
Programación I - FCFM - Benemérita Universidad Autónoma de
Facultad de Ciencias Físico Matemáticas
Apuntes para la materia:
Programación I
M.I. Mónica Macías Pérez
Actualización: Primavera 2015
ÍNDICE
1
Preliminares, conceptos básicos
3
2
Concepto de algoritmo
7
3
Lenguajes de programación
8
4
Datos y expresiones en un programa
10
5
Proceso de resolución de problemas utilizando un lenguaje de programación 12
5.1 Fase de solución
12
5.2 Fase de implementación del diseño
16
6
Lenguaje C
18
7
Instrucciones de entrada y salida (E/S)
32
8
Estructuras secuenciales y selectivas
8.1 Estructura secuencial
8.2 Estructuras selectivas
8.2.1 Alternativa simple (si – entonces)
8.2.2 Alternativa doble (si entonces sino)
8.2.3 Alternativa múltiple (selector)
8.2.4 Alternativa múltiple
8.2.5 Estructuras de decisión anidadas o en cascada
8.2.6 Operador ternario
37
38
38
39
40
41
43
43
Estructuras repetitivas
Estructura mientras
9.1
Estructura hacer mientras
9.2
Estructura desde o para
9.3
Estructuras repetitivas anidadas
9.4
Instrucciones que alteran el flujo normal de un ciclo
9.5
45
45
47
48
50
50
9
10 Números pseudoaleatorios en el lenguaje C
51
11 Arreglos
11.1
11.2
54
55
58
Arreglos unidimensionales
Arreglos bidimensionales
12 Caracteres, cadenas de caracteres y arreglos de caracteres
Caracteres
12.1
Cadenas de caracteres
12.2
Arreglos de caracteres
12.3
62
66
69
13 Funciones
13.1
13.2
69
71
73
Funciones definidas por el usuario en el lenguaje C
Prototipo de funciones
1
13.3
13.4
13.5
14 Anexos
14.1
15 Referencias
Paso de parámetros por valor y por referencia
Reglas básica de alcance o ámbito (scope)
Variables locales y globales
77
81
82
Prácticas sanas de programación
84
87
2
1. PRELIMINARES, CONCEPTOS BÁSICOS
Computadora
Es un dispositivo electrónico capaz de ejecutar cálculos y tomar decisiones
lógicas a grandes velocidades, dotada de memoria y de métodos de tratamiento de
información, utilizando programas informáticos (Deitel & Deitel, 1995).
Hardware y software
Los varios dispositivos (como el teclado, la pantalla, los discos, la memoria,
etc.), circuitos electrónicos, cables, y otros elementos físicos que conforman la máquina
en sí y un sistema de computación se conocen como el hardware. Los programas de
computación que se ejecutan en una computadora se conocen como el software.
Dispositivos de entrada
Son aquellos que permiten ingresar datos a la máquina para poder ser
procesados. Ejemplos de ellos: micrófono, teclado, ratón, joystick1, lápices ópticos,
dispositivos touch, scanner, cámaras, etc.
Dispositivos de salida
Son aquellos que permiten visualizar los resultados de los datos transformados o
tratados en la computadora. Ejemplos: monitores, impresoras, bocinas, plotters
(dispositivo que permite dibujar o representar diagramas y gráficos), fax, etc.
Organización de la computadora
Si no se toman en cuenta las diferencias en apariencia física, todas las
computadoras pueden ser divididas en seis unidades lógicas o secciones como se pude
observar en la figura 1 (Deitel & Deitel, 1995):
1. Unidad de entrada. Esta es la sección “de recepción” de la computadora.
Obtiene información (datos e instrucciones de computadora) a partir de varios
dispositivos de entrada y pone esta información a la disposición de las otras
unidades, de tal forma que la información pueda ser procesada. La mayor parte
de la información se introduce en las computadoras a través de teclados tipo
máquina de escribir, ratones, lectores de código de barras, etc. que son
propiamente los dispositivos de entrada.
2. Unidad de salida. Toma la información que ha sido procesada por la
computadora y la coloca en varios dispositivos de salida para dejar la
información disponible para su uso fuera de la computadora. La mayor parte de
la información sale de las computadoras mediante despliegues en pantallas o
mediante impresión en papel. Ejemplos de dispositivos de salida son: monitor,
impresora, plotters, sintetizador de voz, etc.
1
El joystick es una palanca o control de mando que se usa especialmente en consolas o programas
informáticos de videojuegos, el cual permite desplazar rápida y manualmente el cursor, un personaje, etc.
