influyen en su funcionamiento y deben ser probadas con el fin de encontrar fallos en la aplicación. Estudios recientes resaltan la importancia de tomar en cuenta el contexto en que las aplicaciones móviles operan, en el proceso de pruebas de software para asegurar su calidad [7, 8, 1]. Los usuarios de aplicaciones móviles cada dı́a son más exigentes con la calidad de las aplicaciones que utilizan. Para hacer frente a la creciente demanda de aplicaciones móviles de alta calidad, los desarrolladores deben dedicar más esfuerzo y atención en los procesos de desarrollo de software. En parSe autoriza hacer copias de este trabajo o partes de para uso académico, siempre y cuando sea sin fines de lucro. La copia debe contener esta nota y la cita completa en la primera página. La copia bajo otras circunstancias y la distribución o publicación podrı́a requerir permisos adicionales o pago de derechos. JOCICI’15, Marzo 5-6, San José, Costa Rica. c Copyright 2015 CITIC-PCI Marcelo Jenkins CITIC, Universidad de Costa Rica [email protected] ticular, las pruebas de software y la automatización de éstas, juegan un papel estratégico para garantizar la calidad de las aplicaciones móviles. Para afrontar la problemática de las pruebas de software automáticas en aplicaciones móviles, se han propuesto varias técnicas. Estas técnicas han sido clasificadas en pruebas de software aleatorias, pruebas de software basada en modelos, pruebas de software que aprenden un modelo y pruebas sistemáticas [5, 6]. Basado en las anteriores técnicas, se han desarrollado herramientas para pruebas de software automáticas [3, 4, 5, 6]. Sin embargo, se ha realizado poca validación empı́rica de los resultados que estas herramientas proporcionan. Dada la relevancia de las aplicaciones móviles en las tareas cotidianas de los humanos y la poca experimentación que se ha realizado con las herramientas para pruebas de software automáticas en aplicaciones móviles, es que se plantea el diseño y ejecución de un caso de estudio. En dicho caso de estudio se desea comparar el algoritmo SwiftHand y algoritmo Random, implementados en la herramienta SwiftHand [5]. En este estudio se aborda la siguiente pregunta: ¿El algoritmo SwiftHand y el algoritmo Random exploran el mismo porcentaje de ramas de un modelo? HERRAMIENTA PARA PRUEBAS DE SOFTWARE AUTOMÁTICAS SwiftHand [5] es una herramienta de pruebas de software automáticas para aplicaciones móviles en Android. Esta implementado utilizando los lenguajes de programación Java y Scala. Este entorno tiene implementadas varias técnicas para realizar recorridos sobre el modelo de la aplicación bajo prueba. Dos de estas técnicas son el algoritmo SwiftHand y el algoritmo Random, mismos que son comparados en este trabajo. Algoritmo SwiftHand El algoritmo SwiftHand, genera secuencias de entradas de prueba para aplicaciones de Android. La técnica utiliza aprendizaje de máquina para aprender un modelo de la aplicación durante la prueba de software. Utiliza el modelo aprendido para generar entradas de usuarios para visitar estados inexploradas de la aplicación, y utiliza la ejecución de la aplicación con las entradas generadas para refinar el modelo. Una caracterı́stica clave del algoritmo es que evita reiniciar la aplicación. Reiniciar la aplicación es una operación significativamente más costosa en tiempo y recursos computacionales, Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) que la ejecución de la aplicación con una secuencia de entradas. Q es un conjunto de estados, Algoritmo Random Σ es un alfabeto de entrada, El algoritmo Random realiza las pruebas de software a una aplicación móvil, seleccionando al azar una entrada de usuario del conjunto de entradas habilitadas en cada estado y ejecuta la entrada seleccionada. En las pruebas al azar se reinicia la aplicación en cada estado con cierta probabilidad. COBERTURA DE RAMA La cobertura de rama mide para cada bifurcación o rama (por ejemplo bucles o condicionales), si cada rama ha sido ejecutada al menos una vez durante la prueba. Esta medida se compone de dos valores especı́ficos: la cobertura final, y la velocidad de cobertura. Dichos valores se utilizan para saber si un algoritmo es más eficiente que otro. La cobertura final, permite saber si un algoritmo cubre más bifurcaciones que otro. En este caso, se mide ejecutando la herramienta SwiftHand sobre una misma aplicación durante el mismo periodo de tiempo, con diferentes técnicas (para este estudio, el algoritmo SwiftHand y el algoritmo Random). 2 q0 ∈ Q es el estado inicial, δ : Q × Σ → Q es una función parcial de transición de estados λ : Q → ℘(Σ) es una función de etiquetado de estados. λ(Q) denota el conjunto de entradas válidas en el estado q, y para cualquier q ∈ Q y a ∈ Σ, si existe un p ∈ Q tal que δ(q, a) = p, entonces a ∈ λ(q). APLICACIONES UTILIZADAS EN EL CASO DE ESTUDIO En la tabla 1 se listan las aplicaciones a las que se le realizaron las pruebas. Para las aplicaciones Music Note, Mileage y Tippy Tipper se utilizó el archivo (.apk) disponible en la carpeta de benchmark de la herramienta SwiftHand, el cual ya se encontraba instrumentado por los desarrolladores. Estas tres aplicaciones fueron seleccionadas porque para éstas ya existı́a un reporte de cobertura de rama [5], el objetivo era comparar y confirmar los resultados. Las restantes tres aplicaciones fueron descargadas de F-Droid (https://f-droid.org) y luego fueron instrumentadas utilizando el script para instrumentalización que viene junto con la herramienta. Cuadro 1. Aplicaciones utilizadas en el caso de estudio Nombre Categorı́a aSQLiteManager Cliente para bases de datos SQLite Blokish Juego de tablero Jamendo Reproductor de música en lı́nea Mileage Gestión de vehı́culos Music Note Juego educacional Tippy Tipper Calculador de tips Tamaño (KBs) 606,6 827,4 552,3 225 MODELO DE LA APLICACIÓN M = (Q, q0 ,Σ, δ, λ) donde En la figura 1 se muestra parte del modelo generado para la aplicación Tippy Tipper mediante el algoritmo SwiftHand, en el cual cada nodo representa un estado de la aplicación, que suele ser gráficamente representable mediante su GUI. El estado q0 está representado por el nodo marcado con el número 1. Las aristas representan las transiciones. Junto a cada arista se muestra una o más etiquetas, las cuales indican cual fue el elemento de la interfaz gráfica que invocó a ese evento. RESULTADOS 525,3 638 La herramienta SwiftHand genera un fichero que representa un modelo ELTS (Extended Deterministic Labeled Transition Systems) el cual representa los estados de la aplicación y las transiciones a través de eventos. Formalmente, un ELTS es una tupla Figura 1. Fragmento del grafo de la aplicación Tippy Tipper generado con la herramienta SwiftHand. Cuadro 2. Cobertura de ramas 10 min. 30 min. 180 min. Aplicación SH R SH R SH R aSQLiteManager 625 207 329 310 1022 384 Blokish 334 324 336 327 336 327 Jamendo 1384 854 1684 841 1607 585 Mileage 1402 672 1709 1078 2403 1073 Music Note 72 72 72 66 72 54 Tippy Tipper 661 451 739 503 749 599 SH=SwiftHand R=Random min=minutos Para cada algoritmo (SwiftHand y Rancom) se realizaron pruebas de software de 10, 30 y 180 minutos. Cada aplicación fue ejecutada 3 veces en los tres tiempos (10, 30 y 180 minutos). La tabla 3 muestra el promedio de ramas cubiertas para cada aplicación por el algoritmo SwiftHand como el algoritmo Random. El total de ramas de cada aplicación Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) Figura 2. Cobertura de rama para Mileage. Figura 5. Cobertura de rama para aSQLiteManager. Figura 3. Cobertura de rama para Music Note. Figura 6. Cobertura de rama para Blokish. Figura 4. Cobertura de rama para Tippy Tipper Figura 7. Cobertura de rama para Jamendo. es: aSQLiteManager=2990, Blockish=1082, Jamendo=3451, Mileage=9672, Music Note =245 y Tippy Tipper=1076. Para la aplicación Mileage, el algoritmo SwiftHand mejoró la cobertura de rama cuando el tiempo dedicado a las pruebas 3 fue mayor (figura 2). Además, para esta aplicación el algoritmo SwiftHand mostró mayor cobertura a mayor tiempo dedicado a la prueba. La cobertura de rama para la aplicación Music Note, con el algoritmo SwiftHand, se mantuvo cons- Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) tante para los tres ciclos de pruebas. Con el algoritmo Random, decrementó la cobertura con las pruebas de 30 minutos y decrementó más con las pruebas de 180 minutos (figura 3). Para la aplicación Tippy Tipper, el algoritmo SwiftHand logró una mayor cobertura de ramas que algoritmo Random (figura 4). Comparando con los resultados reportados en [5] para estas tres aplicaciones, la cobertura para Tippy Tipper y Mileage fue muy similar. Sin embargo, para Music Note los resultados reportados en [5] dieron una mejor cobertura. Para la aplicación aSQLiteManager mostraron menor cobertura las pruebas de 30 minutos con el algoritmo SwiftHand. Sin embargo, para las pruebas de 180 minutos con este mismo algoritmo la cobertura aumento considerablemente (figura 5). Las pruebas realizadas a la aplicación Blokish mostraron una cobertura de rama similar para 10 minutos, 30 minutos y 180 minutos (figura 6).Las pruebas para la aplicación Jamendo mostraron una superioridad del algoritmo SwiftHand con respecto al algoritmo Random (figura 7). Reiniciar una aplicación mientras esta siendo explorada tiene una duración de 5 segundos, en promedio. La tabla 3 muestra el promedio de veces que fue necesario reiniciar cada aplicación utilizando el algoritmo SwiftHand y el algoritmo Random. El algoritmo Random introduce un costo adicional en tiempo mayor al algoritmo SwiftHand, debido a la cantidad de veces más que debe reiniciar la apliciación mientras realiza las pruebas de software. Cuadro 3. Cantidad de veces que se reinició las aplicaciones 10 min. 30 min. 180 min. Aplicación SH R SH R SH R aSQLiteManager 3 18 5 47 7 139 Blokish 6 18 14 47 98 343 Jamendo 5 17 8 45 33 353 Mileage 5 16 12 40 47 307 Music Note 5 20 14 56 121 352 Tippy Tipper 2 21 4 52 55 342 SH=SwiftHand R=Random min=minutos CONCLUSIONES Se realizó una comparación entre el algoritmo SwiftHand y el algoritmo Random, mediante la métrica de cobertura de rama. Para cada algoritmo se realizaron pruebas de software de 10, 30 y 180 minutos a 6 aplicaciones. Cada aplicación fue ejecutada 3 veces en los tres tiempos (10, 30 y 180 minutos). Además, se registró la cantidad de veces que los algoritmos requirieron reiniciar la aplicación durante cada prueba. El algoritmo SwiftHand para las 6 aplicaciones logró mayor cobertura de rama que el algoritmo Random. Para lograr un mejor rendimiento en tiempo durante la exploración, es necesario reiniciar la aplicación la mı́nima cantidad de veces. El estudio demuestra que el algoritmo SwiftHand, efectivamente, es más eficiente que el algoritmo Random con respecto a las veces que requiere reiniciar la aplicación. En primer lugar, SwiftHand necesita reiniciar una cantidad mucho menor de veces la aplicación, según las pruebas llevadas a cabo. En segundo lugar, esta cantidad disminuye conforme 4 aumenta el tiempo de ejecución para la exploración de las aplicaciones. Tener modelos completos resultarı́a útil para perfeccionar la metodologı́a de generación de casos de prueba, pero esto es una tarea no trivial que actualmente se encuentra en proceso de investigación. Sin embargo, el algoritmo SwiftHand, ofrece una cobertura de rama de calidad que permite realizar pruebas de software automáticas, con costos de tiempo y recursos computaciones acorde a las prestaciones actuales de la tecnologı́a. TRABAJOS FUTUROS Se está diseñando un caso de estudio para comparar la cobertura de actividades y métodos alcanzados por las herramientas SwiftHand, A3 E [4] y MobiGUITAR [3]. Además, se esta desarrollando una herramienta para pruebas de software automáticas basada en el algoritmo SwiftHand. REFERENCIAS 1. Amalfitano, D., Fasolino, A., Tramontana, P., y Amatucci, N. Considering context events in event-based testing of mobile applications. In Proceedings - IEEE 6th International Conference on Software Testing, Verification and Validation Workshops, ICSTW 2013 (2013), 126–133. cited By (since 1996)0. 2. Amalfitano, D., Fasolino, A., Tramontana, P., De˜Carmine, S., y Memon, A. Using gui ripping for automated testing of android applications. In 2012 27th IEEE/ACM International Conference on Automated Software Engineering, ASE 2012 - Proceedings (2012), 258–261. cited By (since 1996)20. 3. Amalfitano, D., Fasolino, A., Tramontana, P., Ta, B., y Memon, A. Mobiguitar – a tool for automated model-based testing of mobile apps. Software, IEEE PP, 99 (2014), 1–1. 4. Azim, T., y Neamtiu, I. Targeted and depth-first exploration for systematic testing of android apps. ACM SIGPLAN Notices 48, 10 (2013), 641–660. cited By (since 1996)0. 5. Choi, W., Necula, G., y Sen, K. Guided gui testing of android apps with minimal restart and approximate learning. ACM SIGPLAN Notices 48, 10 (2013), 623–639. cited By (since 1996)0. 6. Machiry, A., Tahiliani, R., y Naik, M. Dynodroid: An input generation system for android apps (2013). 224–234. cited By (since 1996)5. 7. Muccini, H., Di˜Francesco, A., y Esposito, P. Software testing of mobile applications: Challenges and future research directions. In 2012 7th International Workshop on Automation of Software Test, AST 2012 - Proceedings (2012), 29–35. cited By (since 1996)1. 8. Wang, Z., Elbaum, S., y Rosenblum, D. Automated generation of context-aware tests. In Software Engineering, 2007. ICSE 2007. 29th International Conference on (2007), 406–415. 5 Testing Strategy for Acceptance and Regression Testing of Outsourced Software Gustavo López CITIC, UCR San José, Costa Rica [email protected] Alexandra Martínez, Marcelo Jenkins ECCI, UCR San José, Costa Rica {alexandra.martinez, marcelo.jenkins}@ecci.ucr.ac.cr ABSTRACT This paper proposes a strategy for acceptance and regression testing of outsourced software, which uses two testing approaches: exploratory testing and automated user interface testing based on boundary value analysis. This strategy is carried out by two tester a senior and a junior tester, leveraging the experience of the first and the low cost of the latter. The proposed strategy was implemented in the context of a university unit that outsourced a web based application. The results from this implementation support our strategy. However, more implementations are required to fully assess its effectiveness. Author Keywords Software testing, outsourced software, acceptance testing, regression testing, exploratory testing, automated testing. INTRODUCTION The importance of software testing within the software development lifecycle is well understood. However, there may be scenarios where the role and scope of software testing is not clear, for example, non-IT organizations that outsource software. The problem is that in non-IT organizations it is unlikely that the staff can adequately perform software testing tasks. This research was conducted in the context of a unit within the University of Costa Rica that outsourced a system. By the time the unit's IT Department contacted us, they had already accepted the first version of the system with only a few acceptance tests ran by domain experts from the unit. When the system was released, a number of nonconformities were exposed and listed on a fix requests backlog for the next version of the software. We were asked to help this unit in developing a software testing strategy fit for its needs, which could be applied in future outsourcings. This paper proposes a strategy for acceptance and regression testing of outsourced software, based on exploratory testing and automated user interface (UI) testing that uses Permission to make digital or hard copies of all or part of this work for academic use is granted, provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, to republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. JoCICI 2015, March 5-6, 2015, San José, Costa Rica. Copyright © 2015 CITIC-PCI boundary value analysis (BVA) underneath. The strategy was designed under the assumption of a limited budget, and with the aim of providing a highly effective and efficient strategy to test outsourced software across multiple releases, so that it would work both for acceptance testing of the first release as well as for regression testing of subsequent maintenance releases. BACKGROUND & RELATED WORK Validation and Verification processes usually costs 50% of the overall development and maintenance budget [1]. Selecting the appropriate technique to reach the required quality level within cost restrictions is currently a challenge. Software testing is an empirical technical investigation carried out to provide stakeholders with information about a software product`s quality [2]. Kanner et al. [3] state that the main goal of software testing is to find problems in software, and that a test case is successful when it finds an error. Software testing best practices are present in literature since the 1980’s. The first recommendations proposed an orderly planning and organization of software and test design, the use of assertion points and full documentation of the process [4]. Researchers and practitioners have since contributed with theoretical advances and empirical studies on how to better perform software testing. An interesting work on non-IT testers was developed by Arnicane [5]. She found that non-IT testers have the following common characteristics: (1) they perform functional testing intuitively, (2) they are afraid of destroying the system, (3) they intuitively use boundary values and partitioning data in equivalence classes, (4) they cannot work with a database, and (5) they use data that are close to reality, among others. The author concludes that non-IT testers can best be used in combination with professional IT testers because they complement one another [5]. This claim provides support for our strategy since it uses IT specialists for exploratory testing and non-IT specialists or IT beginners for a more basic type of testing. Acceptance and regression testing are levels of testing that our strategy targets. Acceptance testing is a formal testing conducted to determine whether or not a system satisfies its acceptance criteria, which enables the customer or other authorized entity to determine whether to accept the system [6]. On the other hand, regression testing refers to the selective retesting of a system in order to verify that changes Proceedings of the II Costa Rican Workshop on Computer Science and Informatics (JoCICI 2015) made have not caused unintended effects, and that the system still complies with its specified requirements [7]. Regression testing is expensive and is used to revalidate software as it evolves. Many studies have been conducted to provide a cost-effective approach to regression testing, however, few of them were carried out in real industrial settings. Rothermel et al. [8] presented cost-benefit tradeoffs associated with regression testing and identified some factors that affect the cost of applying this technique. Engström and Runeson [9] concluded from a qualitative survey that regression testing needs and practices vary greatly depending on the organization and project. Moreover, they state that the main challenges of regression testing are related to test automation and testability of the software. Exploratory and automated UI testing are testing types, whereas boundary value analysis (BVA) is a testing technique, all of them are at the core of our strategy. Exploratory testing [3] is defined as simultaneous learning, test design and test execution [10]. Some studies have focused on the influence of tester knowledge and personality when using exploratory testing to find bugs [11]. Itkonen et al. [11] identified three categories of knowledge used by testers when doing exploratory testing: domain knowledge, system knowledge, and general software engineering knowledge. In the context of our research, the domain knowledge is civil engineering, materials and models, whereas the system knowledge is laboratories administration and organization. In the strategy we propose, exploratory testing is done by senior testers with ample knowledge on software engineering. On the other hand, UI testing consists in exercising an application’s graphical user interface in order to verify that the interaction between the user and the application is correct. In many cases, UI tests are actually functional tests that make use of the graphical user interface and in the process they test UI controls, messages, etc. Manual UI tests can be automated using automation tools that provide record and playback capabilities combined with assertions. Finally, BVA consists in exercising the application with ‘boundary values’, which are those directly on, above and beneath the edges of equivalence classes identified from the specification. Experience shows that tests that explore boundary conditions have a higher payoff than those that do not [12]. BVA can be used for functional testing [12]. PROPOSED STRATEGY We devised a strategy for non-IT units to test outsourced software, which could help them take better decisions regarding the acceptance of the software, be it the first release or subsequent maintenance releases. The strategy consists in having a senior tester execute exploratory testing and a junior tester develop and execute automated user interface testing based on boundary value analysis. The main goal of this strategy is to increase the quality of the acquired software at the lowest possible cost. The strategy workflow is as follows: 6 1. When the contracted company releases the first version of the software, a senior software tester performs exploratory testing on the released software while a junior software tester creates automated UI test cases based on BVA. 2. Once the first test run is complete, if all tests pass, the software is accepted, otherwise, the software is rejected (the test manager could decide to accept it if there are just a few low-severity bugs). Additionally, exploratory tests that find bugs are automated and the entire test battery is then stored in an automated test case database. 3. When a posterior maintenance change is released, exploratory testing is applied over the new functionality while previously stored automated tests are executed against the entire software. 4. When this test run is complete, if all tests pass, the software is accepted, otherwise, the software is rejected. Each new exploratory test that finds a bug then becomes part of the battery of automated tests. The human resources required by the proposed strategy are a senior tester, a junior tester and a test manager (the test manager role can be assumed by the unit’s project manager). The senior tester is not needed permanently but rather only for the duration of the exploratory testing (which could be just a few days). On the other hand, the junior tester has a more permanent role since he is responsible for automating the exploratory tests devised by the senior tester whenever he is not executing tests. The rationale is that senior testers are not only scarce but expensive, whereas junior testers are more abundant and less expensive. The advantage of having a senior tester even for short periods of time is that her knowledge and expertise is captured by documenting the exploratory test cases, so that those tests can later be reproduced as part of an automated test case battery. Figure 1 shows the software testing workflow that starts with estimation and planning, and ends with test reporting. This workflow can be used for both acceptance and regression testing. IMPLEMENTATION Here we describe how the proposed strategy was implemented at a university unit, what tools were used, what was the conformation of the test team, and some other insights. The software under test (SUT) was an web based scheduling and planning tool that was contracted by the university unit. The main purpose of this application is schedule and assign specialized equipment and technicians to work requests. The application was developed in Java, deployed on Oracle Glassfish 2.1.1 web server and connected to a Microsoft SQL Server 2008 SP1database. It was designed to be used by approximately 100 users. In order to specify and automate the UI tests and facilitate the execution and reporting of exploratory tests, as well as bug reporting, we used Microsoft’s suite of test tools, which includes Team Foundation Server, Visual Studio and Test Manager. Proceedings of the II Costa Rican Workshop on Computer Science and Informatics (JoCICI 2015) 7 Fig. 1. Workflow of the proposed strategy We have worked with Microsoft test tools for the past three years and they have proven useful in the context of our projects. Although the SUT was developed using Java technologies for web applications, we could still use Microsoft test tools for the automation. We used the exploratory testing capabilities of these tools to automatically generate test cases from the exploratory tests, thus ensuring repeatability in future executions of the test battery. Particularly, after the senior tester performed exploratory testing and reported bugs, the junior tester used the tools to automatically generate test cases from the “Steps to reproduce” section in each reported bug. Once the test cases were generated, the junior tester proceeded to automate them. Likewise, we used the tools capabilities to automate the set of boundary value tests, by recording the interaction between the junior tester and SUT. In this way, we were able to create and manage test case automation. The test team comprised a test manager, a senior tester and a junior tester. The test manager had three years of industry experience as a software tester and four years of experience as principal investigator in research projects related to software testing and quality assurance. The senior tester had three years of experience using Microsoft test tools, and expertise developing web applications. The junior tester had no experience on software testing but had background in Computer Science and Informatics. The main activities for each role were as follows: (1) Test Manager: Dealt with the administrative decisions (approvals) and activities (progress monitoring) within the software testing process. (2) Senior Tester: Performed exploratory testing on the SUT, reported all bugs found by exploratory tests, and helped creating test cases from failed exploratory tests when necessary. (3) Junior Tester: Generated and automated all test cases extracted from failed exploratory tests, ran the test battery when necessary and reported all bugs found. RESULTS We present next the results obtained from the first implementation of our strategy. The testing process took 4 working days (32 hours in total); a total of 164 test cases were designed and executed; 50 of them were exploratory tests and 114 were automated UI tests based on BVA. Our efficiency indicator was the time required to develop each of the tests cases. Figure 2 shows the distribution of test case development time (in minutes) for exploratory testing (left) and automated UI testing based on BVA (right). As we can observe, the distributions are quite different, being the automated testing approach the one that exhibits smaller creation times, on average. This finding was expected since designing test cases based on boundary value analysis technique is straightforward and automating those test cases using coded UI tests is also very simple (due to the record and playback feature of the tools we used). In contrast, designing exploratory tests requires a lot more thinking and time, since each new test case is supposed to be more powerful than the previous one (it is based on the tester’s continuously increasing knowledge) [12]. Hence the difference in the skill set required by each testing approach. Our effectiveness indicator was the number of bugs found by each testing approach. A total of 21 bugs were reported; 76% of which were found using exploratory testing, and 24% using automated UI testing based on BVA. These results show that the exploratory testing approach was more effective in finding bugs. Moreover, if we combine this indicator with the number of test cases created under each approach (50 under exploratory and 114 under automated UI testing), the supremacy of the exploratory approach in terms of its effectiveness is even greater because, on average, a new bug is discovered every three exploratory test cases whereas a new bug is discovered every twenty-two automated test cases. Each bug was assigned a severity level from a four-level scale: low, medium, high and critical. The distribution of bugs per severity for each testing approach is shown in Figure 3. These results indicate that the exploratory testing approach was able to find bugs of higher severity levels, whereas the automated UI testing approach only found bugs of medium level. This further supports the idea that exploratory testing is a more effective approach. Proceedings of the II Costa Rican Workshop on Computer Science and Informatics (JoCICI 2015) 8 ploratory testing was more time consuming, and therefore more costly. Additionally, this implementation allow us to verify that our strategy was feasible and that it could provide useful information about the quality of the software in a relatively short period of time. Fig. 2. Test case development time by test type Although the strategy was successfully applied in the context of a university unit that contracted an application, we should say that a major threat to validity is that we have only implemented it once in a single unit for a particular software. Factors that could have influenced the results are the tools, the expertise of the senior and junior testers, and the specific characteristics of the SUT. We plan to apply this strategy in other units so that we can compare the results from various implementations. ACKNOWLEDGMENT This work was supported by the CITIC, and ECCI from the University of Costa Rica, under project No. 834-B2-A14. REFERENCES Fig. 3. Bug severity by test type One of the practical challenges of using approaches like exploratory testing is that it is not clear when to stop testing. A somewhat common criterion for deciding on this is to plot a graph of bugs found per day (or week), and to stop when either the number of bugs found is below a certain predefined threshold, or the curve is decreasing. This is also known as the defect discovery rate [10]. During the implementation of our strategy, we applied this criterion to decide when to stop exploratory testing. Particularly, on the first day we found 11 bugs, on the second and third days, we only found 3 bugs each day; and on the fourth day we did not find any bugs, hence the testing team decided to terminate the testing process at that point. Overall, the results obtained from the first implementation offer evidence that exploratory testing is more effective but also more costly than automated UI testing. This backs the proposed strategy up since one of its key principles is leveraging the expertise (and skill set) of a senior tester and the low cost of a junior tester, in order to yield a cost-effective strategy. CONCLUSIONS We presented a low-cost and effective strategy for doing acceptance and regression testing in a non-IT university unit with limited budget. The strategy comprises a senior tester that performs exploratory tests and a junior tester that automates user interface tests based on boundary value analysis. Both approaches are complementary and are performed by different types of testers to reduce costs. Results from the first implementation of this strategy show that the senior tester doing exploratory testing was more effective in finding defects than the junior tester doing automated UI tests with boundary values. However, results also show that ex- 1. M. Young and M. Pezze, Software Testing and Analysis: Process, Principles and Techniques, John Wiley & Sons, 2005. 2. C. Kaner, "Software Testing as a Social Science," in STEP 2000 Workshop on Software Testing, Memphis, EE.UU, 2008. 3. C. Kaner, J. L. Falk and H. Q. Nguyen, Testing Computer Software, Second Edition, New York, NY, USA: John Wiley & Son, Inc., 1999. 4. D. Arrington and N. Thomas, "Experience with Software Testing Techniques," in Southeastcon, 1981. 5. V. Arnicane, "Use of Non-IT Testers in Software Development," in Product-Focused Software Process Improvement, Riga, Latvia, 2007. 6. I. C. Society, IEEE Std 610.12.1990 Standard Glossary of Software Engineering Terminology, 1990. 7. IEEE, IEEE standard for software test documentation., IEEE, 1998. 8. G. Rothermel, S. Elbaum, A. G. Malishevsky, P. Kallakuri and X. Qiu, "On Test Suite Composition and Cost-effective Regression Testing," ACM Transactions on Software Engineering and Methodology, vol. 13, no. 3, pp. 277-331, 2004. 9. E. Engström and P. Runeson, "A Qualitative Survey of Regression Testing Practices," in Product-Focused Software Process Improvement, 2010. 10. L. Copeland, A Practitioner's Guide to Software Test Design, Norwood, MA, USA: Artech House, Inc., 2003. 11. J. Itkonen, M. V. Mantyla and C. Lassenius, "The Role of the Tester's Knowledge in Exploratory Software Testing," IEEE TSE, 2013. 12. N. Salleh, E. Mendes, J. Grundy and G. Burch, "An Empirical Study of the Effects of Personality in Pair Programming Using the Five-factor Model," in ESEM, Washington, DC, USA, 2009. 9 Propuesta de incorporación de pruebas unitarias a un sistema de código legado usando Microsoft Fakes Mario Barrantes PCI, Universidad de Costa Rica San José, Costa Rica [email protected] RESUMEN Este artículo plantea una propuesta para agregar pruebas unitarias a un sistema de información de código legado de nuestra universidad, mediante el marco de aislamiento Microsoft Fakes. Como etapa previa a la propuesta, se realiza una comparación entre Microsoft Fakes y la técnica tradicional de dobles de prueba con refactorización para realizar pruebas unitarias sobre código legado. Los resultados de esta comparación favorecen la adopción de Microsoft Fakes debido a que no se necesita modificar el código fuente del sistema a probar, requiere un menor tiempo de desarrollo y logra el mismo porcentaje de cobertura. Adicionalmente, se validó que la propuesta de usar Microsoft Fakes para agregarle pruebas unitarias a un sistema real de código legado fuera factible. Palabras Clave Pruebas unitarias, código legado, dobles de pruebas, Microsoft Fakes. INTRODUCCIÓN Las pruebas unitarias son una parte importante del proceso de desarrollo de software pues constituyen la retroalimentación más temprana que tiene el desarrollador sobre su código. Recordemos que un defecto detectado en desarrollo es de 2.5 a 10 veces más barato de arreglar que si es detectado en producción [1]. Adicionalmente, durante la etapa de mantenimiento del software, las pruebas unitarias son un buen mecanismo para identificar rápidamente regresiones en el software. De ahí el interés en incorporar pruebas unitarias no sólo al nuevo software que se desarrolle sino también al software existente que está en mantenimiento. La creación de pruebas unitarias automatizadas es una práctica estándar en desarrollos modernos de software, no obstante, su incorporación a software existente sigue siendo un reto debido a que los componentes de software deben aislarse en unidades que puedan ser probadas de forma independiente y no es usual que el software existente soporte tal nivel de aislamiento si no fue diseñado para ello. Se autoriza hacer copias de este trabajo o partes de él para uso académico, siempre y cuando sea sin fines de lucro. La copia debe contener esta nota y la cita completa en la primera página. La copia bajo otras circunstancias y la distribución o publicación podría requerir permisos adicionales o pago de derechos. JoCICI 2015, Marzo 5-6, San José, Costa Rica. Copyright © 2015 CITIC-PCI Alexandra Martínez ECCI, Universidad de Costa Rica San José, Costa Rica [email protected] En este trabajo, utilizaremos el término “código legado” para referirnos a código (software) sin pruebas unitarias, siguiendo la definición dada por Feathers [2]. El código legado generalmente tiene que ser adaptado para que se puedan ejecutar pruebas unitarias sobre él. Esta adaptación se conoce como “refactorización”, que es un proceso de reestructuración interna del código tendiente a mejorar su diseño, legibilidad o mantenibilidad, sin alterar su comportamiento externo [2]. Las técnicas tradicionales para resolver el problema de aislamiento de unidades de software en código legado se conocen con el término genérico de “dobles de prueba” (test doubles en inglés) [3], y consisten en simular componentes de software que interactúan con el software a probar en forma de dependencia. Existen distintos tipos de dobles de prueba, entre los cuales están: maniquí (dummy), auxiliar (stub), espía (spy), falsificación (fake) y simulacro (mock) [5]. Los maniquíes son el tipo más sencillo de dobles de prueba pues no contienen implementación. Se usan como valores de parámetros nada más (bien pueden ser nulos). Los auxiliares son implementaciones mínimas de interfaces o clases base. Normalmente devuelven valores preestablecidos, que obligan al software bajo prueba a ejecutar caminos específicos (que se quieren probar). Los espías son auxiliares con capacidad de grabación. Generalmente guardan información sobre las llamadas (invocaciones) a métodos hechas por el software bajo prueba, para ser verificado luego por las pruebas. Las falsificaciones son implementaciones más complejas que ofrecen la misma funcionalidad que el componente real pero de una forma más sencilla. Se usan principalmente cuando el componente real no está disponible aún, es muy lento o no puede usarse en el ambiente de pruebas debido a sus efectos secundarios. Los simulacros son creados dinámicamente mediante una biblioteca, en lugar de ser codificados por un desarrollador de pruebas (como los otros dobles de prueba). Dependiendo de cómo se configure, un simulacro se puede comportar como un maniquí, un auxiliar o un espía. Microsoft Fakes es el nuevo marco de aislamiento que introdujo Microsoft en Visual Studio 2012, mediante el cual se pueden reemplazar partes de código con stubs o shims para fines de pruebas [4]. Un stub remplaza una clase con un sustituto pequeño que implementa la misma interfaz y Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) típicamente se usa para llamadas dentro de una solución que se pueden desacoplar usando interfaces. Un shim modifica en tiempo de ejecución el código compilado para inyectar un sustituto y se usa para llamadas a ensamblados de referencia para los que el código no está bajo nuestro control. La Figura 1 muestra un diagrama comparativo entre shims y stubs. La mayor diferencia entre ambos elementos es que los shims modifican el ensamblado de la dependencia que necesitamos sustituir, mientras los stubs únicamente inyectan una dependencia distinta (ajustada a lo que se necesita) de una interfaz o abstracción existente. Dos de ellas utilizaban .NET 4.0 con la plantilla ASP.NET Web Forms y la otra utilizaba .NET 4.5 con la plantilla ASP.NET MVC. Todas tenían conexión con una base de datos SQL Server 2008 R2. Estas aplicaciones fueron seleccionadas por estar desarrolladas con la misma tecnología que el software a utilizar en la Etapa 2. Se usaron tres aplicaciones para tener una muestra más amplia y que los resultados no dependieran de la forma particular en que se implementó una aplicación. El caso de estudio abarcó los siguientes pasos: 1. Se seleccionaron 10 métodos de la aplicación que cumplieran los siguientes criterios (se buscaron características que exhiben sistemas reales de código legado): (a) alta cantidad de líneas de código, (b) alta complejidad, (c) uso de componentes de terceros, (d) uso de métodos estáticos y (e) fuerte acoplamiento entre las distintas capas de la aplicación. Generalmente los métodos o funciones con muchas líneas de código hacen más de lo que deberían hacer, según el principio de diseño de responsabilidad única. Se consideró un código con alta cantidad de líneas de código si tenía más de 30. Aunque la complejidad es difícil de medir, se consideró como código complejo aquel que contenía muchas bifurcaciones y que a primera vista era difícil relacionarlo con los requerimientos. 2. Se crearon pruebas unitarias para cada método utilizando Microsoft Fakes, intentando alcanzar la mayor cobertura de código posible. 3. Se crearon pruebas unitarias para cada método utilizando la técnica tradicional de dobles de prueba con refactorización, intentando alcanzar la mayor cobertura de código posible. 4. Se ejecutaron ambos conjuntos de pruebas. 5. Se recolectaron las siguientes métricas sobre la creación y ejecución de las pruebas: CONTEXTO La Universidad de Costa Rica cuenta con un conjunto de sistemas informáticos creados por varias unidades de desarrollo de software institucional. Nuestra investigación se desarrolló en una de estas unidades, la cual posee una extensa base de código legado que en su mayoría no fue diseñado para ser probado mediante pruebas unitarias, pero que está en constante mantenimiento y se beneficiaría de la incorporación de pruebas unitarias automatizadas que sirvan como pruebas de regresión. Al estar los componentes de software de este código fuertemente acoplados, la labor de aislamiento para pruebas unitarias se dificulta si no se recurre a la refactorización. Sin embargo, se busca una solución lo menos invasiva posible de manera que los cambios al código propio de las aplicaciones sean mínimos, para evitar la introducción involuntaria de errores. De ahí surge la necesidad de realizar esta investigación. METODOLOGÍA Esta investigación se dividió en dos etapas, que se describen a continuación. Etapa 1: Comparación entre Microsoft Fakes y una técnica tradicional de dobles de prueba con refactorización Para la comparación se utilizaron 3 aplicaciones de ventas en línea, desarrolladas por estudiantes de posgrado de la Universidad de Costa Rica para el curso ‘Seguridad del Software’. Las tres aplicaciones tenían la misma funcionalidad (respondían a los mismos requerimientos). 10 a. Total de líneas de código necesarias para crear la prueba (incluyendo código de la prueba, dobles de prueba, etc.). b. Cantidad de líneas del código original de la aplicación que tuvieron que ser modificadas, eliminadas o agregadas como parte de la refactorización necesaria para incorporar pruebas unitarias. c. Tiempo de desarrollo de las pruebas. d. Tiempo de ejecución de las pruebas. Figura 1: Forma en que trabajan los stubs y los shims. (Tomado de [4], p. 15, bajo licencia Creative Commons) e. Cobertura de código (porcentaje de líneas de código de la aplicación que fueron ejercitadas por las pruebas). Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) Etapa 2: Desarrollo de la propuesta para incorporar pruebas unitarias a un sistema de código legado Para esta etapa primeramente se escogió, de común acuerdo con la unidad de desarrollo de software institucional, el software que iba a utilizarse como piloto para incorporar pruebas unitarias. Luego de esto, la unidad nos facilitó una copia del código del sistema así como documentación sobre la arquitectura del mismo. Con estos insumos, se procedió a hacer un análisis de la arquitectura del sistema y del código mismo, extrayendo métricas como el índice de mantenibilidad, la complejidad ciclomática, y el acoplamiento de clases. El ‘índice de mantenibilidad’ es una fórmula que combina funciones de variables tales como la complejidad ciclomática, el volumen Halstead, y la cantidad de líneas de código por módulo [6]. La ‘complejidad ciclomática’ mide la cantidad de puntos de decisión que hay en un código [1], lo cual representa la cantidad de rutas por las cuales el código puede pasar. El ‘acoplamiento de clases’ mide la cantidad de entidades que dependen de un determinado miembro de una clase [1]. Estas métricas pemiten evaluar la facilidad o dificultad de realizar pruebas unitarias sobre un código. Combinando los resultados de este análisis con los resultados obtenidos de la etapa 1, se elaboró la propuesta para aplicar pruebas unitarias al sistema. RESULTADOS Resultados de la Etapa 1 Para cada aplicación se desarrollaron 5 pruebas con Microsoft Fakes y 5 pruebas usando la técnica de dobles de prueba con refactorización. Estas pruebas se realizaron utilizando la herramienta Visual Studio 2012. Cada prueba se ejecutó 10 veces y el tiempo reportado fue el promedio de las 10 ejecuciones. 11 La Tabla 1 muestra los resultados obtenidos del caso de estudio en la primera etapa, incluyendo porcentaje de código modificado (PCM), tiempo de desarrollo en minutos (TD), tiempo de ejecución en milisegundos (TE) y porcentaje de cobertura de código (CC). Los hallazgos más interesantes de la Tabla 1 se mencionan a continuación: (a) utilizando Microsoft Fakes no fue necesario modificar ni una sola línea del código original de la aplicación, mientras que utilizando dobles de prueba con refactorización se necesitó modificar en promedio un 24% del código de la aplicación; (b) utilizando Microsoft Fakes el tiempo promedio de desarrollo por método probado fue de 20 minutos, mientras que utilizando dobles de prueba con refactorización fue de 38 minutos; (c) utilizando Microsoft Fakes el tiempo total de ejecución de todas las pruebas fue de 1,116 segundos, mientras que utilizando dobles de prueba con refactorización fue de 238 milisegundos. Resultados de la Etapa 2 Del análisis realizado sobre el sistema institucional, se desprende que es un sistema web basado en un modelo de tres capas (presentación, lógica de negocios y acceso a datos) con un componente compartido donde están las entidades. La mayor parte de la lógica de la aplicación se encuentra en la capa de lógica de negocios, como es esperable. Esta capa también accede a varios servicios web de otros sistemas de la unidad. La capa de presentación constituye la interfaz con el usuario, mientras que la capa de acceso a datos es una interfaz entre la base de datos y la aplicación, sin mucha lógica. Las métricas de código se calcularon solamente para la capa de lógica de negocios. Los principales resultados de estas métricas se resumen a continuación: (a) se encontraron 22 miembros de clases que tienen un índice de mantenibilidad por debajo de 35 (lo cual hace muy difícil la incorporación de pruebas unitarias), aunque el promedio de este índice para todo el código analizado fue de 56 (el rango de valores para este índice va de 0 a 100, donde valores bajos representan código poco mantenible); (b) se encontraron 28 miembros de clases con complejidad ciclomática mayor a 10, aunque el promedio de la complejidad para todo el código analizado fue de 5 (lo cual es bastante bajo e indica que el código es modular y sus unidades tienen pocas ramificaciones); (c) se encontraron 40 miembros de clases con un acoplamiento mayor a 20, siendo el mayor un 42, aunque el promedio de acoplamiento de clases fue de 10. Con base en los resultados anteriores, se plantea la siguiente propuesta para incorporar pruebas unitarias al sistema insitutcional de código legado: Tabla 1: Resultados del caso de estudio en la Etapa 1. Generar pruebas unitarias para cubrir la mayor cantidad de escenarios en la capa de lógica de negocios del sistema. Simular el acceso y los servicios externos creando shims que no hagan nada o que devuelvan valores que la prueba necesite. Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) Utilizar Microsoft Fakes para desarrollar las pruebas unitarias. Esto por cuanto el sistema presenta un alto acoplamiento entre clases y Fakes puede aislar los componentes de una manera fácil, rápida y sin riesgo de introducir errores en el sistema pues Fakes no modifica el código original. Seguir esta guía para la creación de pruebas unitarias con Microsoft Fakes: 12 Paso 1: Seleccionar el método de la capa de lógica de negocio que se quiera probar. Paso 2: Detectar las dependencias y los lugares del código donde estas dependencias están siendo invocadas. Paso 3: Crear una clase de prueba y una prueba unitaria. Paso 4: Suplantar cada invocación de dependencia con un delegado que no haga nada o bien devuelva lo que la prueba unitaria necesita. Paso 5: Asignar los parámetros que la prueba necesita, invocar el método a probar y finalmente verificar que la condición (assert) para el escenario probado sea válida. Siguiendo esta propuesta, se escribieron y ejecutaron exitosamente tres pruebas unitarias sobre el sobre el código legado del sistema institucional. La Figura 2 muestra un ejemplo de una de estas pruebas. CONCLUSIÓN Esta investigación comparó el uso de Microsoft Fakes contra una técnica tradicional de dobles de prueba con refactorización para agregar pruebas unitarias a código legado. Adicionalmente, y considerando los hallazgos derivados de esta comparación, se elaboró una propuesta para incorporar pruebas unitarias a un sistema real de código legado usado en nuestra universidad. Los resultados de la comparación favorecen a Microsoft Fakes debido a que no necesita modificar el código fuente de la aplicación y requiere menos tiempo de desarrollo que la técnica tradicional. La desventaja de Microsoft Fakes es un mayor tiempo de ejecución de las pruebas unitarias, lo cual podría ser un problema en sistemas muy grandes, pero en nuestro contexto es más importante minimizar el riesgo de introducir errores en el código que ahorrar tiempo de ejecución. Finalmente, se corroboró que la propuesta para agregar pruebas unitarias al sistema fuera factible. Figura 2: Ejemplo de prueba unitaria sobre el código legado del sistema institucional. TRABAJO FUTURO Como trabajo futuro se plantea aplicar pruebas unitarias al menos al 25% del código de lógica de negocios del sistema institucional y refinar la propuesta con los hallazgos encontrados en el proceso. Adicionalmente, en el futuro sería interesante investigar si existen otras herramientas (ya sea propietarias o de código libre) que brinden características de aislamiento similares a las que ofrece Microsoft Fakes, y en caso de existir, evaluarlas siguiendo los pasos planteados en la Etapa 1 de este caso de estudio. REFERENCES 1. McConnell, S. (2004). Code Complete. Redmond, Wash: Microsoft Press 2. Feathers, M. (2004). Working effectively with legacy code. Upper Saddle River, N.J: Prentice Hall PTR. 3. Meszaros, G. (2007). XUnit test patterns: refactoring test code. Upper Saddle River, NJ: Addison-Wesley. 4. Microsoft Corporation. Better Unit Testing with Microsoft® Fakes (2013), v1.2. Disponible en http://vsartesttoolingguide.codeplex.com/releases/view/102290 5. Seeman, M. (2007). Exploring The Continuum Of Test Doubles. MSDN Magazine. Disponible en https://msdn.microsoft.com/en-us/magazine/cc163358.aspx 6. Spinellis, D. (2006). Code quality: the open source perspective. Upper Saddle River, NJ: Addison-Wesley. 13 Un caso de estudio de aplicación del estándar de OWASP para verificación de la seguridad de aplicaciones Enrique Brenes PCI, Universidad de Costa Rica San Pedro, San José [email protected] ABSTRACT Este caso de estudio aplica el nivel 1 del estándar de OWASP para verificación de la seguridad de aplicaciones web (ASVS) en el contexto de una aplicación web de la industria financiera que se encuentra en desarrollo. Las principales preguntas de investigación fueron ¿En qué grado se puede aplicar el estándar? y ¿Cómo se caracterizan las vulnerabilidades encontradas? Los resultados obtenidos indican que es posible realizar esta evaluación de seguridad sin ser expertos en el área, utilizando análisis manual de código y técnicas de pruebas de penetración manuales con apoyo de herramientas. Los resultados también sugieren que las vulnerabilidades de control de acceso y autenticación son las que presentan mayor severidad y mayor esfuerzo de mitigación. Palabras clave Pruebas de seguridad; OWASP; ASVS; vulnerabilidades. INTRODUCCIÓN Las aplicaciones web son el fruto de una rápida evolución del paradigma de cliente-servidor hacia el navegador-servidor web, a través de varias fases y tecnologı́as como las páginas web estáticas, dinámicas, AJAX, servicios web, entre otros [8]. Dichas aplicaciones están sujetas a caracterı́sticas del ambiente en que se ejecutan como el acceso abierto y conexiones sin estado, por lo que su seguridad es un tema de preocupación creciente tanto en la academia como en la industria [8]. Por otra parte, cuando se trata de aplicaciones que administran información sensible de personas y negocios, el tema de la seguridad se vuelve aún más crı́tico [2]. Una vulnerabilidad es un fallo o defecto de seguridad en el software que puede ser usado por un atacante para ganar acceso a un sistema o red. Toda debilidad en una aplicación que pueda ser explotada maliciosamente [1]. En el año 2013 el Open Web Application Security Project (OWASP), dedicado a determinar y combatir las causas que hacen que el software sea inseguro, publicó las diez vulnerabilidades de seguridad más comunes en aplicaciones industriales, con base en un conjunto de datos de ocho firmas que se especializan en seguridad de aplicaciones. Estas vulnerabilidades son: inyección de código maligno, administración Se autoriza hacer copias de este trabajo o partes de para uso académico, siempre y cuando sea sin fines de lucro. La copia debe contener esta nota y la cita completa en la primera página. La copia bajo otras circunstancias y la distribución o publicación podrı́a requerir permisos adicionales o pago de derechos. JOCICI’15, Marzo 5-6, San José, Costa Rica. c Copyright 2015 CITIC-PCI Alexandra Martı́nez ECCI, Universidad de Costa Rica San Pedro, San José [email protected] de la sesión, vulneración de la autenticación, cross-site scripting, referencias directas a objetos de forma insegura, exposición de datos sensibles, control de acceso, cross-site request forgery, utilización de componentes con problemas conocidos, y redireccionamiento y reenvı́os no validados [3]. En el año 2014 OWASP publicó la última versión del estándar para verificación de la seguridad de aplicaciones web (ASVS por sus siglas en inglés), el cual tiene tres niveles: oportunista (nivel 1), estándar (nivel 2) y avanzado (nivel 3) [4]. El nivel 1 contiene 45 verificaciones (controles) de seguridad divididas en 9 requerimientos (o categorı́as). Las pruebas de seguridad pueden ser utilizadas para identificar vulnerabilidades en una aplicación web. Las técnicas más utilizadas son las pruebas de penetración y el análisis de código [1]. Las pruebas de penetración consisten en ejecutar una aplicación web de forma remota para encontrar vulnerabilidades, con los mismos permisos que tendrı́a un usuario final, y sin saber cómo funciona la aplicación por dentro. Estas pruebas pueden ser manuales o automatizadas. Por otro lado, el análisis de código consiste en revisar manualmente el código en busca de vulnerabilidades, sin ejecutarlo. Esta técnica es muy efectiva cuando es realizada por expertos en seguridad, aunque también existen herramientas automatizadas que apoyan el proceso. El objetivo de trabajo fue investigar la aplicabilidad del nivel 1 del estándar para verificación de la seguridad de aplicaciones (ASVS) de OWASP, a una aplicación web de la industria financiera, y caracterizar las vulnerabilidades de seguridad encontradas. Nuestras preguntas de investigación fueron las siguientes: RQ1: ¿En qué grado se puede aplicar el nivel 1 del estándar? Esta pregunta se subdividió en tres preguntas: RQ 1.1: ¿Qué grado de experticia en seguridad necesita un analista de calidad para aplicar el nivel 1 del estándar? RQ 1.2: ¿Cuánto esfuerzo toma la aplicación del nivel 1 del estándar? RQ 1.3: ¿Cuáles herramientas pueden apoyar la aplicación del nivel 1 del estándar y en qué medida? RQ2: ¿Cómo se caracterizan las vulnerabilidades encontradas? Esta pregunta se subdividió también en tres preguntas: RQ 2.1: ¿Qué tipos de vulnerabilidades se encontraron? Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) RQ 2.2: ¿Qué severidad y prioridad presentan las vulnerabilidades encontradas? RQ 2.3: ¿Cuánto esfuerzo requiere corregir las vulnerabilidades encontradas? METODOLOGÍA Contexto El estudio se realizó en una empresa de software que desarrolla sistemas financieros. En particular se escogió una aplicación que estaba desarrollada en un 85 %. Dicha aplicación fue implementada con base en C# .NET, Html5, Javascript y Google Angular, utilizando una arquitectura RESTFul, soportado por el ASP.NET Web API y la base de datos Oracle. El estudio se llevó a cabo entre los meses de agosto y noviembre de 2014. Procedimiento y roles La aplicación del nivel 1 del estándar estuvo a cargo de dos analistas de calidad. Durante la ejecución de cada requerimiento del estándar y sus verificaciones, los analistas reportaban las vulnerabilidades encontradas, con los pasos requeridos para reproducirlas, y adicionalmente registraban el tiempo que les habı́a tomado la ejecución. Después de ejecutar cada requerimiento, los analistas tenı́an una reunión donde el analista que habı́a ejecutado el requerimiento mostraba al otro cómo lo habı́a hecho y fundamentaba sus métodos. La intención de esta reunión era encontrar posibles aspectos que no habı́an sido cubiertos durante la ejecución del requerimiento y abordarlos apropiadamente. 14 tomaron más esfuerzo. Para responder RQ 1.3, se extrajo la cantidad de verificaciones que se apoyaron en herramientas, ası́ como la contribución que tuvo cada herramienta en la aplicación del estándar (cantidad de verificaciones que apoyó). Las herramientas fueron seleccionadas con base en las sugerencias de la guı́a de pruebas de OWASP [6], la cual lista una serie de herramientas de utilidad para los diferentes tipos de verificaciones que deben realizarse. Adicionalmente se incluyó AppScan [7], por el amplio uso que tiene en la organización donde se realizó el estudio. Para el análisis de la segunda pregunta de investigación (RQ2) y sus subpreguntas, se utilizó la bitácora de vulnerabilidades encontradas. En cuanto a RQ 2.1 y RQ 2.2, se elaboraron gráficos con los defectos encontrados, agrupados por su respectiva categorı́a o tipo, ası́ como por prioridad y severidad. Un análisis de estos datos permite relacionar las vulnerabilidades encontradas con la prioridad y severidad que se les asignó, facilitando la identificación de las categorı́as más crı́ticas. Esta información permitió ofrecer una perspectiva sobre cuáles vulnerabilidades deben ser descubiertas en etapas tempranas del desarrollo o diseño, para minimizar el esfuerzo de corrección. Con respecto a RQ 2.3, se extrajo de la bitácora el esfuerzo requerido para resolver la vulnerabilidad, y en el caso de las vulnerabilidades no resueltas, se utilizó un estimado realizado por un desarrollador del proyecto. RESULTADOS Esta sección presenta los resultados obtenidos para cada pregunta de investigación planteada. Recolección de datos Durante la aplicación del estándar se mantuvieron tres hojas de cálculo para almacenar los datos relevantes al estudio. En la primera hoja se llevó la bitácora de progreso de la aplicación del estándar, especificando para cada verificación: su estado (pasó o falló), razón del estado, y técnica utilizada o herramienta. En la segunda hoja se registraron las vulnerabilidades encontradas, incluyendo su categorı́a, estado, severidad, prioridad, descripción y esfuerzo requerido (en horas). En la tercera hoja se registró el esfuerzo requerido (en horas) para ejecutar cada requerimiento del nivel 1 del estándar, ası́ como el estado de su ejecución. La información de las vulnerabilidades y las horas de esfuerzo requerido tanto para ejecutar el estándar como para arreglar las vulnerabilidades, se extrajo del Team Foundation Server, herramienta utilizada para el reporte de defectos y gestión del proyecto. Análisis de datos Para responder a la primera pregunta de investigación (RQ1) y sus subpreguntas, se tomaron como insumos la bitácora de progreso y la bitácora de esfuerzo. Se contabilizaron las verificaciones que se pudieron realizar, para obtener el porcentaje de completitud, y en los casos en que no se logró el 100 %, se agregó una explicación de por qué no se pudo completar. Para RQ 1.1, se extrajo un detalle del perfil de los analistas encargados de ejecutar el estándar, el entrenamiento necesario y las limitaciones encontradas. Para contestar RQ 1.2, se graficó el esfuerzo en horas de trabajo para cada requerimiento del estándar, con el fin de visualizar cuáles requerimientos Aplicación del estándar (RQ1) Para el proyecto seleccionado, fue posible ejecutar el estándar en un 98 %, según el reporte de los analistas. La única verificación que no se pudo realizar fue la de seguridad de las comunicaciones, por restricciones de infraestructura impuestas por el departamento de TI al momento de ejecutar el estándar. La Tabla 1 muestra el detalle de los resultados de la ejecución. Los aprobados son controles que sı́ existı́an en la aplicación, los fallidos son aquellos en que se descubrió al menos una vulnerabilidad y los que no aplicaron son aquellos en que el control no existı́a en la aplicación por razones justificadas que no significaban una vulnerabilidad. En términos generales, el conocimiento requerido para ejecutarlo fue básico, es decir, los analistas encargados de la ejecución lograron completar el 98 % sin tener experiencia previa en pruebas de seguridad. Grado de experticia para aplicar el estándar (RQ 1.1) Los analistas que ejecutaron el estándar tenı́an entre 2 y 3 años de experiencia en pruebas de software, pero no tenı́an experticia en pruebas de seguridad. A estos analistas se les Cuadro 1. Resultados de la ejecución del ASVS. Resultado de la verificación APROBADO FALLIDO NO APLICA NO EJECUTADO Cantidad 25 17 3 1 Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) 15 Figura 2. Contribución de las herramientas a la ejecución del estándar. Figura 1. Distribución del tiempo que tomó la ejecución del estándar. dio un entrenamiento de dos horas sobre las diez vulnerabilidades más comunes reportadas por OWASP (2013). Por otro lado, los analistas utilizaron caracterı́sticas puntuales de las herramientas ZAP [5], AppScan y RequestMaker [9], y herramientas del desarrollador del navegador web para apoyar la aplicación del estándar. Cada analista tuvo dos dı́as para el adiestramiento en el uso de estas herramientas. Esfuerzo de aplicar el estándar (RQ 1.2) La ejecución completa del nivel 1 del estándar tomó un total de 95 horas. La Figura 1 muestra el detalle de la distribución de horas por requerimiento del estándar. Los requerimientos “Administración de la sesión” y “Manejo de entradas maliciosas” representaron conjuntamente un 55 % del tiempo total. Herramientas de apoyo en la aplicación del estándar (RQ 1.3) Las herramientas contempladas en esta investigación apoyaron un 48 % del total de verificaciones realizadas. En algunos casos, las herramientas fueron utilizadas para dar exhaustividad a las pruebas de inyección de código; en otros casos, para comparar con los resultados de las pruebas manuales, atrapar tráfico HTTP para su análisis, generar peticiones personalizadas al servidor y listar las URLs del sitio para realizar pruebas de accesos no autorizados. La Figura 2 muestra la contribución de cada herramienta en cuanto a las verificaciones del estándar que apoyó. AppScan resultó ser la que apoyó la mayor cantidad de verificaciones del estándar. También sucedió que varias herramientas apoyaron una misma verificación del estándar, e.g., en la verificación 2.18 del requerimiento de autenticación, se utilizaron AppScan y las herramientas para el desarrollador del navegador web. Caracterización de vulnerabilidades (RQ2) Se encontraron vulnerabilidades en 6 de los 9 requerimientos evaluados, siendo “Autenticación” y “Control de acceso” los requerimientos que más vulnerabilidades presentaron. Es interesante que no se encontraran vulnerabilidades en el requerimiento “Manejo de entradas maliciosas”, a pesar de ser el que encabeza la lista de vulnerabilidades más comunes de OWASP. Esto puede atribuirse a que durante el desarrollo de la aplicación, las pruebas funcionales validaron consistentemente que no se permitieran entradas maliciosas tanto a nivel Figura 3. Relación entre los tipos de vulnerabilidades y sus severidades. de interfaz de usuario como a nivel de parámetros en las peticiones al servidor. Tipo, severidad y prioridad de vulnerabilidades (RQ 2.1 y 2.2) La severidad de las vulnerabilidades fue asignada por personal del departamento de seguridad de la empresa. La Figura 3 muestra que los requerimientos con mayor cantidad de vulnerabilidades reportadas fueron “Autenticación” y “Control de acceso’. Además, en estas mismas categorı́as se dio la mayor concentración de severidades crı́ticas. En “Control de acceso” se reportaron 3 vulnerabilidades crı́ticas y 1 alta, siendo el requerimiento que concentró las severidades más altas. De las 15 vulnerabilidades reportadas en total, 5 fueron catalogadas como crı́ticas, 3 altas, 4 medianas y 3 bajas. En cuanto a la prioridad, se determinó que todas serı́an arregladas por el equipo de desarrollo, de acuerdo con el orden de severidad. Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) 16 de arreglarlas sea muy alto. El segundo requerimiento que causó más esfuerzo requerido para solucionar las vulnerabilidades fue autenticación, por lo que también debe ser considerado en fases tempranas del desarrollo. Los demás requerimientos aportaron vulnerabilidades con costos de mitigación más bajos (por debajo de los dos dı́as). Como trabajo futuro, se plantea aplicar los demás niveles del estándar a la aplicación bajo estudio, y posteriormente contratar a un grupo de expertos en pruebas de seguridad para realizar una evaluación de seguridad formal sobre la aplicación. La comparación de las vulnerabilidades descubiertas por los expertos y las descubiertas por analistas inexpertos siguiendo el estándar, servirı́a para determinar la efectividad de la cobertura del estándar por parte de los analistas. REFERENCIAS Figura 4. Esfuerzo requerido para solucionar las vulnerabilidades. Esfuerzo de corrección de vulnerabilidades (RQ 2.3) En el momento de reportar este trabajo, se habı́an logrado solucionar 6 de las 15 vulnerabilidades encontradas, por lo que las horas de esfuerzo mostradas en la Figura 4 son producto de una combinación entre horas reales y horas estimadas por el equipo de desarrollo. Se estima que la solución de todas las vulnerabilidades requerirá un esfuerzo de aproximadamente 55 dı́as (trabajando 8 horas diarias). Dichas estimaciones fueron dadas por los desarrolladores de la aplicación, tras un análisis de los cambios requeridos en el código. Un resultado notable es que el esfuerzo de solucionar las vulnerabilidades de autenticación y control de acceso suman alrededor de 48 dı́as de esfuerzo, es decir, un 90 % del total de esfuerzo estimado. CONCLUSIONES En esta investigación se aplicó el ASVS en una aplicación web. Se logró aportar evidencia de que para ejecutar el nivel 1 del estándar no se requieren conocimientos profundos en el área de seguridad de antemano, pues analistas de calidad sin antecedentes en pruebas de seguridad fueron capaces de completar un 98 % del estándar en 95 horas de esfuerzo total. La evaluación de seguridad realizada permite dar una idea clara de cómo se encuentra la aplicación en términos de seguridad y permite al equipo de desarrollo abordar las vulnerabilidades encontradas para alcanzar el nivel 1 del estándar. La mayorı́a de las vulnerabilidades detectadas en el nivel 1 del estándar fueron de autenticación y control de acceso, sumando entre ambas 9 vulnerabilidades (de un total de 15). En control de acceso y en autenticación se encontraron vulnerabilidades de severidad crı́tica, las cuales deben ser resueltas antes de liberar a producción. Ası́ también, se encontró que las vulnerabilidades de control de acceso requirieron un esfuerzo considerable para ser eliminadas de la aplicación. Esto da pie para señalar que las pruebas de control de acceso deben realizarse cuanto antes en el ciclo de vida de desarrollo, evitando que sean detectadas muy tarde y que el costo 1. Awang, N., and Manaf, A. Detecting vulnerabilities in web applications using automated black box and manual penetration testing. In Advances in Security of Information and Communication Networks, Springer Berlin Heidelberg (2013), 230–239. 2. Dukes, L., Yuan, X., and Akowuah, F. A case study on web application security testing with tools and manual testing. In Southeastcon, 2013 Proceedings of IEEE (April 2013), 1–6. 3. Foundation, T.˜O. Owasp top 10 - 2013. los diez riesgos mas criticos en aplicaciones web. https://www.owasp.org/images/5/5f/OWASP_Top_10_ -_2013_Final_-_Espa%C3%B1ol.pdf, 2013. [Online; accessed Dec-2014]. 4. Foundation, T.˜O. Application security verification standard (2014). https://www.owasp.org/images/5/58/ OWASP_ASVS_Version_2.pdf, 2014. [Online; accessed Dec-2014]. 5. Foundation, T.˜O. Owasp zed attack proxy project. https://www.owasp.org/index.php/OWASP_Zed_ Attack_Proxy_Project, 2014. [Online; accessed Dec-2014]. 6. Foundation, T.˜O. Testing guide introduction. https://www.owasp.org/index.php/Testing_Guide_ Introduction#Testing_Techniques_Explained, 2014. [Online; accessed Dec-2014]. 7. IBM. Ibm security appscan. www.ibm.com/software/products/en/appscan, 2014. [Online; accessed Dec-2014]. 8. Mao, C. Experiences in security testing for web-based applications. In Proceedings of the 2Nd International Conference on Interaction Sciences: Information Technology, Culture and Human, ICIS ’09, ACM (New York, NY, USA, 2009), 326–330. 9. Nurminen, J. Request maker download site. https://chrome.google.com/webstore/detail/ request-maker/kajfghlhfkcocafkcjlajldicbikpgnp, 2014. [Online; accessed Dec-2014]. 17 Construyendo conciencia sobre amenazas a la privacidad Luis Gustavo Esquivel Quirós Universidad de Costa Rica San José, Costa Rica [email protected] ABSTRACT People tend to value their privacy, but are uninformed about the risks to which it is exposed with the availability of a few, seemingly innocuous facts online. To address this problem, we propose a hands-on method of consciousnessraising. We conducted an exercise with a group of students that were no experts in either privacy or security issues. The exercise asked them to try to find the owners of previously anonymized data, using any means available, in a restricted amount of time. After the exercise, most students correctly linked most data to its owners, and, more importantly, all the participants reported an increased sense of awareness about the exposure of their data online, and interest in general privacy issues, showing the effectiveness of the approach. Keywords Privacy; anonymity; re-identification I INTRODUCCIÓN La información fluye constantemente, ya sea con nuestros teléfonos móviles, estaciones de trabajo o cualquier otro dispositivo electrónico que utilicemos. Generamos todo tipo de información, social, geográfica, financiera, grafica, entre otras. Toda esa información tiene algún tipo de “dueño” y ese dueño tiene derecho a que su privacidad sea respetada. El concepto de "privacidad" no tiene un significado único, claro y definido, y varía ampliamente entre diversas culturas. Es un concepto discutido en la filosofía, la política, el derecho, la sociología, la antropología y otras áreas. En general, las diferencias entre los ámbitos públicos y privados de acción han sido reconocidos en todas las sociedades humanas, hasta donde es posible rastrearlo, aunque no existe consenso con respecto al significado, los límites y la aplicación de los mismos. El tema es muy complejo y amplio, incluyendo las crecientes limitaciones impuestas por algunas legislaciones actuales [1][2][3][4]. En este artículo usaremos la definición de Westin en [5] donde propone que la privacidad es “…el reclamo de personas, grupos o instituciones para determinar ellos mismos cuándo, cómo y en qué medida se comunica a los demás la información sobre ellos". Dicha definición se complementa con la posición argumentada por Willian Se autoriza hacer copias de este trabajo o partes de él para uso académico, siempre y cuando sea sin fines de lucro. La copia debe contener esta nota y la cita completa en la primera página. La copia bajo otras circunstancias y la distribución o publicación podría requerir permisos adicionales o pago de derechos. JoCICI 2015, Marzo 5-6, San José, Costa Rica. Copyright © 2015 CITIC-PCI Elena Gabriela Barrantes Sliesarieva Universidad de Costa Rica San José, Costa Rica [email protected] Parent en [6], donde define la privacidad como la condición de no poseer información personal no documentada (no autorizada) en posesión de otros entes. La posición de Parent es que existe una pérdida de privacidad cuando otros adquieren información personal sobre un individuo sin su autorización. El autor define la información personal como aquella sobre hechos que la persona escoge no revelar sobre sí misma. La información personal se vuelve "documentada" únicamente si se vuelve pública por autorización o acciones del individuo. Los individuos y las organizaciones se exponen a la divulgación no autorizada de sus datos cuando publican información privada en plataformas públicas o semipúblicas. La publicación puede ser intencional o no, pero una vez realizada, el dueño de la información se ve expuesto a diversas consecuencias, en ocasiones negativas, por lo que se han dado demandas en contra de individuos y de empresas por divulgación no autorizada [7]. Con el acceso masivo a datos, el tópico de la privacidad de la información ha cobrado aún más relevancia. El problema de fondo es el cómo realizar la publicación de información asegurando que se respete la privacidad del “dueño”, pero se preserve la utilidad de la misma [8], proceso al cual llamaremos “anonimización”. Este proceso es cualitativamente diferente al problema de ocultar la información durante su transmisión o almacenamiento, para lo cual existen múltiples técnicas, tales como el cifrado [9]. En el caso que nos concierne, la información es publicada por los mismos dueños, o por terceras partes que accedieron de forma legítima a la información, por lo que no se trata estrictamente de ocultarla, sino de evitar que se relacione con individuos específicos. En particular, cuando el dueño de la información es una persona joven, existen estudios que indican que tiende a valorar su privacidad, pero subestima el peligro en que la misma se encuentra debido a los datos que comparte, muchas veces en forma voluntaria, en diferentes medios electrónicos [10]. Lo anterior, combinado con el hecho de que una vez que los datos se encuentran en la red, es virtualmente imposible eliminarlos, incrementa el riesgo de mal uso por terceras partes [11]. Por lo tanto, es importante concientizar a los jóvenes sobre el peligro real que corren [10][11]. En este sentido, es natural pensar en una campaña de divulgación o similar. Sin embargo, existe otra posibilidad y es el uso de las habilidades naturales de los seres humanos para encontrar patrones en todas las cosas [12] como Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) herramienta para realizar una experiencia “hands-on” de identificar los dueños de un grupo de datos arbitrario que ha sido protegido, y con ello crear una impresión más duradera del peligro real que se corre. En este artículo proponemos una forma de concientizar a los estudiantes sobre los riesgos de la falta de protección de la privacidad de la información que se publica y del proceso de re-identificación de personas, por medio de una experiencia práctica, potenciando el aprendizaje tangible para el estudiante [13]. En la sección II explicaremos conceptos básicos de la protección de la privacidad. En la sección III detallamos la metodología utilizada para diseñar el estudio. La sección IV presenta los resultados y su análisis, para finalizar en la sección V con las conclusiones. II CONCEPTOS BÁSICOS DE LA PROTECCIÓN DE LA PRIVACIDAD La protección de la privacidad de la información es el proceso por medio del cual una colección de datos es despojada de información que permita la re-identificación de su fuente. A este proceso también se le conoce como deidentificación [14]. La re-identificación, por otra parte, es el proceso inverso, utilizado para derrotar la de-identificación e identificar a los individuos. Para lograr una correcta de-identificación, existen múltiples estrategias, pero las más comunes comprenden eliminar o enmascarar identificadores personales, tales como la identificación o el nombre, y la supresión o la generalización de los datos que pueden usarse para referenciar a un individuo indirectamente, como el código postal o el correo electrónico. A este tipo de datos se les denomina cuasi-identificadores [15]. En el estudio que se llevó a cabo, el propósito era que al lograr una “re-identificación” natural de datos que parecían no asociados a ningún sujeto, los estudiantes percibieran y se apropiaran del hecho de que toda información puede llegar a ser utilizada con fines desconocidos, y potencialmente peligrosos [11]. La experiencia se llevó a cabo con un grupo de estudiantes universitarios, que no eran expertos en temas de seguridad, ni privacidad. A los estudiantes se les entregó una serie de datos anonimizados o de-identificados, sobre jugadores del fútbol local (costarricense), y se les propuso como tarea intentar identificar a quien hacían referencia los datos. En otras palabras, que re-identificaran los datos anonimizados. El tiempo que se les dio a los jóvenes fue limitado, pero se les permitió utilizar cualquier medio a su alcance, electrónico o no, para re-identificar estos datos. Uno de los supuestos del estudio era que durante el proceso de re-identificación los estudiantes se darían cuenta que este proceso de inferencia no era un ejercicio complejo o especializado, lo que –en principio- elevaría su percepción de riesgo. 18 III METODOLOGÍA En esta sección describiremos los aspectos metodológicos relevantes del estudio. En primer lugar, se describirá el diseño y la ejecución del ejercicio, luego los aspectos a evaluar y finalmente el formulario aplicado. Diseño y ejecución del ejercicio Para poder medir si la exposición a un proceso de reidentificación era útil para mejorar la percepción del riesgo por parte de los estudiantes, se requería un grupo de jóvenes que no estuvieran familiarizados con dichos procesos. Se seleccionó el curso FS408-Termodinámica de segundo año del bachillerato en Física de la Universidad de Costa Rica. Ninguno de los estudiantes de este curso tenía conocimiento previo sobre minería de datos o protección de la privacidad de la información. Se contaba con dos grupos de estudiantes, pero la metodología que se describe a continuación se refiere únicamente al grupo de 34 estudiantes del curso presencial. Por razones de espacio no se describe el ejercicio (ligeramente diferente) realizado con el grupo de 15 estudiantes que atendían el curso de forma remota, que –sin embargo- arroja resultados muy similares. El ejercicio se diseñó en dos etapas separadas. En la primera, se presentaría a los estudiantes una charla de una hora sobre privacidad, y luego se les asignaría un ejercicio de re-identificación de datos que deberían realizar para una fecha posterior. En la segunda etapa, se recolectarían las respuestas, se evaluaría el ejercicio, y se analizarían los datos. Para generar los datos a partir de los cuales iban a trabajar los estudiantes, se utilizó información disponible en Internet de 30 jugadores de fútbol nacional. Se logró compilar el número de cédula, el nombre completo, la fecha de nacimiento, la edad, el lugar de nacimiento, el estado civil, el número de hijos, la provincia de votación y el club actual. Se utilizó información de futbolistas debido a la euforia provocada por la cercanía del mundial de fútbol y la facilidad de acceso a información relacionada a los mismos. En la charla ofrecida se presentaron los conceptos básicos de la protección de la privacidad y las consecuencias legales de la información que se publica en Internet, tomando como ejemplos demandas y condenas nacionales e internacionales [7][16]. Además, se mostraron ejemplos de los peligros potenciales, tales como suplantaciones de identidad y el robo de información sensible. Finalmente, se presentó un ejemplo de re-identificación utilizando personajes de un cuento popular. A los estudiantes se les permitió interactuar libremente con el expositor en cuanto a dudas, sugerencias y opiniones. Al finalizar la charla, a cada estudiante se le entregaron los materiales para el ejercicio, indicándoles un plazo de ocho días para la entrega. El ejercicio consistía en re-identificar la mayor cantidad posible de jugadores, completar el formulario de evaluación, y además responder preguntas de Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) una tarea de curso que relacionaba temas del curso con el ejercicio (específicamente de entropía). La respuesta base consistía en mapear a cada grupo de datos anonimizados al nombre del jugador que él o la estudiante creyera que era el dueño de estos datos. Cuadro 2. Preguntas utilizadas en el formulario. La columna izquierda contiene los diferentes aspectos abordados y la derecha las preguntas que aplican para cada aspecto Aspecto Percepción de facilidad de la re-identificación A los estudiantes se les facilitaron tres tablas obtenidas de consultas sobre los datos recopilados de jugadores: 1) Las columnas fecha de nacimiento, edad, lugar de nacimiento y provincia de votación para todos los individuos a re-identificar. 2) Las columnas estado civil y número de hijos, para aquellos individuos (jugadores) cuyo estado civil correspondía al valor matrimonio. 3) Las columnas número de hijos y club deportivo actual para aquellos jugadores que a la fecha del ejercicio estuvieran jugando para equipos nacionales. En la siguiente sub-sección se describen los aspectos que se pretendía evaluar. Aspectos a evaluar Se deseaba evaluar varios aspectos del proceso de reidentificación, y para cada uno se definieron criterios de evaluación. Una lista parcial de aspectos y criterios se presenta en el Cuadro 1. El formulario de evaluación, descrito en la siguiente subsección, incluía al menos una pregunta por aspecto. Formulario de evaluación En el formulario de evaluación se usaron tanto preguntas abiertas como cerradas para minimizar el sesgo, recolectar la terminología utilizada por personas no expertas, y tratar de determinar la importancia asignada a los términos utilizados. Cada uno de los aspectos del cuadro 1 era referenciado por al menos una pregunta. El cuadro 2 resume las preguntas por aspecto. En la siguiente sección analizaremos los resultados obtenidos. Cuadro 1. Criterios de medición. La primera columna contiene los aspectos que se deseaban evaluar, y la segunda, los criterios de medición que se aplicaron para cada aspecto. Aspecto Percepción de facilidad de la re-identificación Percepción de éxito en la re-identificación Percepción del proceso de re-identificación Éxito en la reidentificación Uso de tecnología en el proceso de reidentificación Criterio de medición Medidas subjetivas sobre la dificultad percibida por el estudiante al realizar el ejercicio Medida cuantitativa de reidentificaciones presentadas por el estudiante. Medida subjetiva reportada por el estudiante sobre el interés generado por el ejercicio Medida cuantitativa del número de jugadores correctamente identificados. Medidas cualitativas sobre herramientas y técnicas utilizadas en el proceso 19 Percepción de éxito en la re-identificación Percepción del proceso de re-identificación Éxito en la reidentificación Uso de tecnología en el proceso de reidentificación Preguntas De las personas re-identificadas, escriba la cantidad de personas asociadas a cada categoría de dificultad de la re-identificación (1 a 5) De las personas que re-identificó, ¿cuál fue la persona más fácil de re-identificar y por qué? De las personas que re-identificó, ¿cuál fue la persona más difícil de re-identificar y por qué? Número total de mapeos entre datos anonimizados y nombres de jugadores presentados por el estudiante. ¿Cómo califica el ejercicio de reidentificación de personas? (Opciones: Desafiante, Interesante, Normal, Aburrido) Número de individuos correctamente reidentificados comparados con el total de jugadores ¿Utilizó usted algún recurso tecnológico o informático para llevar a cabo esa tarea? En caso afirmativo, detalle cuáles recursos utilizó IV RESULTADOS Y ANÁLISIS Se lograron recolectar el 100% de las respuestas y todos los estudiantes consiguieron entregar el ejercicio a tiempo. Luego de tabular las respuestas, se obtuvieron los resultados que se discuten a continuación. Como se indicó anteriormente, se reportan únicamente los datos de los 34 estudiantes del curso regular. En cuanto a la percepción de proceso de re-identificación, 23 estudiantes (67.7%) calificaron como interesante el ejercicio, 6 (17.6%) como normal, 4 (11.8%) como aburrido y 1 (2.9%) como desafiante. Considerando que se trataba de un ejercicio de otra disciplina, estos resultados apoyan el supuesto de que las temáticas de privacidad digital representan un aspecto importante en la población general, aún para la gente joven. El 85.3% (29 estudiantes) de los encuestados reportaron haber re-identificado correctamente a todos los jugadores (“Percepción de éxito en la re-identificación”) aunque en realidad solo el 61.8% (21 estudiantes) logró reidentificarlos correctamente, lo que nos sugiere que la percepción de éxito no está directamente relacionada con el porcentaje de individuos re-identificados correctamente. A pesar de lo anterior, dado que el 97.1% de un grupo de estudiantes sin conocimientos previos al respecto lograron re-identificar más de 20 jugadores, la conjetura implícita de que la re-identificación no es un proceso particularmente difícil con las herramientas y datos disponibles hoy en día, parece confirmarse. Una anécdota curiosa es que algunos estudiantes no únicamente re-identificaron, sino que hasta detectaron que existía un error (involuntario) en la fecha de nacimiento de un jugador. Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) Las preguntas sobre tecnología utilizada fueron relevantes para detectar que todos los participantes aplicaron medios tecnológicos, lo que aporta evidencia al supuesto de que en la actualidad los datos que se encuentran en la red son accesibles a la mayoría de la población. Por otra parte, las preguntas abiertas sobre tecnología no resultaron útiles para muestrear el uso de términos técnicos en poblaciones no expertas, ni para determinar el peso de diferentes fuentes de información, ya que los niveles de granularidad eran muy variables (por ejemplo, “celular” comparado a “Facebook”). Sin embargo, sí permitieron plantear un refinamiento para estudios futuros del tema, determinando que se debe controlar la granularidad, y referirse a fuentes específicas de información, posiblemente mediante el uso de ejemplos, lo que permitiría un análisis a profundidad de los sitios consultados en cuanto a implicaciones de privacidad. Adicionalmente, la mayoría de los estudiantes expresaron preocupación por el uso que se le da a su información personal, lo cual contrasta con la actitud general del grupo durante la charla, durante la cual se dieron varias muestras de escepticismo ante el tema. Este resultado apoya nuestra hipótesis de que la exposición directa al proceso es más efectiva que la simple divulgación. V CONCLUSIONES Se presentó una forma participativa de concientizar a los jóvenes en temas relacionados con la protección de la privacidad de la información y los resultados de aplicarla a un grupo de estudiantes sin conocimientos previos en el tema. Todos los estudiantes lograron re-identificar a 2/3 o más de los jugadores incluidos en el ejercicio, a pesar de que no fueron capacitados para el proceso, confirmando el supuesto de que no se trata de un proceso muy complejo y quizás de que hay un exceso de información publicada en la red. Por otra parte, al realizar el proceso y determinar la facilidad de re-identificación se evidenció en los estudiantes una preocupación genuina por el uso de sus datos, confirmando la hipótesis de los autores. AGRADECIMIENTOS Al profesor Hugo Solís, por colaborar junto con sus estudiantes del curso FS408 de la escuela de Física de la Universidad de Costa Rica, en el aprendizaje y la concientización de la protección de la privacidad de la información. REFERENCIAS 1. J. DeCew, “Privacy,” The Stanford Encyclopedia ofPhilosophy, 14-May-2014. [Online]. Available: 20 http://plato.stanford.edu/archives/fall2013/entries/privac y/. [Accessed: 14-Oct-2014]. 2. Costa Rica, “Ley de protección de la persona frente al tratamiento de sus datos personales,” La Gaceta., vol. 170, p. 2, 2011. 3. I. Shklovski and J. Vertesi, “‘Un-Googling’ Publications: The Ethics and Problems of Anonymization,” in CHI ’13 Extended Abstracts on Human Factors in Computing Systems on - CHI EA '13, 2013, p. 2169. 4. R. Gopalan, A. Antón, and J. Doyle, “UCON LEGAL,” in Proceedings of the 2nd ACM SIGHIT symposium on International health informatics - IHI ’12, 2012, no. 111, p. 227. 5. A. Westin, “Privacy and freedom,” Wash. Lee Law Rev., 1968. 6. W. A. Parent, “Privacy, morality, and the law,” pp. 201– 215, Jan. 1985. 7. “Twitter sued over Hardy tweet.” [Online]. Available: http://www.smh.com.au/technology/technologynews/twitter-sued-over-hardy-tweet-201202161tbxz.html. [Accessed: 12-Sep-2013]. 8. A. Slagell, K. Lakkaraju, and K. Luo, “FLAIM: A Multi-level Anonymization Framework for Computer and Network Logs.,” LISA, p. 6, Dec. 2006. 9. R. Hayashi and K. Tanaka, “Universally anonymizable public-key encryption,” Adv. Cryptology-ASIACRYPT 2005, pp. 2–12, 2005. 10. A. E. Marwick, D. Murgia-Diaz, and J. G. Palfrey, “Youth, Privacy and Reputation (Literature Review),” 10-29, 2010. 11. P. Ohm, “Broken Promises of Privacy: Responding to the Surprising Failure of Anonymization,” UCLA Law Rev., vol. 57, pp. 1701, 2010, Aug. 2010. 12. S. Watanabe, “Pattern recognition: human and mechanical,” Oct. 1985. 13. S. Ambrose, M. Bridges, M. DiPietro, M. Lovett, and M. Norman, How Learning Works: Seven ResearchBased Principles for Smart Teaching. Jossey-Bass, 2010. 14. K. El Emam, E. Jonker, L. Arbuckle, and B. Malin, “A systematic review of re-identification attacks on health data.,” PLoS One, vol. 6, no. 12, p. e28071, Jan. 2011. 15. K. El Emam, “Methods for the de-identification of electronic health records for genomic research.,” Genome Med., vol. 3, no. 4, p. 25, Jan. 2011. 16. M. G. Rhodes, W. Somvichian, and K. C. Wong, “Google-Motion-to-Dismiss-061313,” 2013 21 Diseño de un proceso de certificación para actores del Sistema Nacional de Certificación Digital de Costa Rica Alejandro Mora Castro y Rodrigo A. Bartels Posgrado en Computación Universidad de Costa Rica {alejandro.moracastro, rodrigo.bartels}@ucr.ac.cr ABSTRACT Una Infraestructura de Llave Pública (PKI) permite solventar el problema de la distribución e intercambio de las llaves en sistemas de cifrado mediante certificados digitales. En el caso de una infraestructura PKI a nivel paı́s, generalmente se utilizan certificados digitales para proveer servicios de firma digital como mecanismo alternativo a la firma fı́sica. En este caso, los errores generados a consecuencia de omisiones o fallas en algún elemento de la infraestructura, pueden comprometer la integridad del sistema completo, además de generar pérdidas económicas, acciones legales y la pérdida de confianza de los usuarios. Este artı́culo presenta los resultados preliminares de un proyecto de investigación para diseñar e implementar un proceso de certificación, para los principales actores del Sistema Nacional de Certificación Digital (SNCD) de Costa Rica, que permita mitigar los riesgos de seguridad de la información relacionados con los componentes de dicho Sistema. Palabras clave Infraestructura de Llave Pública, PKI, Seguridad, Información, Certificado digital, Firma digital. INTRODUCCIÓN Una Infraestructura de Llave Pública (PKI, por sus siglas en inglés) permite solventar el problema de la distribución e intercambio de las llaves secretas en sistemas de cifrado. Su implementación otorga la confianza para emitir certificados digitales a un tercero. Estos certificados son utilizados para verificar la identidad de los usuarios. Una infraestructura PKI provee varios servicios de seguridad. El servicio de autenticación permite validar la identidad de usuarios y máquinas que participan en un sistema de información. El servicio de no repudio sobresale, ya que a través de la funcionalidad de firma digital es posible probar que un usuario o máquina realizó una operación en un determinado momento del tiempo. [3] En Costa Rica, el uso de la tecnologı́a PKI recibe un apoyo importante a nivel gubernamental a partir del año 2005, con la aprobación de la ley 8454 [2], la cual se apoya en los servicios Se autoriza hacer copias de este trabajo o partes de para uso académico, siempre y cuando sea sin fines de lucro. La copia debe contener esta nota y la cita completa en la primera página. La copia bajo otras circunstancias y la distribución o publicación podrı́a requerir permisos adicionales o pago de derechos. JOCICI’15, Marzo 5-6, San José, Costa Rica. c Copyright 2015 CITIC-PCI Ricardo Villalón Fonseca CITIC Universidad de Costa Rica [email protected] de autenticación y no repudio para otorgar a la firma digital la misma validez que su equivalente manuscrita. Además, con el anuncio de la directriz gubernamental 067-MICITT-H-MEIC [11] en abril del 2014, se faculta al ciudadano costarricense a exigir la prestación de servicios por medio de la firma digital en todas las entidades de gobierno. A partir de este momento, se hace necesario contar con polı́ticas, normas y regulaciones apoyadas por estándares internacionales, pero ajustadas al entorno costarricense, que promuevan una apropiada asimilación y masificación de la firma digital a nivel nacional. El proyecto de investigación contempla la creación de un sistema de certificación que defina los requerimientos técnicos, procedimientos y sistemas de gestión para certificar a los principales actores involucrados en la prestación de servicios dentro del Sistema Nacional de Certificación Digital de Costa Rica (SNCD). Inicialmente se han considerado las autoridades certificadoras (CA, por sus siglas en inglés), encargadas de emitir y validar certificados digitales, ası́ como los proveedores de servicios, que suministran aplicaciones de software que permiten al usuario final utilizar certificados digitales para realizar transacciones de forma segura. El artı́culo presenta los esfuerzos iniciales realizados durante la ejecución del proyecto para la definición de la metodologı́a de trabajo y los elementos necesarios para la creación del sistema de certificación. El artı́culo está organizado de la siguiente forma. Inicialmente se describe el contexto en el cual se desarrolla el proyecto. Luego se presenta la legislación relevante, los actores y el estado actual del SNCD. Posteriormente se describe el sistema de certificación propuesto. Finalmente, el artı́culo muestra el trabajo pendiente en el proyecto. ANTECEDENTES El origen de la certificación digital en Costa Rica se remonta al año 2002, cuando el Poder Ejecutivo presentó a la Asamblea Legislativa un proyecto con el que buscaba legislar el uso de la firma digital. El 22 de agosto del 2005 se logró la aprobación de la Ley 8454 [2], Ley de Certificados, Firmas Digitales y Documentos Electrónicos. En esta ley se define el marco legal para el uso de certificados y firmas digitales como un mecanismo equivalente a la firma manuscrita, ası́ como su validez y aplicabilidad a documentos electrónicos. La Ley 8454 también regula a los actores del SNCD y crea la Dirección de Certificadores de Firma Digital (DCFD), un ente Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) adscrito al Ministerio de Ciencia, Tecnologı́a y Telecomunicaciones (MICITT), y encargado de proveer vı́a reglamento los requisitos que deben cumplir los distintos componentes del Sistema. En el año 2014, el Gobierno de la República emite la directriz 067-MICITT-H-MEIC [11], en la cual decreta que todas las instituciones del sector público costarricense deben tomar las medidas técnicas y financieras necesarias para que las personas fı́sicas puedan utilizar la capacidad de firma digital en cualquier escenario, tanto para autenticarse como para firmar documentos por la vı́a electrónica. Con esta directriz, más de 300 entidades del sector público deben adaptar sus servicios actuales para soportar certificados y firma digital, por lo que una gran cantidad de aplicaciones deben ser implementadas o mejoradas en el corto y mediano plazo. ACTORES DEL SISTEMA NACIONAL DE CERTIFICACIÓN DIGITAL En una infraestructura PKI participan diversos actores, cada uno con roles diferentes dentro del proceso para emitir y usar certificados digitales. En el contexto del SNCD, el MICITT es el dueño de los certificados raı́z y es el ente encargado de aprobar la creación de las CA en el paı́s. Una CA es una entidad de confianza, responsable de emitir y revocar los certificados digitales utilizados para firmar documentos digitalmente y mitigar riesgos relacionados con el no repudio de las acciones realizadas por parte del poseedor de un certificado digital. El Reglamento a la Ley de Certificados, Firmas Digitales y Documentos Electrónicos [10] le confirió el grado de Autoridad Certificadora Raı́z del SNCD a la DCDF, sin embargo, en la actualidad existe un convenio de cooperación entre el MICITT y el Banco Central de Costa Rica (BCCR), por lo que este último es el encargado de implementar, custodiar y operar la raı́z del Sistema, ası́ como de proveer certificados digitales a los ciudadanos. Además, el reglamento permite la implementación de múltiples CA, públicas o privadas, e incluye la posibilidad de convalidar certificados generados por CA extranjeras. Un proveedor de servicios es una organización que presta servicios a través de aplicaciones de software que utilizan firma digital. Un ejemplo es una entidad bancaria pública o privada que provee un portal en lı́nea, el cual permite a sus clientes utilizar certificados digitales, con el de fin autenticar de forma inequı́voca a una persona y ası́ brindar mayor seguridad en la realización de transacciones. Por último está el usuario final, beneficiario de los servicios, que puede ser una persona fı́sica o una persona jurı́dica. ESTADO ACTUAL DEL SNCD En Costa Rica, el Reglamento a la Ley de Certificados, Firmas Digitales y Documentos Electrónicos [10], publicado en el 2006, define los requisitos que debe cumplir una entidad para poder registrarse como autoridad certificadora dentro del SNCD: Artı́culo 11. Comprobación de idoneidad técnica y administrativa. Para obtener la condición de certificador 22 registrado, se requiere poseer idoneidad técnica y administrativa, que serán valoradas por el ECA, de conformidad con los lineamientos técnicos establecidos en las Normas INTE/ISO/IEC 17021 e INTE/ISO 21188 versión vigente, las polı́ticas fijadas por la DCFD y los restantes requisitos que esa dependencia establezca, de acuerdo con su normativa especı́fica. [10] Luego de la experiencia adquirida por el MICITT y el BCCR al implementar la Autoridad Certificadora actual, se observó que los requisitos estipulados en el artı́culo 11 del reglamento a la ley 8454 pueden ser adaptados al considerar con mayor profundidad algunos aspectos del contexto y la realidad nacional. Luego de varias sesiones de trabajo con personal de ambas instituciones, se identificó lo siguiente: 1. Existen diversos estándares a nivel internacional para la implementación y certificación de CA, y de infraestructuras PKI en general, que no son mencionados en el artı́culo 11. A partir de la existencia de estos estándares, se hace necesario realizar una evaluación de cada uno de ellos para analizar e identificar los elementos que podrı́an considerarse, adicionalmente o en sustitución de los requisitos existentes. 2. El estándar ISO 21188 [14], está definido en el marco de entidades financieras, para infraestructuras de uso generalmente comercial, por lo que podrı́an existir requisitos que no son aplicables en el escenario de una infraestructura PKI a nivel paı́s. 3. El instrumento utilizado actualmente para las evaluaciones de CA (desarrollado por la DCFD mediante una revisión de los estándares 21188 y 17021) refleja las polı́ticas iniciales requeridas para la implementación de una CA de forma exitosa y segura en el paı́s, con base en los casos existentes. Sin embargo, podrı́an existir elementos en los otros estándares que sean valiosos en el contexto nacional, y que contribuyan a mejorar la seguridad y la confianza del Sistema. Con datos obtenidos a través del MICITT, se ha observado un incremento del número de aplicaciones públicas y privadas, que aceptan certificados digitales por medio de proveedores de servicios que utilizan firma digital. Sin embargo, la experiencia del personal del MICITT y del BCCR ha mostrado que estos desarrollos son producto de esfuerzos independientes de cada institución, lo cual no permite garantizar que: Cumplen con las leyes, reglamentos y polı́ticas definidas por el SNCD. Disponen de servicios de seguridad tales como autenticación, no repudio, integridad y confidencialidad, fundamentales en este contexto. Utilizan las mejores prácticas de implementación a nivel de código fuente para el manejo seguro y eficiente de los certificados digitales. Con el fin de solventar los elementos presentados anteriormente, se describe a continuación el sistema de certificación propuesto, el cual permitirá evaluar tanto CA como proveedores de servicios, con base en los requisitos definidos por el MICITT. Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) SISTEMA DE CERTIFICACIÓN PROPUESTO Para establecer niveles apropiados en la seguridad de la información para los servicios que utilizan firma digital, se decidió recurrir a estándares internacionales que evalúan la conformidad de productos y servicios. Se utilizará el estándar ISO/IEC 17067:2014 ”Evaluación de la conformidad - Fundamentos de la certificación de producto y directrices para los esquemas de certificación de producto” [16], el cual provee un marco de referencia apropiado para la certificación de servicios que utilizan firma digital. El apartado 5.3.8 del estándar ISO/IEC 17067 describe el tipo de esquema 6, el cual está dirigido a la certificación de servicios y procesos. El esquema se refiere a la evaluación de servicios tangibles e intangibles. En nuestro caso, los servicios intangibles son los servicios de seguridad de la información como el no repudio, la autenticación, la confidencialidad, y otros. Los elementos tangibles corresponden a controles y mecanismos de seguridad aplicados a la información; por ejemplo la inspección de un componente de software, que cifra datos en la comunicación de un usuario con un servicio, permitirı́a detectar vulnerabilidades en el tránsito de la información entre el origen y el destino. Además, el tipo de esquema mencionado anteriormente incluye auditorı́as periódicas al sistema de gestión, y evaluaciones periódicas del servicio, lo cual es importante, pues las aplicaciones de software son, por naturaleza, susceptibles a nuevas vulnerabilidades detectadas en el tiempo, y esto obliga a realizar revisiones regularmente, que permitan ajustar los parámetros y configuración del sistema de seguridad. Para implementar los procesos de certificación se decidió utilizar un sistema de certificación, tal y como se describe en la sección 6.2 del estándar ISO/IEC 17067. Un sistema de certificación establece un grupo común de reglas, procedimientos y una gestión comunes para dos o más esquemas. Cada esquema dentro del sistema define los requisitos especı́ficos para los servicios o procesos al cual aplica. En nuestro caso los servicios son dos, y corresponden a las CA y a los proveedores de servicios que utilizan firma digital. Al usar el formato de sistema de certificación, se habilita la posibilidad de extender la infraestructura de certificación con nuevos esquemas para futuros servicios. Dentro de los elementos necesarios para definir un esquema de certificación, el más relevante desde la perspectiva técnica es el relacionado con los requisitos para la evaluación del servicio (apartado 6.5.1.b del estándar 17067). Por esta razón, es necesario definir los elementos que debe cumplir cada uno de los actores dentro del SNCD. Para cada uno de los servicios mencionados, se procedió a realizar una recopilación de los estándares o normas existentes, la literatura y legislación utilizada en otros paı́ses, y la definición de los requisitos a nivel nacional mediante sesiones de trabajo con funcionarios de la DCFD y el BCCR. En el caso de las CA, se realizó una revisión de documentación disponible a nivel mundial para evaluar su aplicabilidad dentro del SNCD. Se identificaron tres estándares relevantes que serán analizados: 23 1. Estándar ISO-21188: definido para la implementación de infraestructuras PKI en entidades financieras [2]. 2. AICPA/CICA WebTrust Program for Certification Authorities [4]: definido por Canadian Institute of Chartered Accountants y utilizado en los Estados Unidos y Canadá. 3. European Standard: Policy requirements for Certification Authorities issuing public key certificates (EN 319 411-3) [6]: definido por la Unión Europea. En el caso de los proveedores de servicios, para definir un proceso de aseguramiento de la información, se realizó un análisis de los escenarios en los que una aplicación de software utiliza certificados y firma digital, y se procedió a recopilar estándares y guı́as de desarrollo disponibles a nivel mundial. Con base en los artı́culos 3 y 4 de la directriz 067-MICITT-HMEIC [11], se identificaron los escenarios que requieren un proceso de aseguramiento riguroso y que deberı́an ser analizados detalladamente, tanto en aplicaciones de software existentes como en nuevos desarrollos. Dichos escenarios son: Autenticación mediante firma digital. Creación y verificación de firma digital. Creación y verificación de firma digital mediante el uso de certificados digitales de Sello Electrónico de Persona Jurı́dica. Posteriormente, se realizó una revisión de la literatura disponible, con el fin de apoyar la identificación de elementos relevantes, aplicables al contexto costarricense. Se encontraron los siguientes documentos: Unión Europea: la Directiva 1999/93/CE del Parlamento Europeo y del Concejo del 13 de diciembre de 1999 [7] establece un marco comunitario para la firma electrónica en ese continente, por lo que se realizaron esfuerzos para estandarizar la implementación y evaluación de sistemas relacionados con firmas electrónicas. España: la Polı́tica de Firma Electrónica y de Certificados de la Administración General del Estado [5] especifica, entre otros, requerimientos para los formatos admitidos en documentos firmados, la validación de la firma electrónica, la comprobación de la validez de los certificados y la validez de las firmas a lo largo del tiempo. Alemania: la Oficina Federal para la Seguridad de la Información (BSI, por sus siglas en alemán) publicó la guı́a técnica Preservation of Evidence of Cryptographically Signed Documents - Annex TR-ESOR-M.2: Cryptographic-Module [8] en la que establece lineamientos para la creación y verificación de firmas electrónicas, validación de certificados, estampado de tiempo y administración de llaves criptográficas. Bélgica: a partir de los doce años, todo ciudadano belga es portador de una tarjeta (eID) que contiene un chip que almacena certificados digitales, con el cual pueden autenticarse en distintas aplicaciones, ası́ como firmar documentos digitalmente. Se ha optado por utilizar código abierto para colaborar con los desarrolladores de aplicaciones, para lo cual se han desarrollado guı́as técnicas como The Electronic Identity Card (eID) - Developers Guide Version [9]. Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) 24 Brasil: la infraestructura PKI brasileña provee documentación [12], [13] que especifica los requerimientos técnicos para la homologación y evaluación de software de firma digital. Se definen lineamientos generales para seguridad, documentación y certificados digitales. 5. Comisión Permanente del Consejo Superior de Administración Electrónica. Polı́tica de Firma Electrónica y de Certificados de la Administración General del Estado. Ministerio de Hacienda y Administraciones Públicas de España, Mayo 2012. Finalmente, el cumplimiento de los esquemas debe ser certificado por un ente acreditado para tal efecto. Para obtener los credenciales de certificador se debe aprobar un proceso de acreditación según se establece en el estándar INTE ISO/IEC 17065:2013 ”Evaluación de la conformidad - Requisitos para organismos que certifican productos, procesos y servicios” [15]. El organismo encargado de realizar el proceso de acreditación es el Ente Costarricense de Acreditación (ECA) [1]. 6. ETSI. Policy requirements for certification authorities issuing qualified certificates. Tech. rep., 2013. TRABAJO FUTURO A nivel de las CA, debe completarse el análisis de los estándares mencionados, para identificar los elementos que serán incluidos en el esquema de certificación. Con base en los resultados obtenidos, se podrán definir los requerimientos técnicos a ser utilizados durante la redacción del esquema de certificación para las CA a nivel nacional. En cuanto a la certificación de proveedores de servicios dentro del SNCD, el trabajo futuro incluye el análisis de los escenarios mencionados anteriormente, que permita identificar los riesgos de seguridad, establecer las polı́ticas de seguridad para mitigar los riesgos identificados y que considere los controles de seguridad requeridos para hacer cumplir las polı́ticas. Estos elementos serán parte del insumo requerido para la elaboración del esquema de certificación para proveedores de servicio. Además, una vez establecido el sistema y los esquemas de certificación, se hará necesaria la definición de los requisitos de las entidades que deseen acreditarse, con el fin de llevar a cabo los procesos de certificación, con base en los esquemas definidos. En este proceso se utilizará el estándar INTE ISO/IEC 17065:2013, indicado previamente. 7. Eur-Lex. Directive 1999/93/EC of the European Parliament and of the Council of 13 December 1999 on a Community framework for electronic signatures, Diciembre 1999. 8. Federal Office for Information Security. BSI Technical Guideline 03125 Preservation of Evidence of Cryptographically Signed Documents - Annex TR-ESOR-M.2: Cryptographic-Module, Febrero 2011. 9. Fedict. The Electronic Identity Card (eID) - Developers Guide Version, 1.0˜ed. Federal Public Service for Information and Communication Technology. 10. Gobierno de Costa Rica. Reglamento a la Ley de Certificados, Firmas Digitales y Documentos Electrónicos. Decreto Ejecutivo N 33018-MICIT (2006). 11. Gobierno de Costa Rica. Masificación de la implementación y el uso de la firma digital en el sector público costarricense. Diario Oficial La Gaceta 136, 79 (Abril 2014), 49–51. 12. Instituto Nacional de Tecnologia da Informação. Manual de Condutas Técnicas 4 - Volume I: Requisitos, Materiais e Documentos Técnicos para Homologação de Softwares de Assinatura Digital no Âmbito da ICP-Brasil, 2.0˜ed., Noviembre 2007. AGRADECIMIENTOS 13. Instituto Nacional de Tecnologia da Informação. Manual de Condutas Técnicas 4 - Volume II: Procedimentos de Ensaios para Avaliação de Conformidade aos Requisitos Técnicos de Softwares de Assinatura Digital no Âmbito da ICP-Brasil, 2.0˜ed., Noviembre 2007. Agradecemos a la Dirección de Certificadores de Firma Digital del MICITT, ası́ como al personal del Área de Seguridad de la División de Servicios Tecnológicos del BCCR, por el invaluable apoyo durante el desarrollo de este proyecto. 14. International Organization for Standardization. Norma INTE/ISO 21188:2007 Infraestructura de llave pública para servicios financieros - Estructura de prácticas y polı́ticas. Tech. rep., 2007. REFERENCIAS 1. Asamblea Legislativa de la República de Costa Rica. Sistema Nacional de Calidad, 2002. 2. Asamblea Legislativa de la República de Costa Rica. Ley de Certificados, Firmas Digitales y Documentos Electrónicos, 2005. 3. Buchmann, J.˜A., Karatsiolis, E., and Wiesmaier, A. Introduction to PKI Infrastructures. Springer, 2013. 4. Canadian Institute of Chartered Accountants. Trust Service Principles and Criteria for Certification Authorities. Tech. rep., 2011. 15. International Organization for Standardization. Conformity assessment – Requirements for bodies certifying products, processes and services. Tech. rep., 2012. 16. International Organization for Standardization. Conformity assessment – Fundamentals of product certification and guidelines for product certification schemes. Tech. rep., 2013. 25 Comprensión de la máquina nocional a través de enseñanza tradicional Jeisson Hidalgo-Céspedes, Gabriela Marín-Raventós, Vladimir Lara-Villagrán Centro de Investigaciones en Tecnologías de la Información y Comunicación (CITIC) Universidad de Costa Rica {jeisson.hidalgo, gabriela.marin, vladimir.lara}@ucr.ac.cr ABSTRACT Para aprender a programar en un lenguaje de programación es requisito tener una correcta comprensión de su máquina nocional. Los estudiantes adquieren esta comprensión principalmente a través de las explicaciones verbales y visuales de profesores, libros, vídeos u otros medios. Esta investigación en progreso evalúa la comprensión de la máquina nocional de C++ tras un curso de Programación II impartido en modalidad "tradicional". Las conclusiones revelan que este método es insuficiente para alcanzar la comprensión requerida. lenguajes de programación, a través de sus constructos, proveen una abstracción de la máquina real que Boulay en 1981 llamó máquina nocional [2]. Cada lenguaje de programación provee una máquina nocional. Por ejemplo, un programador de C podría pensar que la máquina tiene tipos de datos y ejecuta funciones, cuando la máquina real no dispone de estos constructos. Un programador de Java podría creer que la máquina es capaz de ejecutar métodos polimórficamente y dispone de un recolector de basura [7]. La parte derecha de la Figura 1 representa la relación entre la máquina nocional y la máquina real. Author Keywords Programming learning; constructivism; notional machine; program visualization ACM Classification Keywords K.3.2. Computer and Information Science Education: Computer science education 1. INTRODUCCIÓN A diferencia de otros tipos de textos, como novelas o artículos científicos, el código fuente de los programas para computadora tiene un dualismo que es obvio para programadores consolidados. El código fuente se escribe de forma estática, usualmente en editores de texto. Sin embargo, el código tiene un comportamiento dinámico a la hora de ejecutarse en la computadora. Una comprensión correcta del comportamiento dinámico es imprescindible a la hora de escribir el código estático, y esta habilidad es especialmente difícil para algunos estudiantes [6]. Para comprender el comportamiento del código en tiempo de ejecución, es necesario comprender cómo trabaja la máquina que se está programando. Es común que varios cursos se incluyan en las carreras de computación con este objetivo, como circuitos, arquitectura de computadoras y ensambladores [1], los cuales no necesariamente son previos a los cursos de programación. Sin embargo, no es requisito el dominio de la máquina real para comprender la dinámica de los programas en tiempo de ejecución. Los Se autoriza hacer copias de este trabajo o partes de él para uso académico, siempre y cuando sea sin fines de lucro. La copia debe contener esta nota y la cita completa en la primera página. La copia bajo otras circunstancias y la distribución o publicación podría requerir permisos adicionales o pago de derechos. JoCICI 2015, Marzo 5-6, San José, Costa Rica. Copyright © 2015 CITIC-PCI Figura 1. Modelos mentales de la máquina nocional. En su tesis doctoral, Sorva indica que los estudiantes no se apropian directamente la máquina nocional del lenguaje en que programan, sino que crean modelos mentales de ella [6], como se diagrama en extremo izquierdo de la Figura 1. Los modelos mentales son subjetivos y basados en creencias, por lo que son propensos a imprecisiones. Amparado por amplia literatura científica, Sorva afirma que modelos mentales correctos de la máquina nocional son ineludibles para el aprendizaje de la programación [6,7]. Los estudiantes construyen los modelos mentales de la máquina nocional a través de las explicaciones verbales y visuales que realizan los profesores y los materiales didácticos empleados. A menos de que se cree una nueva máquina o un lenguaje de programación, los seis elementos rotulados en la Figura 1 son inalterables para el profesor, a excepción de las ilustraciones o explicaciones que se hagan de la máquina nocional. El objetivo de este trabajo es evaluar cualitativamente la comprensión (los modelos mentales) que tienen los estudiantes de la máquina nocional de C++, tras haber tomado un curso de programación que utiliza este lenguaje, siguiendo una didáctica tradicional (clases magistrales). La sección que continúa explica el coloquio, el método utilizado para evaluar los modelos mentales. La sección 3 expone los resultados obtenidos de los coloquios. Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) Finalmente, la sección 4 discute el aporte de estos resultados y cómo enriquecer la investigación afín. 2. METODOLOGÍA Se tomó como escenario el curso de Programación II de la carrera de Computación, impartido por el primer autor durante agosto a noviembre de 2014 en la Universidad de Costa Rica. Por convención el lenguaje de programación utilizado en este curso fue C++. La modalidad didáctica fue magistral. Es decir, los estudiantes construyeron modelos mentales de la máquina nocional de C++, principalmente a través de las explicaciones e ilustraciones creadas por el profesor durante las lecciones. Para cada concepto de programación el profesor aplicó el principio de contraposición conceptual [4] a la clase magistral. Por ejemplo, a la hora de introducir el concepto de apuntador, el profesor escribió un programa en la computadora de proyección. El programa incluía una función que pretendía intercambiar (swap) dos números recibidos como parámetros por valor. Los recibía de esta forma pues son los conceptos ya presentes en la mente de los estudiantes, y los que probablemente utilicen para implementar el intercambio. A vista de los estudiantes el programa parecía perfecto. El profesor corrió el programa en la computadora de proyección, el cual produjo un resultado incorrecto. Ver fallar el programa que parecía perfecto debió propiciar un estado de incertidumbre mental, necesario para el aprendizaje del nuevo concepto [4]. El profesor explicó el comportamiento del programa línea tras línea ilustrándolo en la máquina nocional con el fin de hacer evidente la causa del fallo. La máquina nocional de C/C++ es muy cercana a la física. El profesor cuidadosamente dibujó en la pizarra la memoria del programa dividida en cuatro segmentos, y actuó como el procesador leyendo y moviendo datos al seguir paso a paso las instrucciones del programa. Tras haber observado que el programa falla y su causa, el estudiante aún continúa en estado de incertidumbre mental y requiere saber cómo se corrige. El profesor entonces introdujo el nuevo concepto, en este caso, el apuntador y su sintaxis. Corrigió el programa y lo ejecutó manualmente actualizando en las ilustraciones de la máquina nocional el efecto de los apuntadores. Finalmente ejecutó el programa en el equipo de proyección, el cual produjo el resultado esperado. Este método de introducir el concepto tras una contraposición conceptual y su efecto en la máquina nocional, se aplicó reiteradamente para cada concepto que tiene efecto en el estado del programa. ¿Habrán construido los estudiantes modelos mentales correctos de la máquina nocional? Para evaluar los modelos mentales de la máquina nocional, se realizaron coloquios a cambio de puntos adicionales para la nota del curso al finalizar el semestre. El coloquio es un 26 método de evaluación formativa ampliamente utilizado por los autores del constructivismo social [4]. Consiste en un diálogo entre el profesor y el estudiante mientras el segundo realiza una tarea educativa. En una primera fase el profesor sólo indaga el nivel de dominio que tiene el estudiante sobre el contenido y las habilidades evaluadas, llamado nivel de desarrollo efectivo [4]. En una segunda fase, el profesor solicita al estudiante regresar a la tarea, en especial adonde ha detectado deficiencias cognitivas. El profesor provee preguntas clave, información, herramientas o consejos que ayudan al estudiante a sobrepasar las deficiencias (andamiaje). Es decir, el profesor influye en la zona de desarrollo próximo del estudiante y evalúa el nivel de desarrollo potencial que el estudiante logró alcanzar con esta ayuda [4]. La primera fase está más orientada a la evaluación, la segunda más al aprendizaje del estudiante. La tarea educativa escogida fue la siguiente. Se le pidió a cada estudiante que ejecutara línea a línea el programa de C++ listado en la Figura 2. En cada línea debía explicar qué hace la máquina nocional para ejecutarla. Se le brindó al estudiante una hoja en blanco y se le solicitó que dibujara el estado del programa. El coloquio fue grabado sólo en audio. No hubo restricciones de tiempo. Los estudiantes tuvieron acceso a la documentación del algoritmo std::sort(). El programa de la Figura 2 calcula la mediana de conjuntos de datos ingresados en la entrada estándar. Cada conjunto de datos es precedido por su tamaño. Se le indicó a cada estudiante asumir que el usuario del programa introduce los valores (3, 100, 70, 90, EOF), donde el 3 indica que el conjunto de datos tiene tres valores. Para el segundo conjunto se ingresa el carácter especial fin-de-archivo (EOF) como su tamaño. El programa reacciona terminando su ejecución. Cada vez que se invoca al método calc(), se crea un arreglo en memoria dinámica (línea 06) que no es eliminado, y por tanto genera una fuga de memoria. Las declaraciones de este párrafo no fueron comunicadas a los estudiantes, excepto los datos de entrada. 01 02 03 04 05 06 07 08 09 10 11 12 13 14 15 16 18 19 20 21 22 23 24 25 #include <algorithm> #include <iostream> void calc(size_t size) { double* arr = new double[size]; for ( size_t i = 0; i < size; ++i ) std::cin >> arr[i]; std::sort(arr, arr + size); if ( size % 2 == 0 ) std::cout<<(arr[size/2] + arr[size/2 - 1]) / 2; else std::cout << arr[size / 2]; } int main() { size_t size; while ( std::cin >> size ) calc(size); return 0; } Figura 2. Programa en C++ utilizado para evaluar. Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) 3. RESULTADOS Participaron 11 estudiantes de 13 activos al finalizar el semestre. En general se encontró que los estudiantes tienen claros los conceptos de entrada y salida de datos, la invocación de funciones, y la iteración con el ciclo for. En lo siguiente se hace un resumen de la actuación de cada uno de ellos, en especial en aquellos indicios relacionados con modelos mentales de la máquina nocional. Participante 1. Distingue el heap segment pero no los demás segmentos. Ubica dos variables locales en un segmento sin nombre. No separa las invocaciones de funciones. Agrega el tamaño del arreglo (variable local) como primer elemento del arreglo en memoria dinámica, que lo lleva a decisiones e impresiones incorrectas. Detecta y corrige la fuga de memoria sólo con andamiaje. Participante 2. No recuerda los nombres de los segmentos de memoria, pero tiene una idea clara de su uso. Duda con los tamaños de los arreglos, e inventa valores temporales cuando no son requeridos. Realiza divisiones reales de índices en lugar de divisiones enteras y se confunde al acceder a los arreglos (línea 15). A través de supuestos llega a la impresión correcta de los resultados. Detecta y corrige correctamente la fuga de memoria. Participante 3. Muestra una disociación entre lo verbal y lo lógico. Explica apropiadamente los cuatro segmentos en forma verbal, pero al recorrer el programa hace un uso incorrecto de los mismos. Por ejemplo, ubica tanto al apuntador como el arreglo en la memoria dinámica (línea 06) como si fuese un nodo de una clase contenedora. Duda si la división entera descarta o redondea decimales. Se inclina por el redondeo hacia abajo por lo que llega a imprimir el resultado correcto. Detecta la fuga de memoria y la corrige correctamente. Participante 4. Tiene vagos recuerdos de los segmentos de memoria. Utiliza términos genéricos, como secciones o espacios en lugar de segmentos. Confunde apuntador con arreglo. Duplica las invocaciones de funciones en el segmento de pila. Realiza las divisiones enteras e imprime el valor correcto en la pantalla. Detecta la fuga de memoria, pero trata de corregirla con la función de biblioteca free(). Requiere andamiaje para recordar el operador delete[]. Participante 5. No recuerda los nombres de los segmentos, pero logra indicar que hay tres "partes": "donde van las cosas dinámicas", "donde se corren los métodos", y "donde se guardan las variables globales". No separa las invocaciones entre funciones. Separa correctamente entre apuntador y el arreglo apuntado. Agrega incorrectamente el carácter fin de cadena ('\0') a un arreglo de números reales. Tiene serias dificultades para realizar la división 3/2 y utilizar el resultado como índice en un arreglo. Opina que el programa no debe compilar, y si lo hace, se debe caer. No detecta la fuga de memoria. Termina la ejecución del programa abruptamente. 27 Participante 6. Recuerda que existen segmentos de memoria. Uno de ellos se utiliza para recursos del sistema operativo. Hace la división entre ellos, pero todas las variables las ubica "donde van las funciones" porque "este programa no usa memoria dinámica". No distingue claramente entre el apuntador y el arreglo. Realiza correctamente los módulos y divisiones enteras, e imprime el elemento central. No detecta la fuga de memoria. Participante 7. Indica que las variables locales van en el segmento de datos, pero luego duda. Termina por separar las funciones de la memoria dinámica sin poder explicar por qué. Crea tanto un apuntador como una función, ambos llamados calc sin poder explicar la diferencia. Hace correctamente los módulos y divisiones enteras. Imprime el valor correcto. Tiene serias dudas de cómo el control sale del ciclo en la línea 21, sin embargo, luego de unos minutos lo recuerda espontáneamente. Requirió andamiaje para detectar la fuga de memoria. Participante 8. Separa en el dibujo entre variables locales, invocaciones de funciones, y memoria dinámica. Sin embargo, hace a las variables locales tener sus valores en la memoria dinámica. Duda cómo trabaja el módulo y la división entera. No puede explicar cómo la computadora indexa en el arreglo a partir de un número real (el resultado de la división 3/2). Asume que la computadora toma la parte entera de la división, pero luego duda. Indica que la computadora elimina la memoria dinámica automáticamente. Participante 9. Distingue correctamente entre el segmento de código y el de memoria dinámica. Sin embargo, separa el segmento de pila (no recuerda el nombre) en dos, uno para variables y otro para invocaciones de métodos. Interpreta inicialmente el "módulo 2" como equivalente a preguntar si el número es par. Luego duda, e indica que el programa debe caerse en tiempo de ejecución. Con andamiaje indica que el programa imprime valores espurios. Indica que los vectores en memoria dinámica se destruyen automáticamente. Termina abruptamente la ejecución del programa. Con andamiaje llega a resultados incorrectos del programa. Requirió explicaciones de funcionamiento de la división entera para llegar al resultado correcto. Participante 10. Recuerda correctamente los cuatro segmentos de memoria y su funcionalidad, excepto que ubica las variables locales en el segmento de datos, separadas de las invocaciones de funciones. Confunde los valores de variables integrales con valores de apuntadores. Tiene dudas sobre el módulo y la división entera, aunque realiza correctamente las operaciones. Indexa el vector iniciando en 1, requiere andamiaje para descubrirlo. No descubre la fuga de memoria; indica que la memoria dinámica se libera automáticamente. Participante 11. Recuerda correctamente el propósito de tres segmentos (omite el segmento de código). Entrelaza Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) correctamente las variables locales con las invocaciones de funciones. Sin embargo, incluye también algunas instrucciones de código en este segmento. Realiza correctamente los módulos y divisiones enteras. Se equivoca al imprimir los resultados. Al solicitarle que vuelva a ejecutar el cálculo, lo hace correctamente. Detecta la fuga de memoria y la corrige adecuadamente. Todos los estudiantes examinaron la documentación del algoritmo std::sort() y aplicaron el efecto correcto en sus ejecuciones del programa. Sin embargo, la mitad tuvo dudas con la aritmética de punteros en la expresión arr + size en la línea 11, por tratarse de una posición no válida del arreglo. Los estudiantes que señalaron esta situación revelan una comprensión clara de aritmética de punteros, pero no de iteradores de la biblioteca estándar de C++. El algoritmo std::sort(begin,end) recibe dos iteradores begin y end, y ordena los valores comprendidos en el intervalo [begin, end[. Nótese que aproximadamente tres de cada cuatro estudiantes tuvo dudas sobre la operación del módulo y la división entera. Esos temas no se cubren en el curso de Programación II, sino que se asumen aprendidos en cursos previos. 