
Creación de aplicaciones tolerantes a fallos en AWS
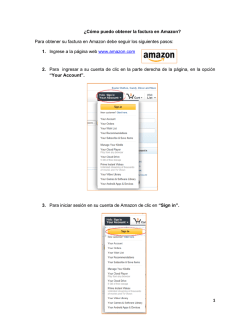
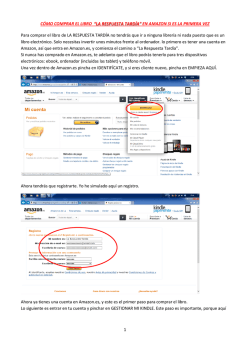
Amazon Web Services – Creación de aplicaciones tolerantes a fallos en AWS Mayo de 2010 Creación de aplicaciones tolerantes a fallos en AWS Mayo de 2010 Jeff Barr y Attila Narin 1 Amazon Web Services – Creación de aplicaciones tolerantes a fallos en AWS Mayo de 2010 Introducción El software se ha convertido en un aspecto de vital importancia de la vida cotidiana en casi todos los rincones del mundo. Allí donde estemos, interactuamos con el software, ya sea al utilizar nuestro teléfono móvil, retirar dinero de un cajero automático o simplemente al detenernos ante un semáforo. Debido a que el software forma una parte tan importante de nuestra vida diaria, es necesario poner todo el empeño posible para garantizar que el software permanece operativo y disponible. En términos generales, este área de estudio recibe el nombre de tolerancia a fallos, y es la capacidad que tiene un sistema de seguir en funcionamiento incluso si alguno de los componentes utilizados para crear el sistema falla. Aunque es cierto que los sistemas básicos deben estar disponibles en todo momento, también esperamos que haya una variedad de software mucho más amplia a nuestra disposición en todo momento. Por ejemplo, podríamos querer visitar un sitio web de comercio electrónico para comprar un producto. Tanto si son las nueve de la mañana de un lunes o las tres de un día festivo, esperamos que el sitio web esté disponible y listo para aceptar nuestra compra. El coste que puede tener no cumplir estas expectativas puede ser devastador para muchas empresas. Incluso con presunciones muy conservadores, se estima que un sitio de comercio electrónico que realiza muchas transacciones podría perder miles de dólares por cada minuto que no está disponible. Este es tan solo uno de los ejemplos por los que las empresas y las organizaciones se esfuerzan por desarrollar sistemas de software que puedan sobrevivir a los fallos. Amazon Web Services (AWS) proporciona una plataforma idónea para la creación de sistemas de software tolerantes a fallos. Sin embargo, este atributo no es exclusivo de nuestra plataforma. Con los recursos necesarios y el tiempo adecuado, una persona podría crear un sistema de software tolerante a fallos casi en cualquier plataforma. La plataforma AWS es única en el sentido de que le permite crear sistemas tolerantes a fallos que funcionan con un nivel mínimo de interacción humana y de inversión monetaria inicial. Los fallos no deben ser TAN interesantes Cuando un servidor se bloquea o un disco duro se queda sin espacio en un entorno de centro de datos que se encuentra en las instalaciones se avisa inmediatamente a los administradores, ya que son eventos de cierta importancia que requieren, como mínimo, su atención, e incluso a veces su intervención. El estado ideal en un entorno de centro de datos tradicional dentro de las instalaciones tiende a ser uno en el que las notificaciones de fallos se transmiten de forma fiable a un conjunto de administradores que están preparados para ponerse manos a la obra para resolver el problema. Muchas empresas son capaces de alcanzar este estado de nirvana informático. Sin embargo, conseguirlo necesita una dilatada experiencia, una fuerte inversión inicial y recursos humanos considerables. Este no es el caso cuando se utiliza la plataforma proporcionada por Amazon Web Services. En una situación ideal, los fallos que se produzcan en una aplicación creada en nuestra plataforma puede gestionarlos directamente el sistema, y por lo tanto, son eventos poco interesantes. Amazon Web Services le proporciona acceso a una enorme cantidad de infraestructura de TI (equipos informáticos, almacenamiento y comunicaciones) que puede asignar de forma automática (o casi automática) para resolver casi todo 2 Amazon Web Services – Creación de aplicaciones tolerantes a fallos en AWS Mayo de 2010 tipo de fallos. Únicamente se le cobrarán los servicios que en realidad utilice, por lo que no tendrá que realizar ningún tipo de inversión inicial. Amazon Machine Images (Imágenes de máquina de Amazon) Amazon Elastic Compute Cloud (Amazon EC2) es un servicio web dentro de Amazon Web Services que proporciona recursos informáticos (literalmente instancias de servidor) que puede utilizar para crear y alojar sus sistemas de software. Amazon EC2 es el punto de entrada natural a Amazon Web Services para el desarrollo de sus aplicaciones. Podrá crear un sistema muy fiable y con alta tolerancia a fallos utilizando varias instancias de EC2, mediante el uso de herramientas y servicios secundarios tales como Auto Scaling (Escalado automático) y Elastic Load Balancing (Equilibrado de carga elástico). En la superficie, las instancias de Amazon EC2 son muy similares a los servidores de hardware convencionales. Las instancias de Amazon