3
3. Unidad de memoria. Esta es la sección donde se almacenan por un corto o
largo periodo tanto los datos como las instrucciones.
Figura 1. Estructura funcional de un ordenador.
a. La memoria principal, primaria o central, también llamada de acceso
directo o interna trabaja a mayor velocidad que la memoria auxiliar, por
lo que se le conoce como de acceso rápido. Retiene información que ha
sido introducida a través de la unidad de entrada, de tal forma que esta
información pueda estar disponible de inmediato para su proceso cuando
sea necesario. También retiene información ya procesada hasta que dicha
información pueda ser colocada por la unidad de salida en dispositivos
de salida. Existe la memoria de lectura y escritura que es volátil,
conocida como RAM y la memoria de sólo lectura que es permanente,
conocida como ROM.
Para que un programa se ejecute, debe estar almacenado o cargado en la
memoria principal.
La memoria cuenta con una dirección o localidad y un valor o
contenido que se guarda en dichas localidades.
b. La memoria secundaria, auxiliar, externa o masiva es más lenta que la
anterior pero de mayor capacidad. Los datos y programas se suelen
almacenar aquí, para que cuando se ejecute varias veces un programa o
se utilicen repetidamente unos datos, no sea necesario introducirlos de
nuevo. Los programas o datos que no se estén utilizando de forma activa
por otras unidades, están por lo regular colocados en dispositivos de
4
almacenamiento secundario (como discos) en tanto se necesiten otra vez,
es posible que sean horas, días, meses o inclusive años después.
4. Unidad de procesamiento central (CPU). Esta es la sección “administrativa”
de la computadora, responsable (coordinadora) de la supervisión de la operación
de las demás secciones. El CPU le indica a la unidad de entrada cuándo debe
leerse la información y colocarse en la unidad de memoria, señala a la ALU
cuándo deberá utilizar información de la unidad de memoria en cálculos, y le
indica a la unidad de salida cuándo enviar información de la unidad de memoria
a ciertos dispositivos de salida.
5. Unidad aritmética y lógica (ALU). Esta es la sección de “fabricación” de la
computadora. Es responsable de la ejecución de cálculos como: suma, resta,
multiplicación y división. Contiene los mecanismos de decisión que permiten
que la computadora, por ejemplo, compare dos elementos existentes de la unidad
de memoria para determinar si son o no iguales.
6. Unidad de control. Detecta señales de estado procedentes de las distintas partes
del ordenador y genera señales de control dirigidas a todas las unidades para,
precisamente, controlar el funcionamiento de la máquina.
Capta de la memoria principal las instrucciones del programa que ejecuta el
ordenador, las decodifica2 (el concepto de codificar se explica más adelante en
este apartado) y las ejecuta una a una.
Contiene un reloj que sincroniza todas las operaciones elementales involucradas
en la ejecución de una instrucción. La frecuencia del reloj determina, en parte, la
velocidad de funcionamiento del ordenador.
Sistema operativo
El propósito de un sistema operativo es facilitar la utilización de los recursos de
la computadora: software y hardware). Permite ejecutar programas, realizar operaciones
de entrada y salida de los programas, detección y notificación de errores, manipulación
de archivos de todo tipo entre otras cosas. Ejemplos de sistemas operativos: MS-DOS,
OS/2, UNIX, SOLARIS, IRIX, GNU/Linux, Windows (3.x, 95, 98, NT, 2000, XP,
Vista, 7, 8, 10, Phone), MAC-OS, Android, etc.
Codificación de la información
Codificar es representar los elementos de un conjunto mediante los de otro, de
forma tal que, a cada elemento del primer conjunto le corresponda uno y sólo un
elemento distinto del segundo. Una codificación asocia signos con los elementos de un
conjunto a los que se les denomina significados. Por ejemplo, se codifican los números
del sistema decimal con los símbolos o signos {0, 1, 2, 3, 4, 5, 6, 7, 8, 9}, es decir, se
ponen en correspondencia los símbolos con cantidades (Marzal & Gracia, 2006).
2
Decodificar o descodificar es aplicar inversamente las reglas de su código a un mensaje codificado para
obtener la forma primitiva de este (DRAE, 2014).
5
Código binario o código máquina
La unidad básica de información en las computadoras es el bit (binary digit,
dígito binario) cuyos valores establecen una de dos posibilidades mutuamente
excluyentes. Los dígitos binarios 0 y 1 se usan para representar los dos estados posibles
de un bit particular.