4. DISCUSIÓN Y TRABAJO FUTURO Los resultados revelan que la población de estudiantes evaluada posee modelos mentales deficientes de la máquina nocional de C++, tras haber tomado un curso "tradicional" de Programación II. Aunque no se puede determinar la causa a partir de los datos obtenidos, de los seis elementos que componen el modelo teórico diagramado en la Figura 1, las explicaciones e ilustraciones ofrecidas por el profesor o los materiales de instrucción, tienen un efecto inmediato e importante por mediar directamente entre la máquina nocional y los modelos mentales de los estudiantes. Amplia literatura científica compilada por Sorva et. al. [5] señala la poca pertinencia de los materiales estáticos, tales como ilustraciones en la pizarra, en libros, o animaciones en vídeo; para explicar un fenómeno inherentemente dinámico. Desde 1985 hasta la actualidad, un número creciente de visualizaciones de programas se han propuesto como una solución al problema [5]. Sin embargo, sus evaluaciones científicas revelan una mezcla de resultados, que no permiten aún concluir si las visualizaciones incrementan significativamente la comprensión o el aprendizaje del comportamiento dinámico de los conceptos de programación [5]. Pero sí hay una notoria evidencia de la falta de uso de las visualizaciones de programa en los ambientes de aprendizaje de la programación [5]. Estos dos resultados no son sorpresa al examinar las visualizaciones de programas como herramientas de aprendizaje ante la teoría constructivista. El constructivismo indica que el aprendizaje ocurre únicamente en condición activa de la mente [4]. Si el estudiante se mantiene como un observador pasivo del profesor en el salón de clases, o ante una visualización de programa realizada por la computadora, no producirá un aprendizaje real. Sorva conocía este hecho y 28 en su tesis doctoral desarrolla UUhistle, una visualización de la máquina nocional de Python que opera en dos modos: (1) la computadora realiza la visualización y (2) el estudiante realiza la visualización [6]. UUhistle no atiende otros principios del constructivismo, en especial la motivación y la interacción social. Esta investigación en progreso propone aplicar principios de ludificación [3] al diseño de visualizaciones de la máquina nocional para llenar este vacío. El resultado de esta aplicación son videojuegos. Existen varios videojuegos de programación, como CodeSpells y CodeCombat, los cuales requieren que el jugador cree programas para resolver retos del juego. Sin embargo, no son visualizaciones del estado de esos programas en la máquina nocional del lenguaje en que se escriben. El reto aquí planteado involucra idear una metáfora de la máquina nocional que permita crear un juego que visualice programas. Es decir, esta metáfora debe ser lo suficientemente versátil para crear una problemática ficticia intrigante al estudiante, cuya solución requiere la creación o modificación de programas con un nivel de reto incremental, los cuales al ejecutarse son visualizados en una representación de la máquina nocional que es natural en la narración del juego. ¿Construirán los estudiantes modelos mentales correctos de la máquina nocional jugando con esta propuesta? AGRADECIMIENTOS Esta investigación es fruto del proyecto 834-B3-255 del CITIC y la ECCI de la UCR, con apoyo del MICITT. REFERENCIAS 1. ACM and IEEE Computer Society. Computer Science 2013: Curriculum Guidelines for Undergraduate Programs in Computer Science. 2013. 2. Boulay, B. du, O’Shea, T., and Monk, J. The black box inside the glass box: presenting computing concepts to novices. International Journal of Man-Machine Studies 14, 3 (1981), 237–249. 3. Kapp, K.M. The Gamification of Learning and Instruction: Game-based Methods and Strategies for Training and Education. Pfeiffer, 2012. 4. Luria, Leontiev, and Vigotsky. Psicología y pedagogía. Ediciones Akal, Sevilla, España, 1986. 5. Sorva, J., Karavirta, V., and Malmi, L. A Review of Generic Program Visualization Systems for Introductory Programming Education. ACM Transactions on Computing Education 13, 4 (2013), 1–64. 6. Sorva, J. Visual Program Simulation in IntroductoryProgramming Education. 2012. http://lib.tkk.fi/Diss/2012/isbn9789526046266/. 7. Sorva, J. Notional machines and introductory programming education. ACM Transactions on Computing Education 13, 2 (2013), 1–31. 29 Representación de estrategias en juegos utilizando un modelo del conocimiento Juan Carlos Saborı́o, Álvaro de la Ossa Colaboratorio Nacional de Computación Avanzada, Centro Nacional de Alta Tecnologı́a San José, Costa Rica {jcsaborio, delaossa}@cenat.ac.cr ABSTRACT El espacio de estados en dominios como los juegos es por lo general muy extenso, lo cual dificulta la aplicación de métodos computacionales de aprendizaje y toma de decisiones. El presente trabajo propone la utilización de una representación del conocimiento para registrar estrategias en un juego lógico, que a través de funciones de similitud y relevancia permite generalizar soluciones conocidas con el fin de reducir el problema de generación de estados cuando se complemente con algoritmos de aprendizaje y decisión. Palabras clave Representación del conocimiento; resolución de problemas; aprendizaje computacional; general game playing. INTRODUCCIÓN En la inteligencia artificial (IA) y en particular el aprendizaje mecánico (machine learning, ML) se proponen algoritmos que permiten a una computadora reconocer y clasificar señales e información sensorial, con el fin de automatizar tareas complejas. Sin embargo, en muchas ocasiones estos métodos no pueden ser implementados en forma práctica o eficiente ya que los problemas del mundo “real” plantean una representación continua, con incertidumbre, y donde no siempre es posible determinar estados discretos o bien numerarlos. En el aparato cognitivo animal intervienen diferentes mecanismos que permiten resolver problemas complejos eficientemente. En particular, el conocimiento previamente adquirido modula juicios de relevancia en problemas de decisión y de aprendizaje. Incluso en hormigas se ha observado que estas seleccionan ubicaciones para sus próximos nidos mediante criterios cuya relevancia varı́a según las selecciones anteriores [15]. El aprendizaje y la toma de decisiones están ı́ntimamente relacionados, lo cual debe reflejarse en los modelos computacionales que los estudian. En un trabajo relacionado, se diseñó un método de decisión con aprendizaje autónomo, que permite a un agente interactuar con su entorno y descubrir nuevos estados. Este paradigma, basado en aprendizaje por reforzamiento (reinforcement learning, RL), requiere de una combinación de métodos de Se autoriza hacer copias de este trabajo o partes de para uso académico, siempre y cuando sea sin fines de lucro. La copia debe contener esta nota y la cita completa en la primera página. La copia bajo otras circunstancias y la distribución o publicación podrı́a requerir permisos adicionales o pago de derechos. JOCICI’15, Marzo 5-6, San José, Costa Rica. c Copyright 2015 CITIC-PCI optimización y métodos de muestreo, y por lo general utiliza procesos de decisión de Markov (MDP’s). Sin embargo, la construcción de un MDP requiere conocer los estados del problema y la probabilidad asociada a las transiciones entre ellos (P (s0 |s, a), probabilidad de pasar al estado s0 desde el estado s con la acción a). Con el fin de aplicar este modelo en el dominio de juegos, donde el espacio de estados es comúnmente intratable, se utilizó un modelo de representación del conocimiento que registra estrategias de un juego y utiliza métodos de similitud para evaluar la semejanza entre estados y aproximar funciones de valoración. Esta metodologı́a permite aplicar paradigmas de aprendizaje autónomo mediante la generalización de estados, a través de una representación del conocimiento. Las siguientes secciones discuten el tema de la representación y presentan una formalización breve de la metodologı́a. Se destaca la importancia de utilizar una representación del conocimiento como un sistema de apoyo en el aprendizaje y toma de decisiones, la cual reduce la complejidad del espacio de estados en un ambiente variable y permite implementar aprendizaje en lı́nea, un aspecto relevante como lo menciona Tesauro [19]. Vale destacar que esta propuesta no resuelve un juego; más bien consiste en una metodologı́a de representación que facilita la percepción de estados para un agente inteligente. REPRESENTACIÓN DEL CONOCIMIENTO El conocimiento en seres humanos cumple diversas funciones: modula la percepción (en particular cuando esta es parcial), permite generar categorı́as para clasificar estı́mulos sensoriales, y permite utilizar estas categorı́as en procesos de inferencia. Dos caracterı́sticas importantes de una representación del conocimiento son la intencionalidad (tendencia, consciente o no, de capturar información) y la capacidad para realizar inferencias sobre la estructura, función o similitud de elementos [17]. Se han sugerido los siguientes formatos de representación de conocimiento: Imágenes: utilizan analogı́as o isomorfismos a nivel de activación cerebral, por ejemplo mediante mapas topográficos en la corteza visual. Elementos significativos (meaningful entities): aquellos con impacto en la supervivencia o en la consecución de objetivos. Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) Caracterı́sticas: aspectos significativos obtenidos de estı́mulos sensoriales. Sı́mbolos amodales: aquellos que carecen de asociaciones motrices o perceptuales. Podrı́an utilizar representación estadı́stica. Comúnmente se utilizan métodos amodales en la IA, como listas de atributos o redes semánticas, en lugar de mecanismos perceptuales, enfocados en la reconstrucción más que en la transformación de estı́mulos [2]. Estas asociaciones perceptuales (por ejemplo, aspectos auditivos, táctiles o visuales del conocimiento) se conocen como modalidades, las cuales dan pie a enfoques integrativos conocidos como áreas de convergencia multimodales [16], respaldados por estudios de activación neuronal y evidencia conductual (switching cost) [12]. Se han propuesto las siguientes estructuras internas de representación [17]: Ejemplares y reglas: implementan adquisición de conocimiento mediante ejemplos especı́ficos y la abstracción de reglas relacionadas con ellos. Prototipos: caracterı́sticas generales que pueden conducir a una categorı́a, describen clases de ejemplares a través de caracterı́sticas que permiten identificarlos. Esquemas: Los esquemas (schemas) son conjuntos coherentes de relaciones entre propiedades, los cuales proveen información no esencial para categorizar, realizar inferencias y comprender los eventos que rodean las entidades. Permiten representar conocimiento contextual (background knowledge), útil para clasificar, y pueden incidir en procesos como la resolución de problemas y toma de decisiones. La representación propuesta utiliza estructuras derivadas de ejemplares, prototipos y esquemas, cuyo contenido se relaciona con modalidades especı́ficas del conocimiento pero con la capacidad de integrarse con otras modalidades en un modelo de mayor jerarquı́a. 30 A continuación se presenta una formalización resumida. La versión extendida se encuentra en [13]. Intuitivamente se entiende estrategia como una secuencia de movimientos que indican a un jugador qué acción tomar, dado un estado del juego. Se asume la existencia de las listas de movimientos I y II, correspondientes a los jugadores 1 y 2 respectivamente, tal que I ∩ II = ∅. Se define entonces la función de selección σ, para un conjunto de estrategias E y un problema de decisión P tal que: σ(P ) = Eσ ⊂ E (1) donde Eσ = {Eσ ∈ E | Eσ es relevante} (2) Cada estrategia E está compuesta por una secuencia de movimientos, descritos mediante pares atributo-valor. Definición 1. Sean A un conjunto de atributos, V un conjunto de valores y E un conjunto de estrategias. Una estrategia E ∈ E ⊂ A × V es un conjunto finito de la forma: E = h(a1 , v1 ), (a2 , v2 ), · · · , (an , vn )i (3) donde ∀i, ai ∈ A ∧ vi ∈ V . Un evento es un par e = (a, v) ∈ E. Las estrategias se organizan mediante un grafo dirigido acı́clico, denominado red de estrategias. Los nodos de la red contienen eventos y están enlazados mediante una relación de indización Ind ⊆ E ×E. Definición 2. Una red de estrategias es una tupla: R = hE, r0 , A, V, Indi (4) donde r0 es el nodo raı́z de R. Definición 3. La función sucesor de un evento e es: ∆(e) : E → E ∆(e) = {e0 | ∃ < e, e0 > ∈ Ind} (5) La organización resultante es similar a las redes de discriminación utilizadas en el Razonamiento Basado en Casos (RBC) [8]. REPRESENTACIÓN DE ESTRATEGIAS EN JUEGOS Construcción de la red La metodologı́a propuesta se enfoca en juegos de información perfecta (IP), apropiados para el estudio de la toma computacional de decisiones (y la racionalidad limitada) ya que restringen el dominio de representación y búsqueda al espacio de posibles estados derivados de los estados actuales, ignorando eventos fortuitos o de azar [7], [9]. Como caso de prueba se seleccionó el juego hex [5], [10], reconocido como un problema que requiere razonamiento complejo. Trabajos como [1] y [6] se han enfocado en determinar las estrategias ganadoras en tableros dados, por lo que no constituyen aportes en representación y aprendizaje. Anteriormente se han aplicado métodos de ML a los juegos en forma exitosa, como el programa de damas de Samuel [14] y el reconocido TD-Gammon de Tesauro [18], [19], pero nuestro enfoque permite implementar dos caracterı́sticas importantes: aprendizaje en lı́nea y representación comunicable. Dados los conjuntos A, V y E ya definidos, el algoritmo 1 se aplica ∀E ∈ E en una red R, iniciando con n = r0 y se detiene cuando E = ∅. Algorithm 1 Construcción de la red de estrategias 1: function CONSTRUCCI ÓN(n, E) 2: n0 ← primer elemento de E 3: if @n0 ∈ ∆(n) then 4: agregar (n, n0 ) en I 5: end if 6: construcción(n0 , E − {n0 }) 7: end function Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) Similitud y relevancia La ecuación 6 promedia en forma lineal una función de cercanı́a entre eventos (δ), aproximando la relevancia de una estrategia conocida con respecto a un problema P . rel : E × E → [0, 1] funciones de creación y selección de la red. La segunda prueba utiliza un método de aprendizaje autónomo, exploratorio, con aproximación guiada por conocimiento. El entrenamiento utilizó self-play con aprendizaje en lı́nea. Esto permite observar el comportamiento de la red en escenarios reales. Rendimiento n 1X rel(E, P ) = δ(Ei , Pj ) n i,j 31 (6) donde δ : e × e → [0, 1]. Las definiciones de δ pueden variar según el dominio, y puede ser utilizada como criterio de búsqueda. En forma semejante se define la similitud como un promedio lineal de la cercanı́a entre elementos de dos estrategias. Selección de estrategias Sea P un problema o estrategia incompleta, Pσ una posición de referencia y R una red de estrategias. La función de selección 7 retorna la estrategia en R más relevante para P iniciando en r0 ∈ R. El cuadro 1 muestra el tiempo de respuesta para la construcción de las diferentes redes, según el tamaño del conjunto de estrategias utilizado para su creación. La columna Tt corresponde al tiempo de respuesta total y TE al tiempo de respuesta por estrategia, ambos dados en milisegundos. Estrategias 500 1000 2000 Tt 3050 6120 13200 TE 6.1 6.1 6.6 Cuadro 1. Tiempos de respuesta – Creación de la red (7) El tiempo de respuesta para la construcción de una red de estrategias es aproximadamente lineal con respecto a la longitud del conjunto de datos. Cada estrategia se agrega a la red en aproximadamente 6 milisegundos, lo cual facilita la actualización de la red en vivo, sin necesidad de una etapa de entrenamiento previo. Es posible implementar selección heurı́stica y recuperar todas las rutas que satisfagan δ(r0 , Pσ ) > tσ tal que tσ es un umbral de selección. El cuadro 2 muestra los tiempos de respuesta para el proceso de selección, con un problema dado, según la cantidad de estrategias en la red (detalles en [13]). La columna |Sσ | corresponde a la cardinalidad del conjunto de soluciones. ρ:R→E n o 0 ρ(r, P ) = r ∪ ρ( máx ∆(r ), P ) 0 δ(r ,Pσ ) Ordenamiento En una selección heurı́stica el conjunto de soluciones debe ser ordenado y transformado. Por ejemplo la analogı́a derivacional permite implementar inferencia a partir de instancias [3]. Adicionalmente, se pueden considerar heurı́sticas como el reconocimiento (preferir alternativas conocidas), la fluidez (preferir la alternativa recuperada más rápidamente) y la cuenta (preferir la alternativa con más elementos positivos) [4]. En la siguiente sección se presenta un ejemplo de implementación de esta metodologı́a, aplicada al juego hex. PROTOTIPO, RESULTADOS Y ANÁLISIS Se implementó un prototipo en Common Lisp que describe los eventos mediante pares ordenados de coordenadas en un mapa, en forma semejante al ajedrez. Cada uno de los eventos en la red de estrategias es un par ordenado, mientras que una estrategia una secuencia de pares más un valor esperado promedio. Un problema P corresponde a la lista (I II). Las estrategias se representan mediante listas con listas de pares. Al agregar una estrategia en la red, se genera una llave aleatoria que se utiliza como referencia para almacenar su valor esperado en una lista de propiedades de Lisp. Esto reduce el tiempo de acceso ya que mantiene estos valores como variables globales. Se aplicaron dos pruebas en un tablero de hex 8×8. La primera utiliza listas de movimientos generadas aleatoriamente, cada una compuesta por secuencias de entre 8 y 15 movimientos. Esta prueba permitió medir el rendimiento de las Estrategias 500 1000 2000 Tt 3800 6700 9900 |Sσ | 10 18 29 TE 380 372.2 341.38 Cuadro 2. Tiempos de respuesta – Selección La tendencia indica que el tiempo de respuesta total es aproximadamente lineal con respecto a la cantidad de estrategias seleccionadas, independientemente del tamaño de la red utilizada. Los tiempos de respuesta son cortos (en el orden de segundos), lo cual facilita utilizar representaciones de conocimiento potencialmente grandes. El bajo tiempo de respuesta es también ideal para implementar este modelo en agentes simulados o reales, incluso con capacidad limitada de procesamiento. Aprendizaje y generalización En un trabajo relacionado se diseñó e implementó un modelo de agente autónomo, exploratorio, basado en el paradigma de aprendizaje por reforzamiento. Este enfoque requiere que un agente perciba el estado actual del entorno y seleccione una acción que maximice una función de valoración de estados y acciones. Para un estado dado, existe un conjunto de acciones válidas que conducen a estados nuevos, y tras seleccionar y ejecutar un acción, el agente recibe una recompensa numérica que utiliza para aproximar la expectativa del valor de dicho par estado-acción. Este paradigma goza de aceptación en la comunidad neurocientifica ya que modela apropiadamente algunos procesos neuronales de aprendizaje basado en recompensa [11]. Sin embargo, los dominios con gran cantidad Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) de estados, como los juegos, pueden volverse intratables bajo este esquema: la cantidad de acciones posibles para un estado dado genera una explosión combinatoria1 que impide realizar un muestreo exacto. Se utilizó el modelo descrito como un mecanismo de selección de estrategias y como una arquitectura de aproximación para la función de estados-acciones, en agentes jugadores de hex. El modelo no cuenta con una descripción del ambiente más allá de las acciones posibles y las condiciones finales, ya que su objetivo es descubrir estrategias de juego mediante interacción y experiencia únicamente, ajustando juicios de relevancia y expectativa mediante un mecanismo semejante a la “prueba y error”. Tras 2500 episodios de entrenamiento con agentes competitivos, el sistema logró extraer 2204 estrategias para hex 8×8 y cada partida tardó en promedio 43.83 movimientos (de 64 máximos). El modelo permite reducir el espacio de estados de hex 8×8 a un subconjunto tratable, a través de la generalización de estrategias. Vale destacar que 2204 es una fracción infinitesimal del conjunto de estados de hex (n2 factorial); jugar apropiadamente requiere de mucho más entrenamiento para que los agentes descubran estrategias eficaces. CONCLUSIONES El artı́culo presenta una generalización de otras representaciones del conocimiento, como las redes de discriminación o redes de conceptos. Sin embargo nuestro enfoque promueve la simplicidad, con impacto en eficiencia computacional y reducción en el consumo de memoria. Las pruebas de eficiencia realizadas revelan aspectos importantes del modelo. Los bajos tiempos de acceso para el proceso de selección son ideales para una arquitectura dinámica que soporte aprendizaje en lı́nea, sin una etapa de entrenamiento previa. Esta es una caracterı́stica deseable, como lo sugiere Tesauro [19]. También relevante es la capacidad para representar conocimiento simbólico. En tareas de planificación, por ejemplo en robótica cognitiva, se requiere que las representaciones sean al menos en parte simbólicas, de modo que el conocimiento representado sea fácilmente comunicable. Nuestro modelo permite extraer descripciones simbólicas fácilmente y justificar el razonamiento interno del agente, como respaldo a un proceso de decisión. REFERENCIAS 1. Anshelevich, V.˜V. The Game of Hex: An Automatic Theorem Proving Approach to Game Programming. In Proceedings of the Seventeenth National Conference on Artificial Intelligence and Twelfth Conference on Innovative Applications of Artificial Intelligence, AAAI Press / The MIT Press (2000), 189–194. 2. Barsalou, L.˜W., Simmons, W.˜K., Barbey, A.˜K., and Wilson, C.˜D. Grounding conceptual knowledge in modality-specific systems. Trends in Cognitive Sciences 7, 2 (2003), 84–91. 1 conocido como “maldición por dimensionalidad” 32 3. Carbonell, J. Derivational Analogy: A Theory of Reconstructive Problem Solving and Expertise Acquisition. 371–392. 4. Gigerenzer, G., and Gaissmaier, W. Heuristic decision making. Annual Review of Psychology 62, 1 (2011), 451–482. PMID: 21126183. 5. Hein, P. Vil de laere polygon? Politiken newspaper (1942). 6. Henderson, P., Arneson, B., and Hayward, R.˜B. Solving 8x8 hex. In IJCAI, C.˜Boutilier, Ed. (2009), 505–510. 7. Hodges, W. Logic and games. In The Stanford Encyclopedia of Philosophy, E.˜N. Zalta, Ed., spring 2013˜ed. 2013. 8. Kolodner, J. Case-Based Reasoning. Morgan Kaufmann, 1993. 9. Mycielski, J. Games with perfect information. In Handbook of Game Theory with Economic Applications, R.˜Aumann and S.˜Hart, Eds., 1˜ed., vol.˜1. Elsevier, 1992, ch.˜03, 41–70. 10. Nash, J. Some games and machines for playing them. Technical Report D-1164, Rand Corp. (1952). 11. Niv, Y., Edlund, J.˜A., Dayan, P., and O’Doherty, J.˜P. Neural Prediction Errors Reveal a Risk-Sensitive Reinforcement-Learning Process in the Human Brain. The Journal of Neuroscience 32, 2 (Jan. 2012), 551–562. 12. Pecher, D., Zeelenberg, R., and Barsalou, L.˜W. Verifying different-modality properties for concepts produces switching costs. Psychol Sci 14, 2 (2003), 119–24. 13. Saborı́o, J.˜C. Representación y selección de experiencias, con aplicaciones en juegos lógicos. http://cluster.cenat.ac.cr/kqhex/sel0215.pdf, 2015. [Informe Técnico]. 14. Samuel, A.˜L. Some studies in machine learning using the game of checkers. IBM J. Res. Dev. 3, 3 (July 1959), 210–229. 15. Sasaki, T., and Pratt, S.˜C. Ants learn to rely on more informative attributes during decision-making. Biology Letters 9, 6 (Dec. 2013), 20130667+. 16. Simmons, W.˜K., and Barsalou, L.˜W. The similarity-in-topography principle: reconciling theories of conceptual deficits. Cognitive Neuropsychology (2003), 451–486. 17. Smith, E.˜E., and Kosslyn, S.˜M. Cognitive psychology: Mind and Brain. Pearson/Prentice Hall, Upper Saddle River, N.J., 2007. 18. Tesauro, G. Practical issues in temporal difference learning. In Machine Learning (1992), 257–277. 19. Tesauro, G. Temporal difference learning and td-gammon. Commun. ACM 38, 3 (Mar. 1995), 58–68. 33 Modelo u-CSCL basado en la Ingeniería de la Colaboración Mayela Coto, Sonia Mora Universidad Nacional Costa Rica {mcoto, smora}@una.cr Alexander Moreno, Maria Fernanda Yandar, César A. Collazos Universidad del Cauca-Colombia FIET, Sector Tulcan {amoreno, myandar, ccollazo}@unicauca.edu.co ABSTRACT El proyecto Red u-CSCL es un proyecto actualmente en ejecución que busca la transferencia de conocimiento en el ámbito de desarrollo de tecnología colaborativa, personalizada y ubicua. En la primera etapa se ha definido el modelo de aprendizaje ubicuo y colaborativo (u-CSCL) tanto desde el punto de vista pedagógico como tecnológico, y se ha realizado una primera implementación de la plataforma tecnológica que soporta al modelo u-CSCL. Este documento presenta los referentes teóricos del modelo y el proceso seguido para el desarrollo de la plataforma tecnológica que la soporta. Author Keywords Ingeniería de la colaboración, patrones de colaboración, aprendizaje ubicuo, CSCL INTRODUCCIÓN Cada día crece la tendencia hacia el trabajo en forma colaborativa para alcanzar metas comunes. Cuando se integran aspectos colaborativos a un proceso determinado se busca una mejora de la comunicación, y una mayor participación y compromiso entre los integrantes de un grupo, lo que aumenta la productividad y la calidad del producto final. El proceso de crear, en forma colaborativa recursos de aprendizaje forma parte de esta tendencia colaborativa. Este documento presenta una metodología para el desarrollo colaborativo basada en la ingeniería de la colaboración (IC) y su aplicación en un ambiente de enseñanza-aprendizaje ubicuo y colaborativo. El trabajo se realiza en el marco de la red CYTED u-CSCL que está conformada por 80 investigadores de 12 universidades pertenecientes a 7 países iberoamericanos, la experiencia en sí misma involucra el trabajo colaborativo. Dicha metodología está basada en una “Metodología para el Desarrollo de Procesos Colaborativos” de Kolfschoten y Vreede [1]. El objetivo es que dicha metodología pueda ser Se autoriza hacer copias de este trabajo o partes de él para uso académico, siempre y cuando sea sin fines de lucro. La copia debe contener esta nota y la cita completa en la primera página. La copia bajo otras circunstancias y la distribución o publicación podría requerir permisos adicionales o pago de derechos. JoCICI 2015, Marzo 5-6, San José, Costa Rica. Copyright © 2015 CITIC-PCI aplicada a la creación colaborativa de recursos de aprendizaje en la que participen varias personas que pueden o no estar distribuidas geográficamente y que puedan pertenecer a diferentes áreas de conocimiento [2]. En las siguientes secciones se presentan, de forma breve, los referentes teóricos que sustentan la propuesta, y que permiten entender la aplicación de la metodología en el marco del modelo u-CSCL. MODELO U-CSCL Es bien sabido que la incorporación de las tecnologías de la información y de las comunicaciones (TIC) a los entornos educativos ha cambiado dichos entornos de múltiples maneras, por ejemplo, la forma en que se comunican los docentes y los estudiantes, y las maneras de interactuar con la información y los contenidos. Se han creado entornos más flexibles para el aprendizaje, eliminando las barreras espacio-temporales para la interacción entre los diversos actores, e incrementando las modalidades de comunicación, y de entornos interactivos, que favorecen tanto el aprendizaje independiente como el aprendizaje colaborativo, y ofrecen nuevas posibilidades para organizar la actividad docente [3]. El modelo u-CSCL es un modelo de aprendizaje constituido primordialmente por las mejores prácticas de dos formas de aprendizaje: (1) el aprendizaje ubicuo (ulearning) que utiliza actividades formativas apoyadas en la tecnología, accesibles en cualquier lugar y disponible en distintos canales al mismo tiempo; y (2) CSCL que es el aprendizaje colaborativo apoyado por herramientas computacionales, enfocado en ambientes educativos [4]. Un entorno de aprendizaje apoyado por tecnología, como el u-CSCL, requiere de una dimensión tecnológica y una dimensión educativa que se interrelacionen y potencien entre sí. La dimensión tecnológica está representada por las herramientas o aplicaciones informáticas con las que está construido el entorno de aprendizaje, y la dimensión educativa está representada por el proceso de enseñanzaaprendizaje que se desarrolla en su interior. Esta dimensión facilita la interacción que se genera entre el docente y los estudiantes a partir de las actividades de aprendizaje. Ambas dimensiones proponen un ambiente de trabajo compartido para la construcción del conocimiento con base Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) en la participación activa y la cooperación de todos los actores del proceso [5]. Al igual que otros modelos educativos, el modelo u-CSCL, incluye cinco componentes principales: 1. Docentes, 2. Estudiantes, 3. Materiales de estudios (contenidos, actividades colaborativas, contenedor de objetos de aprendizaje), 4. Plataforma Tecnológica (Sistemas de Gestión de Aprendizaje, Ambientes virtuales de Aprendizaje), 5. Servicios de acceso [4]. INGENIERÍA DE LA COLABORACIÓN Para lograr mayores posibilidades de éxito en los procesos colaborativos, algunos autores [6] han argumentado que estos deben ser explícitamente diseñados, estructurados y manejados. Este proceso de diseñar y estructurar explícitamente los procesos colaborativos se ha convertido en el eje central de una nueva área llamada Ingeniería de Colaboración (IC), en la cual “se diseñan procesos repetitivos colaborativos, los cuales se pueden transferir a grupos, usando técnicas y tecnología de colaboración [7]. La Ingeniería de la Colaboración es un acercamiento al diseño de procesos colaborativos reutilizables” [1]. La Ingeniería de la Colaboración busca entonces codificar y empaquetar en unidades de conocimiento, las actividades y sus respectivas guías de ejecución, involucrando tanto los pasos a ejecutar en una herramienta computacional, como los pasos a ejecutar entre los integrantes del grupo, de forma que estas unidades, puedan ser reutilizadas fácilmente por los miembros del grupo para potenciar el rendimiento y resultados del trabajo grupal [2] [7]. En la IC se destacan los patrones de colaboración y los Thinklets, que se describen a continuación. Patrones de colaboración La Ingeniería de la Colaboración ha identificado una serie de patrones a partir de los cuales un grupo trabaja colaborativamente hacia sus metas. Estos patrones denominados patrones de colaboración son una guía de cómo se ejecutará un proceso, y “definen la manera como los participantes de una actividad grupal van de un estado inicial a un estado final” [8]. Cada patrón tiene sub-patrones que se pueden relacionar con las actividades, en la descripción del proceso genérico. Algunos de los patrones de colaboración usados en este proyecto son [7] [8]: Generación: es un patrón a partir del cual el grupo crea contenido. Consiste en pasar de tener pocos a muchos conceptos que son compartidos por el grupo. Reducción: el objetivo de este patrón es mantener sólo la información que cumple con un determinado criterio. Consiste en pasar de tener muchos conceptos a unos pocos que el grupo considere que requieren mayor atención. Clarificación: el objetivo de este patrón es lograr el entendimiento común de conceptos manejados por el grupo. Consiste en pasar de tener un menor a un mayor 34 conocimiento compartido de los conceptos, las palabras y frases usadas por los integrantes del grupo. Un proceso de colaboración consiste en una serie de actividades ejecutadas por un grupo para lograr un objetivo. Un supuesto fundamental en el diseño de procesos de colaboración, es que cada proceso consiste de una secuencia particular de thinkLets y actividades, que apoyan la creación de colaboración o patrones de colaboración entre los miembros del equipo [9]. Con el objetivo de ir de una fase a otra del proceso de colaboración, cada actividad puede ser apoyada por una combinación de thinklets. Thinklets Los ThinkLets son “técnicas de facilitación repetibles, transferibles y predecibles para asistir a un grupo a alcanzar el objetivo acordado” [10]. Un ThinkLet se refiere a la unidad más pequeña de conocimiento requerido, que se necesita para ser capaces de reproducir la colaboración entre personas que trabajan hacia un objetivo común [11]. Los ThinkLets pueden ser usados como unidades conceptuales de construcción en el diseño de procesos que involucran la colaboración como elemento ya que cada ThinkLet proporciona el conocimiento necesario sobre los pasos o instrucciones a seguir para implementarlos como parte del proceso grupal[8]. Una de las grandes ventajas de los Thinklets es que al diseñar procesos colaborativos se pueden emplear soluciones conocidas y no invertir esfuerzos en inventar y probar nuevas [2], por lo tanto, el enfoque de trabajo cambia de inventar y probar soluciones, a escoger soluciones conocidas y probadas, lo que puede reducir tanto el esfuerzo como el riesgo de desarrollar e implementar procesos grupales [12]. DISEÑO DE LA PLATAFORMA TECNOLÓGICA El proceso que se ha seguido para el desarrollo del entorno pedagógico y computacional ha sido el siguiente: Modelo Pedagógico U-CSCL: El modelo pedagógico UCSCL, es un proceso el cual pretende una actualización metodológica soportada en diferentes iniciativas de innovación didáctica, este modelo pedagógico puede especificarse como el conjunto de definiciones, roles, metodologías, pasos y procedimientos destinados a regular la estructura académica; representa lo que se quiere lograr, y todo lo que abarca el procedimiento para lograrlo. Este modelo pedagógico guiará a los docentes y estudiantes en todos los aspectos que influyen para lograr los objetivos que se han propuesto, de una manera diferente, ya que tanto los alumnos como los profesores trabajaran de forma colaborativa. El modelo pedagógico U-CSCL, es un esquema y una serie de pasos del cual se detallan dos etapas importantes, la primera es la etapa de Definición y Diseño, donde los docentes de manera conjunta y colaborativamente crean Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) “El esquema del curso” y “Esquema teórico”: enfocado a lo que se debe enseñar y qué debe aprender el alumno; la concepción del desarrollo: cómo aprende el alumno; la metodología que se utiliza: cómo enseñar y cómo lograr que el alumno aprenda; la evaluación de los conocimientos: cómo y para que retroalimentar los procesos de enseñanza aprendizaje; la relación docente-estudiante: cuál es el rol de cada uno y cómo debe ser su interacción. La Segunda etapa es la de “Desarrollo del curso”, en este los principales protagonistas son los alumnos, quienes desarrollaran las actividades colaborativas e individuales propuestas en el curso, es aquí donde el modelo pedagógico busca que los participantes se involucren, realicen aportes y actúen, propiciando así el desarrollo del pensamiento y se proceda a la construcción del conocimiento, de tal manera que los medios tecnológicos, logren la mediación necesaria para que pueda efectuarse una actividad productiva que permita lograr una experiencia de aprendizaje completa. En el mapa conceptual que se muestra a continuación, se pueden observar los principales elementos pedagógicos del modelo propuesto (ver Figura 1) 35 Figura 1: Elementos pedagógicos Plataforma u-CSCL. Modelo Tecnológico: Se hizo una revisión de diferentes plataformas tecnológicas que soporten la creación de cursos masivos, similares a los MOOCs como Coursera, MiriadaX, Udacity, entre otros. Se toman aspectos de dichas herramientas para diseñar una plataforma propia, en la cual se integren los aspectos colaborativos. Este aspecto colaborativo es el elemento diferenciador con respecto a las plataformas existentes estudiadas, teniendo en cuenta que las actividades colaborativas la mayoría de las veces son dirigidas a estudiantes, en este caso incluimos los docentes como personajes principales y activos en algunas actividades. La plataforma permite que un conjunto de profesores geográficamente dispersos pueden diseñar un curso de manera colaborativa, utilizando medios como una pizarra colaborativa y chat, en cuanto a los estudiantes podrán desarrollar el curso de manera conjunta y colaborativa por medio de actividades diseñadas para este fin. La plataforma colaborativa se está implementando mediante el framework de desarrollo web Django, basado en el lenguaje Python, aprovechando de esta forma las ventajas de un ambiente de aprendizaje colaborativo con los beneficios de la computación ubicua y los nuevos instrumentos y recursos tecnológicos, permitiendo romper las barreras de espacio y tiempo que existen en las aulas de clase tradicionales. En la actividad colaborativa (ver Figura 2) se despliega un formulario preliminar del esquema de un curso desarrollado por el líder de la actividad; posteriormente, los docentes pueden desarrollarlo de manera tal, que cada uno de ellos pueda definir una serie de ideas generales correspondientes al esquema a trabajar, esto mediante una pizarra colaborativa; determinando así, un consenso de las ideas principales por medio de una votación (ver Figura 3). Figura 2: Formulario esquema del curso. Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) Figura 3: Pizarra colaborativa. CONCLUSIÓN Como se mencionó anteriormente, el proyecto Red u-CSCL es un proyecto en ejecución, por lo que este documento se ha centrado en describir los conceptos teóricos que soportan el aprendizaje ubicuo y colaborativo que busca la red. Se ha desarrollado una metodología y una primera implementación de la plataforma tecnológica, para apoyar el diseño colaborativo de actividades de aprendizaje que combina las ventajas de un ambiente de aprendizaje colaborativo con los beneficios de la computación ubicua y la flexibilidad de las nuevas tecnologías digitales. Dicha metodología está basada en los conceptos de la ingeniería de la colaboración, lo que de alguna manera pretende incrementar la productividad de los equipos de trabajo, ya sea docentes o estudiantes. Como trabajo futuro se plantea validar la metodología a través de la generación de contenidos digitales enfocados en el liderazgo participativo en entornos ubicuos y colaborativos. AGRADECIMIENTOS Este artículo es desarrollado como parte del proyecto “RED u-CSCL: Red Iberoamericana de apoyo a los procesos de enseñanza-aprendizaje de competencias profesionales a través de entornos ubicuos y colaborativos, código CYTED 513RT0481”, y como parte del proyecto de la Universidad Nacional, “Desarrollo e Implementación de un Modelo Pedagógico de Apoyo a los Procesos de Enseñanza-Aprendizaje de Competencias Profesionales a través de entornos ubicuos y colaborativos en el marco de la red U-CSCL”, código 0406. REFERENCIAS [1] G. Kolfschoten and G. Vreede, “The Collaboration Engineering Approach for Designing Collaboration 36 Processes,” presented at the International Conference on Groupware: Design, Implementation and Use, 2007. [2] A. Solano and C. Collazos, “Modelo para el diseño de actividades colaborativas desde un enfoque práctico,” Rev. Univ. RUTIC, vol. 1, no. 2, 2013. [3] J. Cabero and M. Llorente, “La alfabetización digital de los alumnos. Competencias digitales para el siglo XXI,” Rev. Port. Pedagog., vol. 42, no. 2, pp. 7–28, 2008. [4] C. Collazos, A. Moreno, M. Yandar, R. Vicari, and M. Coto, “Propuesta metodológica de apoyo a los procesos de enseñanza-aprendizaje a través de entornos ubicuos y colaborativos: u-CSCL,” presented at the VIII Congreso Colombiano de Computación - 8CCC, 2013. [5] M. I. Salinas, “Entornos virtuales de aprendizaje en la escuela: tipos, modelo didáctico y rol del docente,” Programa de Servicios Educativos (PROSED), 2011. [6] R. Briggs, G. Kolfschoten, V. Gert-Jan, and D. Douglas, “Defining key concepts for collaboration engineering,” presented at the Americas Conference on Information Systems, 2006. [7] Y. Méndez, J. Jiménez, C. Collazos, T. Granollers, and M. Gonzalez, “Thinklets: Un Artefacto Útil para el Diseño de Métodos de Evaluación de la Usabilidad Colaborativa,” Rev. Av. En Sist. E Informática, vol. 5, no. 2, pp. 147–154, 2008. [8] G. Kolfschoten, R. Briggs, and G. Vreede, “Definitions in Collaboration Engineering,” presented at the Proceedings of the 39 Hawaii International Conference on System Sciences, Delft University of Technology, University of Arizona, 2006. [9] C. Acosta, “Diseño e implementación de una herramienta de Representación del conocimiento para apoyar la Gestión de requisitos en un proceso de desarrollo de software,” Universidad de Chile, 2010. [10] R. Briggs, G. Vreede, and J. Nunamaker, “Collaboration engineering with ThinkLets to pursue sustained success with group support systems,” J. Manag. Inf. Syst., vol. 19, pp. 31–64, 2003. [11] E. Santanen and G. Vreede, “Creative Approaches To Measuring Creativity: Comparing The Effectiveness Of Four Divergence Thinklets,” presented at the 37th Hawaiian Internal Conference On System Sciences, Los Alamitos, IEEE Computer Society Press, 2004. [12] G. Kolfschoten, R. Briggs, J. Appelman, and G. Vreede, “ThinkLets as building blocks for collaboration processes: a further conceptualization,” Groupw. Des. Implement. Use, pp. 137–152, 2004. 