EC2 utilizan sistemas operativos conocidos como, por ejemplo, Linux, Windows y OpenSolaris. De esta forma, pueden dar cabida a casi todas las aplicaciones de software que pueden ejecutarse en estos sistemas operativos. Las instancias de Amazon EC2 tienen direcciones IP, por lo que pueden utilizarse los métodos habituales de interacción con máquinas remotas (p. ej., SSH o RDP). La plantilla que el usuario utiliza para definir sus instancias de servicio recibe el nombre de Amazon Machine Image (AMI) (Imagen de máquina de Amazon). Esta plantilla contiene básicamente una configuración de software (es decir, sistema operativo, servidor de aplicaciones y aplicaciones) que se aplica a un tipo de instancia1. Los tipos de instancia de Amazon EC2 son básicamente arquetipos de hardware. El usuario elige un tipo de instancia que se adapta a la cantidad de memoria (RAM) y potencia informática (número de CPU) que necesita para su aplicación. Es posible utilizar una única AMI para crear recursos de servidor de diferentes tipos de instancia. Esta relación se ilustra a continuación. 1 Tipos de instancia: http://aws.amazon.com/ec2/instance-‐types/ 3 Amazon Web Services – Creación de aplicaciones tolerantes a fallos en AWS Mayo de 2010 AMI Ilustración 1 -‐ Amazon Machine Image Amazon publica numerosas AMI que contienen configuraciones de software comunes. Además de ello, varios miembros de la comunidad de desarrolladores de AWS también han publicado sus propias AMI personalizadas. Todas estas AMI se encuentran en la página de recursos de Amazon Machine Image 2 del sitio web de AWS. Sin embargo, el primer paso en la creación de aplicaciones tolerantes a fallos en AWS es crear una biblioteca de sus propias AMI. Su aplicación debe estar compuesta por, al menos, una AMI que usted haya creado. Iniciar su aplicación será, por lo tanto, cuestión de iniciar la AMI. Por ejemplo, si su aplicación es un sitio web o un servicio web, su AMI debería estar configurada con un servidor web (como por ejemplo Apache o Microsoft Internet Information Server), el contenido estático asociado y el código de todas las páginas dinámicas. También podría configurar su AMI para instalar todos los componentes de software que necesite y el contenido ejecutando una secuencia de comandos de arranque en cuanto se ejecuta la instancia. De este modo, tras ejecutar la AMI, se iniciará el servidor web y su aplicación podrá empezar a aceptar solicitudes. Una vez creada una AMI, la sustitución de una instancia que falla es muy sencilla. Puede literalmente ejecutar una instancia de sustitución que utiliza la misma AMI como su plantilla. Esto puede realizarse mediante la invocación de una API, a través de herramientas de línea de comandos mediante secuencias de comandos o a través de la Consola de administración de AWS, tal y como se muestra a continuación. En una sección posterior de este documento presentaremos el servicio Auto Scaling (Escalado automático), que puede sustituir instancias que fallan o que presentan un escaso rendimiento que actualiza instancias automáticamente. 2 Página de recursos de Amazon Machine Images: http://developer.amazonwebservices.com/connect/kbcategory.jspa?categoryID=171 4 Amazon Web Services – Creación de aplicaciones tolerantes a fallos en AWS Mayo de 2010 Ilustración 2 -‐ Ejecución de una instancia de Amazon EC2 Este es en realidad el primer paso hacia la tolerancia a fallos. En este punto podrá recuperar fácilmente después de producirse fallos. Si una instancia falla, o si simplemente no se está comportando tal y como usted desea, puede ejecutar otra basada en la misma plantilla. A fin de minimizar los tiempos de inactividad, puede incluso mantener en ejecución una instancia de respaldo, lista para entrar en funcionamiento en caso de producirse un fallo. Esto puede hacerse de un modo eficiente utilizando direcciones IP elásticas. Podrá conmutar por error fácilmente a una instancia de sustitución o una instancia de recambio en ejecución reasignando su dirección IP elástica a la nueva instancia. Las direcciones IP elásticas se describen con mayor nivel de detalle en una sección posterior de este documento. Tener la posibilidad de ejecutar rápidamente instancias de sustitución basadas en una AMI que usted define es un paso de vital importancia para conseguir la tolerancia a fallos. El siguiente paso es almacenar los datos persistentes a los que estas instancias de servidor tienen acceso. Elastic Block Store (Almacén de bloque elástico) Amazon Elastic Block Store (Amazon EBS) proporciona volúmenes de almacenamiento a nivel de bloque diseñados para utilizarlos con las instancias de Amazon EC2. Los volúmenes Amazon EBS son almacenamiento fuera de la instancia que persisten con independencia de la vida de una instancia. Los volúmenes Amazon EBS son básicamente discos duros que pueden conectarse a una instancia de Amazon EC2 en ejecución. Amazon EBS resulta