Cualquier dato que se introduce en la computadora o que sea manipulado por
ella se codifica en su interior por una sucesión de ceros y unos (que físicamente se
presenta por corrientes eléctricas, campos magnéticos, etc.). Entonces puede asignarse
cualquier significado a un patrón de bits particular, en tanto esto se haga en forma
consistente, lo que le da el significado es la interpretación de un patrón de bits; así por
ejemplo, a un caracter le corresponde, según el código utilizado para representarlo, un
byte, que es el conjunto de 8 bits, es decir, un byte es el número de bits necesario para
almacenar un caracter. En la figura 2 se muestran ejemplos de representación en código
binario de algunos caracteres del teclado, concretamente, el abecedario.
A
B
C
D
E
F
01000001
01000010
01000011
01000100
01000101
01000110
G
H
I
J
K
L
01000111
01001000
01001001
01001010
01001011
01001100
M
N
Ñ
O
P
01001101
01001110
10100101
01001111
01010000
Q
R
S
T
U
01010001
01010010
01010011
01010100
01010101
V
W
X
Y
Z
01010110
01010111
01011000
01011001
01011010
Figura 2. Representación binaria del abecedario. (Berzal, s.f.)
Para medir la capacidad de almacenamiento de la computadora se utilizan
múltiplos del byte, como se observa en la tabla 1, y en la tabla 2 se presentan algunos
ejemplos del tamaño en bytes de ciertos tipos de datos.
Tabla 1. Algunos múltiplos del byte.
Unidad
Kilobyte
Megabyte
Gigabyte
Terabyte
Petabyte
Exabyte
Abreviación
1 Kb
1 Mb
1 Gb
1 Tb
1 Pb
1 Eb
Capacidad en bytes
210 bytes
220 bytes
230 bytes
240 bytes
250 bytes
260 bytes
1,024 bytes
1,048,576 bytes
1,073,741,824 bytes
1,099,511,627,776 bytes
1,125,899,906,842,624 bytes
11,529,215,046,068,46,976 bytes
Tabla 2. Ejemplos del tamaño en bytes de ciertos tipos de datos. (Berzal, s.f.)
Datos
Texto
Tamaño
1 novela de 200 páginas, 50 líneas por
800,000 bytes
página y 80 caracteres por línea
Aproximadamente:
780 Kb
6
Imagen en blanco y 1024x768 pixeles3, 1 bpp (bit
negro
píxel)
Imagen en color
1024x768 pixeles, 24 bpp (bit
píxel)
Sonido de baja calidad 3 minutos, 11000 muestras
segundo, 8 bits por muestra
Sonido de alta calidad 3 minutos, 44100 muestras
segundo, 12 bits por muestra,
canales (estéreo)
Video (Calidad DVD) 90 minutos, 25 fotogramas4
segundo,
750x576
pixeles
resolución, 24 bpp (bit por pixel)
por
por
por
por
dos
por
de
98,304 bytes
Menos de 100 Kb
2,359,296 bytes
Unos 2300 Kb
1,980,000 Kb
Casi 2 Mb
23,814,000 bytes
Casi 23 Mb
167,961,600,000
bytes
Menos de 160 Gb
En la entrada y salida de la computadora, los cambios de código se realizan de
forma automática para que las personas no tengan que introducir ni interpretar la
información codificada.
2. CONCEPTO DE ALGORITMO
Algoritmo
Es una secuencia ordenada, finita e inequívoca de pasos a seguir para resolver un
determinado problema, en otras palabras, es la descripción exacta y sin ambigüedades
de la secuencia de pasos elementales a aplicar para, a partir de los datos del problema
encontrar la solución buscada (Cairó, 2006).
Características de un algoritmo
Para que un algoritmo sea completo deberá contemplar todas las alternativas
lógicas posibles que las distintas combinaciones de valores de los datos puedan
presentar.
Cualquier problema puede tener diferentes formas de solución, es decir, de
construir el algoritmo, cada uno de ellos con sus ventajas e inconvenientes, por lo que,
se busca elegir el que cumpla una serie de características a la hora de programar (Cairó,
2006):
Finitud: el algoritmo debe terminar en algún momento, se dice que no debe
ciclarse, es decir, debe tener un número finito de pasos, independientemente de
su complejidad.
3
Un píxel, del inglés pixel es la superficie homogénea más pequeña de las que se componen una imagen,
que se define por su brillo y color (DRAE, 2014).
4
Fotograma es cada una de las imágenes que se suceden en una película cinematográfica. (DRAE, 2014).
7
Precisión: los pasos a seguir se deben indicar clara y ordenadamente.
Determinismo: si se sigue el algoritmo varias veces proporcionándole los
mismos datos, se deben obtener siempre los mismos resultados.