37 A Political Sentiment Analysis System using Spanish Postings: Expectations and Realities Edgar Casasola Murillo ECCI-CITIC Universidad de Costa Rica [email protected] ABSTRACT The creation of a Real World Political Sentiment Analysis System for the Spanish language is presented. Its intention is to monitor public opinion published online. Political sentiment analysis as compared to sentiment analysis in other scenarios is more complex. After running the system to obtain data from real information sources the complexities related to sentiment analysis in the political arena were identified. The new characteristics that have been depicted for this new scenario are explained in this paper. Context and dialogue dependencies, political character name disambiguation, and emergent dynamic references to candidates and their the aspects are some of the domain specific identified characteristics. Palabras clave Sentiment analysis, Political opinion, Spanish postings Introduction Most sentiment analysis research is based on English text. There is a gap between resources and techniques available for English and other languages [5]. Spanish is one of those languages, and some effort has been done to narrow the gap using different approaches. Some approaches go from adapting English techniques and algorithms to techniques based on automatic translation as in [4]. Others try to develop native Spanish sentiment analysis tools. According to Internet World Stats1 , Spanish speakers occupy the third place amongst the Internet users. Moreover, the use of Spanish is rapidly growing compared to the use of English (807.4% vrs 301.4% between 2000 and 2011). These indicators reveal the specific need to increase the amount of sentiment analysis research based on Spanish. Our work is part of what we call the Sentı́metro Project. Its main goal is to work with real text written by native Spanish speakers. The name Sentı́metro was derived from the Spanish words sentimiento (sentiment) and metro (meter), which 1 http://www.Internetworldstats.com/stats7.htm Permission to make digital or hard copies of all or part of this work for academic use is granted, provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, to republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. JOCICI’15, March 5-6, San José, Costa Rica. c Copyright 2015 CITIC-PCI Gabriela Marı́n Raventós CITIC-ECCI Universidad de Costa Rica [email protected] means, a tool used to measure the amount of sentiment expressed in a text. The goal of the Sentı́metro Project is to provide a useful sentiment analysis tool to monitor public opinion about specific events, topics or public individuals in Costa Rica. Important sources of information in Spanish about public matters have already been identified and documented in our country. A public survey done by Arce [2] identified and ranked the main public opinion sites used by the population. These sources of information allow users to post comments related to a broad range of public matters. They include the Internet sites owned by popular media TV, newspapers and popular independent radio programs in the country. The twelve sites with the highest volume of comments are being monitored. We already downloaded and created a PoS Tagged Corpus with 1.9 million individual comments downloaded from the 12 most popular Facebook profiles related to the new media and news sites as reported by [2]. This corpus in Spanish was named CR2013FBCorpus and is available for research purposes at http://citic.ucr.ac.cr/ proyecto/analisissentimiento. The system design is based on modular and extensible software bundles implemented using the Java programming language. It gathers data and facilitates the execution of program modules. Test programs can be run using the data and results can be store for further analysis. The first section includes current Spanish research in sentiment analysis compared to English. Native and non-native approaches are mentioned. Next section provides a system’s description. The next section refers to the information sources we are using and the information gathering process. The results section present our findings and some results analysis. Finally conclusions and future work are presented. Spanish Sentiment Analysis Research in sentiment analysis has been shifting on new directions [6]. According to Cambria [5], research is moving from heuristics to discourse structure, from coarse to fine grained analysis, and from keyword to concept-level mining. Nevertheless, he considers that working with other languages is more a context adaptation problem while others, like Brooke[4], mentions that since Spanish is a highly inflected language, special research needs to be done. Recent publications about sentiment analysis in Spanish are centered on evaluating the performance of various polarity detection classifiers like support vector machines and tf*idf Proceedings of the II Costa Rican Workshop on Computer Science and Informatics (JoCICI 2015) 38 based schemes [9], and naive Bayes variations [8]. Other approaches like [1] evaluate results while working with Spanish Tweets. It can be observed that much of the Spanish sentiment analysis research is still based on heuristics but it is also moving towards syntactical structure dependency analysis as in [11] and [10]. Spanish native research still seems to be based on coarse grained analysis, i.e. polarity assignment is associated to the whole review or text expression. This kind of analysis assumes that the whole text contains a single opinion or sentiment about a single entity. Automatic translation has been studied as a medium to adapt existing English sentiment analysis methods and algorithms for Spanish text. Results are not as promising as expected. Known problems related to automatic translation are still open and sources of error still exist. As said, Spanish is a highly inflected language. Anaphora and co-reference resolution can affect the quality of the results based on English to Spanish translations. Automatic translation becomes a potentially good idea at keyword level but may become a source for unexpected effects producing unwanted results at concept or phrase level. The work done by [4] is a good example where the use of automatic translation affects the quality of Spanish results compared to English results. Clearly, there is sufficient work to be done to keep the pace with current sentiment analysis research in English. Creating a tool to facilitate access to real data sources, to help gather and filter user postings, and to store and manage data is important. The possibility to produce new corpus with Spanish text annotated with information regarding polarity can be very useful too. A more complex scenario appears if we try to do Sentiment Analysis using News posts as mentioned in [3]. New subproblems show up in this domain. We will refer to this aspect in the results section. Figura 1. Sentı́metro System to allow to test existing algorithms but also adapt and create new Spanish specific ones. In some cases, .arff output files are produced to work with Weka2 . Many of the algorithms and techniques used for sentiment analysis have parameters and variations that need to be studied. The system provides the possibility to test and store results for data analysis. The top level design of the platform, shown in Figure 2, presents the main components of the system. Interaction among bundles is based on streams of comments. A comment is a bundle that includes the information related to every post or text expression the system works with. Comments can be related to other comments following a hierarchical relationship. Relationships between comments is not expected to have more than one or two levels deep, but it is not a constraint imposed by this design. The Sentı́metro System Sentı́metro is a software tool to gather, store, run sentiment analysis programs on, and administer real data obtained from different data sources available online. It is a platform to gather real data and run empirical studies in order to facilitate experimentation. As shown in Figure 1, the system is useful for gathering real postings (1), and for organizing and classifying them to create new Spanish text resources (2). The stored data design supports the storage of human sentiment annotations (3) as well as modular integration of automated software modules for various sentiment analysis specific tasks (4). It means that each posting may have a sentiment annotation assigned by a human as well as the polarity assigned by a software module. Sample data for experiments can be extracted from the data repository. The system design is based on an easy to extend and scale software architecture. It is based on the OSGi specification as shown in http://www.osgi.org/ Technology/HomePage. Bundles are modules designed according to the OSGi specification. Bundles are created to implement task specific sentiment analysis techniques and algorithms. The goal is not only Figura 2. Sentı́metro System Design Extractors are the bundles used to get data from information sources. They get real data and push it into Comment Stream bundles. The Basic Storage bundle implementation is an abstraction used to provide storage services without getting into the implementation details of this layer. Persistent storage is provided by the implementation of an underlying relational data base. 2 http://www.cs.waikato.ac.nz/ml/weka/index.html Proceedings of the II Costa Rican Workshop on Computer Science and Informatics (JoCICI 2015) Most of the modules related to sentiment analysis specific identification or transformation tasks are implemented as filter bundles or annotator bundles. The idea of these bundles is to provide services where selection or transformation is applied to input comments. Tasks as entity identification, entity classification, opinion holder identification, holder extraction, sentiment identification and extraction, and aspect identification and extraction are seen as specific implementations of filter and annotator bundles. Annotator bundles are used to add extra annotations or data to the comments it receives as input from the Comment Stream. Information Gathering from Real Data Sources The platform has data gathering modules for specific Internet sites. Since every site has its own format, specific gathering modules need to be created in each case. The platform allows the creation of new modules to gather information from different data sources. A common type of data source for sentiment analysis can be a regular Internet site that allows users to post comments, as news sites and other media sites. Other common data sources are specific social network profiles. Organizations in Costa Rica allow users to post directly on their Internet sites or Facebook profiles, and those groups of postings are kept separated. Facebook users for example don’t get an integrated view of comments posted at the Internet site. At the Internet site both groups of postings are readable but kept apart. This characteristic permits studying possible differences among opinions expressed by Facebook compared to the ones of Internet site visitors. It is important to notice that these opinion sites do not have a star system or like-unlike schemes but are potential sources of opinion for sentiment analysis at the political domain. When people are simply expressing their opinion they are not worrying about tagging their comments with a happy or sad face. Costa Rica news sites allow readers to express their opinions about public matters with comments. They are not expecting them to mark bullets or radio buttons, and if so, not all users do it. 39 Rica will provide us with enough information for sentiment analysis of public matters in the country. Based on descriptive statistics, we decided to first use Sentı́metro to gather a corpus from Facebook since it is the most popular social network in Costa Rica. Figure 3 shows how the system can be used to analyze postings and their corresponding responses. It keeps track of user opinions regarding specific topics. The user id numbering system helps to keep track of a user without compromising its identity. Notice how user 5 has two postings in the same conversation. The Sentimetro system has been used with random samples from that data collected. After one year exploration of data of the CR2013FBCorpus, some research findings regarding the political arena postings are summarized in the following section. Results As a result of the analysis of the information sources, we found that the isolated comment as a minimal unit of analysis is not enough to get sound results in Spanish. Experiments run on single comments allowed us to notice that after extraction of comments with information related to political candidates, hardly 56 percent of them hold opinions. From the comments regarded as opinions, only 21.6 percent of the results hold positive opinions and 78.5 percent negative opinions. Even more, using a tf-idf technique (based on the lack of training data to apply a supervised technique) the average precision obtained when judging single comments was only of 0.53. Due to these results we proceed to present text to native Spanish human corpus annotators and their conclusion were that many comments were only understandable in context. The sequence of comments demonstrate the complexity of the task and the necessity to take into account the context for sentiment analysis. It is true that we can expect that threads bear information about the original post, but when discussions get longer, participants easily introduce new subjects or aspects (sometimes loosely related), which we need to identified and filter. The new emerging aspects could eventually be use to extract new sentiment opinions. Sentiment analysis in the political arena is far more difficult. Political opinion differ from other contexts. Some characteristics that have been depicted for this new scenario are: 1. As stated before, postings or comments make no use of any star coding as in product or entertainment reviews. In order to train or evaluate sentiment analysis algorithms, human expert annotators much produce data collections with associated comment polarity. That is why having annotated corpora becomes important to evaluate possible polarity extraction algorithms. Figura 3. System keeps track of postings and their corresponding responses We believe that monitoring the opinion expressed as open text on the twelve most popular sources of information in Costa 2. Comments typically involve comparisons between two or more candidates or public policy proposals. For example, in the statement ”I prefer Luis Guillermo’s view on economic issues rather than other main candidate views”, the opinion holder is not only referring to Luis Guillermo but is implicitly referring to some other not explicitly mentioned candidates (from 13 official candidates it is difficult to assess which are the main candidates). Proceedings of the II Costa Rican Workshop on Computer Science and Informatics (JoCICI 2015) 3. There are many possible types of references that can be used to address a particular candidate or political party. Thus, the entity recognition task used to identify the candidate could be even more complicated than in other contexts. In a specific candidate’s homepage or site, comments are not only directed to him. It is typical to find opinion comments for other candidates as well. 4. Postings many times belong to complex dialogue structures present on Internet real data in the context of political discussions. So, comments are not individual expressions but groups of interrelated texts. 5. Comments are spread on diverse Internet sites and social networks which not only include opinion comments. A high percentage of the expressions do not involve opinions, or can not be classified as positive or negative. 6. Aspects upon which entities are evaluated may be implicit, emergent, dynamic and even ambiguous in the political context. 7. The dynamics of certain sites and topics, represented by its posting’s effervescence or inactivity, are important determinants as well as the polarity of the comments. 8. Several sources of motivation for spamming exist, thus, spam postings must be detected and eliminated. 9. Postings not always form complete grammatical structures. They do not correspond to complete and correct sentence structures in many cases but still hold opinion. 10. Language used in real political Costa Rican comments can help determine polarity. Emphasis given to frases by using words like NOOOOOO, instead of using a simple no, muchisiı́simo instead of muchı́simo, are examples of things conventional text normalization algorithms eliminate. New text normalization algorithms that preserve emotional markings are required to ease polarity determination. These characteristics make sentiment analysis in this context different from traditional approaches. Having a very flexible extensible platform is very useful to incorporate new system requirements as domain knowledge arises. Moreover, directing its architecture to incorporate naturally algorithm evaluation and fine tuning is critical. Conclusions and Future Work An experimental platform for Spanish sentiment analysis has been presented. The platform was used to gather data from real sources of Spanish postings in Costa Rica on the political domain. Sources include Internet sites as well as social network ones. Sentiment analysis has been mainly done in the context of product or entertainment reviews as recalled by [5], [7] and others. In this context, the task of sentiment analysis algorithm construction and testing are eased by the existence of the user star or like-unlike ratings available on many review systems. Algorithms can be trained or evaluated using preexisting sentiment auto-defined measurements provided by 40 the number of stars or equivalent ranking systems provided by the opinion holder. Nevertheless, even in this scenarios sentiment analysis has been shown to be complex. The Sentı́metro System was designed to monitor specific sentiment opinion on real time from the main national wide opinion sources in Costa Rica. We have information extractors for the most important sources already identified in Costa Rica. And we are adding new module bundles for new sentiment analysis tasks, and expect to accelerate fine grained sentiment analysis research on the political domain. Using the system through several experiments, we have depicted that the political domain is far more complex. Identification of context for comment sentiment classification will help to improve classification methods and algorithms for it. Can a system automatically identify the political opinion sentiment of a nation about specific subjects? At least for an small country like Costa Rica? Those are the question we really want to answer, and this system pretends to be an step forward towards reaching that goal. We believe this system will encourage and allow further research. REFERENCIAS 1. A. F. Anta, L. N. Chiroque, P. Morere, and A. Santos. Sentiment analysis and topic detection of Spanish tweets: A comparative study of NLP techniques. Procesamiento del Lenguaje Natural, 50:45–52, 2012. 2. J. L. Arce. Medios de comunicación de masas en Costa Rica: Entre la digitalización, la convergencia y el auge de los ”new media”. In Hacia la Sociedad de la Información y el Conocimiento, chapter Medios de Comunicación de Masas en Costa Rica, pages 283–308. Programa Sociedad de la Información y el Conocimiento, Universidad de Costa Rica, 2012. 3. A. Balahur, R. Steinberger, M. Kabadjov, V. Zavarella, E. Van Der Goot, M. Halkia, B. Pouliquen, and J. Belyaeva. Sentiment analysis in the news. arXiv preprint arXiv:1309.6202, 2013. 4. J. Brooke, M. Tofiloski, and M. Taboada. Cross-linguistic sentiment analysis: From English to Spanish. In Proceedings of the 7th International Conference on Recent Advances in Natural Language Processing, Borovets, Bulgaria, pages 50–54, 2009. 5. E. Cambria, B. Schuller, Y. Xia, and C. Havasi. New avenues in opinion mining and sentiment analysis. Intelligent Systems, IEEE, PP(99):1–1, 2013. 6. B. Liu. Sentiment analysis: a multifaceted problem. IEEE Intelligent Systems, 25(3):76–80, 2010. 7. B. Liu and L. Zhang. A survey of opinion mining and sentiment analysis. In C. C. Aggarwal and C. Zhai, editors, Mining Text Data, pages 415–463. Springer US, 2012. 8. M.-T. Martı́n-Valdivia, E. Martı́nez-Cámara, J.-M. Perea-Ortega, and L. A. Ureña-López. Sentiment polarity detection in Spanish reviews combining supervised and unsupervised approaches. Expert Systems with Applications, 40(10):3934 – 3942, 2013. 9. G. Paltoglou and M. Thelwall. A study of information retrieval weighting schemes for sentiment analysis. In Proceedings of the 48th Annual Meeting of the Association for Computational Linguistics, ACL ’10, pages 1386–1395, Stroudsburg, PA, USA, 2010. Association for Computational Linguistics. 10. J. Sing, S. Sarkar, and T. Mitra. Development of a novel algorithm for sentiment analysis based on adverb-adjective-noun combinations. In Emerging Trends and Applications in Computer Science (NCETACS), pages 38–40, 2012. 11. D. Vilares, M. Alonso, and C. Gómez-Rodrı́guez. Clasificación de polaridad en textos con opiniones en espanol mediante análisis sintáctico de dependencias. Procesamiento del Lenguaje Natural, 50(0), 2013. 41 Plataforma para el reconocimiento facial: aspectos de percepción y cognición social Janio Jadán-Guerrero Universidad de Costa Rica Universidad Tecnológica Indoamérica 988599@ ecci.ucr.ac.cr ABSTRACT The face of a person is one of the anatomical structures that has more muscles and the elements that compose it (forehead, eyebrows, eyes, nose, mouth, for example.) can take different forms and arrangements through the development of the person to over time. In this context, hypotheses concerning the perceptual process and social cognition were raised. Variables as gender, response time and type of processing of the perceived information were controlled. An experiment with 100 participants was carried out. Two instruments (a web application with 120 pairs of photographs and a structured on-line survey) determined whether a person was able to match a face seen in a photograph with the respective counterpart twenty years earlier. Using inferential statistics seems that participants were able to "defrag" or "decompose" the overall image of the face, but there is no significant difference in gender. Keywords Face perception; bottom-up; top-down; social cognition; web-platform. Kryscia Ramírez y Shirley Romero Bonilla Universidad de Costa Rica [email protected], [email protected] aspectos importantes de los estados internos: emociones e intenciones [6]. Otras investigaciones señalan que las personas son capaces de percibir en el rostro, cualidades internas que son más estables a través del tiempo, tan variadas como la dominancia o el atractivo [2-3]. Con base en estos aspectos derivados de estudios previos, resulta inquietante y objeto de esta investigación el conocer los alcances de los procesos “top-down” en cuanto a la capacidad retrospectiva de descomponer y condensar los cambios faciales a través de los años [6], para así, asociar dos rostros homólogos pero cuyos cambios están espaciados por hasta veinte años. Además es de interés para esta investigación identificar si criterios como el género de quien percibe es relevante en la eficacia de procesos inferenciales (cambio del rostro a través del tiempo). Con base en estos objetivos, se ha diseñado una plataforma web que apoye a comprobar las siguientes hipótesis: 1. ACM Classification Keywords Experimentation; Human Factors En cuanto a procesos perceptuales y procesos de coherencia central: a. Los participantes son capaces de emparejar un rostro observado en una fotografía con el homólogo respectivo de veinte años atrás. b. Elementos del rostro: ojos, boca y nariz son la base sobre la cual los participantes orientaron sus procesos “top-down”: para la deconstrucción y reconstrucción del rostro (partes) a través de métodos analíticos y sintéticos. INTRODUCCIÓN Algunos estudios señalan que el reconocimiento facial parece tener un componente innato [1-7]. Se ha evidenciado que alrededor de los 30 minutos posteriores al nacimiento de un niño, este realizará el seguimiento y rastreo visual, así como el movimiento cefálico que permita “enfocar” una cara en movimiento, con más ahínco que otros objetos móviles significativamente más contrastantes, e independientemente de la complejidad o la frecuencia espacial con que se presente. Desde el área de la Etología, el percibir la edad del rostro, ayuda al ser humano a regular su comportamiento (en forma y frecuencia) dirigido hacia un homólogo; por ejemplo: el tamaño de la circunferencia cefálica es de vital importancia en la pertinencia de la conducta paternal/maternal para la atención, el cuidado y la protección de los infantes. Por otra parte, el área de la psicología referente a la Cognición Social (CS) [5], considera que el rostro, sus facciones y el movimiento de las mismas, muestran 2. En cuanto a aspectos concernientes a la Cognición Social: a. Los participantes masculinos muestran más fallas que las participantes femeninas al intentar emparejar un rostro observado en una fotografía con el homólogo respectivo de veinte años atrás, independientemente del sexo de las personas de las fotografías. b. Los participantes masculinos tienen un tiempo de respuesta menor que las participantes femeninas al intentar emparejar un rostro observado en una fotografía con el homólogo respectivo de veinte años atrás, independientemente del sexo de las personas de las fotografías. Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) 42 entre 15 y 25 años. Una de ellas era la homóloga de la persona de la fotografía en la parte superior. El diseño contempló el uso del ratón del computador para seleccionar las fotografías de la parte inferior durante un tiempo de exposición de 30 segundos. Al finalizar el tiempo, la diapositiva pasaba automáticamente a la siguiente sin registrar ningún acierto. Al final se presentaban una diapositiva con los resultados. Tabla 1. Características de los participantes. METODOLOGÍA La presente investigación es de tipo experimental, debido a que se controlan las características de la fotografía de una persona por género, rango de edad y tiempo de exposición (variables independientes). Con el fin de analizar su efecto en el reconocimiento de rostros en función de cantidad de aciertos y tiempo de respuesta (variables dependientes) por parte de participantes en varios ensayos en la plataforma web. Participantes La muestra para el experimento estaba compuesta por cien participantes con las características que se muestran en la Tabla 1. La selección de los participantes se hizo mediante un muestreo no probabilístico y de modo intencional en función de las características antes mencionadas. Adicionalmente, para lograr mayor precisión en el experimento, fue imprescindible establecer criterios para la selección de la muestra: Mostrar disposición voluntaria a participar en la investigación, saber usar un computador y no presentar limitaciones visuales que entorpezcan el reconocimiento de imágenes. Instrumentos En el diseño del instrumento se llevaron a cabo tres fases. En la Primera Fase se realizó la recopilación de pares de fotografías del rostro de una persona entre 30 y 45 años de edad y su homóloga cuando tenía entre 15 a 25 años de edad. Para este proceso se recurrieron a las redes sociales, bases de datos de fotografías disponibles en internet (UB KinFace Database of Northeastern University http://www3.ece.neu.edu) y por solicitud directa de colegas y amigos de los experimentadores. Se recopilaron 240 fotografías correspondientes a 120 personas de tres grupos étnicos: caucásicos, de color y asiáticos. Estas fueron procesadas a un formato blanco y negro de tamaño estándar a 264x356 pixeles. En la Segunda Fase se diseñó un prototipo preliminar del instrumento en PowerPoint, se utilizaron macros y el lenguaje de programación Visual Basic. El instrumento estaba compuesto por la diapositiva de instrucciones, diez diapositivas que contenían en la parte superior la fotografía de una persona adulta entre 30 y 45 año de edad. En la parte inferior se mostraban 6 fotografías de personas jóvenes Estas pruebas preliminares permitieron identificar que el total de aciertos y desaciertos no eran suficiente para los objetivos de la investigación, por tal motivo se llevó a cabo una Tercera Fase, en la que se desarrolló una plataforma web con características similares a las del primer instrumento, pero que adicionalmente registraba el tiempo que tardaba cada participante en emparejar la fotografía homóloga y aumentando el número de ensayos a 20. Este instrumento fue desarrollado con lenguajes de programación PHP, HTML5, JavaScript y base de datos MySQL. Para seleccionar las 20 fotografías de las personas adultas se utilizó un procedimiento aleatorio, que seleccionaba de entre las 120 fotografías de adultos tomando en cuenta los siguientes parámetros: 7 de grupo étnico caucásico, 7 de grupo étnico de color, 6 de grupo étnico asiático, 1 o 2 fotografías de personajes públicos por cada grupo étnico y que no se repita ninguna fotografía de adulto, hubiera 10 fotografías de mujeres y 10 fotografías de hombres. Para seleccionar las fotografías de las personas jóvenes se consideraron los siguientes parámetros: La fotografía de la persona joven correspondiente, 5 fotografías al azar de personas jóvenes del mismo género y grupo étnico y que no se repita ninguna fotografía de joven. Este nuevo instrumento facilitó a que el experimento pueda ser realizado también en forma virtual sin necesidad de la presencia del experimentador. Procedimiento Para llevar a cabo el experimento se contactaron 30 participantes de forma presencial y 70 por medio de Facebook y correo electrónico. En cada caso se le pedía al participante ingresar al sitio http://ticaula.citic.cr/experimento en una computadora de escritorio o portátil. En la primera página se informaba sobre el experimento, si estaba de acuerdo en participar se le pedía que llene un formulario con sus datos: cédula, edad, país y género. Posteriormente, al presionar el botón de registro se mostraba la página de instrucciones. En ésta página se le pedía al participante realizar una práctica con un ejemplo de una persona famosa. Después el experimentador preguntaba si todo está claro antes de que presione el botón de inicio. Una vez que el participante daba inicio se registraba el tiempo actual de apertura del ensayo en un reloj ubicado en la parte inferior de la página y se iban contabilizando 30 segundos. Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) 43 En esta parte también se informaba al participante el número de ensayo en orden inverso comenzando desde el 20. Se consideró ubicar los relojes en la parte inferior y de tamaño pequeño con el fin de que no sea un distractor para el participante. Para registrar el tiempo en segundos que le toma al participante emparejar las dos fotografías mediante sus inferencias se restaba la hora del reloj derecho del reloj izquierdo. Si el participante no seleccionaba ninguna fotografía dentro de 30 segundos, el instrumento pasaba al siguiente ensayo. Este proceso se repetía hasta que se presenten los 20 ensayos. Es importante indicar que se controló que los 20 ensayos sean los mismos para todos los participantes, lo único que cambia es el orden mediante un proceso aleatorio, es decir que los ensayos no se muestran en el mismo orden para todos los participantes, así como también las fotografías de personas jóvenes se mostraban en orden aleatorio. Como se explicó en la sección del diseño del instrumento, en la fase 2 se utilizó un procedimiento que seleccionó de forma aleatoria las fotografías de las personas adultas. En este proceso se controló que haya un equilibrio entre género y grupo étnico. Finalmente, el instrumento mostraba a cada participante los resultados de los aciertos, el tiempo total del experimento, el tiempo promedio de los aciertos y el tiempo promedio de todos los ensayos realizados. El tiempo máximo del experimento se contemplaba en aproximadamente 15 minutos por participante. Con el fin de complementar la información se utilizó una encuesta como segundo instrumento. La encuesta fue realizada en Google Drive estructurada con 10 preguntas. Análisis de datos Los resultados obtenidos fueron analizados cuantitativamente, teniendo en cuenta las hipótesis de la investigación. El análisis estadístico se realizó con el programa SPSS. En primer lugar se presenta la estadística descriptiva de los datos y, posteriormente se presenta el análisis estadístico por cada una de las hipótesis, utilizando las pruebas t de Student y chi-cuadrado (para la tabla de contingencia). Los resultados del análisis de los datos se muestran en la siguiente sección. RESULTADOS En relación a la primera hipótesis, los participantes son capaces de emparejar un rostro observado en una fotografía con el homólogo respectivo de veinte años atrás, acertando en promedio una cantidad de personas mayor a 10 (un porcentaje de acierto mayor del 50%) en un tiempo promedio menor a 10 segundos. Estos resultados se verificaron al realizar una prueba t de Student de una cola con un 95% de confianza para cada una de las variables dependientes. La prueba t de Student de una cola con un 95% de confianza para la variable Cantidad de aciertos se obtiene t(3,437;99) = 0,0005 (p < 0,05), esto muestra que los Figura 1. Cantidad de participantes por género que utilizaron ciertos elementos del rostro para realizar el emparejamiento. participantes del experimento son capaces de emparejar un rostro observado en una fotografía con el homólogo respectivo de veinte años atrás, con un porcentaje mayor del 50%. La prueba t de Student de una cola con un 95% de confianza para la variable Tiempo de respuesta se obtiene t(-2,004;99) = 0,024 (p < 0,05), esto quiere decir que los participantes del experimento son capaces de emparejar un rostro observado en una fotografía con el homólogo respectivo de veinte años atrás, en un tiempo menor a la tercera parte del total de tiempo asignado para el experimento. En relación a la segunda hipótesis, en la Figura 1 se observa que los elementos del rostro: ojos, boca y nariz fueron la base sobre la cual los participantes orientaron sus procesos “top-down”: para la deconstrucción y reconstrucción del rostro (partes) a través de métodos analíticos y sintéticos; sin importar el género. Siguiendo con los resultados de los elementos del rostro que fueron la base sobre la cual los participantes realizaron el emparejamiento, se realizó una tabla de contingencia para averiguar si existía relación de dependencia entre el género de un participante y los elementos del rostro que utilizó para emparejar un rostro observado en una fotografía con el homólogo respectivo de veinte años atrás (donde se tiene la cantidad de participantes que contestaron en la encuesta los elementos del rostro utilizados para llevar a cabo el experimento). De acuerdo a la información de la tabla de contingencia se realizó la prueba χ2 (chi-cuadrado) con 95% de confianza, obteniendo χ2(15,002;11) = 0,182 (p > 0.05), por lo que las variables son independientes, o sea, el género de un participante no es determinante al utilizar ciertos elementos del rostro para realizar el emparejamiento. Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) La media de la cantidad de aciertos de las mujeres es mayor (los participantes masculinos muestran en promedio más fallas que las participantes femeninas en el emparejamiento) y la media del tiempo de respuesta de los hombres es menor (los participantes masculinos duraron en promedio menos que las participantes femeninas en el emparejamiento); no existe realmente una diferencia significativa en ambos casos. Para corroborar estos resultados se realizó la prueba t de Student de una cola con un 95% de confianza para cada variable dependiente, comparando las medias de dos muestras independientes: participantes femeninas y participantes masculinos. La prueba t de Student para dos muestras independientes de una cola con un 95% de confianza para la variable Cantidad de aciertos, donde existe igualdad de varianzas según la prueba de Levene F(3,925;1;98) = 0,05 (p ≥ 0,05), t(1,285;98) = 0,101 (p ≥ 0,05). Este resultado muestra que no existe diferencia significativa entre participantes masculinos y femeninos, con relación en la cantidad de aciertos promedio al intentar emparejar un rostro observado en una fotografía con el homólogo respectivo de veinte años atrás, independientemente del sexo de las personas de las fotografías. La prueba t de Student para dos muestras independientes de una cola con un 95% de confianza para la variable Tiempo de respuesta, donde existe igualdad de varianzas según la prueba de Levene F(0,3841;98) = 0,537 (p ≥ 0,05), t(0,569;98) = 0,2855 (p ≥ 0,05). Este resultado muestra que no existe diferencia significativa entre los participantes masculinos y las participantes femeninas; o sea, el tiempo de respuesta promedio es igual en ambos al intentar emparejar un rostro observado en una fotografía con el homólogo respectivo de veinte años atrás, independientemente del sexo de las personas de las fotografías. Discusión De acuerdo con los datos expuestos, los resultados señalan que los participantes son capaces de emparejar un rostro observado en una fotografía con el homólogo respectivo de veinte años atrás, tal como se ha mencionado, el rostro constituye –desde el punto de vista biológico, psicológico y social- el estímulo visual de mayor significación para el ser humano [8]. Numerosos estudios [1][2][3][7] han demostrado ampliamente cómo el rostro constituye una clave esencial para identificar aspectos tan básicos como: el sexo, la edad, el grupo étnico, y aspectos más complejos como: sus estados de ánimo y el atribuirle características de personalidad o perfilar la identidad de una personas CONCLUSIONES El estudio parece mostrar la habilidad de nuestro aparato cognitivo para utilizar mecanismos de procesamiento de 44 información que hace posible la asociación de un par de fotografías homólogas y a la vez distintas por variables de edad, lo cual implica una habilidad para proyectar un pensamiento retrospectivo o prospectivo respecto a una imagen y esquematizar un rostro no familiar al tiempo que se intuyen los cambios del mismo a través del tiempo. Adicionalmente, este estudio parece no mostrar diferencias significativas entre los participantes en relación con su género [4], tampoco hay investigaciones homólogas con qué contrastar los resultados obtenidos. Resulta interesante para futuras investigaciones tomar en cuenta el “dinamismo” del rostro, y realizar el experimento con una etapa de asociación “in vivo”, es decir, utilizar un participante modelo que deba ser asociado u homologado con su fotografía correspondiente, pues, puede considerarse como variable, la estática facial en una fotografía y la facilidad que ésta representa para realizar una asociación, situación que podría tornarse más compleja si el rostro se encuentra dinámico, en movimiento y expresivo. AGRADECIMIENTOS Al Dr. Odir Rodriguez (Maestría en Ciencias Cognocitivas) por su guía en la experimentación con humanos. Al Centro de Investigaciones en Tecnologías de la Información y Comunicación (CITIC) por el contingente tecnológico para publicar la plataforma en la web. REFERENCIAS 1. Adolphs, R. (2001). The neurobiology of social cognition. Current Opinion in Neurobiology, 11(2), 231–9. 2. Alley, T. R. (2013). Social and Applied Aspects of Perceiving Faces (p. 285). Psychology Press. 3. Bruce, V., & Young, A. (1986). Understanding face recognition. British Journal of Psychology, 77(3), 305– 327. 4. Heisz, J. J., Pottruff, M. M., & Shore, D. I. (2013). Females scan more than males: a potential mechanism for sex differences in recognition memory. Psychological Science, 24(7), 1157–63. 5. Johnson, M. H., Dziurawiec, S., Ellis, H., & Morton, J. (1991). Newborns’ preferential tracking of face-like stimuli and its subsequent decline. Cognition, 40(1-2). 6. Liggett, J. (1974). The human face. New York, NY, USA: Stein & Day Pub. 7. Lopera, F. (2000). Procesamiento de caras: bases neurológicas, trastornos y evaluación. Revista de Neurología, 30(5), 5. 8. Manzanero, A. (2010). Procesos cognitivos en el reconocimiento de caras. In Memoria de Testigos (pp. 131–146). Madrid, España: Ed. Pirámide. Adolphs, R. (2001). The neurobiology of social cognition. Current Opinion in Neurobiology, 11(2), 231–9. 45 Diseño de una interfaz para la evaluación del rango articular en terapias tumbadas Kaiser Williams, Karla Arosemena y Christopher Francisco Universidad Tecnológica de Panamá {kaiser.williams, karla.arosemena, christopher.francisco}@utp.ac.pa RESUMEN Este trabajo muestra los requerimientos de usabilidad tenidos en cuenta al momento de diseñar una interfaz que intente evaluar el rango articular. El articulo muestra los resultados de los análisis que se realizaron a los usuarios, tareas y entorno laboral. Además presenta los resultados de las pruebas de usabilidad aplicada al prototipo diseñado. Para lograr esto se utilizó una metodología de diseño de software centrada en el usuario, de manera que, la interfaz tuviera los requerimientos reales de los usuarios y fuese una herramienta real de apoyo para su labor. Palabras claves Rango articular, escenarios, interfaz, usuario, diseño. INTRODUCCIÓN Al visitar los centros de rehabilitación física de pacientes que padecen artrosis de cadera, percibimos la necesidad de incorporar alguna interfaz que le permitiera al terapeuta evaluar el rango articular (RA) de los pacientes que estaban en estos programas de una manera más continua y objetiva. Entendiendo primero, que el RA es “la distancia y dirección que una articulación ósea puede extenderse”[1], se observó que los terapeutas, debido a la gran cantidad de paciente que atienden en la jornada del día, no pueden realizar evaluaciones de RA a los pacientes al finalizar o iniciar cada sesión. Debido a esto, ellos solo realizan las mediciones del RA al inicio y al final de un tratamiento de terapias, o sea solo 2 veces. Esto nos induce a preguntar ¿cómo sabe el terapeuta que su paciente está mejorando o empeorando? ¿Podrá tener el terapeuta algún otro elemento que apoye su experticia y experiencia al momento de redactar alguna recomendación al médico? Ante esta problemática observada y presentada, nos planteamos la interrogante ¿Cómo se podría apoyar al terapeuta en la evaluación del RA? En la revisión literaria que iniciamos observamos el gran impacto que ha tenido el Se autoriza hacer copias de este trabajo o partes de él para uso académico, siempre y cuando sea sin fines de lucro. La copia debe contener esta nota y la cita completa en la primera página. La copia bajo otras circunstancias y la distribución o publicación podría requerir permisos adicionales o pago de derechos. JoCICI 2015, Marzo 5-6, San José, Costa Rica. Copyright © 2015 CITIC-PCI Eric De Sedas Universidad Católica Santa María La Antigua [email protected] sensor Kinect en la evaluación del RA. Algunos de estos ejemplos podemos encontrarlos en [2-5]. Estos ejemplos sirvieron como base para tomar la decisión de utilizar el sensor kinect para este fin. Sin embargo se pudo notar, en la literatura revisada, que no se han presentado estudios de usabilidad a los métodos de evaluación del RA propuestos, no pudimos concluir si las técnicas son los más convenientes para los terapeutas, ni se pudo saber si ellos, como usuarios no informáticos, lo llegaron entender. También en los trabajos revisados escasamente se encuentran los nombre de los movimientos de la articulación a la cual están evaluando (flexión, extensión, abducción, entre otros). Estos detalles nos impulsaron a la aplicación de técnica de diseño centrado en el usuario para proponer un diseño acorde a las necesidades del terapeuta. El terapeuta, para la medición del RA, puede valerse de varios instrumentos tales como las radiografías, las fotografías, el electro-goniómetro, el flexómetro, entre otros[2], los cuales permiten conseguir una medición objetiva, válida y fiable del RA, pero no siempre pueden practicarse en todos los ambiente clínico. Es por ello que, debido a su fácil disponibilidad, los terapeutas utilizan comúnmente una herramienta manual llamado goniómetro[1]. Este instrumento consta de dos brazos, con un indicador en uno de ellos y una escala transportadora de 180° a 360° en el otro. Este instrumento requiere que el paciente sostenga la ejecución del movimiento articulación a evaluar mientras que el terapeuta sitúa los brazos en las posiciones correctas de los huesos involucrados, el señalamiento del brazo que tiene los grados es el que indicara el RA. Este proceso de evaluación no podría ser llevado al momento en que el paciente está realizando una terapia, ya que este necesita sostener el movimiento. La interfaz propuesta intenta mantener una evaluación del RA constante, mientras el paciente realiza su terapia. También espera que le permita al fisioterapeuta realizar una evaluación del RA inicial del paciente cuando este le es asignado. Ya que esto son algunos de los primeros pasos que se pudo observar que realiza el terapeuta cuando inicia un proceso de terapia. Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) Característica Edad Hallazgo Requisitos de la interfaz - Las letras no pueden ser muy pequeñas. - El contraste de colores debe ser notorio para facilitar la lectura a distancia Entre 24 y 50 años Limitaciones físicas Las Limitaciones físicas no fueron halladas pero no deben ser descartadas. Nivel de conocimientos en el uso general de las computadoras Medio: utiliza algunos programas de la computadora para desarrollar el trabajo. Sabe navegar en internet. No le incomoda utilizar la computadora, pero prefiere utilizarla solo cuando es necesario Experiencia previa con aplicaciones similares Perspectiva del usuario sobre la interfaz 46 Ninguna Puntual: La perspectiva de usuario revela sus necesidades y sugieren algunos requerimientos - Formas de interactuar adicionales al mouse y teclado (voz, gesto). - Retroalimentación visual y auditiva en caso de que la persona, ya sea por distracción o ruido en el medio, no pueda oír o ver. - Imitar los botones y las metáforas propias de los programas que más utilizan. - Debe evitarse la aparición de múltiples pantallas para realizar las tareas. - Pocas instrucciones y muy ordenada. - Usar términos terapéuticos habituales para ellos - Los resultados sean fáciles de entender, identificar y buscar. - Indicaciones básicas Tabla 1 Requerimientos de la interfaz acorde a los hallazgo METODOLOGÍA Para el diseño de esta interfaz se utilizó una metodología de Diseño Centrada en el Usuario (DCU). La aplicación de esta metodología nos permitió recolectar los requerimientos de los usuarios y acondicionar el diseño de la interfaz a las necesidades de este [6], permitiendo así un diseño en donde los usuarios sintieran cada sección de la interfaz como una extensión de sus actividades y no como algo nuevo por aprender. Para lograr esto, la metodología aplicada se sub dividió en tres diferentes análisis: análisis de usuario, de tareas y entorno [7]. Análisis de usuario En el diseño de una interfaz es importante conocer para quienes está siendo diseñada la aplicación y que esperan los usuarios de ella. La persona o el grupo de personas que usaran primeramente la aplicación se les conoce con el nombre de usuarios primarios o usuarios [7], en nuestro caso serían los terapeutas. Este análisis se realizó con el objetivo de saber de manera más precisa las características grupales de los usuarios para los que se espera diseñar la interfaz. Características del usuario Para la caracterización, se encuestó al 80% (13 de 16) de los usuarios de la interfaz, que laboran en el centro de rehabilitación física visitado. También, se realizaron dos sesiones de entrevistas de hora y media cada una. Las entrevistas incluyeron tres usuarios diferentes por sesión. Estas actividades nos permitieron agrupar las características más importantes encontradas, y de esta manera definir los requisitos que debe tener el sistema para complementarlas. Estas son presentadas en la Tabla 1. Tal como señala Stone[7], los requisitos presentados podrían cambiar al momento de realizar las pruebas de usabilidad, así que no se consideraron como requisitos finales Análisis de tarea Para iniciar el desarrollo de este análisis lo enmarcamos en base a dos preguntas: 1. ¿Cuál es la meta final que desea nuestro usuario? y 2. ¿Cuáles son las tareas que el usuario realiza para lograr esa meta? Considerando lo anterior, se efectuó el análisis con la intención de entender lo que la interfaz de computación deberá hacer y la funcionalidad que esta debe proveer para que los usuarios sean apoyados en sus tareas y así logren su meta. Por medio de observaciones contextuales, las cuales fueron cinco días a razón de dos horas por día, y el desarrollo de un escenario de tarea, en donde se preguntó y se simuló el procedimiento que generalmente efectúan nuestros usuarios, se pudo conocer que la meta principal es la reeducación de las habilidades perdidas por el paciente. Para lograr esta meta, se deben ejecutar diferentes tareas. Entre esas tareas y para efecto de nuestra interfaz, la tarea que se tomó en cuenta es la evaluación del rango articular, en donde se emplearon las ocho preguntas sugeridas por Stone [7] para entender una tarea del usuario. Estas y sus respuestas, son presentadas en la Tabla 2. Por último, para este análisis, se realizó una entrevista en donde se les presentaron diferentes escenarios que describían las tareas de la manera en que habían sido entendidas, los usuarios corrigieron las descripciones Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) erradas. Toda esta información nos permitió concluir en los siguientes requisitos de nuestra interfaz: Una interfaz que pueda visualizarse a mínimo 2.5 metros de la pantalla. La capacidad de controlar la aplicación a distancia. La mayor similitud de los pasos que hace el fisioterapeuta, incluso en el orden que generalmente lo hace. Flexibilidad en el tiempo de descanso, la cantidad de repeticiones y el tiempo de inicio, que no debe ser automático, ni fijo. Tener un listado de los ejercicios que se podrán hacer y poder escoger que hacer. Incluir en el sistema la indicación del uso de algún otro artefacto que proporcione extra peso. Una retroalimentación visual pronunciada, es decir que con facilidad el usuario pueda ver donde está ubicado su cursor. Evalúe el rango articular. Interacción a través de la voz. Esto debido a que el terapeuta puede requerir pausar la terapia en cualquier momento por alguna situación que le ocurra al paciente. Análisis del entorno Este análisis se realiza con la finalidad de conocer las condiciones físicas en las que se desarrollan las tareas, las recomendaciones de seguridad que se toman en el lugar donde se desarrolla la tarea, las relaciones interpersonales entre usuarios y las políticas internas de la organización. Características ¿La tarea varía cada vez que se va a desarrollar? ¿Con cuánta frecuencia se desarrolla la tarea? ¿Qué clase de habilidades o conocimientos son requeridas? ¿Es la tarea afectada por el entorno? ¿Es el tiempo crucial en el desarrollo de la tarea? ¿Existe algún riesgo para la seguridad? ¿El trabajo es realizado solo o con otros? ¿El usuario estará cambiando entre tareas? Respuesta Sí. La tarea varía por el tipo de movimiento que se desee evaluar (flexión o abducción) La tarea solo es realizada oficialmente al inicio y finalización de las jornadas de rehabilitación. El uso del goniómetro aplicado al rango articular. Saber sobre los tipos de movimientos que realiza una articulación en particular. No. El dolor del paciente puede dificultar la evaluación. No. El tiempo no es un factor considerado en la ejecución de la tarea No. El trabajo es realizado solo. El usuario no cambiará entre tareas, podrá cambiar de movimiento, no de tarea. Tabla 2 Análisis de la tarea Elemento Criterio de medida Efectividad % realizado 47 Escala de medida Medida Mejor de los casos Nivel planea do Peor de los casos % 100% 5199% 0-50 % Tabla 3 Métrica de usabilidad diseñada Las características encontradas en estos puntos mencionados también influyeron en el diseño de la interfaz. Estas nos permitieron concluir en las siguientes recomendaciones de diseño de la interfaz: Un uso de colores pasivos (azul por ejemplo) ya que la iluminación no es fuerte, evitando la fatiga visual. Poca o ninguna retroalimentación auditiva, ya que esto incrementaría el ruido en la sala de terapia. Secciones donde el terapeuta pueda agregar sus comentarios a los resultados presentados por la interfaz. Prototipo Finalizados los análisis ya presentados, se procedió a la creación del primero prototipo que nos permitiría aplicar las primeras pruebas de usabilidad y de esta manera comprobar la usabilidad de nuestra interfaz. Como apoyo, utilizamos la recomendación dada por Quesenbery en [7] la cual expone cinco elementos importantes que se deben comprobar en una interfaz: efectividad, eficiencia, atractivo, facilidad de aprendizaje y tolerancia al error. En base a ellos se diseñó una métrica de usabilidad la cual incluyo: el elemento a comprobar, el criterio de medida, el método para medirlo y la escala de medida; la cual se desglosaba a su vez en: mejor de lo casos, nivel planeado y el peor de los casos. Una parte de la misma la vemos en la Tabla 3. Para la pruebas de usabilidad participaron cinco usuarios, a los cuales se les asigno tres tipos de escenarios diferentes. Estos escenarios no solo indicaban una tarea principal a realizar sino también algunas sub-tareas que reforzaban la realización correcta de la tarea. La prueba se programó para que no durara más de 30 minutos. Además el usuario debía resolver todos los escenarios planteados sin ayuda. En la ¡Error! No se encuentra el origen de la referencia. se muestra algunas pantallas de la interfaz que se utilizaron para las pruebas de usabilidad. Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) Figura 1 a) Pantalla para realizar evaluación del RA; b) Pantalla para programar las terapias. RESULTADOS DE PRUEBAS DE USABILIDAD Durante la realización de la prueba se les pedía a los usuarios que comentarán en voz alta lo que estaban pensando que tenían que hacer para completar la tarea. Estos datos también fueron anotados. Posteriormente a la realización de los escenarios, procedimos a realizarles algunas preguntas en cuanto a los elementos restante que menciono Quesenbery. Al finalizar las pruebas pudimos obtener los siguientes resultados: Efectividad (precisión): en los 3 escenarios, todos los usuarios lograron terminar la actividad en un 100%, indicando que realizaron de manera correcta las sub-tareas que reforzaban la culminación de la tarea. Las acciones regresivas, debido a confusiones, se mantuvieron en los rangos establecidos en la métrica de usabilidad diseñada. Esto nos indicó que la efectividad de los usuarios en la realización de las tareas a través de la interfaz es buena. Eficiencia (velocidad operacional): Comparando el tiempo tomado por los usuarios para realizar las tareas y la escala de usabilidad establecida en la métrica diseñada, pudimos ver que los usuarios se mantuvieron en el nivel planeado o el mejor de los casos. Los usuarios no pasaron el tiempo fijado, el cual iba desde los dos minutos (mejor de los casos) y los ocho minutos (limite nivel planeado), en la escala para la realización de cada tarea. Los intentos de los usuarios buscando alguna sección de ayuda estuvieron dentro del nivel planeado de la escala diseñada. De esta manera verificamos la eficiencia de nuestra interfaz. Atractivo (lo que atrae al usuario): los usuarios comentaron diferentes cosas atractivas que encontraron en la interfaz. Estas, según expresaron, los hacía sentir cómodas al interactuar con la interfaz. Algunas de las mencionadas fueron: Que para todo tiene guías (retroalimentación), los movimientos que se pueden programar son bastante flexibles y no son una receta, los colores son bastante agradables y fáciles de percibir. También se obtuvo las cosas que no les gustaron al usuario, entre estas: falta de algunos campos en la información del paciente, uso de palabras no tan usadas por ellos, botones en una posición un poco difícil de encontrar. Facilidad de aprendizaje: el 100% de los usuarios contestaron con la calificación más alta (+3) en la escala presentada en el cuestionario. También el 80% de los usuarios comentaron que si pasara algún tiempo en que no utilizaran la interfaz, podrían volver a interactuar con ella sin problemas. 48 Tolerancia al error: ante este elemento, el 60% de los usuarios mencionó que la interfaz le daba una excelente orientación (+3). El otro 40%, mencionó que esta brindaba una buena orientación (+2). CONCLUSIONES Como hemos mostrado a través de las pruebas de usabilidad, la interfaz propuesta ha presentado buenos resultados de interacción para los fisioterapeutas. Estos logros nos han señalado que la realización de este proyecto ha comenzado buscando satisfacer a los usuarios de nuestra interfaz. Por ello hemos concluido que la primera fase en el diseño de la interfaz para la evaluación del RA en terapias tumbadas ha servido de apoyo para la realización de la tarea y sub-tareas involucradas en evaluación de RA. También que el usuario podrá ver la interfaz como un elemento más de trabajo y no como una herramienta impuesta de ayuda. TRABAJOS FUTUROS Como trabajo futuro se espera programar, ya sea a través del tratamiento de imágenes de profundidad o la creación de un motor de lectura para el kinect, el reconocimiento de movimientos articulares en posición tumbada (acostada). REFERENCIA [1] L. Ruiz García, R. Navarro Navarro, J. A. Ruiz Caballero, J. Jiménez Díaz, and M. E. Brito Ojeda, "Biomecánica de la cadera," 2003. [2] A. E. Salazar, W. A. Castrillón, and F. Prieto, "Herramienta de Asistencia en el Diagnóstico de la Movilidad Articular en 3D Software for Assisted Diagnostic of Joint Motion in 3D," Avances en Sistemas e Informática, vol. 5, pp. 55-64, 2008. [3] A. Fernández-Baena, A. Susín, and X. Lligadas, "Biomechanical validation of upper-body and lowerbody joint movements of kinect motion capture data for rehabilitation treatments," in Intelligent Networking and Collaborative Systems (INCoS), 2012 4th International Conference on, 2012, pp. 656-661. [4] A. Bo, M. Hayashibe, and P. Poignet, "Joint angle estimation in rehabilitation with inertial sensors and its integration with Kinect," in EMBC'11: 33rd Annual International Conference of the IEEE Engineering in Medicine and Biology Society, 2011, pp. 3479-3483. [5] J. Liu, H. Chuan, and P. Kuan, "Assessment of range of shoulder motion using Kinect," Gerontechnology, vol. 13, p. 249, 2014. [6] G. Vera, "Diseño centrado en el usuario," 2014. [7] D. Stone, C. Jarrett, M. Woodroffe, and S. Minocha, User interface design and evaluation: Morgan Kaufmann, 2005. 49 Troyóculus: Gafas electrónicas para potenciar la visón de personas con problemas de visión baja Paúl Fernández Barrantes [email protected] Adrián Fernández Malavasi [email protected] ABSTRACT METODOLOGÍA Thanks to the easy access to technology, nowadays it is possible create new devices that make life easier. This research is about a device that we will call "Troyóculus". This device shares features of different technologies as the virtual reality, web cams, and image processing, to help people with some low vision problems. Este proyecto se encuentra en fase de prototipado, por lo cual se han empleado diferentes piezas de hardware comerciales, es decir aún, no se ha creado un dispositivo propio. A continuación se detallara cada una de estas piezas. INTRODUCCIÓN La tecnología ha ayudado a las personas discapacitadas a que puedan alcanzar un mejor nivel de vida. Por ejemplo se han diseñado huesos y prótesis con impresoras 3D. Sin embargo, siempre se puede innovar para crear dispositivos o técnicas para mejorar sus condiciones de vida. Como mecanismo para generar la realidad virtual se emplea el Oculus Rift Developer Kit 1[1]. Cabe mencionar que este dispositivo fue pensado originalmente para el desarrollo de video juegos y simuladores. Enfermedades como la ectasia posterior (abultamiento en la parte posterior del ojo), retinosis pigmentaria (degeneramiento progresivo de la retina) y estrabismo (una desviación del alineamiento de un ojo respecto al otro), son problemas visuales cuyas consecuencias van desde la pérdida parcial de la vista hasta la total. En cuanto a sus detalles técnicos, posee una pantalla con una resolución de 720 (es decir, 720 líneas horizontales). Esta se encuentra dividida a la mitad con el objetivo de separar lo visible por cada ojo y generar el efecto de profundidad. Además utiliza lentes oftálmicos diseñados para generar un efecto similar al de una lupa. Por último, posee una caja de controles donde se encuentra la entrada de video HDMI, y desde la cual se puede cambiar el brillo y el contraste de la pantalla. Las personas que las padecen no pueden realizar muchas de sus actividades cotidianas sin ayuda de otras personas o requieren de condiciones especiales de luz. Esto limita sus posibilidades para estudiar, trabajar y divertirse; por mencionar algunas. Esto conlleva a una reducción de su independencia y calidad de vida en general. La cámara empleada en esta investigación es una Microsoft Lifecam Cinema [2]. La razón por que fue escogida, es su mecanismo automático de corrección de color conocido como true color. Además de esto posee otras características importantes como enfoque automático y alta resolución (720 líneas horizontales con barrido progresivo. En la actualidad, la mayoría de estas enfermedades son incurables y, lamentablemente, tampoco existen tratamientos efectivos para mitigar sus efectos. Por esta razón, se está desarrollando un dispositivo llamado Troyóculus. Este utiliza técnicas de realidad virtual en conjunto con cámaras de vídeo para capturar, en tiempo real, información visual del medio. Después de esto, transforma la imagen para ser vista, en una pantalla con condiciones como brillo, contraste, enfoque y ubicación, controlables por el paciente. Todo esto con el objetivo de crear las condiciones necesarias para maximizar la visión del paciente. La última pieza de hardware utilizada es un control inalámbrico de la consola de videojuegos XBOX 360 [3]. Esta se incluyó con el objetivo de que el paciente pueda, en tiempo real, controlar algunas variables de ambiente presentes como brillo, zum y filtros de colores, entre otras. Se autoriza hacer copias de este trabajo o partes de él para uso académico, siempre y cuando sea sin fines de lucro. La copia debe contener esta nota y la cita completa en la primera página. La copia bajo otras circunstancias y la distribución o publicación podría requerir permisos adicionales o pago de derechos. JoCICI 2015, Marzo 5-6, San José, Costa Rica. Copyright © 2015 CITIC-PCI Para el desarrollo a nivel de software, se emplea el Oculus Developer Kit integrado con Unity versión 4.6 [4]. Aunque desde un punto de vista computacional hay opciones más eficientes que usar un motor para la creación de videojuegos como Unity, esto nos permitía desarrollar un mínimo producto viable de manera más rápida. Por otra parte, el lenguaje de programación empleado es C#. Como metodología de desarrollo, se emplea una adaptación del desarrollo guiado por pruebas. Esta técnica perteneciente al grupo de metodologías ágiles, se caracteriza por invertir el orden común de creación de software: primero se crean las pruebas, luego se desarrollan las funcionalidades que las cumplan y por último se hacen ajustes según sea necesario; todo esto en fases pequeñas y rápidas. Cabe mencionar que se habla de una adaptación, Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) pues esta técnica fue desarrollada en un inicio como mecanismo para el diseño y la implementación de software. Sin embargo, esta investigación engloba aspectos más complejos como la adaptación de hardware, la experimentación con pacientes y la retroalimentación tanto de pacientes como de especialistas en el área. Para realizar pruebas se cuenta con un paciente que padece diversas enfermedades visuales como lo son: ectasia, retinosis pigmentaria, estrabismo y miopía (padecimiento que dificulta el enfoque de objetos a larga distancia). Este para poder visualizar su entorno necesita de una excesiva cantidad de luz, además de que el estrabismo le provoca una visión muy pobre en el ojo derecho. Cuando se trata de temas tan delicados como la salud, es necesario contar con la opinión profesional de un experto en el tema. Por esta razón se consultó al inicio de esta investigación al licenciado en optometría Jairo Madriz y a la doctora en oftalmología, Johanna Sauma. A ambos se les consultó sobre la viabilidad del proyecto, los posibles efectos secundarios y detalles de las enfermedades que padece el paciente. A ambos especialistas el proyecto les pareció factible e incluso extensible a otras enfermedades y usos en la oftalmología ya que indicaron que podría emplearse para realizar terapia visual. Por último, ambos consideraron que la posibilidad de que el Troyóculus generara efectos secundarios en los pacientes es prácticamente nula. Para la primera fase, se buscó probar que el paciente no presentara efectos adversos al utilizar el Oculus Rift. Para esto se le colocó el dispositivo y se ejecutaron algunos de los simuladores disponibles en el mercado. Para recopilar datos sobre la experiencia del paciente al usar el dispositivo, se le preguntó sobre que objetos tenía al frente, y si se sentía mareado o si tenía algún malestar en la vista. La sesión de pruebas se extendió por aproximadamente una hora y se pidió al paciente que informara si durante las horas posteriores percibía algún efecto adverso, lo cual no ocurrió. El éxito de esta fase estaba dado si el paciente no presentara ninguna molestia. Figura 1 50 Para la segunda fase de investigación se construyó la primera versión del Troyóculus, la cual consistía únicamente del software que conectaba la cámara, el Oculus Rift y algunas funcionalidades muy básicas como zum y brillo ajustables. El objetivo de esta etapa era identificar la mejoría que pudiera obtener el paciente con el uso de esta versión. Para medir el éxito de esta fase, se diseñó un conjunto de pruebas sencillas donde el paciente debía realizar acciones cotidianas que normalmente se le dificultan: leer letras en una pizarra, identificar objetos que se encuentran alrededor de él, identificar el color de los objetos y leer un libro. Para una tercera fase, se le agregó más funcionalidades al Troyóculus, entre las cuales destacan la inclusión del control remoto para que el paciente pueda realizar ajustes y un filtro de color para regular la tonalidad de los colores. En la Figura 1 se puede observar el prototipo en esta fase de la investigación. Para esta tercera etapa, se reutilizó el conjunto de pruebas desarrollado en la fase previa, con el objetivo de cuantificar el éxito realizando una comparación de los resultados obtenidos de ambas sesiones. RESULTADOS Los resultados producidos por el prototipo actual con el paciente fueron alentadores: se puede ubicar mejor en su entorno, distingue mejor los objetos que se encuentran a su alrededor, puede leer letras escritas en la pizarra e incluso leer un libro. Además, no mostró síntomas adversos debidos al uso del aparato incluso por períodos relativamente extensos de una hora. En la Figura 2 se puede ver al paciente utilizando. Figura 2 Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) De manera específica, durante las pruebas realizadas a lo largo de las diferentes fases, se obtuvieron los siguientes resultados: 1. 2. 3. 4. 5. 6. El paciente requirió de un lapso menor a 10 minutos para acostumbrarse al dispositivo. El paciente logro visualizar de mejor manera los objetos en el espacio circundante utilizando el dispositivo que sin este. Incluso, logró identificar objetos del mundo real que nunca antes había conseguido observar, por ejemplo, el proyector del laboratorio. La persona logró leer textos escritos, tanto de un libro impreso como de una pizarra, aunque todavía presenta dificultades para hacerlo fluidamente. Esto se le atribuye a la baja resolución de la pantalla del Oculus Rift. Debido a limitaciones del hardware empleado los objetos transparentes, como botellas, siguen siendo indetectables por el paciente. El enfoque automático de la cámara presenta fallos cuando intenta distinguir un objeto cuyo color es igual al del fondo. Por lo cual se deberá mejorar el algoritmo de enfoque o bien incluir un modo manual controlable por el paciente. El prototipo no produjo efectos adversos en el paciente, incluso cuando este fue utilizado por periodos de hasta una hora. Sin embargo, según lo sugerido por los doctores consultados, para personas con problemas de foto sensibilidad es recomendable usar lentes con filtros especiales. 51 INVESTIGACIÓN FUTURA Lo siguiente a realizar es investigar acerca de cámaras o técnicas que permitan visualizar de manera óptima objetos transparentes. Además, se planea agregar una segunda cámara para crear un efecto de profundidad más efectivo, mejorar el enfoque que realizan las cámaras y crear un mecanismo de zoom digital. Por último, se agregará al dispositivo comandos de voz al para eliminar la dependencia del control remoto. A pesar de los resultados positivos obtenidos, es necesario probar este dispositivo con nuevos pacientes, por lo que se está estableciendo una alianza con una clínica privada para conseguir apoyo en este aspecto. Además, una vez corregido los problemas detectados en este estudio, se intentará expandir las funcionalidades del Troyóculus para el tratamiento de otras enfermedades como lo son el glaucoma (aumento en la presión intraocular que tiene como consecuencia la pérdida progresiva de las fibras nerviosas) y daltonismo (perdida de la percepción de al menos uno de los colores que percibe el ojo). Como un último paso, se creará un dispositivo con diseño completamente propio, que deje de lado el Oculus rift; ya que este además de tener sensores innecesario para los pacientes, es incómodo. De manera adicional, este nuevo modelo a desarrollar se hará portable para mejorar la experiencia del paciente. AGRADECIMIENTOS 1. Jairo Madriz, Licenciado Optometrista. 2. Johana Sauma, Doctora Oftalmóloga. CONCLUSIONES Tomando en cuenta lo básico del prototipo actual y los resultados obtenidos en las pruebas, concluimos que el Troyóculus puede llegar a ser en una herramienta de gran utilidad para las personas con visión baja. Por otro lado, aun cuando el dispositivo desarrollado hasta el momento es muy básico, las mayores limitantes del prototipo actual se deben al hardware empleado. REFERENCIAS 1. Oculus Rift, dispositivo de realidad aumentada. Oculus VR https://www.oculus.com/ 2. LifeCam Cinema, Cámara de microsoft, http://www.microsoft.com/hardware/en-us/p/lifecamcinema 3. Control inalámbrico de X-box 360, http://support.xbox.com/en-US/browse/xbox-360 4. Unity 3D, Motor de videojuegos. Unity technologies http://www.unity3d.com/ 52 Improving the performance of OpenFlow Rules Interactions Detection OscarVasquez-Leiton, J.deJesusUlate-Cardenas, Rodrigo Bogarin Costa Rica Institute of Technology San José, Costa Rica [email protected], [email protected], [email protected] ABSTRACT In recent years the dynamic programming of networks has gained popularity, this is known as Software Defined Networks (SDN). The communications protocol OpenFlow has become one of the most important amongst SDN. Currently most of OpenFlow configurations are done manually by using rules that define the network behavior of the nodes, which can be an error prone process, caused by the unwanted interactions that might occur between rules. There is previous work on the formal definition of interactions between rules and a detection algorithm, but the algorithm was only suited for OpenFlow applications with less than a few hundred rules, or during development of the applications. This work presents an improvement of the interactions detection algorithm performance, using well-known data structures to reduce the amount of required operations and a lazy comparison between rules (analogous to lazy initialization). The experiments showed the achieved improvement in the rules’ processing depends on the rule set composition, but the overall improvement was 41%, and it was determined that the changes in the algorithm present an alternative approach that makes the algorithm better suited to reside inside an OpenFlow switch and not used just during development as originally conceived. thanks to functionality it provides to configure the network traffic flows. Currently most of the OpenFlow configuration is done by applications, and this applications are created by a manual process of rules’ modifications that define network behavior, which can be an error prone process causing unwanted interactions between the rules. Bifulco and Scheider [3] proposed a formal definition for the interactions between rules and a detection algorithm, but stated that the algorithm was suited for use only with OpenFlow applications with just a few hundred of rules or during development. This definition and the algorithm are the base of the investigation. Software Defined Networks using OpenFlow is in its early stages of development, and there are still several unexplored areas of work. One of these areas is the evaluation of previous work and the proposed solutions, analyzing their applicability in current problems. This work explores previous work related to the firewall rules’ interaction detection, which is very similar to the OpenFlow rules’ interaction problem but with a much smaller problem domain; and also evaluates current work regarding OpenFlow rules programming. An alternative algorithm is proposed in this work, this algorithm is based on optimizations made in detection algorithms for firewall rules’ interactions. The experiments showed the achieved performance improvement compared to the original algorithm proposed by Bifulco and Schneider [3]. Palabras clave Computer Networks; OpenFlow; Algorithm; Interactions; Software Defined Networks. ACM Classification Keywords C o: mpunter Networks; Algorithms; Performance. INTRODUCTION During several decades computer networks have been statically programmed and tools have been created to facilitate this process, but in recent years dynamic programing has gained momentum, something known as software defined networks. The communications protocol OpenFlow [6] has become one of the most important in the Software Defined Networks, Permission to make digital or hard copies of all or part of this work for academic use is granted, provided that copies are not made or distributed for profit or commercial advantage and that copies bear this notice and the full citation on the first page. To copy otherwise, to republish, to post on servers or to redistribute to lists, requires prior specific permission and/or a fee. JOCICI’15, March 5-6, San José, Costa Rica. c Copyright 2015 CITIC-PCI RELATED WORK The interactions definition given in [3] is similar to the firewall rules interactions definition presented in [1], but the proposed algorithm is trivial and implies the comparison of all the rule set, whilst in [2] the researchers present a tree-based algorithm for faster lookups. In [5] a system is proposed to reduce the required resources to maintain the switch configuration and its interaction with the controller by grouping the rules having the same actions, however, the proposed uses the knowledge of the controller to group the rules, and this limits the application to the controller instead of a single switch. Another approach is the codification of flow tables using binary decision diagrams (BDDs) as presented in [1]. In this work Boolean algebra is used to compare the binarycodified rules. This approach requires the conversion of all the rules to the binary format and manually built binary deci- Proceedings of the II Costa Rican Workshop on Computer Science and Informatics (JoCICI 2015) sion diagrams. The presented model runs in a separate server with communication with the OpenFlow controller. The work presented in this paper takes the foundation established in [3] and presents an algorithm with improved performance, with the objective of making it more suitable for being deployed inside an OpenFlow switch, with a performance that allows better scalability for the number installed rules. RULES INTERACTIONS OpenFlow is a relatively simple protocol base on an Ethernet switch with one or more internal flow tables, and a standard interface for adding and removing entries from the tables. OpenFlow has some advantages over traditional switching technology, because it allows to run network configurations in heterogeneous switches (switches that combine traditional TCP/IP and OpenFlow configurations) without exposing the inner workings of the switch. The OpenFlow switch uses rule based programming, these rules are known as Flow Table Entries (FTEs), and are installed in the switch using the OpenFlow protocol. FTEs are defined by its match set defining network flows, and action set defining the forwarding decisions applied on the matching network packets. Bifulco and Schneider [3] define the switch’s behavior as the combination of the installed FTEs, because the same flow could be matched by several rules, and their priority would define which action set is applied. This means the defined network flows in a switch could be inadvertently modified when installing new FTEs. They proposed a formal classification of the rules interactions inside an OpenFlow switch, and provided a detection algorithm, but as mentioned before, it’s suited towards small applications or development time. The defined interactions are composed of match set relations and action set relations. Match set relations The match set is composed of values of the packet header, like ingress port, Ethernet address, IP values, etc. When a packet is received the OpenFlow switch performs a lookup in the flow table, and if there are several matches the FTE with the highest priority takes precedence. It’s possible to have wildcard values in the match set fields, and in some values there can be partial wildcards. The fields based on integer numbers only allow total wildcards and are called int based fields. The fields that allow arbitrary wildcards are named complex fields. The match set relations are derived from the relation of their fields. Given a field c1 and a field c2 , the field relations are defined as disjoint (c1 6= c2 ), equal (c1 = c2 ), subset (c1 ⊂ c2 ) and superset (c1 ⊃ c2 ). Based on this relations, the match set relations are defined as the following for two match sets M1 and M2 : disjoint (M1 6= M2 ), exactly matching (M1 = M2 ), subset (M1 ⊂ M2 ), superset (M1 ⊃ M2 ) and correlated (M1 ∼ M2 ). ACTION SET RELATIONS 53 The action sets are composed of action, and each action has a value and an action type. The action sets can have zero or more actions. The relation between two actions a1 and a2 can be one of the following: disjoint (a1 6= a2 ), equal (a1 = a2 ) and related (a1 ∼ a2 ). Based on the action relations, the possible action set relations between two action sets A1 and A2 are defined as: disjoint (A1 6= A2 ), equal (A1 = A2 ), subset (A1 ⊂ A2 ), superset (A1 ⊃ A2 ) and related (A1 ∼ A2 ). Interactions definition The interactions between two FTEs are defined by their match set and action set relations, and their priority. Given an FTE Fx with a match set Mx and an action set Ax, and an FTE Fy with a match set My and an action set Ay, and assuming the priority of Fx is always lesser than the priority of Fy, the interactions between Fx and Fy can be: Duplication: if two FTEs have the same priority and the same match and action sets. • Redundancy: the redundant FTEs have the same effect on the flows they match but the actions sets are not equal. • Generalization: both FTEs have different action sets but Mx is T a superset of My . In this case to the flows matched by F1 F2 the actions of Ay will be applied and to the flows matched by F1 −F2 the actions of Ax will be applied. • Shadowing: Fx and Fy have different action sets and if Fx is shadowed by Fy the action set of Fx will never be applied on its matching flows. • Correlated: the FTEs have different match sets but the intersection between those two isn’t empty, so to the matched flows of this intersection the actions of Ay will be applied. It’s different from shadowing because to the flows that are only matched by Mx the actions of Ax will be applied. • Inclusion: it’s similar to shadowing, but in this case the action set Ax is a subset of Ay so the actions of Ax are also applied. • Extension: it’s similar to the generalization, but in this case the action set Ax is a superset of Ax so the actions of Ax are also applied. The rules interaction detection could aid in the automation of rules management, for example as mentioned by Bifulco and Schneider [3], detecting when a rule shadows another rule, for simplifying the existing set of rules, splitting rules to avoid redundancy, or for an advanced policy control of allowed rules inside a switch ORIGINAL ALGORITHM The interactions detection algorithm (IDA) proposed in [3] receives two FTEs Fx and Fy , assuming that Fx ’s priority is lesser than Fy ’s priority. It’s expected the data structures contain the necessary data to calculate the relations between match sets and action sets, which are the values for the FTE fields. The algorithm has a main function that identifies the interaction between two FTEs and 2 auxiliary functions to identify the relation between match sets and action sets. In Proceedings of the II Costa Rican Workshop on Computer Science and Informatics (JoCICI 2015) [3] the authors include the pseudo code of these functions When comparing an single FTE against a set of FTEs of size n, the algorithm has a complexity of θ(n) because it always compares all fields of all FTEs. ALTERNATIVE ALGORITHM The original algorithm was analyzed to identify how could its complexity be reduced, at least in the majority of scenario, and out of this, two main areas of improvement were detected: (1) the algorithm compares all fields when comparing FTEs, (2) the algorithm compares all the FTEs of the existing set of FTEs. The alternative algorithm provides an implementation for both improvements, and this was done to compensate when the overhead in one of the improvements is greater than the benefits, which is expected only in corner cases that are not likely to happen in a real scenario. Number of compared fields reduction The authors of the original algorithm note that the fields must be compare done by one when comparing 2 FTEs, but after analyzing the pseudo code and the interactions, a prematurely stop point can occur when the match sets are disjoint. This is called lazy comparison (analogous to lazy initialization), when a disjoint relation is identified between two match fields. The implementation also sorts the comparison by complexity, so the comparisons of int based fields are performed first, to avoid any unnecessary comparison of complex field, which are expected to take longer than int based fields comparisons. Reduction of number of FTEs compared This improvement is based on characteristic that if a relationship between two match fields of two FTEs is disjoint, then the interaction between the two FTEs is nonexistent. As previously mentioned, the match fields can be classified in two types, int based or complex fields. For the purposes of this work, only the required fields by the OpenFlow specification [4] are taken into account. • The int based fields are: int port, Ethernet type, IP protocol, TCP source, TDP destiny, UDP Source and UDP destiny. • The complex fields are: Ethernet source, Ethernet destiny, IPv4 source, IPv4 destiny, IPv6 source and IPv6 destiny. The improvement consists in grouping the fields of the same type of all FTEs, providing a quick lookup method for nondisjoint fields of the existing set of FTEs. The algorithm would discard any FTE not in this groupings, because those will always have an inexistent interaction. The groupings are an adaptation of the work on [8], where several specific data structures are presented to improve the lookup speed for related firewall rules. Hashes of hashes were used to store the fields based on integers, and specific data structures were created for the other Ethernet and IP addresses. Only the groupings of int based fields were implemented, but as shown in the results section, it’s enough to 54 provide an important performance improvement. For example, in the groupings of TCP source, a pointer will be stored in the hash entry 80 for all FTEs having TCP source value 80, then when comparing a new FTE whose TCP source value is 80, it will only be compared to the FTEs pointed by the hash stored in the TCP source hash with key 80. EXPERIMENTS The objective of the experiments was to find statistically meaningful results, and thus the design was made based on the principles of randomization, replication and blocking, exposed in [7] for the design and analysis of experiments. The Kruskal-Wallis method was used to analyze the result data, as this is equivalent to the non-parametric version of the analysis of variance (ANOVA) but without the constraints needed by the ANOVA as the results didn’t provide normally distributed data. Experiment design The experiment was designed as a single factor experiment [7], using the algorithm execution time as the factor and the levels of this experiment were “original” and “alternative”. All iterations were executed in random order, and it was fully repeated 20 times with each one of the FTE sets. To generate the FTE sets different configurations were made based on the original experiment in [3]: 1. Number of FTEs per set: this is the main attribute, as this represents the main indicator of the algorithm performance. The used values were: 10,000, 40,000, 70,000 and 100,000. 2. Number of non-wildcard fields: gives the amount of fields in the match set that have a defined value. The used values were: 2, 4, 6, 8 and 10. 3. Probability of repeated values: this gives the probability of the FTEs in the set to have the same values as the FTE that is being compared. For example, in a 10.000 thousand set with 0,5 of probability, the set would have approximately 5.000 FTEs with repeated values. The used values were: 0, 0.25 and 0.5. In Table 1 a summary is shown with all the values used in the FTE sets configuration. Attribute Num. FTEs Non WildCard Prob. repeated #1 10,000 2 0 #2 40,000 4 0.25 #3 70,000 6 0.5 #4 100,000 8 #5 10 Cuadro 1. FTE sets configuration Implementation and execution The algorithms were implemented in Java 1.8 and in the NetBeans 8.1 IDE, and were ran in a PC with an Intel Core i7 at 2.8 GHz with 8GB of RAM and Windows 7. The original algorithm code was based on the source code presented in [3], and the alternative algorithm was a copy of the original algorithm modified to include the proposed improvements. In total, there were 2,400 executions of the experiments which outputted the data used in the results analysis. Proceedings of the II Costa Rican Workshop on Computer Science and Informatics (JoCICI 2015) Experiment results 60 53.429 40 Alternative Duration in ms 31.483 Original 20 0 Algorithm Figura 1. Average execution time of both algorithms The complete source code is available at the following address: https://github.com/ovasquez/ida/. RESULTS The obtained results show that the reduction in the number of compared fields and the number of compared FTEs is an effective way to improve the performance of the algorithm, and the evidence indicates the improvement doesn’t fall off with the bigger FTE sets. Needless to say both algorithms found exactly the same interactions. The measured improvement was of 41%, taking into account all experiments of both algorithms, as shown in Figure 1. An analysis of the algorithm behavior with the different configurations was made, showing that there are a few cases were the original algorithm performs better, but those cases are considered corner cases and do not represent a real-world scenario. CONCLUSION This paper presented an alternative for the Interactions Detection Algorithm for OpenFlow rules, using well-known data structures to reduce the number of necessary operations and a lazy processing of the comparisons between the rules. The experiments showed the improvement depends on the composition of the rule set and he results may vary from one to another, but the overall improvement was of 41%. It was 55 determined that the modifications of the algorithm provide a more feasible scenario for having the algorithm within a single OpenFlow switch. The data structures used for the fast lookups were based on the optimizations made in [8], allowing to reduce the number of FTEs to compare. Furthermore, the lazy processing between the rules allowed to prematurely discard FTEs with no interaction. One of the possible ideas for future work could be to implement the lookup structure for all the match set fields, and not only the int based fields. A suggestion for this is to create specific data structures for the complex fields (MAC, IPv4 and IPv6), taking into account the arbitrary bitmasks and hierarchy of the values. Another idea is to research the impact of the actions in the algorithm, as it’s not certain that optimizing the processing of actions would have any tangible effect on the overall processing time. Finally, this work leaves the door open for any researcher that likes to contribute with this algorithm to any open source OpenFlow Project. REFERENCIAS 1. Al-Shaer, E., and Al-Haj, S. FlowChecker: Configuration analysis and verification of federated OpenFlow infrastructures. In Proceedings of the 3rd ACM workshop on Assurable and usable security configuration, 37–44. 2. Al-Shaer, E., and Hamed, H. Design and implementation of firewall policy advisor tools. 3. Bifulco, R., and Schneider, F. OpenFlow rules interactions: Definition and detection. 1–6. 4. Foundation, O. N. OpenFlow switch specification 1.4.0. 