especialmente ideal para aquellas aplicaciones que necesitan una base de datos, un sistema de archivos o acceso a almacenamiento bruto a nivel de bloque. Los volúmenes EBS almacenan los datos de forma redundante, lo que los hace más resistentes que un disco duro convencional. La tasa de fallo anual (AFR) de un volumen EBS es del 0,1% y el 0,5%, en comparación con el 4% que presenta un disco duro comercial. Amazon EBS y Amazon EC2 suelen utilizarse de forma conjunta al crear una aplicación tolerante a fallos en la plataforma AWS. Todos los datos que tengan que estar disponibles de forma persistente deben almacenarse en volúmenes Amazon EBS, no en el "almacenamiento efímero" asociado con cada instancia de EC2. Si la instancia de Amazon EC2 falla y debe sustituirse, el volumen Amazon EBS puede simplemente conectarse a la nueva instancia de Amazon EC2. Dado que esta instancia es básicamente un duplicado de la instancia original, no debe haber ningún tipo de pérdida de datos o funcionalidad. Los volúmenes Amazon EBS presentan elevados niveles de fiabilidad, pero para mitigar aún más la posibilidad de que se produzca un fallo, es posible crear copias de seguridad de estos volúmenes utilizando una función denominada instantáneas. Una estrategia de copia de seguridad robusta incluirá un intervalo (tiempo entre copias de seguridad, normalmente diario pero, quizás, con mayor frecuencia en determinadas aplicaciones), un periodo de retención (en 5 Amazon Web Services – Creación de aplicaciones tolerantes a fallos en AWS Mayo de 2010 función de la aplicación y de los requisitos empresariales de reversión) y un plan de recuperación. Las instantáneas se almacenan en Amazon S3 con el objetivo de mantener su resistencia. Las instantáneas pueden utilizarse para crear nuevos volúmenes Amazon EBS, que son una réplica exacta del volumen original en el momento en el que se realizó la instantánea. Dado que las copias de seguridad representan el estado en disco de la aplicación, se debe tener la precaución de volcar los datos que se encuentran almacenados en la memoria antes de iniciar una instantánea. Estas operaciones con Amazon EBS pueden realizarse desde la API o desde la Consola de administración de AWS, tal y como se muestra a continuación. Ilustración 3 -‐ Amazon EBS Direcciones IP elásticas Las direcciones IP elásticas son direcciones IP públicas que pueden asignarse (enrutarse) a cualquier instancia de EC2 dentro de una Región de EC2 concreta. Las direcciones se asocian a una cuenta de AWS, no a una instancia concreta ni a la vida útil de una instancia, y están diseñadas para ayudar en el proceso de construcción de aplicaciones tolerantes a fallos. Una dirección IP elástica puede desvincularse de una instancia que presenta fallos y, posteriormente, asignarse a una instancia de sustitución en un plazo de tiempo muy breve. Del mismo modo que con los volúmenes EBS (y con todos los demás recursos de EC2 importantes), todas las operaciones con direcciones IP elásticas pueden realizarse de forma programática mediante la API o manualmente desde la Consola de administración de AWS: Ilustración 4 -‐ Direcciones IP elásticas Los fallos pueden resultar útiles "No soy programador en realidad. Intento encajar las piezas del puzzle, hasta que encajan, y continúo. Los programadores de verdad dirán "sí, funciona, pero estás desperdiciando memoria por 6 Amazon Web Services – Creación de aplicaciones tolerantes a fallos en AWS Mayo de 2010 todos sitios. Quizás deberíamos resolver este aspecto." Reiniciaré Apache después de cada 10 solicitudes." Rasmus Lerdorf (creador de PHP) Aunque a menudo no suele admitirse, la realidad es que la mayoría de sistemas de software pierden rendimiento con el paso de tiempo. Esto se debe, en parte, a una o todas de las razones siguientes: 1. El software desperdiciará memoria y/o recursos. Esto incluye tanto software que usted haya desarrollado como software del que dependa (como, por ejemplo, marcos de trabajo de aplicación, sistemas operativos y controladores de dispositivos). 2. Los sistemas de archivos se fragmentan con el paso del tiempo y afectan al rendimiento. 3. Los dispositivos de hardware (especialmente los de almacenamiento) se degradan físicamente con el paso del tiempo. Los procesos de ingeniería de software disciplinados puede mitigar algunos de estos problemas, pero en último término hasta el sistema de software más sofisticado depende de una serie de componentes que están fuera de su control (por ejemplo, el sistema operativo, el firmware y el hardware). En un determinado momento, una combinación de hardware, software de sistema y su software provocará un fallo e interrumpirá la disponibilidad de su aplicación. En un entorno de TI tradicional, el hardware puede mantenerse y repararse de forma regular, pero existen límites tanto prácticos como financieros sobre la agresividad con la que puede adoptarse este enfoque. Sin