5. Iyer, A., Mann, V., and Samineni, N. SwitchReduce: Reducing switch state and controller involvement in OpenFlow networks. 1–9. 6. McKeown, N., Anderson, T., Balakrishnan, H., Parulkar, G., Peterson, L., Rexford, J., Shenker, S., and Turner, J. OpenFlow: enabling innovation in campus networks. 69–74. 7. Montgomery, D. Design and Analysis of Experiments. Student solutions manual. John Wiley & Sons. 8. Pozo, S., Varela-Vaca, A. J., Gasca, R. M., and Ceballos, R. Efficient algorithms and abstract data types for local inconsistency isolation in firewall ACLs. 42–53. 56 Metodología CNCA de Servicios de Computación Científica de Alto Rendimiento Alvaro de la Ossa O.1, Daniel Alvarado A.2, Renato Garita F.3, Ricardo Román B.4, Juan Carlos Saborío M.5, Andrés Segura C. 6 Colaboratorio Nacional de Computación Avanzada Centro Nacional de Alta Tecnología 1 delaossa / 2dalvarado / 4rroman / 5jcsaborio @cenat.ac.cr 3 [email protected], [email protected] RESUMEN En este artículo se describe la metodología desarrollada por el Colaboratorio Nacional de Computación Avanzada (CNCA) para el desarrollo y la prestación de servicios de computación científica de alto rendimiento. La metodología se caracteriza por (a) una segmentación de la población de usuarios basada en sus conocimientos y en la disponibilidad de soluciones parciales a su problema, (b) una definición de los requisitos que deben cumplirse para poder construir una solución adecuada al problema, y (c) un plan de educación del usuario en los fundamentos de la computación de alto rendimiento. Palabras clave del autor Computación científica, Computación de alto rendimiento, Servicios de computación avanzada, Metodología de desarrollo de servicios ANTECEDENTES En el año 2006 el Consejo Nacional de Rectores (CONARE) encomendó al Centro Nacional de Alta Tecnología (CeNAT), a través del Director de la entonces llamada Área de Tecnologías de Información y Comunicación, ahora de Computación Avanzada, la creación de un laboratorio de investigación que se enfocara en el desarrollo de aplicaciones y servicios para investigadores de las universidades, y de sus socios de proyectos en otras universidades, instituciones, organizaciones y empresas. Entre el año 2007 y el 2010, gracias a fondos otorgados por el Consejo de Rectores y financiamiento externo dotados por el Ministerio de Ciencia y Tecnología (MICIT), el Consejo para Investigaciones Científicas y Tecnológicas (CONICYT) y la Fundación CRUSA, entre otros, se desarrolló un programa de promoción de la computación avanzada. El objetivo principal era y sigue siendo, el desarrollo de capacidades propias, dentro del Sistema Universitario Estatal costarricense, de desarrollo de aplicaciones de computación científica de alto rendimiento. Se autoriza hacer copias de este trabajo o partes de él para uso académico, siempre y cuando sea sin fines de lucro. La copia debe contener esta nota y la cita completa en la primera página. La copia bajo otras circunstancias y la distribución o publicación podría requerir permisos adicionales o pago de derechos. JoCICI 2015, Marzo 5-6, San José, Costa Rica. Copyright © 2015 CITIC-PCI El proceso de formación del CNCA comenzó en 2007, pero fue creado formalmente en el año 2009 con la contratación de un grupo de investigadores y asistentes de investigación de planta, y con la adquisición y puesta en marcha de un clúster computacional de arquitectura híbrida para procesamiento paralelo usando procesadores CPU y GPU. Al clúster se le bautizó con el nombre Cadejos. A partir de ese año se dió a conocer el colaboratorio mediante visitas a laboratorios, centros e institutos de investigación y otras unidades académicas de las cuatro universidades estatales, así como realización de reuniones con investigadores en las instalaciones del CNCA, todo esto con el fin de identificar necesidades específicas de procesamiento de datos científicos. El equipo del CNCA ha desarrollado su propia metodología de trabajo en un proceso paulatino de interacción con investigadores con diversas necesidades, de realización de proyectos de investigación para diseñar y desarrollar soluciones a las necesidades de procesamiento de datos de esos investigadores, y de producción de documentación histórica de los proyectos, así como de materiales de capacitación para la inducción de investigadores en el área de la computación científica de alto desempeño. La metodología desarrollada responde a uno de los objetivos específicos definidos en el Plan Estratégico del CNCA 2011-2014 [1]. SEGMENTACIÓN DE LOS USUARIOS La población de investigadores que solicitan los servicios del CNCA es diversa en disciplinas, los niveles de conocimiento y experiencia, los objetivos que buscan cumplir con el uso de nuestros servicios, y las soluciones parciales con las que cuentan antes de solicitarlos. Esta realidad nos ha llevado a perfilar los usuarios de los servicios del CNCA como sigue: Perfil 1: Usuario experto Conoce la terminología estándar de la computación, tiene conocimientos sobre arquitectura de computadoras y desarrollo de métodos computacionales, suficientes para sostener una discusión con los investigadores del CNCA y para negociar con ellos aspectos específicos de los servicios que desea obtener del colaboratorio. Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) 57 Perfil 2: Usuario inexperto pero conocedor Conoce la terminología estándar de la computación, pero sus conocimientos sobre arquitectura de computadoras y desarrollo de métodos computacionales son insuficientes para comprender el proceso que requiere el desarrollo y puesta a su disposición de servicios del colaboratorio. Perfil 3: Usuario no conocedor No conoce ni la terminología ni los conceptos fundamentales de la computación, pero tiene una idea clara de sus necesidades de procesamiento de datos. En [2] puede observarse una propuesta de segmentación similar a la utilizada por el CNCA en este caso. En esa propuesta el “mundo de la computación” es visto como un universo de proveedores y usuarios de servicios. La segmentación fundamental de los usuarios de los servicios se basa en atributos de estos que describen sus conocimientos, experticia y requerimientos, y la identificación de servicios se produce en un proceso de negociación similar al que se lleva a cabo en la etapa 1 de nuestra metodología (ver adelante). ANÁLISIS Y DESARROLLO DE SERVICIOS El proceso de puesta en marcha de servicios de computación científica de alto rendimiento contempla cinco etapas: primer contacto con el usuario; análisis del problema y elaboración de una propuesta de solución; educación del usuario; desarrollo de la solución; y puesta en marcha de la solución. Etapa 1: Primer contacto con el usuario El proceso de atención de usuarios comienza cuando un(a) investigador(a) establece contacto con el colaboratorio indicando su deseo de contar con ayuda para resolver un problema propio de procesamiento de datos científicos. Figura 1. Toma de decisiones en la primera entrevista con el usuario Objetivo general: se registra el objetivo general del proyecto del investigador usuario Objetivos específicos: se registran los objetivos específicos del proyecto de prestación del servicio al investigador usuario Justificación: descripción de las razones para solicitar el servicio del colaboratorio Metodología: instancia específica de la metodología que se describe en este artículo, para el servicio particular Cronograma Resultados El primer paso en la metodología consiste en realizar una reunión con los interesados para conocer el problema, indagar sobre el estado de avance en su solución, y acordar con el usuario los pasos a seguir. Abajo se muestra un flujograma que describe las decisiones que deben tomarse en este primer contacto con el usuario. La información consignada en los ítemes “Estado”, “Metodología”, “Cronograma” y “Resultados” se añaden a las informaciones previas, es decir, se incluye nueva información sin borrar o modificar las entradas anteriores. De esta forma se garantiza que, de ser necesario, es posible regresar a un paso anterior para revisarlo. Una vez realizada la primera entrevista, se le solicita al investigador completar un formulario o Ficha de Proyecto, documento vivo con en el que se pretende mantener una bitácora detallada del proyecto. En la Ficha de Proyecto se consigna la información siguiente: Etapa 2: Análisis del problema Sobre el proyecto: Nombre del proyecto, Resumen, Disciplinas relacionadas, Palabras clave, Estado del servicio Investigadores principales (típicamente el usuario y otros investigadores) y colaboradores (investigadores del CNCA que se involucran en el proyecto, y colaboradores de otras unidades académicas), Instituciones colaboradoras El objetivo de la etapa de análisis es elaborar una propuesta de solución al problema del usuario. La propuesta considera los aspectos siguientes: datos, métodos, programas y la formas de prestación del servicio (p.ej., acceso del usuario al clúster, carga de datos, envío de solicitudes trabajo, respuesta, etc.). Datos Se analiza la representación de los datos, para garantizar la eficiencia en el acceso, y la disponibilidad de datos de prueba, para asegurar que los investigadores del colaboratorio puedan realizar pruebas de la solución que se va a proponer. Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) Métodos Se analiza el rendimiento de la solución disponible, si esta existe, o se especifica el rendimiento deseado en la solución que se va a proponer, con el fin de garantizar la eficiencia del servicio. Programas Se implementa un método eficiente apropiado a una de las arquitecturas de procesamiento disponibles en el clúster del colaboratorio. Se definen los procedimientos de acceso del usuario al recurso de procesamiento, la carga de los datos, el envío de solicitudes de trabajos, la descarga de los resultados, etc. Formas de prestación del servicio El producto final de la etapa de análisis es una propuesta de solución a las necesidades del investigador usuario. La etapa concluye cuando la propuesta es aprobada por el usuario. Etapa 3: Educación del usuario En los casos en que el usuario corresponde al segundo o tercer perfil (usuario no experto o no conocedor), en la propuesta de servicios se incluye la realización de uno taller de inducción a la computación de alto rendimiento para el investigador y sus colaboradores. Esta práctica ha mostrado una y otra vez sus beneficios. En algunos casos los usuarios creen tener la mejor solución de procesamiento de sus datos, pero una vez que han pasado por el taller, pueden identificar debilidades de su solución y cambiar consecuentemente sus requerimientos para que estas sean tomas en cuenta en el desarrollo del servicio. A continuación se resume el contenido del taller introductorio desarrollado por los investigadores del CNCA. Taller de Computación Científica y de Alto Rendimiento para Investigadores Introducción a la computación científica: tareas, modelos, métodos y algoritmos principales. Arquitecturas: revisión de arquitecturas de procesamiento secuencial y paralelo. Computación paralela: revisión de los principios de la computación paralela y de las técnicas básicas de implementación de métodos paralelos. Elementos de sistemas operativos: introducción a los SO y los servicios requeridos por el investigador. Linux: descripción del sistema operativo Linux y revisión de los comandos básicos de administración, para capacitar al investigador en el uso de líneas de comando para el acceso al clúster del colaboratorio. Es pertinente comentar que el uso de este sistema operativo obedece a la política expresa del colaboratorio de desarrollar, en lo posible, soluciones computacionales de código libre y acceso abierto. Esto es congruente con la necesidad de reducir costos de las actividades de investigación. 58 Métodos, algoritmos y aplicaciones: revisión de los métodos, algoritmos y aplicaciones consideradas por el investigador y otras que podrían servir para complementar el servicio del colaboratorio. Proyectos: el taller culmina con la elaboración de una práctica con el investigador y los demás participantes en la que se realizan ejemplos del procesamiento de datos requerido por el usuario. Etapa 4: Desarrollo de la solución La realización del taller de la etapa anterior puede tener como efecto una revisión, por parte del usuario, de la solución de la que dispone. En este caso se regresa a la estapa de análisis. En otro caso, se procede con el desarrollo del servicio solicitado por el investigador usuario. Dependiendo de la disponiblidad previa de una solución a las necesidades del usuario, las actividades de esta etapa son las siguientes: El diseño de un método para el procesamiento de los datos del usuario y la construcción de un programa de computador para implementar ese método. Este es el caso en que el usuario no dispone previamente de una solución, o la solución parcial a la que tiene acceso no es aceptable de acuerdo con sus propios criterios. La adaptación de un método ya existente. Este es el caso en que que el usuario ya posee un método o programa, que es el deseado, pero este debe ser adaptado a la arquitectura de procesamiento del colaboratorio, o su rendimiento es inaceptable y debe ser mejorado. Cualquiera que sea el caso, esta actividad presupone la duración más extensa del proyecto, al menos por dos razones. Primero, porque considera el proceso de diseño y programación de un método. Segundo, porque debe incluirse la validación del método y la puesta a prueba de su rendimiento y eficiencia una vez implementado. De esta tarea surgen precisamente los temas de investigación de mayor interés para el CNCA. La experiencia en esta parte de la etapa de desarrollo ha sido diversa. En algunos casos los resultados han sido mejor que los esperados. Típicamente en estos casos se procede de inmediato a la quinta y última etapa, de puesta en marcha del servicio. En otras ocasiones los resultados no han sido satisfactorios, y en estos casos ha sido necesario regresar a la segunda etapa de la metodología, para reconsiderar otros métodos posibles de procesamiento de sus datos. Etapa 5: Puesta en marcha del servicio La última etapa de la metodología es la puesta en marcha del servicio de procesamiento. Se crea una cuenta de usuario del clúster para el investigador usuario, y se le da un instructivo de los procedimientos de acceso y utilización del recurso. Con el fin de que los servicios puedan ser reutilizados por otros investigadores, el servicio es instalado globalmente en Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) el clúster. Para finalizar el proyecto, la Ficha de Proyecto es actualizada con los resultados obtenidos. Cabe mencionar que al usuario investigador se le solicita, como requisito para brindar el servicio, que este sea reconocido en cualquier publicación derivada de su investigación. ENFOQUES SIMILARES En la literatura consultada la mayoría de enfoques son muy similares al del CNCA. En todos los casos, la metodología de servicios parte de una identificación de los conocimientos y destrezas de los usuarios, y continúa con etapas similares a las del CNCA, pero en escalas de organización y gestión mayores, en un entorno de prestación de servicios de mayor capacidad y complejidad, en el que se presupone la existencia de unidades o equipos de trabajo separados para cada una de las etapas del proyecto. Ejemplos de esto son el Centro de Supercomputación de Barcelona (BSC) y al Texas Advanced Computing Center (TACC). que han implementado estrategias similares a la expuesta en [3]. En nuestro caso, las actividades en todas las etapas son asumidas por el mismo equipo de investigadores. RESULTADOS Y CONCLUSIONES La metodología desarrollada por los investigadores del CNCA ha sido desarrollada con base en la experiencia adquirida de un total de 23 proyectos de prestación de servicios de procesamiento de datos científicos. En esta muestra, los usuarios y sus disciplinas han sido muy diversos, lo que hace necesario que la metodología sea flexible y adaptable a cada caso. En los dos últimos años, los usuarios han provenido de las Ciencias (Física y Química), las Ingenierías (Eléctrica, Forestal, Química), las Ciencias de la Salud (Medicina, Microbiología), las disciplinas relacionadas con la Computación, y las Ciencias Sociales. Del total de 20 usuarios del clúster computacional del CeNAT en los dos últimos años, un 28% no tenía una solución computacional a su problema; esta debía ser desarrollada. Del 72% restante, aproximadamente la mitad tenía ya una solución completa y requería únicamente el uso del recurso del CNCA, y la otra mitad tenía una solución que debía ser mejorada. A la fecha hay 20 usuarios activos del clúster que expresan su satisfacción con el conjunto de servicios de asesoría, capacitación y procesamiento de datos. Por otro lado, la demanda de servicios ha aumentado considerablemente, y con frecuencia ha sido necesario administrar las colas de trabajos para hacer posible que todos procesen sus datos en un tiempo razonable. 59 Las áreas de investigación principales del CNCA han sido determinadas, en parte, por las necesidades de los usuarios, y en parte por lo intereses teóricos del equipo del colaboratorio. El área de investigación común a la mayoría de proyectos, y de mayor enfoque del colaboratorio en el desarrollo de servicios para investigadores, es la de técnicas para la aceleración de métodos, incluyendo técnicas de paralelización de procesos y distribución de datos. Entre los métodos analizados podemos mencionar métodos numéricos para la estimación de valores de los parámetros de un modelo, métodos estadísticos para el análisis de sensibilidad o la estimación de datos faltantes, métodos analíticos para la extracción de información característica de conjuntos de objetos de estudio, y criterios de análisis del rendimiento y escalabilidad de los métodos. Un ejemplo de esto puede verse en [4]. AGRADECIMIENTOS Agradecemos a todos y todas los investigadores que han solicitado y utilizado los servicios del Colaboratorio por la confianza depositada en nuestro equipo. Agradecemos también al Consejo de Rectores por la asignación de recursos para la adquisición y puesta en operación del clúster Cadejos del CNCA. REFERENCIAS 1. de la Ossa, A.; Alvarado, A.; Garita, R.; Román, R.; Saborío, J.C.; Segura, A. Plan estratégico del CNCA 2011-2014. Reporte técnico CNCA. 2. Kling. R. y Gerson, E.M. Patterns of segmentation and intersection in the computing world. Symbolic Interaction, Vol. 1 No. 2 (1978), 25-28. 3. Papazoglou, M.P. Service-oriented computing: a research roadmap. En: International Journal of Cooperative Information Systems, 17(02), junio de 2008 4. a orío, C iseño y desarrollo de algoritmos paralelos para recuperación en una memoria de casos distribuida. Tesis de Licenciatura en Computación e Informática, ECCI, UCR, 2012. 60 Cantidad y rango óptimos de los retrasos en un modelo computacional de la sensación de altura musical basado en la autocorrelación Sebastián Ruiz Blais Centro de Investigaciones en Tecnologías de la Información y Comunicación (CITIC) Universidad de Costa Rica [email protected] RESUMEN Los modelos computacionales permiten analizar cuantitativamente las teorías de la sensación de altura musical. El modelo que ha sido más extensamente estudiado se basa en la autocorrelación del patrón de disparo del nervio auditivo. Ese modelo mantiene consistencia con numerosos fenómenos relacionados con la sensación de altura. El presente estudio buscó determinar el número y rango óptimo de los retrasos en el modelo de autocorrelación. Mediante el uso de simulaciones, se determinaron las configuraciones óptimas para dar cuenta de la evidencia psicoacústica, utilizando el menor número posible de operaciones. I. INTRODUCCIÓN El modelado computacional de los procesos auditivos de los humanos ayuda a comprender mejor las bases de la percepción [6], lo cual puede contribuir en el diseño de los implantes cocleares y para el desarrollo de software inspirado en la biología. Actualmente, los implantes cocleares mejoran la comprensión del lenguaje de sus usuarios en condiciones de silencio, pero no funcionan muy bien bajo condiciones de ruido y para la percepción de la música [15]. Por otro lado, cada vez más, nuevos algoritmos y estrategias computacionales se inspiran en elementos biológicos, tales como la inteligencia de enjambre y las redes neuronales [7]. Algunos problemas prácticos requieren estimar la altura musical para identificar la fuente del sonido, como en el caso de especies animales [17]. La sensación de altura musical consiste en la cualidad del sonido que permite distinguir tonos o notas y ordenarlos en una escala de grave a agudo [3]. Tal sensación es producto de una cascada de procesamientos realizados en la vía auditiva [8]. El nervio auditivo representa el sonido en la Se autoriza hacer copias de este trabajo o partes de él para uso académico, siempre y cuando sea sin fines de lucro. La copia debe contener esta nota y la cita completa en la primera página. La copia bajo otras circunstancias y la distribución o publicación podría requerir permisos adicionales o pago de derechos. JoCICI 2015, Marzo 5-6, San José, Costa Rica. Copyright © 2015 CITIC-PCI Arturo Camacho Escuela de Ciencias de la Computación e Informática Universidad de Costa Rica [email protected] dimensión espacial; distintas neuronas asociadas a una región de la cóclea se activan con mayor probabilidad ante sonidos con distintas frecuencias [4]. La información también es representada en la dimensión temporal, ya que las neuronas se sincronizan con las fluctuaciones del sonido [4]. Las principales teorías de la sensación de altura la vinculan ya sea con mecanismos temporales o bien espaciales [5]. Los modelos basados en la autocorrelación, compatibles con la creencia de que el cerebro realiza en un procesamiento temporal de la altura, dan cuenta de múltiples fenómenos de esta sensación [6]. La autocorrelación es el producto de una señal por sí misma al cabo de un retraso, como función de él [6]. Los modelos más completos calculan la autocorrelación a partir de la representación neural en distintos canales cocleares y luego integran la información de estos canales para obtener la autocorrelación sumatoria (SACF) [9, 2]. Cada uno de los canales cocleares responde de manera preferente a una frecuencia presente en el estímulo auditivo, la cual se denomina frecuencia característica (FC). Como entrada a la SACF, la representación neural es generalmente obtenida a partir de un modelo de la periferia auditiva [11]. A pesar de su buen desempeño para reproducir los datos obtenidos por medios psicofísicos, los modelos basados en la autocorrelación usualmente son considerados biológicamente poco plausibles, ya que no hay evidencia de estructuras en el cerebro que realicen esta función [6, 12]. Existe una creencia general de que, para ciertas características, el cerebro tiene una configuración óptima, en respuesta a diversas presiones evolutivas [4]. El cálculo de la autocorrelación, en cambio, requiere de muchas operaciones y probablemente muchas de ellas son innecesarias. Por ejemplo, Moore propone un modelo esquemático que utiliza únicamente ciertos retrasos que dependen de la FC [14]. Basado en el principio de economía de la evolución, el presente trabajo consiste de una serie de simulaciones para determinar el modelo con la menor cantidad de retrasos que sea consistente con la evidencia psicoacústica. La sección II describe las Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) simulaciones realizadas, la sección III presenta los resultados obtenidos y la sección IV muestra las conclusiones. II. METODOLOGÍA Las simulaciones realizadas se basan en las respuestas de varias modificaciones al modelo SACF de la sensación de altura elaborado por Meddis et al. [9, 2, 12, 10]. La SACF recibe como entrada una representación de la actividad del nervio auditivo, la cual es simulada por un modelo de la periferia auditiva [11]. El objetivo de las simulaciones fue determinar el rango, número y tipo de espaciamiento óptimo de los retrasos utilizados por la función de autocorrelación. Para ello se contrastaron los resultados del modelo ante varios estímulos con evidencia empírica, buscando siempre minimizar la cantidad de operaciones. 1. Descripción del modelo 1.1. Modelo de la periferia auditiva Los estímulos son procesados por el modelo de la periferia auditiva propuesto por [11], con las modificaciones introducidas por [2]. Los componentes del modelo son: el estímulo de entrada, la respuesta del estribo, la respuesta por canales de la membrana basilar, el potencial de recepción de las células ciliadas internas (IHC, por sus siglas en inglés), la probabilidad de liberación de neurotransmisores en sinapsis entre las IHC y el Nervio Auditivo (NA) y las probabilidades de disparo en el NA, que conforman la salida del modelo. 1.2. Modelo de la sensación de altura El modelo de la sensación de altura usado consiste en una serie de modificaciones al modelo de SACF [10]. El modelo de SACF calcula la función de autocorrelación sobre la probabilidad de disparo de las neuronas en cada uno de los canales de la membrana basilar y posteriormente las suma sobre todos los canales. En cada canal se calcula el producto de la probabilidad de disparo de cada neurona por sí misma luego de un retraso. 2. Descripción de las simulaciones Las simulaciones consisten en la ejecución del modelo para distintas configuraciones de retrasos. Los resultados fueron evaluados con respecto a la cantidad de operaciones requeridas y la consistencia con la evidencia psicoacústica. Se determinó la cantidad de retrasos utilizados en cada configuración y se obtuvo la respuesta del modelo para cada estímulo que se contrastó con los datos experimentales. Los retrasos fueron definidos linealmente en el rango de 0, 1 a 3,3 ms, correspondientes a las frecuencias 10000 y 30 Hz, respectivamente. Las configuraciones variaron en cuanto al número, tipo de espaciamiento de retrasos en el rango anterior y en el rango de los retrasos relativo a la FC. El tipo de espaciamiento fue lineal en el tiempo y logarítmico en las frecuencias correspondientes a los retrasos. El rango de retrasos fue restringido en el intervalo de 0,5/ FC a 15/FC [3]. Se estableció como punto de referencia la configuración sin restricción en los retrasos y que utiliza 400 retrasos 61 espaciados linealmente. A continuación se describen los estímulos utilizados y sus correspondientes simulaciones. 2.1. Umbral de discriminación de frecuencia Un tono puro es un estímulo de forma sinusoidal. A la menor diferencia detectable en la frecuencia de un tono puro se le conoce como umbral de discriminación de frecuencia (FDL, por sus siglas en inglés) [16]. Los FDL dependen de la frecuencia, intensidad y duración de los tonos [13]. Para determinar los FDL en estas simulaciones, se calculó la respuesta del modelo para un tono puro dado y otros tonos puros en las frecuencias vecinas. Los tonos puros fueron de las frecuencias utilizadas en el experimento de Moore [13]: 250, 500, 1000, 2000, 4000, 5000, 6300 y 8000 Hz. Para cada uno de ellos, se produjeron sesenta tonos puros espaciados logarítmicamente con una variación entre 0,001 y 0,15. Posteriormente, se calculó la distancia Euclídea entre la respuesta del modelo al tono puro original y cada uno de los sesenta tonos vecinos. Para la simulación, se estableció que los tonos son discriminados a partir de cierto umbral con respecto a la distancia Euclídea. A partir de este cálculo, se determinó la variación porcentual en frecuencia que se debe alcanzar para que un tono vecino sea identificado como distinto. 2.2. Tonos complejos con cuarta armónica desafinada Un tono complejo armónico contiene componentes de frecuencia en múltiplos de una frecuencia fundamental. Darwin et al. estudiaron el efecto sobre la sensación de altura de desafinar la cuarta armónica de un tono armónico [5]. Encontraron que la altura aumenta junto con la frecuencia de la cuarta armónica, pero en menor proporción con respecto a la magnitud del desafinamiento. A partir de un desafinamiento de 3%, la cuarta armónica comienza a ser percibida como una nueva entidad auditiva y poco a poco la altura percibida vuelve a ser la misma del tono original. Para esta simulación se sintetizaron estímulos correspondientes a un tono de 155 Hz con diez armónicas, la cuarta de ellas desafinada en los siguientes porcentajes: 0; 1,6; 3,2; 4,8; 6,4; 8,0 y11,3. Además, como referencia se sintetizaron tonos compuestos, en el rango 140-170 Hz, también de diez armónicas. La distancia Euclídea fue calculada entre los estímulos con desafinamiento y los tonos de referencia para encontrar la altura correspondiente al tono desafinado. 2.3. Tonos complejos con fase alternada Algunos estímulos son filtrados en una región espectral de modo que sus armónicas no son distinguibles en el patrón de excitación de la cóclea [16]. Estos estímulos con armónicas no resueltas son útiles en el campo de la investigación psicoacústica porque permiten eliminar información espacial y analizar así únicamente los mecanismos temporales. En un estudio, Shackleton y Carlyon utilizaron dos tipos de tonos armónicos: unos con Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) fase seno y otros con fase alternada [18]. En los tonos armónicos con fase seno, los senos que conforman el tono son sumados todos con la misma fase. En los tonos armónicos con fase alternada, los componentes individuales son sumados de manera alterna en fase seno y coseno. En estímulos con armónicas no resueltas, los tonos armónicos con fase alternada son percibidos con una altura que es el doble de los mismos tonos en fase seno, lo cual no ocurre con armónicas resueltas [18]. Siguiendo la evaluación realizada por Meddis y O’Mard [12], se sintetizaron tonos armónicos de 125 Hz con fase alternada en una región espectral baja (125-625 Hz) y una región espectral alta (3900-5400 Hz). En la región espectral baja las armónicas son resueltas, pero no en la región espectral alta. Se sintetizaron tonos armónicos de referencia en cada una de estas regiones, con fase seno, para frecuencias entre 60 y 260 Hz. De manera análoga a las simulaciones anteriores, las alturas fueron determinadas calculando la distancia Euclídea entre los tonos con fase alternada y los tonos de referencia. III. RESULTADOS FDL Para la configuración con 400 retrasos espaciados linealmente y sin restricciones en el rango de retrasos, los FDL son consistentes con los datos de Moore para las bajas frecuencias (500-5000 Hz). Para frecuencias mayores a 5000 Hz, hay un aumento significativo en los FDL, lo cual concuerda con la debilitación de la sincronización del nervio auditivo en altas frecuencias [14, 16]. Moore ha planteado que los FDL pueden ser explicados por la existencia de un mecanismo temporal para las bajas frecuencias y otro espacial para las frecuencias altas [1, 13]. Los resultados obtenidos bajo esta configuración son consistentes con esta idea. Otras configuraciones fueron evaluadas y se determinó que algunas de ellas también eran consistentes con la evidencia al variar el umbral escogido. Por ejemplo, el rango de 0.5/FC a 15/FC con 100 retrasos espaciados logarítmicamente mostró resultados consistentes con la evidencia empírica. Figura 1. FDL de configuraciones en contraste con datos empíricos de Moore [13]. Las predicciones del modelo son consistentes con la evidencia. 62 La figura 1 permite contrastar las predicciones del modelo y los datos empíricos. Como resultado importante se determinó que la utilización de un espaciamiento logarítmico entre los retrasos permite dar cuenta de los FDL con el uso de un menor número de retrasos. Además, en términos generales, utilizar un rango de retrasos más amplio implica menores FDL. Cuarta armónica desafinada La configuración que incluye todos los retrasos produce una tendencia similar a los datos experimentales de Darwin et al. ya que con la desafinación produce un cambio de altura. Sin embargo, se puede apreciar que la altura percibida rápidamente vuelve a la altura sin desafinar, siguiendo una tendencia distinta a los datos de Darwin et al. Varias configuraciones estuvieron más cercanas a los datos experimentales, especialmente la configuración con rango 0.5/FC a 10/FC y 100 retrasos linealmente espaciados. La figura 2 muestra los datos de Darwin et al., las predicciones del modelo de Meddis y O'Mard [10] y las predicciones de dos configuraciones de la presente simulación. La configuración óptima mantiene a grandes rasgos las mismas tendencias que los datos experimentales, a diferencia de la configuración con todos los retrasos o las predicciones de Meddis y O’Mard [10]. Tonos complejos con fase alternada La configuración que usa todos los retrasos reproduce sin problemas el cambio de altura para estímulos en fase alternada con armónicas no resueltas. Igualmente, el modelo no predice ningún cambio de altura para el caso del estímulo con armónicas resueltas. Otras configuraciones también dieron cuenta de este fenómeno, utilizando un número de retrasos considerablemente menor. Por ejemplo, fue satisfactoria la condición con 50 retrasos en la región 0.5/FC a 15/FC. En los resultados producidos por la SACF para la configuración anterior se puede percibir un pico alrededor de 0,004 s, correspondiente a 250 Hz, lo que reproduce el fenómeno perceptual. Figura 2. Predicciones de altura para estímulos con cuarta armónica desafinada. Se muestran los datos de Darwin et al. [5], las predicciones de Meddis y O’Mard [10] y las predicciones del modelo para varias configuraciones. Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) Resultados generales El número de retrasos total para cada una de las configuraciones se muestra en la tabla 1. El número de retrasos implicado por cada configuración fue calculado para cada uno de los canales cocleares y fue multiplicado por el número de neuronas en ese canal, que es 200. La tabla muestra una predicción de la cantidad de retrasos utilizados por el sistema auditivo en el conjunto de neuronas. Las configuraciones con un rango restringido de retrasos o con menor número de retrasos son más económicas en términos de operaciones. Si bien no hay evidencia en favor de ninguna de estas configuraciones específicas, es más probable que el cerebro haya adoptado una configuración económica en cuanto a cantidad de operaciones involucradas. Rango retrasos de N.° de retrasos Distribución N.° total de retrasos Sin límite 400 Lineal 4 800 000 0.5/FC a 15/FC 100 Logarítmica 635 000 0.5/FC a 10/FC 100 Lineal 598 600 0.5/FC a 15/FC 50 Lineal 297 200 Tabla 1. Número total de retrasos para cada configuración. IV. CONCLUSIONES Y TRABAJO FUTURO De los resultados se concluye que configuraciones menos costosas que aquellas que usan todos los retrasos son capaces de reproducir los datos de estudios empíricos. Estas configuraciones deben ser preferidas por sobre las más complejas, ya que son más plausibles con respecto al argumento de economía del sistema nervioso. Los resultados actuales no son suficientes para determinar las configuraciones ideales del modelo debido a que se deben considerar otros fenómenos de altura. Sin embargo, el presente estudio sugiere que el uso del rango 0.5/FC a 15/FC para los retrasos es al menos consistente con la evidencia. Trabajo futuro explorará el rendimiento de las distintas configuraciones en otros estímulos. REFERENCIAS 1. ASA. Acoustical Terminology SI, 1-1960. New York: American Standards Association, 1960. 63 4. Bullmore, E., & Sporns, O. Complex brain networks: graph theoretical analysis of structural and functional systems. Nature Reviews Neuroscience, 10(3), 186-198 5. Darwin, C. J., Ciocca, V., & Sandell, G. J. Effects of frequency and amplitude modulation on the pitch of a complex tone with a mistuned harmonic. J. Acoust. Soc. Am., 95(5), 2631-2636. 6. De Cheveigné, A. Pitch perception models, in Plack, C. Oxenham, A., Fay, R. & Popper, A. eds. Pitch, Springer New York, 2005, 169-233. 7. Engelbrecht, A. P. Computational intelligence: an introduction. John Wiley & Sons, 2007. 8. Kandel, E. R., Schwartz, J. H., & Jessell, T. M. (Eds.). Principles of neural science (Vol. 4). New York: McGraw-Hill, 2000. 9. Meddis, R., & Hewitt, M. J. Virtual pitch and phase sensitivity of a computer model of the auditory periphery. I: Pitch identification. J. Acoust. Soc. Am., 89(6), 2866-2882. 10. Meddis, R., & O’Mard, L. A unitary model of pitch perception. J. Acoust. Soc. Am., 102(3), 1811-1820. 11. Meddis, R. Auditory-nerve first-spike latency and auditory absolute threshold: a computer model. J. Acoust. Soc. Am., 119(1), 406-417. 12. Meddis, R., & O’Mard, L. P. Virtual pitch in a computational physiological model. J. Acoust. Soc. Am., 120(6), 3861-3869. 13. Moore, B. C. J. Frequency difference limens for short‐duration tones. J. Acoust. Soc. Am., 54(3), 610619. 14. Moore, B. C. An introduction to the psychology of hearing. Academic, London, 1982 15. Oxenham, A. J. Pitch perception and auditory stream segregation: implications for hearing loss and cochlear implants. Trends in amplification,12(4), 316-331. 16. Plack, C. J., & Oxenham, A. J. The psychophysics of pitch, in Plack, C. Oxenham, A., Fay, R. & Popper, A. eds. Pitch, Springer New York, 2005, 7-55. 2. Balaguer-Ballester, E., Denham, S. y Meddis, R. A cascade autocorrelation model of pitch perception. J. Acoust. Soc. Am., 124 (4). 2186-2195. 17. Ruiz-Blais, S., Camacho, A., & Rivera-Chavarria, M. R. Sound-based automatic neotropical sciaenid fishes identification: Cynoscion jamaicensis. In Proceedings of Meetings on Acoustics (Vol. 21, No. 1, p. 010001). 3. Bernstein, J. y Oxenham, A. An autocorrelation model with place dependence to account for the effect of harmonic number on fundamental frequency discrimination. J. Acoust. Soc. Am., 117 (6). 3816-3831. 18. Shackleton, T. M., & Carlyon, R. P. The role of resolved and unresolved harmonics in pitch perception and frequency modulation discrimination. J. Acoust. Soc. Am., 95(6), 3529-35 64 Cancelación del Ruido de Ambiente en Grabaciones de Vocalizaciones de Manatı́es Antillanos Jorge Castro Centro de Investigaciones en Tecnologı́as de la Información y Comunicación Universidad de Costa Rica [email protected] (506) 8862-3108 Arturo Camacho Escuela de Ciencias de la Computación e Informática Universidad de Costa Rica [email protected] ABSTRACT El manatı́ antillano es una especie que se encuentra amenazada a lo largo de su ámbito de distribución. Para promover su conservación, es importante localizar y contar individuos. La estimación de población a través de sus vocalizaciones es una opción confiable, de bajo costo, no invasiva y novedosa en la región centroamericana. Sin embargo, para desarrollar un método de conteo automático, conviene primero cancelar el ruido de ambiente en las grabaciones. En este trabajo se propone un algoritmo para cancelar el ruido ambiental en grabaciones de campo de vocalizaciones de manatı́es, basado en la transformada wavelet, la función de autocorrelación y técnicas de agrupamiento. El algoritmo propuesto logra una mejora promedio de la razón de señal a ruido de 28 dB para grabaciones de emisiones vocales de manatı́es antillanos contaminadas con ruido ambiental de alta intensidad. Palabras clave Manatı́; cancelación; ruido; vocalizaciones; wavelets; INTRODUCCIÓN El manatı́ antillano (Trichechus manatus manatus) constituye una parte representativa de la biodiversidad de los ecosistemas en los humedales centroamericanos. Desafortunadamente, pertenece a la lista de especies amenazadas de la IUCN desde hace varias décadas [2]. El problema tratado en este artı́culo es el de la cancelación de ruido en grabaciones de campo de vocalizaciones de manatı́es. La eliminación del ruido de ambiente es necesaria para la detección automática de sus emisiones vocales y el conteo automático de individuos con base en estas. El conteo de individuos permite realizar estimaciones de población que contribuyen con la gestión y protección del manatı́. En investigaciones recientes se han propuesto diversos métodos para la cancelación de ruido de ambiente en vocalizaciones de manatı́es. Se ha investigado el uso de filtros adaptativos lineales [9, 10], métodos no lineales basados en la transformada wavelet [4, 7, 6] y técnicas de separación de fuentes que Se autoriza hacer copias de este trabajo o partes de para uso académico, siempre y cuando sea sin fines de lucro. La copia debe contener esta nota y la cita completa en la primera página. La copia bajo otras circunstancias y la distribución o publicación podrı́a requerir permisos adicionales o pago de derechos. JOCICI’15, Marzo 5-6, San José, Costa Rica. c Copyright 2015 CITIC-PCI Mario Rivera Centro de Investigaciones en Tecnologı́as de la Información y Comunicación Universidad de Costa Rica [email protected] utilizan múltiples receptores [5]. Los resultados de los métodos basados en la transformada wavelet han sido superiores a los obtenidos mediante filtros adaptativos lineales. El algoritmo de cancelación de ruido propuesto está basado en la transformada wavelet no decimada (UDWT, por sus siglas en inglés) y la función de autocorrelación [4]. En adición, utiliza un algoritmo de agrupamiento para seleccionar el umbral a aplicar en el dominio wavelet [1]. CARACTERIZACIÓN DEL RUIDO Y DE LAS VOCALIZACIONES El ruido presente en las aguas poco profundas en que habita el manatı́ no es estacionario y se compone de diversas fuentes, entre ellas, el producido por el camarón de la familia alpheidae, el movimiento del agua, los motores de los botes y las emisiones de otras especies [9]. La cantidad de camarones aumenta conforme a la cercanı́a al mar y por lo tanto, también el ruido producido por estos [8]. El ruido producido por este camarón se caracteriza por ser de banda ancha (llega hasta 100 kHz), tener una duración menor a 10 ms y alcanzar niveles superiores a los 90 dB (re 1 µPa) [9]. Otros factores que contribuyen al ruido son el movimiento del agua, los motores de los botes y las emisiones de otras especies. Las vocalizaciones del manatı́ usualmente evocan una fuerte sensación de altura musical (son vocalizaciones armónicas). Estas emisiones vocales tienen una frecuencia fundamental entre 2 y 5.5 kHz, una duración entre 200 y 500 ms y un contenido armónico extenso, que suele alcanzar frecuencias ultrasónicas. A diferencia del ruido de ambiente, las vocalizaciones armónicas presentan poca energı́a por debajo de los 2 kHz y tienen una función de autocorrelación que decae lentamente [4]. Ambas caracterı́sticas son explotadas por el algoritmo de cancelación de ruido propuesto. ALGORITMO DE CANCELACIÓN DE RUIDO Las estrategias de cancelación de ruido con wavelets parten de la elección de una wavelet base apropiada, de manera que la energı́a de la señal objetivo queda concentrada en un número pequeño de coeficientes de gran amplitud, y que el ruido de ambiente queda distribuido en una gran cantidad de coeficientes de pequeña amplitud. De esta forma, la aplicación de la transformada wavelet para el realce de una señal, es un proceso de tres etapas: descomposición en wavelets, umbralización de los coeficientes wavelet y reconstrucción de la señal. Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) La señal acústica del ruido submarino se suele modelar como ruido aditivo de la siguiente forma: s(t) = x(t) + r(t) (1) donde x(t) es la señal de la vocalización del manatı́, r(t) es la señal del ruido y s(t) es la señal de la vocalización contaminada con ruido. El algoritmo de cancelación de ruido propuesto se muestra en la figura 1. Primero, se le aplica a la señal contaminada s(t) un filtro paso alto con frecuencia de corte fc = 2 kHz para eliminar el ruido de ambiente que se sale del rango de frecuencias de las vocalizaciones de manatı́. Luego, se divide la señal en I ventanas de 3 ms cada una y se aplica la UDWT con la wavelet base Daubechies 8 y una descomposición en J = 4 niveles. Este tamaño de ventana es suficientemente pequeño como para considerar el fragmento de la señal como estacionario en sentido amplio (WSS, por sus siglas en inglés), lo que aumenta la velocidad de cómputo. Además, es suficientemente grande como para cubrir al menos seis perı́odos de la frecuencia más baja de interés (2 kHz). Se seleccionó la UDWT por su simplicidad con respecto a otras transformadas wavelet y porque elimina el problema de variación ante la traslación que posee la transformada discreta de wavelet. Además, la familia Daubechies ha sido empleada exitosamente en la cancelación del ruido de vocalizaciones de manatı́es [4, 6]. La descomposición en cuatro niveles, parte la señal en bandas relevantes según la distribución en frecuencia de las emisiones vocales del manatı́. De esta forma, para cada ventana i se tiene una señal wi ( j, k) de coeficientes wavelet de nivel j y traslación k. Luego, se aplica la función de autocorrelación a los coeficientes wavelets obtenidos en cada nivel y se calcula la raı́z cuadrada de la media de los cuadrados (valor RMS) de la función de autocorrelación. Cabe resaltar que en el dominio wavelet, la función de autocorrelación de las vocalizaciones de manatı́ y del ruido de ambiente, conservan sus diferencias [4]. La función de autocorrelación para señales WSS se calcula mediante la fórmula rss (τ) = 1 N ∑ (s(k) − s̄)(s(k − τ) − s̄) N k=τ (2) donde τ es el desfase, N el tamaño de la señal y s̄ su valor medio. Para discernir entre una función de autocorrelación con decaimiento lento (como la de una vocalización de manatı́) y otra con decaimiento rápido (como la del ruido), se calcula el valor RMS sobre la función de autocorrelación, desde el desfase τ = 20 hasta el desfase τ = 120. Posteriormente, se concatenan en una matriz RJxI los valores RMS obtenidos para las I ventanas procesadas y a cada fila de la matriz se le aplica una media móvil de 22 puntos para eliminar los transientes producidos por el camarón alpheidae, que pueden alcanzar valores RMS altos por instantes cortos de tiempo. A la matriz resultante se le denomina GJxI . Para determinar la posible presencia de una vocalización de manatı́, se inspecciona la matriz GJxI . A diferencia del método seguido por Gur y Niezrecki [4], en el cual se determina un umbral fijo para la evaluación, en nuestro caso se utiliza un 65 algoritmo de agrupamiento [1] que se adapta mejor a los cambios de nivel de las vocalizaciones y el ruido. Este algoritmo toma una señal unidimensional y le asigna a cada uno de sus puntos una de dos posibles clases, de acuerdo a un criterio de maximización de separación de los centroides de las clases, evaluado en ventanas de múltiples tamaños. Estas clases se representan mediante los valores de cero y uno, e indican la ausencia o posible presencia de un manatı́, respectivamente. Luego de aplicar el algoritmo de agrupamiento, se realiza una verificación de la longitud de los segmentos de ceros y unos resultantes, para que no sean inferiores a la longitud mı́nima esperada de un canto. El resultado final se almacena en una matriz HJxI , que se usa para seleccionar el umbral a aplicar a los coeficientes wavelet para cancelar el ruido de ambiente, como se explica a continuación. Los coeficientes wi ( j, k) obtenidos anteriormente para cada ventana son encogidos según un umbral adaptativo y una regla de umbralización suave. Este umbral varı́a para cada ventana i y nivel j de los coeficientes dependiendo del valor en H( j, i). El umbral se define de la siguiente forma [4]: ηi, j = máxk {wi ( j, k)} σ (2 log(N))1/2 si H( j, i) = 0 si H( j, i) = 1 (3) donde N es el número de coeficientes, σ es el nivel del ruido estimado a través de la desviación absoluta de la mediana (MAD) de los coeficientes de alta frecuencia del primer nivel [4], y σ (2 log(N))1/2 es el umbral universal propuesto por Donoho y Johnstone [3]. De esta forma, si H( j, i) = 0, el umbral es fijado al valor máximo de los coeficientes evaluados, y si H( j, i) = 1, se usa el umbral universal. La regla de umbralización suave reduce a cero todos los coeficientes con valor absoluto menor o igual al umbral, y el resto de coeficientes son encogidos hacia cero por una cantidad equivalente al umbral. Este último paso evita discontinuidades en la señal (producto de la umbralización dura). Finalmente, se aplica la transformada no decimada wavelet inversa (IUDWT) y se obtiene la señal con el ruido cancelado x̂(t). SIMULACIÓN Para evaluar el método propuesto se usaron grabaciones de campo de vocalizaciones de manatı́es antillanos tomadas en el rı́o San San, Panamá. De la colección con que se contaba, se seleccionaron las vocalizaciones con menor ruido ambiental (21 de ellas) y se concatenaron en un solo archivo, dejando al menos un segundo entre cada vocalización. Para contaminar la grabación , se seleccionó una muestra de ruido de alta intensidad (proveniente del mismo ambiente) y se sumó a la grabación original. Este ruido está compuesto principalmente por el movimiento del agua y el producido por camarones alpheidae. Las grabaciones del ruido de ambiente y de vocalizaciones de manatı́es fueron muestreadas a 96 kHz. Dado que el objetivo final del algoritmo de cancelación de ruido propuesto es facilitar el reconocimiento de vocalizaciones y la identificación de individuos, es conveniente realzar las vocalizaciones y preservar su forma de onda original. Para cuantificar el realce alcanzado, se usa la razón de señal a Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) 66 Figura 1. Diagrama de bloques del algoritmo de cancelación de ruido ruido (SNR, por sus siglas en inglés), y para medir la preservación de la forma de onda, se usa la razón de señal a distorsión (SDR, por sus siglas en inglés) [5]. La SNR se obtiene mediante la fórmula ∑21 i=1 Pi SNR = 10 log10 21 ∑i=1 Qi (4) donde Pi es el valor RMS de la iésima vocalización alterada y Qi es el valor RMS de la sección de ruido, de igual longitud, precedente a la iésima vocalización. La mejora en SNR se calcula como la diferencia entre la SNR de las vocalizaciones con el ruido cancelado x̂(t) y las vocalizaciones contaminadas s(t). Para cálcular la SNR de las vocalizaciones contaminadas, se usan las vocalizaciones originales x(t), para despreciar el ruido concurrente sumado a cada vocalización. La SDR se define como la razón entre la potencia del valor RMS de la vocalización original y la potencia del valor RMS de la señal de error: SDR = 10 log10 2 ∑21 i=1 Di , 21 ∑i=1 Ei2 (5) donde Di es el valor RMS de la iésima vocalización original y Ei es el valor RMS del error presente en la iésima vocalización alterada: v u u 1 Ni Ei = t ∑ |x̂i ( j) − xi ( j)|2 , (6) Ni j=1 Cuadro 1. Resultados del algoritmo propuesto, respecto a la SNR y la SDR, para grabaciones contaminadas con ruido de ambiente de alta intensidad. Métrica SNR SDR s(t) x̂(t) Mejora 1.14 −1.61 28.07 −0.35 26.93 1.27 donde Ni corresponde a la duración de la vocalización iésima. La mejora en SDR se calcula como la diferencia entre la SDR de x̂(t) y s(t). La SDR se escogió por encima del comúnmente utilizado error cuadrático medio normalizado (NMSE) porque brinda resultados en dB, que son comparables con la SNR. Dado que para calcular la SDR es necesario conocer la señal de vocalizaciones sin ruido, no se usaron grabaciones de vocalizaciones originalmente contaminadas con ruido de ambiente. RESULTADOS Los resultados obtenidos para la SNR y SDR al aplicar el algoritmo propuesto se muestran en el cuadro 1. La mejora promedio en SNR es de 26.93 dB y en SDR es de 1.27 dB. En la figura 2 se muestra la forma de onda de la señal de vocalizaciones original, contaminada con ruido y luego de aplicar el algoritmo de cancelación de ruido. El panel c) evidencia el buen desempeño obtenido, en cuanto a SNR, respecto a la señal del panel b). Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) 67 Figura 2. Forma de onda de a) las vocalizaciones originales, b) las vocalizaciones contaminadas con ruido ambiental y c) las vocalizaciones luego de aplicar el algoritmo de cancelación de ruido CONCLUSIONES Y TRABAJO A FUTURO La notable mejora de la SNR indica que el algoritmo de cancelación de ruido propuesto logra realzar las vocalizaciones, ante ruido de ambiente de alta intensidad. Sin embargo, el valor negativo del SDR informa que la distorsión respecto a la forma de onda original es considerable. Esto revela que parte de la mejora reportada en SNR está asociada a ruido residual presente en las vocalizaciones. Para mejorar la SDR se propone el uso de la transformada wavelet packet, la cual permitirı́a obtener una mejor resolución en frecuencia y aislar más efectivamente los armónicos de las emisiones vocales respecto al ruido de ambiente. Por otra parte, el algoritmo de cancelación de ruido funciona como un primer peldaño en el desarrollo de un método para el reconocimiento automático de vocalizaciones y el conteo automático de manatı́es. Se pretende usar el método desarrollado en el instituto Smithsonian para la gestión de población de manatı́es en Bocas del Toro, Panamá. REFERENCIAS 1. Camacho, A. Detection of pitched/unpitched sound using pitch strength clustering. In Proceedings of the Ninth International Conference on Music Information Proceedings of the Ninth International Conference on Music Information Retrieval (2008), 533–537. 2. Deutsch, C., Self-Sullivan, C., and Mignucci-Giannoni, A. Trichechus manatus. Tech. rep., IUCN Red List of Threatened Species, 2008. 3. Donoho, D. L., and Johnstone, J. M. Ideal spatial adaptation by wavelet shrinkage. Biometrika 81, 3 (1994), 425–455. 4. Gur, B. M., and Niezrecki, C. Autocorrelation based denoising of manatee vocalizations using the undecimated discrete wavelet transform. Acoustical Society of America 122 (2007), 188–199. 5. Gur, B. M., and Niezrecki, C. A source separation approach to enhancing marine mammal vocalizations. The Journal of the Acoustical Society of America 126, 6 (2009), 3062–3070. 6. Gur, B. M., and Niezrecki, C. A wavelet packet adaptive filtering algorithm for enhancing manatee vocalizations. Journal of the Acoustical Society of America 129(4) (2011), 2059–2067. 7. Ren, Y., Johnson, M. T., and Tao, J. Perceptually motivated wavelet packet transform for bioacoustic signal enhancement. Acoustical Society of America 124 (2008), 316–327. 8. Rivera, M., and Guzman, H. Consideraciones etológicas para el manejo del manatı́ antillano (trichechus manatus) en los humedales costeros del caribe norte de panamá y caribe sur de costa rica. preprint. 9. Yan, Z., Niezrecki, C., and Beusse, D. O. Background noise cancellation for improved acoustic detection of manatee vocalizations. Acoustical Society of America 117, 6 (2005), 3566–3573. 10. Yan, Z., Niezrecki, C., Cataffesta, Louis N., l., and Beusse, D. O. Background noise cancellation for manatee vocalizations using an adaptive line enhacer. Journal of Acoustical Society of America 120 (2006), 145–152. 68 Detección de voces y otros ruidos en ambientes de trabajo y estudio Juan Fonseca Solı́s [email protected] ABSTRACT Los entornos abiertos de oficina, a pesar de ser populares en la industria, son lugares difı́ciles para trabajar y estudiar. Una de las principales razones es que carecen de barreras acústicas que aislen los ruidos distractorios del ambiente. Para atacar este problema se han usado con éxito sistemas de enmascaramiento por ruido de multitudes, que logran atenuar los sonidos distractorios añadiendo más ruido al ambiente. Sin embargo ha surgido un problema adicional: escuchar continuamente un perfil de enmascaramiento puede ser dañino para el oı́do e innecesario en los perı́odos intermitentes de silencio. En éste artı́culo proponemos un método para saber cuándo es necesario activar el control, para ello empleamos tres descriptores de audio que nos indican la presencia de voz humana en el entorno, uno de los ruidos distractorios más dañinos. Los resultados preliminares muestran que los descriptores elegidos son capaces de detectar el 85% de las conversaciones molestas en las grabaciones recopiladas para el estudio. En este trabajo se propone una forma de mejorar el uso del ruido de multitudes, haciendo que el enmascaramiento sea activado solo cuando es necesario, es decir tomando en cuenta de forma continua, la presencia y ausencia de ruidos similares a la voz en el entorno. Para ello se propone calcular tres descriptores de audio denominados: tasa de cruces por cero (TCC), eventos acústicos por segundo (EAPS) y energı́a por segundo de la señal. Estos descriptores son ampliamente usados en la detección automática de voz (VAD) en el entrenamiento de maquinas de vectores de soporte [3] y modelos probabilı́sticos [15]. Nos proponemos evaluar la eficacia del método propuesto para identificar voces y otros ruidos molestos mediante un clasificador del vecino más próximo (o kNN) que nos permita reconocer las categorı́as de sonidos dentro de un margen aceptable [11]. Satisfacción acústica; Salud ocupacional; En las secciones siguientes se detalla el cálculo de cada descriptor, se revisan las categorı́as de ruidos, se explica el método propuesto y finalmente se analiza la efectividad alcanzada según los resultados obtenidos de los experimentos. ACM Classification Keywords METODOLOGÍA Signal analysis, synthesis, and processing, Algorithms: Modeling Tasa de cruces por cero Palabras clave INTRODUCCIÓN Una herramienta comúnmente usada para combatir las molestas conversaciones humanas, es el ruido de multitudes, también conocido como café-restaurante o fiesta de cocteles [7]. Este método consiste en aplicar un perfil de enmascaramiento usando voces humanas, pero de manera desincronizada, tal y como lo hace el ruido blanco para enmascarar todas las frecuencias con la misma probabilidad. Tales herramientas ya se puede encontrar en varios sitios web, y es previsible que se popularice en ambientes de estudio y oficina en el futuro. Por esto, es importante idear métodos para mejorar su uso y proteger el oı́do del usuario. Y es que según varias investigaciones se sabe que las personas que usan audı́fonos en sus ambientes de trabajo pueden alcanzar fácilmente a escuchar sonidos de hasta 100 decibelios (dB), donde el tiempo máximo permitido para exponerse es de 15 minutos para evitar un daño en la audición [10]. Se autoriza hacer copias de este trabajo o partes de para uso académico, siempre y cuando sea sin fines de lucro. La copia debe contener esta nota y la cita completa en la primera página. La copia bajo otras circunstancias y la distribución o publicación podrı́a requerir permisos adicionales o pago de derechos. JOCICI’15, Marzo 5-6, San José, Costa Rica. c Copyright 2015 CITIC-PCI La tasa de cruces por cero -tambien conocida como zero crossing rate- es una cantidad que se usa para determinar la cantidad de energı́a que aportan las frecuencias altas a la señal. Los sonidos con estas frecuencias tienen la particularidad de realizar muchos cruces con el eje horizontal del tiempo, pues su perı́odo es más corto que el resto de sonidos [3]. La presencia de frecuencias altas es un indicador del grado de periodicidad de la señal de audio, porque los sonidos con mayor TCC son aquellos sin modulación de la energı́a producida, por ejemplo el ruido blanco. En cambio, los sonidos con pocos cruces por cero suelen asociarse a señales periódicas con una altura musical semejante a la voz humana o las notas de instrumentos musicales [8]. Los algoritmos de estimación de altura son métodos alternativos a la TCC. Entre los más exitosos están SWIPEP [2] y autocorrelación. Sin embargo tienen una alta complejidad computacional y no son aptos para el análisis en tiempo real. La ecuación 1 se usa para calcular la TCC de una señal s representada discretamente en un vector de N entradas [4]. TCC = 1 N−1 ∑ f (s(n)s(n − 1)) N − 1 n=1 (1) Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) Donde la función f es 1 si el argumento es negativo, 0 en caso contrario Eventos acústicos por segundo Un evento acústico es un cambio brusco en la cantidad de energı́a de la señal de audio. Este tipo de evento llama nuestra atención, porque interrumpe la noción de suavidad [14]. Ejemplos de eventos acústicos en la oficina son: golpes y chillidos de muebles o puertas, voces, pitidos de carros, digitación en los teclados, pisadas de zapatos, pitidos y tocidos. 69 Energı́a de la señal por segundo La cantidad de energı́a por segundo ET presente en una señal s, con duración T segundos, está definida por la ecuación 2. La ecuación se derivada del teorema de conservación de energı́a de Parseval, en donde sustituimos el cuadrado de la señal por el valor absoluto [13]. 2 ET = 1 T N ∑ |s(n)| (2) n=1 Los eventos acústicos pueden hallarse al buscar los “comienzos”, es decir, los incrementos de energı́a (pendiente positiva de energı́a), en contrapartida de los “finales” que son el fin de un evento acústico, o sea, cuando hay un decremento de energı́a (pendiente negativa de energı́a) [12]. Con base en observaciones del espectrograma de la voz humana y otros sonidos intermitentes se sabe que la voz humana tiene más energı́a por segundo que el resto de ruidos y su flujo de energı́a es más uniforme. Nos interesa usar los comienzos porque marcan el inicio de los eventos y porque pueden ser detectados usando el método onset detection function (ODF), que consiste en tomar la derivada de la energı́a de los marcos de una señal. Para calcular el ODF se requiere seguir una serie de pasos [1]: Categorización de los ruidos 1. Calcular el espectrograma de una señal de duración D (segundos) y frecuencia de muestreo f s (Hz) usando una ventana de tamaño M muestras para obtener I marcos con sus respectivos espectros (esto es conocido como la transformada de Fourier de corto plazo), donde M = d4 ∗ f s/ fmin e y I = d(D ∗ f s)/M)e.1 2. Para cada marco del espectrograma, sumar el cuadrado de la energı́a de la magnitud del espectro S empleando la fórmula: k2 Ei = ∑ |Si (k)|2 Los ruidos de oficina pueden clasificarse en tipos: constantes y variables. Estos últimos, a su vez, pueden dividirse en dos subcategorı́as: aislados e intermitentes. Uno de los criterios para diferenciar los tipos de ruido es la cantidad de eventos acústicos por segundo [9]. En los ruidos constantes, o zumbidos, ocurren una gran cantidad de eventos acústicos. Ejemplos de estos ruidos son los producidos por el aire acondicionado, ventiladores, silbidos de equipos eléctricos y lluvia [9]. En los ruidos variables, en cambio, ocurren una cantidad menor de eventos acústicos. La subcategorı́a de ruidos variables aislados -conocidos también como golpes aislados- consta de sonidos aperiódicos con manifestación breve, como por ejemplo: golpes de muebles y el cierre de una puerta [9]. k=k1 Donde k1 y k2 son los ı́ndices más cercanos a la frecuencia inferior y superior que se desea analizar, respectivamente 3. Calcular la resta de la energı́a de los marcos adyacentes evaluada por un rectificador de media onda r(x) para igualar a cero los finales detectados: ODF j = r(E j+1 − E j ), r(∆E) = j = 1, 2, ..., I − 1 ∆E, 0 < ∆E 0, sino 4. Aplicar un filtro pasabajas (para dejar solo los picos más caracterı́sticos) y luego contar la cantidad de comienzos cuya energı́a que esté por encima de un umbral deseado de intensidad sonora Definimos los eventos acústicos por segundo o EAPS como la cantidad de comienzos dividida entre la duración de la señal de audio. 1 Se utiliza un largo de ventana de 4 veces el perı́odo de la frecuencia mı́nima fmin , para evitar el traslape de los lóbulos principales de una ventana Hamming Por su parte los ruidos variables intermitentes son aquellos con una cantidad intermedia de eventos que se repiten a un intervalo casi constante, por ejemplo: digitación en un teclado, clics de un ratón, pitidos de carros, música y voz [9]. La voz es un ruido intermitente porque al hablar se pronuncia una secuencia de sı́labas, y las sı́labas son unidades que se componen de un inicio breve y aperiódico de energı́a fuerte: los comienzos. Las sı́labas también tienen un segmento más largo y periódico que contiene la vocalización (detectada por la TCC). La voz, y en general, esta última categorı́a de ruidos variables intermitentes, es la que mayor distracción produce [5]. Para este estudio se decidió realizar una división adicional para los ruidos intermitentes. Con el fin de ignorar los sonidos de digitación en los teclados (que no resultan tan molestos como la voz humana) se creó la categorı́a “golpes intermitentes”, que abarca especı́ficamente sonidos de teclado y “vo2 Dado que el dispositivo de grabación no expresa la señal en términos de nivel de presión sonora (SPL) sino que más bien asigna un valor de ±1 para los voltajes máximos recibido desde el micrófono, no es posible medir la energı́a en una unidad establecida como pascales o watts/m2 sin usar equipo especial. Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) 70 cales” para los sonidos producidos por el tracto vocal (conversaciones, despejes de garganta, cantos y silbidos). Éstas últimas a su vez se dividen en “vocales bajas” y “vocales altas” dependiendo de la intensidad de la conversación. EVALUACIÓN Se recopilaron 138 grabaciones con los ruidos más comunes encontrados en una oficina. La oficina de estudio consiste en un espacio rectangular de 5x9 metros sin barreras entre los cubı́culos y en donde conviven a diario 8 personas (sin contar los individuos que entran y salen). Hay un sistema de aire acondicionado y el lugar encuentra cerca de una carretera muy transitada. Las grabaciones son monoaurales, con tasa de muestreo de 44100 Hz, de formato OGG y fueron recopiladas usando un teléfono LG G2 Mini. Los archivos de audio fueron clasificados a mano según la clasificación de ruidos vocales, zumbidos, golpes aislados y golpes continuos. Para calcular el espectrograma se utilizó una ventana Hamming de tamaño M = 512, la cual permitió abarcar la frecuencia fundamental más baja de la voz humana (70 Hz). El filtro pasabajas se implementó usando el algoritmo moving average con 2 vecinos para cada muestra [13]. Para contar los eventos acústicos se empleó un umbral empı́rico de 3.2. Este umbral fue determinado a partir de un análisis de las grabaciones de un aire acondicionado (figura 1) y de una conversación de intensidad alta (figura 2). La elección de éste umbral se debe a que los ruidos producidos por los generadores de ruido blanco de la oficina (ventiladores, abanicos, aires acondicionados) tienen menos energı́a que la voz humana y querı́an ser omitidos del control. Figura 2. Oscilograma para una conversación de intensidad alta y su ODF. Nóte que muchos de los picos están ubicados por encima del umbral, estos corresponden con el inicio de las sı́labas. Cuadro 1. Valor promedio de los descriptores para cada categorı́a Categoria vocalesBajas zumbidos golpesC golpesA vocalesAltas TCC 0.0407 0.0619 0.1466 0.0988 0.1047 EAPS 18.43 10.64 20.81 17.62 15.87 ENERGIA 0277.01 2302.07 0833.25 1099.88 2531.36 recopiladas se muestran la figura 3. En ella se pueden observarse 4 regiones correspondientes a las categorı́as definidas, los centroides de cada grupo se presentan en el cuadro 1. Al quitar el grupo de los golpes aislados y aplicar un algoritmo de clasificación del vecino más próximo, usando la distancia Euclidiana y un criterio de validación cruzada con 10 plieges [6], podemos agrupar los puntos en sus categorı́as respectivas con una precisión del 85.3448%.3 El problema del traslape entre los puntos de las vocales altas y los golpes aislados no es grave y en la sección de trabajo futuro explicamos como resolverlo. No es de sorprender que los ruidos constantes estén ubicados en las regiones con EAPS muy altas (0.20) o muy bajas (0.06), pues al aumentar el número de eventos acústicos en la señal se obtiene una envolvente casi continua sin cambios apreciables de energı́a. CONCLUSIONES Se describió un método para clasificar tipos de ruido por medio de los descriptores TCC, EAPS y energı́a por segundo de la señal. Figura 1. Oscilograma para el sonido de un aire acondicionado y su ODF. Nóte que la mayorı́a de los picos están ubicados por debajo del umbral. RESULTADOS Los resultados obtenidos al calcular los descriptores TCC, EAPS y energı́a por segundo de la señal para las grabaciones En el experimento realizado se determinó que usando un clasificador del vecino más próximo es posible ubicar con un 85% de acierto las grabaciones recopiladas en las categorı́as propuestas, y con ésto saber cuándo es necesario activar el control por enmascaramiento. 3 Para ello empleamos una implementación del clasificador kNN llamada iBK, accesible del ambiente de minerı́a de datos WEKA. Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) 71 3. Cho, N., and Kim, E.-K. Enhanced voice activity detection using acoustic event detection and classification. Consumer Electronics, IEEE Transactions on 57, 1 (February 2011), 196–202. 4. Gouyon, F., Pachet, F., and Delerue, O. On the use of zero-crossing rate for an application of classification of percussive sounds (2000). 5. Haapakangas, A., Hongisto, V., H., J., Kokko, J., and K., J. Effects of unattended speech on performance and subjective distraction: The role of acoustic design in open plan offices. Applied Acoustics 86, 0 (2014), 1 – 16. 6. Hall, M., Frank, E., Holmes, G., Pfahringer, B., Reutemann, P., and Witten, I. H. The weka data mining software: An update. SIGKDD Explor. Newsl. 11, 1 (Nov. 2009), 10–18. Figura 3. Plano formado por los descriptores TCC, EAPS y energı́a por segundo de la señal. Los cı́rculos rojos corresponden a sonidos vocales altos, las equis son sonidos vocales bajos, los cuadrados celestes pertenecen a los zumbidos, los triangulos azules significan golpes intermitentes y los puntos negros son los golpes aislados. TRABAJO FUTURO El problema de separar los golpes aislados respecto de las vocales altas necesita un enfoque adicional que considere también el número de veces que se repite el sonido. Esto puede lograrse usando un autómata de estados finitos como el de la figura 4. En el cual usando una variable “cont” se puede hacer la transición entre los estados: “en silencio” y “en ruido”, pasando por los niveles intermedios. Cuando el ruido no se repite más de cierto número de veces, por ejemplo 3 para perı́odos de grabación de 3s, entonces se sabe que el ruido es aislado. 7. Haykin, S., and Chen, Z. The cocktail party problem. Neural Computation 17, 9 (Sept. 2005), 1875–1902. 8. Jalil, M., Butt, F., and Malik, A. Short-time energy, magnitude, zero crossing rate and autocorrelation measurement for discriminating voiced and unvoiced segments of speech signals. In Technological Advances in Electrical, Electronics and Computer Engineering (TAEECE), 2013 International Conference on (May 2013), 208–212. 9. NIOSH. Occupational noise exposure. National Institute of Occupational Safety and Health 126, 98 (June 1998). 10. NIOSH. Reducing noise hazards for call and dispatch center operators. National Institute of Occupational Safety and Health DHHS series, 2011-210 (September 2011). 11. Pao, T.-L., Liao, W.-Y., and Chen, Y.-T. Audio-visual speech recognition with weighted knn-based classification in mandarin database. In Intelligent Information Hiding and Multimedia Signal Processing, 2007. IIHMSP 2007. Third International Conference on, vol. 1 (Nov 2007), 39–42. 12. Percival, G., and Tzanetakis, G. Streamlined tempo estimation based on autocorrelation and cross-correlation with pulses. Audio, Speech, and Language Processing, IEEE/ACM Transactions on 22, 12 (Dec 2014), 1765–1776. 13. Prandoni, P., and Vetterli, M. Signal processing for communications. EPFL Press 1, 1 (2008), 85–86. Figura 4. Autómata para activar el control por enmascaramiento REFERENCIAS 1. Bello, J., Daudet, L., Abdallah, S., Duxbury, C., Davies, M., and Sandler, M. B. A tutorial on onset detection in music signals. Speech and Audio Processing, IEEE Transactions on 13, 5 (Sept 2005), 1035–1047. 2. Camacho, A. Swipe: A Sawtooth Waveform Inspired Pitch Estimator for Speech and Music. PhD thesis, Gainesville, FL, USA, 2007. AAI3300722. 14. Tian, M., Srinivasamurthy, A., Sandler, M., and Serra, X. A study of instrument-wise onset detection in beijing opera percussion ensembles. In Acoustics, Speech and Signal Processing (ICASSP), 2014 IEEE International Conference on (May 2014), 2159–2163. 15. Wu, B., Ren, X., Liu, C., and Zhang, Y. A robust, real-time voice activity detection algorithm for embedded mobile devices. International Journal of Speech Technology 8, 2 (2005), 133–146. 72 Reconocimiento automático de acordes musicales usando un enfoque holı́stico Arturo Camacho Escuela de Ciencias de la Computación e Informática CITIC Universidad de Costa Rica [email protected] ABSTRACT En este artı́culo se propone un método para reconocer automáticamente acordes musicales en grabaciones de audio. A diferencia de otros métodos que reconocen notas individuales y que a partir de ellas forman el acorde, o que reconocen el acorde pero no permiten inferir las notas individuales, el método propuesto primero reconoce el acorde de una forma holı́stica y luego deduce las notas a partir de él. Esta estrategia está inspirada en la forma en que los músicos perciben la música: al escuchar un acorde lo identifican como como un todo y no como la suma de sus partes. En el método propuesto se usan plantillas para reconocer notas individuales y para reconocer acordes. Esto se hace comparando la similitud entre el espectro de la señal y las plantillas. Los resultados muestran tasas de acierto por encima del 90 % y el 70 % para intervalos pequeños y medianos, respectivamente, y un poco por debajo para trı́adas. En términos del reconocimiento de las notas individuales, tiene una alta precisión (por encima del 90 %) y una moderada exhaustividad (por encima del 70 %). Palabras clave Reconocimiento automático de acordes; procesamiento de señales de audio; análisis de armonı́a musical INTRODUCCIÓN La estimación automática de acordes (grupos de notas musicales) tiene múltiples aplicaciones en el procesamiento de música, predominantemente, en la transcripción automática. En la literatura se proponen dos estrategias para resolver este problema: detectar acordes a partir de histogramas cı́clicos de altura (lo que da información sobre el acorde pero no de las alturas individuales) [2] y detectar notas individuales (ya sea seleccionando los máximos locales en una función de puntaje de candidatos o mediante un proceso iterativo de detección y cancelación de notas individuales) [4, 3]. En este trabajo se propone un método que combina ambos enfoques: detecta el acorde de una forma holı́stica (como un todo) pero además permite identificar las notas individuales. Este enfoque se inspira en la forma en la que los músicos perciben los acordes: como un todo y no como notas individuales. El método propuesto es una extensión de un trabajo previo del autor que Se autoriza hacer copias de este trabajo o partes de para uso académico, siempre y cuando sea sin fines de lucro. La copia debe contener esta nota y la cita completa en la primera página. La copia bajo otras circunstancias y la distribución o publicación podrı́a requerir permisos adicionales o pago de derechos. JOCICI’15, Marzo 5-6, San José, Costa Rica. c Copyright 2015 CITIC-PCI solo reconocı́a acordes mayores [1]. La extensión consiste en el reconocimiento de acordes menores. MÉTODO El método consiste en comparar el espectro de la señal con plantillas que modelan tanto notas individuales como intervalos (grupos de dos notas) y trı́adas (grupos de tres notas) y escoger como ganadora a aquella que se asemeje más al espectro de la señal. Si la similitud es suficientemente alta, se declara que se ha reconocido la nota o acorde asociada a la plantilla. Para intervalos y trı́adas consonantes (trı́adas cuyas notas suenan en armonı́a al tocarse simultáneamente) se usa la entonación justa, que consiste en yuxtaponer notas cuyas frecuencias forman cocientes de enteros pequeños (por ejemplo: 2:1 y 3:2), y para los disonantes se usa la entonación temperada, en la que las frecuencias forman cocientes que son potencias de 21/12 . En este trabajo nos concentramos en los intervalos consonantes de quinta justa (2:3), cuarta justa (3:4), tercera mayor (4:5) y sexta menor (5:6) y en los intervalos disonantes de segunda mayor (1:21/6 ≈ 1:1,12) y segunda menor (1:21/12 ≈ 1:1,06). En cuanto a trı́adas, nos concentramos en acordes mayores y menores y cada una de sus inversiones. Para el acorde mayor se usa la relación 4:5:6 y para sus inversiones 5:6:8 y 3:4:5. Para el acorde mayor se usa la relación 10:12:15 y para sus inversiones 12:15:20 y 15:20:24. Construcción de las plantillas Las plantillas que reconocen notas individuales tienen picos localizados en múltiplos de la frecuencia fundamental f , es decir, en k f (k = 1, 2, 3, . . .). Las plantillas que reconocen intervalos en relación p:q (p < q) tienen sus picos en kp ft y kq ft (k = 1, 2, 3, . . .), donde ft es la frecuencia de la tónica (en términos matemáticos: el máximo común divisor de las frecuencias de las notas). Las plantillas que reconocen trı́adas en relación p:q:r (p < q < r) contienen además picos en kr ft (k = 1, 2, 3, . . .). Con respecto a la altura y ancho de los picos, la altura es inversamente proporcional a la raı́z cuadrada de la frecuencia de su ubicación y el ancho es fb /32 [1]. La figura 1 muestra la plantilla usada para reconocer un intervalo de quinta justa (notas en relación 2:3). Los picos se ubican en múltiplos de 2 y 3. Al ser 6 y 12 múltiplos de ambos, su altura se duplica. Por otra parte, la figura 2 muestra la plantilla usada para reconocer una trı́ada mayor en posición fundamental (notas en relación 4:5:6). Los picos se localizan en múltiplos de 4, 5 y 6. Al ser 12 y 20 múltiplos de dos de ellos, su altura se duplica. (Para 60 —ausente en la figura— se triplicarı́a). √ Amplitud Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) 1 2 3 4 justa y una trı́ada mayor (en posición fundamental), con bajo la4 (440 Hz), producidos al combinar grabaciones de notas aisladas tocadas con una flauta traversa. Se puede ver en cada caso que la puntuación más alta es producida por la plantilla correspondiente a la nota, intervalo o trı́ada correcta, y que la frecuencia (de la nota bajo) es también la correcta. 5 6 7 8 9 10 11 12 Frecuencia / ft √ Amplitud Figura 1: Plantilla usada para reconocer una quinta justa (notas en relación 2:3) con tónica de frecuencia ft . 4 5 6 8 10 12 1516 18 20 Frecuencia / ft Figura 2: Plantilla usada para reconocer una trı́ada mayor en posición fundamental (notas en relación 4:5:6) con tónica de frecuencia ft . Cálculo del espectro El tamaño de la ventana de la señal que se usa para calcular el espectro es 64/ fb segundos, donde fb es la frecuencia del bajo (la nota de de más baja frecuencia en el acorde). Este tamaño permite hacer corresponder el ancho de los lóbulos espectrales con el ancho de los picos de la plantilla [1]. A costas de reducir un poco esta correspondencia, se puede reducir el costo computacional usando el tamaño más cercano a 64/ fb cuya cantidad de muestras sea una potencia de dos: 2k ≈ fm / fb , donde fm es la frecuencia de muestreo de la señal. Cálculo de la similitud entre el espectro y las plantillas La similitud entre el espectro de la señal X y una plantilla P se calcula como el coseno del ángulo entre ellos: R∞ similitud(X, P) = s 0 R∞ 0 P( f ) |X( f )|1/2 d f s P2 ( f )d f . (1) R∞ 0 73 |X( f )| d f (Un resultado bien conocido del álgebra lineal es que, para dos vectores a y b separados por un ángulo θ , se cumple que cos θ = a · b/ kak kbk). Esta similitud se calcula para cada una de las plantillas y distintas frecuencias ft , y es interpretada como una puntuación para el par plantilla-frecuencia. A partir del par con la máxima puntuación se declara la nota, intervalo o trı́ada reconocido y la frecuencia de cada una de las notas que lo componen (basado en la frecuencia del bajo y las relaciones entre las frecuencias de las notas previamente definidas). Ejemplos de puntuaciones producidas por las plantillas A manera de ejemplo, las figuras 3, 4 y 5 muestran, respectivamente, las puntuaciones producidas por cada una de las plantillas para una nota sola (unı́sono), un intervalo de quinta RESULTADOS El método propuesto fue evaluado usado muestras de la colección de sonidos de Electronic Music Studio de la Universidad de Iowa, que incluye muestras de cuerdas (violı́n, viola, violonchelo y contrabajo), maderas (flauta traversa, clarinete, saxofón, fagot y oboe), metales (trompeta, trombón, corno francés y tuba) y piano. El rango de los bajos fue de do3 (131 Hz) a si4 (494 Hz). El rango de frecuencias para el bajo de las plantillas fue de 100 Hz a 500 Hz. El cuadro 1 muestra los resultados obtenidos para cada tipo de intervalo o trı́ada (el unı́sono corresponde a una sola nota tocada por un instrumento). La segunda columna indica la cantidad de muestras usadas, la tercera la tasa de acierto (fracción de intervalos o trı́adas que fueron correctamente clasificados, tanto en cuanto a tipo como a frecuencia, después de redondear esta al semitono más cercano de la escala temperada afinada en la4 = 440 Hz), la cuarta la precisión (fracción de notas reconocidas presentes en la señal), la quinta la exhaustividad (fracción de notas reconocidas en la señal) y la última la medida F (media armónica de las dos anteriores). CONCLUSIÓN Los resultados muestran que el método propuesto alcanza una tasa de acierto alta (por encima del 90 %) para notas aisladas e intervalos pequeños (segunda mayor y menor), una tasa mediana (entre el 70 % y el 90 %) para intervalos medianos (tercera mayor y menor, y cuarta y quinta justas) y una tasa baja para trı́adas (generalmente por debajo del 70 %). En cuanto a precisión del reconocimiento de las notas individuales, los resultados son buenos (excede generalmente el 90 %), lo que significa que las notas reconocidas por el método generalmente están presentes en la señal. La exhaustividad varı́a dependiendo del tipo de intervalo o trı́ada: en general es alta (por encima del 80 %), excepto para las trı́adas menores (entre el 70 % y el 80 % para trı́adas en posición fundamental y primera inversión, y 60 % para trı́adas en segunda inversión). Sin embargo, la baja exhaustividad es contrarrestada por la alta precisión. Esto se refleja en la medida F, que se calcula como la media armónica de ellas; su valor es del 87 % o mayor, excepto para los casos mencionados antes. INVESTIGACIÓN FUTURA Este trabajo deja por fuera cuatro aspectos clave del trabajo previo del autor: el uso en las plantillas de picos negativos, el análisis del espectro basado solo en las armónicas primas y el uso de una escala de la frecuencia derivada de la psicoacústica. Se hizo ası́ porque de momento se obtienen mejores resultados dejando esas caracterı́sticas por fuera. En particular, debe buscarse un lugar apropiado para poner los picos negativos, ya que la ubicación definida en el trabajo previo no funciona en este caso, especialmente para las plantillas de Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) Puntuación Tercera mayor Cuarta justa Quinta justa Unı́sono 74 Segunda mayor Tercera menor Segunda menor 0.8 0.8 0.8 0.8 0.8 0.8 0.8 0.6 0.6 0.6 0.6 0.6 0.6 0.6 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.2 0.2 0.2 0.2 0.2 0.2 0.2 0 200 400 200 400 Trı́ada mayor 1 0.5 0 200 400 Trı́ada mayor I inv. 200 200 400 Trı́ada mayor II inv. 200 400 Trı́ada menor 200 400 Trı́ada menor I inv. Trı́ada menor II inv. 0.8 0.8 0.8 0.8 0.8 0.8 0.6 0.6 0.6 0.6 0.6 0.6 0.4 0.4 0.4 0.4 0.4 0.4 0.2 0.2 0.2 0.2 0.2 0.2 0 0.20.40.60.8 1 200 200 400 400 200 200 400 400 200 400 200 400 400 Frecuencia del bajo / Hz Figura 3: Puntuación producida por las plantillas como función de la frecuencia del bajo para la nota la4 (440 Hz) tocada en una flauta alto. Quinta justa Puntuación Unı́sono Cuarta justa Tercera mayor Segunda menor Segunda mayor Tercera menor 0.8 0.8 0.8 0.8 0.8 0.8 0.8 0.6 0.6 0.6 0.6 0.6 0.6 0.6 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.2 0.2 0.2 0.2 0.2 0.2 0.2 0 200 400 200 400 Trı́ada mayor 1 0.5 0 200 200 400 Trı́ada mayor I inv. 400 200 Trı́ada mayor II inv. 200 400 Trı́ada menor 400 Trı́ada menor I inv. 200 Trı́ada menor II inv. 0.8 0.8 0.8 0.8 0.8 0.8 0.6 0.6 0.6 0.6 0.6 0.6 0.4 0.4 0.4 0.4 0.4 0.4 0.2 0.2 0.2 0.2 0.2 0.2 0 0.20.40.60.8 1 200 400 200 200 400 400 200 200 400 400 400 200 400 Frecuencia del bajo / Hz Figura 4: Puntuación producida por las plantillas como función de la frecuencia del bajo para una quinta justa con bajo la4 (440 Hz) tocada en una flauta alto. Puntuación Cuarta justa Quinta justa Unı́sono Tercera mayor Segunda menor Segunda mayor Tercera menor 0.8 0.8 0.8 0.8 0.8 0.8 0.8 0.6 0.6 0.6 0.6 0.6 0.6 0.6 0.4 0.4 0.4 0.4 0.4 0.4 0.4 0.2 0.2 0.2 0.2 0.2 0.2 0.2 0 200 200 400 400 Trı́ada mayor 1 0.5 0 0 0.20.40.60.8 1 200 400 Trı́ada mayor I inv. 200 400 200 Trı́ada mayor II inv. 200 400 Trı́ada menor 400 Trı́ada menor I inv. 200 Trı́ada menor II inv. 0.8 0.8 0.8 0.8 0.8 0.8 0.6 0.6 0.6 0.6 0.6 0.6 0.4 0.4 0.4 0.4 0.4 0.4 0.2 0.2 0.2 0.2 0.2 0.2 200 400 200 400 200 400 200 400 200 400 400 200 400 Frecuencia del bajo / Hz Figura 5: Puntuación producida por las plantillas como función de la frecuencia del bajo para una trı́ada mayor (en posición fundamental) con bajo la4 (440 Hz) tocada en una flauta alto. Memorias de las II Jornadas Costarricenses de Investigación en Computación e Informática (JoCICI 2015) 75 Cuadro 1: Resultados producidos por el método propuesto para intervalos y acordes producidos por piano e instrumentos de cuerda, maderas, metales. Intervalo o trı́ada Unı́sono Quinta justa Cuarta justa Tercera mayor Tercera menor Segunda mayor Segunda menor Trı́ada mayor en posición fundamental Trı́ada mayor en primera inversión Trı́ada mayor en segunda inversión Trı́ada menor en posición fundamental Trı́ada menor en primera inversión Trı́ada menor en segunda inversión N.o de muestras Tasa de acierto Precisión Exhaustividad Medida F 374 340 351 356 361 365 369 338 331 326 356 344 347 0,96 0,76 0,83 0,74 0,74 0,90 0,92 0,63 0,73 0,60 0,50 0,37 0,56 0,91 0,90 0,95 0,92 0,90 0,98 0,97 0,91 0,94 0,91 0,90 0,87 0,69 0,97 0,88 0,90 0,85 0,84 0,94 0,95 0,85 0,87 0,83 0,76 0,71 0,60 0,94 0,89 0,93 0,88 0,87 0,96 0,96 0,87 0,90 0,87 0,82 0,78 0,64 acordes menores. Una vez resuelto este problema, se espera que la incorporación de las otras caracterı́sticas aporte al desempeño del método. REFERENCIAS AGRADECIMIENTOS 2. Fujishima, T. Realtime chord recognition of musical sound: a system using common lisp music. En Proc. Int. Computer Music Conf. (Pekı́n, China, 1999), 464–467. Este trabajo es fruto del proyecto de investigación n.o 834B4-215 de Centro de Investigaciones en Tecnologı́as de la Información y Comunicación (CITIC) de la Universidad de Costa Rica. Se agradece al Centro el apoyo brindado a este proyecto. 1. Camacho, A. Detection of musical notes and chords using a holistic approach. Proceedings of Meetings on Acoustics 21, 1 (2014). 3. Klapuri, A. Multipitch analysis of polyphonic music and speech signals using an auditory model. IEEE Trans. Audio, Speech, Lang. Process. 16 (2008), 255–266. 4. Tolonen, T. y Karjalainen, M. A computationally efficient multipitch analysis model. Speech and Audio Processing, IEEE Transactions on 8, 6 (nov 2000), 708–716.
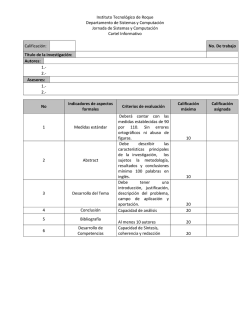



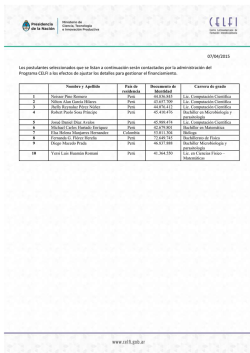
© Copyright 2026