embargo, con Amazon EC2, puede finalizar y volver a crear los recursos que necesite a voluntad. Una aplicación que aproveche al máximo la plataforma AWS puede actualizarse de forma periódica con nuevas instancias de servidor. Esto garantiza que cualquier posible reducción de rendimiento no afecte a todo su sistema. En cierto modo, estaría utilizando lo que podría considerarse como un fallo (como, por ejemplo, la parada de un servidor) como función que fuerza la actualización de este recurso. Con este enfoque, una aplicación AWS se define con mayor precisión como el servicio que proporciona a sus clientes, en lugar de como las instancias de servidor que la componen. Teniendo esto en mente, las instancias de servidor pasan a ser inmateriales e, incluso, desechables. Auto Scaling (Escalado automático) El concepto de aprovisionar y ampliar automáticamente los recursos informáticos es un aspecto de vital importancia de toda aplicación tolerante a fallos bien diseñada que se encuentra en ejecución en la plataforma Amazon Web Services. Auto Scaling3 es una potente opción para aplicar de una forma muy sencilla este concepto a su aplicación. Auto Scaling le permite modificar de forma automática su capacidad de Amazon EC2 para ampliarla o reducirla. Podrá definir reglas que determinen aquellos momentos en los que se necesitan más (o menos) instancias de servidor, como por ejemplo: 3 Auto Scaling puede aplicarse en una serie de situaciones. Este documento va a analizar cómo puede aplicarse en un entorno de tolerancia a fallos. 7 Amazon Web Services – Creación de aplicaciones tolerantes a fallos en AWS Mayo de 2010 1. Cuando el número de instancias de servidor en funcionamiento se encuentre por encima de (o por debajo de) un número determinado, ejecutar (o finalizar) instancias de servidor 2. Cuando la utilización de recursos (es decir, CPU, red o disco) de la flota de instancias de servidor se encuentre por encima (o por debajo) de un umbral determinado, ejecutar (o finalizar) instancias de servidor. El servicio Amazon CloudWatch, que supervisa las instancias de Amazon EC2, recopilará estas métricas. Auto Scaling le permite finalizar instancias de servidor cuando lo desee, con la tranquilidad que supone saber que se ejecutarán de forma automática instancias de sustitución. Auto Scaling le permite además añadir más instancias como respuesta al aumento de carga, y cuando estas instancias ya no sean necesarias, se finalizarán de forma automática. Estas reglas le permiten implementar con gran facilidad varios patrones de redundancia tradicionales. Por ejemplo, la "redundancia N + 1"4 es una estrategia muy popular a la hora de garantizar que un recurso (como, por ejemplo, una base de datos) está siempre disponible. El enfoque "N + 1" dicta que debe haber N+1 recursos operativos, en una situación en la que N recursos son suficientes para gestionar la carga prevista. Este enfoque resulta idóneo para Auto Scaling. Para implementar N + 1 con Auto Scaling, simplemente debe definir una regla que indica que siempre debe haber un mínimo 2 instancias disponibles de una AMI determinada. Cuando se utiliza de forma conjunta con Elastic Load Balancing (Equilibrado de carga elástico), cada instancia gestionaría una parte de la carga entrante, con capacidad libre suficiente en cada instancia para gestionar toda la carga, en caso de que fuera necesario. Si una instancia falla, Auto Scaling ejecutará de forma automática una instancia de sustitución, dado que se ha infringido el umbral mínimo de 2 instancias. Auto Scaling le asegura que tendrá en todo momento 2 instancias de servidor en buen estado de funcionamiento disponibles. Dado que Auto Scaling detectará automáticamente fallos y ejecutará instancias de sustitución, si una instancia no se comporta tal y como se espera (p. ej., está en funcionamiento pero con bajos niveles de rendimiento), podrá simplemente finalizar dicha instancia y se ejecutará una nueva. Mediante la utilización de la función Auto Scaling podrá (y deberá) cambiar las instancias en funcionamiento de forma regular para asegurarse de que las fugas de memoria o la degradación no afecta a su aplicación. Podrá, literalmente, establecer fechas de caducidad de sus instancias de servidor para asegurarse de que permanecen en perfecto estado. Con el enfoque "N+1" también puede permitir que el servidor adicional acepte peticiones. Esto permite que su aplicación realice la migración de forma transparente en caso de que el servidor principal falle. La función Elastic Load Balancing (Equilibrado de carga elástico) de Amazon EC2 es una forma ideal de equilibrar la carga entre sus servidores. Elastic Load Balancing (Equilibrado de carga elástico) Elastic Load Balancing es un producto de AWS que distribuye el tráfico entrante en su aplicación entre diversas instancias de Amazon EC2. Cuando utiliza Elastic Load Balancing, recibe un nombre de host DNS, y todas las solicitudes enviadas a este nombre de host se delegan en un conjunto de instancias de Amazon EC2. 4 http://en.wikipedia.org/wiki/N%2B1_redundancy (en inglés) 8 Amazon Web Services – Creación de aplicaciones tolerantes a fallos en AWS Mayo de 2010 Incoming Traffic Elastic Load Balancing Delegated to Amazon EC2 Instances Ilustración 5 -‐ Elastic Load Balancing Elastic Load Balancing detecta instancias en mal estado dentro de su conjunto de instancias de Amazon EC2 y redirige automáticamente el tráfico hacia las instancias que se encuentran en buen estado hasta que se restauren las instancias en buen estado. Auto Scaling y Elastic Load Balancing son la combinación perfecta: Elastic Load Balancing le proporcionan un único nombre de DNS para el direccionamiento, mientras que Auto Scaling le garantiza que siempre está disponible el número adecuado de instancias de Amazon EC2 en buen estado para aceptar solicitudes. Reserved Instances (Instancias reservadas) Todas las técnicas que hemos tratado hasta ahora se basan en la suposición de que el usuario tiene la capacidad de obtener las instancias de Amazon EC2 siempre que las necesite. Amazon Web Services cuenta con una cantidad enorme de recursos de hardware, pero como cualquier proveedor de servicios informáticos de nube, estos recursos no son ilimitados. La mejor forma que tienen los usuarios de maximizar su acceso a estos recursos es reservando una parte de la capacidad informática que necesitan. Esto puede realizarse mediante una función denominada Reserved Instances (Instancias reservadas). Con Reserved Instances, el usuario literalmente reserva capacidad informática en la nube de Amazon Web Services. De esta forma consigue un precio más bajo, pero lo que es aún más importante dentro del contexto de la tolerancia a fallos, aumentará al máximo las posibilidades de obtener la capacidad informática que necesite. Regiones y zonas de disponibilidad Otro de los elementos que goza de una enorme importancia a la hora de conseguir una mayor tolerancia a fallos es la distribución de su aplicación de forma geográfica. Si, por cualquier motivo, un centro de datos de Amazon Web Services falla, podrá proteger su aplicación ejecutándola de forma simultánea en un centro de datos que se encuentre en otra ubicación geográfica. 9 Amazon Web Services – Creación de aplicaciones tolerantes a fallos en AWS Mayo de 2010 Amazon Web Services están disponibles en Regiones geográficas. Cuando utiliza AWS puede especificar la Región en la que desea que se almacenen sus datos, se ejecuten sus instancias, se inicien las colas y se creen las instancias de las bases de datos. Para la mayoría de nuestros servicios de infraestructura de AWS, incluido Amazon EC2, existen (en el momento de la redacción de este documento) cuatro Regiones: Este de los EE. UU. (norte de Virginia), Oeste de los EE. UU. (norte de California), UE (Irlanda) y Pacífico Asiático (Singapur). Amazon S3 presenta una estructura de región ligeramente diferente: EE. UU. estándar, que engloba centros de datos dispersos por los Estados Unidos, Oeste de los EE. UU. (norte de California), UE (Irlanda) y Pacífico Asiático (Singapur). Dentro de cada Región existen Zonas de disponibilidad. Las Zonas de disponibilidad son regiones diferentes que están diseñadas para estar aisladas fallos que se produzcan en otras Zonas de disponibilidad, y que proporcionan conectividad de red de baja latencia a otras Zonas de disponibilidad de la misma Región. Mediante la ejecución de instancias en Zonas de disponibilidad independientes podrá proteger sus aplicaciones de fallos (en el improbable caso de que sucedan) que afecten a toda una zona. Las Regiones están compuestas por una o más Zonas de disponibilidad, están geográficamente dispersas y se encuentran en áreas geográficas o países independientes. El compromiso del contrato a nivel de servicio de Amazon EC2 es de una disponibilidad del 99,95% en cada Región de Amazon EC2. Las Direcciones IP elásticas juegan un papel fundamental en el diseño de una aplicación tolerante a fallos que abarca varias Zonas de disponibilidad. El mecanismo de conmutación por error puede redirigir con facilidad la dirección IP (y, por lo tanto, el tráfico entrante) para alejarla de una instancia o zona que falla hacia una instancia de sustitución. Para las Zonas de disponibilidad es importante particionar correctamente la funcionalidad. Las instancias redundantes de cada capa (p. ej., web, aplicación y base de datos) de una aplicación deben emplazarse en Zonas de disponibilidad diferentes. El objetivo que se busca es tener una copia independiente de cada pila de aplicaciones en dos o más Zonas de disponibilidad. El siguiente diagrama de arquitectura muestra el particionamiento de funcionalidad que se desea. Requests from Internet Ability to remap EIP on failure Elastic Load Balancer Elastic IP Address Ability to remap EIP on failure Distribute load across multiple Availability Zones (detects unhealthy application stacks) X Independent Independent avoid Application unnecessary Application Stack Stack dependencies Independent Application Stack Application (Replacement) Application (Active) Application (Standby) EBS Volume EBS Volume On failure: replace instance, re-attach volume Ability to fail over Replicated Data Layer Replicated Data Layer Replicated Data Layer Availability Zone A Availability Zone B Availability Zone m Availability Zone A Availability Zone B Snapshot Elastic Load Balancing and multiple Availability Zones Amazon S3 Elastic IP Address and multiple Availability Zones Ilustración 6: Aprovechamiento de varias Zonas de disponibilidad 10 Amazon Web Services – Creación de aplicaciones tolerantes a fallos en AWS Mayo de 2010 Puede crear aplicaciones tolerantes a fallos emplazando sus instancias de Amazon EC2 en varias Zonas de disponibilidad. Para conseguir aún más tolerancia a fallos con menos intervención manual puede utilizar la función Elastic Load Balancing. Podrá conseguir mayor tolerancia a fallos emplazando sus instancias informáticas tras un Equilibrador de carga elástico, ya que puede equilibrar de forma automática el tráfico entre varias instancias y entre varias Zonas de disponibilidad, y asegurarse de que únicamente las instancias de Amazon EC2 que se encuentran en buen estado reciben tráfico. Podrá configurar un Equilibrador de carga elástico para que equilibre el tráfico entrante de una aplicación entre instancias de Amazon de EC2 dentro de una Zona de disponibilidad o varias Zonas de disponibilidad. La función Elastic Load Balancing puede detectar el estado de las instancias de Amazon EC2. Cuando detecta instancias de Amazon EC2 que presentan un estado incorrecto, deja de dirigir el tráfico hacia las instancias que no presentan buen estado. En lugar de ello, dispersa la carga entre las instancias restantes que se encuentran en buen estado. Si todas sus instancias de Amazon EC2 de una Zona de disponibilidad concreta presentan mal estado, pero ha configurado instancias en varias Zonas de disponibilidad, Elastic Load Balancing dirigirá el tráfico hacia las instancias de Amazon EC2 en buen estado que se encuentran en estas otras zonas. Reanudará el equilibrado de carga hacia las instancias de Amazon EC2 cuando se hayan restaurado a un estado correcto. Bloques de creación tolerantes a fallos Amazon EC2 y sus funciones relacionadas proporcionan una potente, aunque económica, plataforma en la que implementar y crear sus aplicaciones. Sin embargo, son solo uno de los aspectos de Amazon Web Services. Amazon Web Services ofrece una serie de productos que pueden incorporarse al desarrollo de sus aplicaciones. Estos servicios web son, de forma implícita, tolerantes a fallos, por lo que al utilizarlos aumentará la tolerancia a fallos de sus propias aplicaciones. Amazon Simple Queue Service (Servicio de cola sencilla de Amazon) Amazon Simple Queue Service (SQS) es un sistema de mensajería distribuida de gran fiabilidad que puede realizar las funciones de columna vertebral de su aplicación tolerante a fallos. Los mensajes se almacenan en colas que el usuario crea. Cada cola se define como una URL, de forma que pueda acceder a ella cualquier servidor que tenga acceso a Internet, sujeto a la Lista de control de acceso (ACL) de la cola. Podrá utilizar Amazon SQS para asegurarse de que su cola está siempre disponible; todos los mensajes que envíe a una cola se conservan durante un periodo de hasta cuatro días (o hasta que su aplicación lee y elimina el mensaje). A continuación se muestra una arquitectura de sistema canónica que hace uso de Amazon SQS. 11 Amazon Web Services – Creación de aplicaciones tolerantes a fallos en AWS message message message Mayo de 2010 message message message message message Amazon SQS message Worker message message Worker Worker Worker Worker Ilustración 7 -‐ Arquitectura de sistema Amazon SQS En este ejemplo se utiliza una cola Amazon SQS para aceptar solicitudes. Varias instancias de Amazon EC2 sondean de forma constante dicha cola, buscando solicitudes. Cuando se recibe una solicitud, una de estas instancias de Amazon EC2 recogerá dicha solicitud y la procesa. Cuando la instancia ha terminado de procesar la solicitud, vuelve al proceso de sondeo. Si el número de mensajes de una cola empieza a aumentar, o si el tiempo medio que tarda en procesar un mensaje empieza a ser demasiado elevado, podrá ampliar con solo añadir más trabajadores a instancias de Amazon EC2 adicionales. Es frecuente incorporar Auto Scaling para gestionar estas instancias de Amazon EC2 para asegurarse de que el suministro de instancias EC2 que ejecutan "trabajadores" que consumen mensajes de la cola es el adecuado. Incluso en una situación extrema en la que todos los procesos del trabajador hayan fallado, Amazon SQS simplemente almacenará los mensajes que reciba. Los mensajes se almacenan durante un periodo máximo de cuatro días, por lo que tendrá tiempo de sobra para ejecutar instancias de Amazon EC2 de sustitución. Una vez se recupere un mensaje de una cola SQS dejará de ser visible a otros consumidores durante un intervalo de tiempo configurable, conocido como tiempo de espera de visibilidad. Cuando el consumidor haya procesado el mensaje, deberá eliminarlo de la cola. Si el intervalo de tiempo especificado por el tiempo de espera de visibilidad se ha cumplido, pero no se ha eliminado el mensaje, volverá a ser visible en la cola y otro consumidor podrá recuperarlo y procesarlo. Este modelo de dos fase garantiza que no se pierden elementos de cola si la aplicación de consumo falla durante el procesamiento de un mensaje. 12 Amazon Web Services – Creación de aplicaciones tolerantes a fallos en AWS Mayo de 2010 Amazon Simple Storage Service (Servicio de almacenamiento sencillo de Amazon) Amazon Simple Storage Service (Amazon S3) es un servicio web aparentemente sencillo que proporciona almacenamiento de datos con tolerancia a fallos de alta resistencia. Amazon Web Services es responsable de mantener la disponibilidad y la tolerancia a fallos, el usuario simplemente paga por el almacenamiento que utiliza Entre bambalinas, Amazon S3 almacena los objetos de forma redundante en varios dispositivos en diversas instalaciones de una Región Amazon S3, para que incluso en el caso de que se produzca un fallo en un centro de datos de Amazon Web Service, siga pudiendo acceder a sus datos. Amazon S3 resulta ideal para cualquier tipo de necesidad de almacenamiento de datos que su aplicación pueda tener. Las URL acceden a Amazon S3 como Amazon SQS, de forma que cualquier recurso informático que tenga acceso a Internet puede utilizarlo. La función Control de versiones de Amazon S3 le permite conservar versiones anteriores de objetos almacenados en S3, además de protegerle de eliminaciones accidentales iniciadas por una aplicación que se comporta de forma incorrecta. El Control de versiones puede habilitarse en cualquiera de sus depósitos S3. Mediante la utilización de S3 podrá delegar la responsabilidad de uno de los aspectos vitales de la tolerancia a fallos, como es el almacenamiento de datos, a Amazon Web Services. Amazon SimpleDB Amazon SimpleDB es una solución de almacenamiento de datos estructurada resistente y tolerante a fallos. Con Amazon SimpleDB podrá decorar sus datos con atributos, y realizar consultas en estos datos en base a los valores de estos atributos. En diversas situaciones, Amazon SimpleDB puede utilizarse para aumentar o incluso sustituir su uso de bases de datos relacionales tradicionales como, por ejemplo MySQL o Microsoft SQL Server. Amazon SimpleDB presenta elevados niveles de disponibilidad, como Amazon S3 y el resto de servicios. Mediante la utilización de Amazon SimpleDB podrá sacar partido a un servicio escalable que ha sido diseñado para ofrecer elevados niveles de disponibilidad y tolerancia a fallos. Los datos almacenados en Amazon SimpleDB se almacenan de forma redundante, sin puntos únicos de error. Amazon Relational Database Service (Servicio de base de datos relacional de Amazon) Amazon Relational Database Service (Amazon RDS) es un servicio que facilita la ejecución de las bases de datos relacionales en la nube. En el contexto de creación de aplicaciones tolerantes a fallos y con alta disponibilidad, Amazon RDS ofrece diversas funciones diseñadas para mejorar la fiabilidad de las bases de datos más importantes. Las copias de seguridad automatizadas de su base de datos permiten la recuperación en puntos del tiempo de su instancia de base de datos. Amazon RDS realizará una copia de seguridad de sus registros de base de datos y de transacciones, y los almacenará durante un periodo de retención que puede especificar el usuario. Esta función está habilitada de forma predeterminada. De forma similar a las instantáneas de Amazon EBS, con Amazon RDS puede iniciar instantáneas de su instancia de base de datos. Amazon RDS almacenará estas copias de seguridad completas de la base de datos hasta que las elimine de forma explícita. Puede crear una nueva instancia de base de datos a partir de una Instantánea de base de datos donde desee. Esto puede ayudarle a recuperar de errores de más alto nivel, como por ejemplo eliminación de datos no intencionada, derivados tanto de errores del operador como de fallos de la aplicación. 13 Amazon Web Services – Creación de aplicaciones tolerantes a fallos en AWS Mayo de 2010 Amazon RDS admite también una función de implementación de Multi-‐AZ (Varias zonas de disponibilidad). Si esta función está habilitada, se aprovisionará una réplica en espera síncrona de su base de datos en una Zona de disponibilidad diferente. Las actualizaciones de su Instancia de base de datos se replicarán de forma síncrona de las Zonas de disponibilidad a en espera, para mantener ambas bases de datos sincronizadas. En caso de producirse una situación de conmutación por error, la instancia en espera pasará a ser la instancia principal, y gestionará las operaciones de su base de datos. La ejecución de su Instancia de base de datos como implementación Multi-‐AZ salvaguarda sus datos en el improbable caso de que se produzca un fallo en un componente de la Instancia de base de datos o de que se produzca un trastorno en el estado de servicio de una Zona de disponibilidad. Conclusión Amazon EC2 es el punto básico natural para el desarrollo de sus aplicaciones. Sus instancias de servidor son, en esencia, muy similares a los servidores tradicionales, y reduce en gran medida la curva de aprendizaje en el desarrollo de aplicaciones para la nube. Sin embargo, el uso de instancias de servidor de Amazon EC2 de la misma forma que instancias de servidor de hardware tradicionales es tan solo el punto de partida: esta práctica no mejorará su tolerancia a fallos, su rendimiento ni su coste total. El conjunto de ventajas de la plataforma Amazon Web Services adquiere sentido cuando incorpora más funciones de Amazon EC2, así como otros productos Amazon Web Services. Para poder crear aplicaciones tolerantes a fallos en Amazon EC2, es importante seguir prácticas recomendadas tales, como por ejemplo, ser capaz de poner en funcionamiento instancias de sustitución, utilizar Amazon EBS para contar con almacenamiento persistente, y sacar partido a múltiples Zonas de disponibilidad y direcciones IP elásticas. El uso de Auto Scaling le permite reducir en gran medida la cantidad de tiempo y recursos que necesita para supervisar sus servidores: si se produce un error, se ejecutará automáticamente una instancia de sustitución. El diagnóstico de un servidor en mal estado puede ser tan sencillo como detenerlo y dejar que Auto Scaling ejecute uno nuevo. Elastic Load Balancing le permite publicar un único punto final bien conocido para su aplicación. El EBB y el flujo de ejecución, error, finalización y reejecución de sus instancias de EC2 se realizará de forma transparente para sus usuarios. Amazon SQS, Amazon S3 y Amazon SimpleDB son bloques de creación de más alto nivel que puede incorporar a su aplicación. Estos servicios son ejemplos excelentes de cómo conseguir tolerancia a fallos, y a cambio aumentan la tolerancia a fallos de su aplicación. Con Amazon RDS tendrá acceso a funciones que crean implementaciones de bases de datos tolerantes a fallos, incluyendo copias de seguridad, instantáneas e implementaciones Multi-‐AZ. Por encima de todo esto, el modelo de precio de Amazon Web Services le da la opción de experimentar: no tiene que realizar ninguna inversión por adelantado, simplemente paga por lo que usa. Si le resulta que uno de los aspectos de la plataforma Amazon Web Services no es idóneo para su aplicación, su inversión finalizará en el momento en el que deje de utilizarlo. La potencia, sofisticación y transparencia económica que ofrece Amazon Web Services le proporcionan una plataforma sin parangón en la que poder crear su software tolerante a fallos. 14 Amazon Web Services – Creación de aplicaciones tolerantes a fallos en AWS Mayo de 2010 Más documentación 1. Best Practices for using Elastic IPs and Availability Zones (Prácticas de uso recomendadas de IP elásticas y Zonas de disponibilidad) -‐ http://support.rightscale.com/09-‐Clouds/AWS/02-‐ Amazon_EC2/Designing_Failover_Architectures_on_EC2/00-‐ Best_Practices_for_using_Elastic_IPs_%28EIP%29_and_Availability_Zones (en inglés) 2. Setting up Fault-‐tolerant site using Amazon’s Availability Zones (Configuración de un sitio tolerante a fallos con las Zonas de disponibilidad de Amazon) -‐ http://blog.rightscale.com/2008/03/26/setting-‐up-‐a-‐fault-‐ tolerant-‐site-‐using-‐amazons-‐availability-‐zones/ (en inglés) 3. Scalr -‐ https://scalr.net/login.php (en inglés) 4. Creating a virtual data center with Scalr and Amazon Web Services (Creación de un centro de datos virtual con Scalr y Amazon Web Services) -‐ http://scottmartin.net/2009/07/11/creating-‐a-‐virtual-‐datacenter-‐with-‐scalr-‐ and-‐amazon-‐web-‐services/ (en inglés) 5. Amazon Elastic Load Balancing (Equilibrado de carga elástico de Amazon) -‐ http://aws.amazon.com/elasticloadbalancing/ (en inglés) 6. Auto Scaling Service (Servicio Auto Scaling) – http://aws.amazon.com/autoscaling (en inglés) 7. Instance Types (Tipos de instancia) -‐ http://aws.amazon.com/ec2/instance-‐types/ (en inglés) 8. Elastic Block Store (Almacén de bloque elástico) -‐ http://aws.amazon.com/ebs/ (en inglés) 9. Amazon Machine Images Resources (Recursos de imagen de máquina de Amazon) -‐ http://developer.amazonwebservices.com/connect/kbcategory.jspa?categoryID=171 (en inglés) 10. Amazon Relational Database Service (Servicio de base de datos relacional de Amazon) -‐ http://aws.amazon.com/rds/ (en inglés) 15



© Copyright 2026