Eficiencia: al momento de traducirse a un lenguaje de programación, no debe
tardar mucho tiempo en ejecutarse el programa ni usar mucho espacio de la
memoria de la computadora.
3. LENGUAJES DE PROGRAMACIÓN
Programar
En el nivel más simple consiste en ingresar en la computadora una secuencia de
órdenes para lograr un cierto objetivo. Es elaborar programas para la resolución de
problemas empleando una computadora (DRAE, 2014).
Programa
Es la expresión de un algoritmo, que consiste en un conjunto de instrucciones
que la computadora puede entender y ejecutar. Es una serie de operaciones que realiza
la computadora para llegar a un resultado con un grupo de datos específicos. Ejemplos:
Programa de aplicación: desarrollado para llevar a cabo tareas específicas ya
sea de tipo administrativo, científico o de entretenimiento.
Programa de sistema: es más general que uno de aplicación, e independiente de
cualquier área específica de aplicación. Ejemplo: el sistema operativo.
Lenguaje de programación
Un lenguaje de programación es un conjunto de símbolos, junto con un conjunto
de reglas para combinar y utilizar dichos símbolos para expresar programas. Los
lenguajes de programación se componen de un léxico (conjunto de símbolos permitidos
o vocabulario), una sintaxis (reglas que indican cómo realizar las construcciones
correctas del lenguaje) y una semántica (reglas que permiten determinar el significado
de cualquier construcción del lenguaje) (Bermúdez et. al., 2003).
Un lenguaje de programación es un medio para expresar algoritmos y puede ser
tanto entendido por los humanos como interpretado por las computadoras.
Clasificación de los lenguajes de programación
El lenguaje máquina ordena a la máquina las operaciones fundamentales para
su funcionamiento. Consiste en la combinación de ceros y unos para formar las
8
órdenes entendibles por el hardware de la máquina. Es mucho más rápido que
los lenguajes de alto nivel. La desventaja es que son bastantes difíciles de
manejar y usar, además de tener enormes cantidades de instrucciones donde
encontrar un fallo es casi imposible y depende de la máquina que en ese
momento se esté manejando.
El lenguaje de bajo nivel (ensamblador) es un derivado del lenguaje máquina
y está formado por abreviaturas de letras y números llamadas nemotécnicos. Con
la aparición de este lenguaje se crearon los programas traductores para poder
pasar los programas escritos en lenguaje ensamblador a lenguaje máquina.
Como ventaja con respecto al código máquina es que se tiene menos
instrucciones, los programas creados ocupan menos memoria. Las desventajas
son que dependen totalmente de la máquina en la que se está usando, lo que
impide la transportabilidad de los programas (posibilidad de ejecutar un mismo
programa en diferentes máquinas o entornos sin hacer modificaciones
importantes).
Lenguajes de alto nivel son aquellos cuyo lenguaje es más cercano al que
utiliza una persona. Estos lenguajes permiten al programador olvidarse por
completo del funcionamiento interno de la computadora para la que están
diseñando el programa. Tan sólo necesitan de otros programas llamados
compiladores o intérpretes que entiendan las instrucciones como las
características de la máquina.
Ejemplos de lenguajes de alto nivel son: Fortran, Pascal, COBOL, SQL, C,
C++, SmallTalk, Java, LISP, PROLOG, ADA, MODULA-2, Basic, G, AutoLisp,
Python, etc. Estos a su vez se suelen clasificar de acuerdo a los tipos de
problemas que permiten resolver y el estilo de programación que fomentan.
Traductores de lenguaje
Cuando se escribe un programa en un lenguaje de alto nivel, el conjunto de
instrucciones y todo lo que lo conforma se le llama archivo fuente, código fuente o
programa fuente. Los traductores de lenguaje son programas que traducen a su vez los
programas fuente a código máquina y se dividen en:
Compiladores
Intérpretes
Un intérprete es un traductor que toma un programa fuente, traduce y ejecuta
cada instrucción o bloque lógico antes de traducir y ejecutar el siguiente, es decir lo
hace instrucción a instrucción (ver figura 3).
Un compilador es un programa que traduce los programas fuente a lenguaje
máquina y el programa traducido se le llama programa objeto o código objeto. El
compilador traduce instrucción a instrucción pero no las ejecuta.
9
La compilación y sus fases
Programa fuente
Intérprete
Traducción y ejecución línea a línea
Figura 3. Intérprete
La compilación es el proceso de traducción de programas fuente a programas
objeto, estos últimos normalmente conocidos como código máquina. Para conseguir el
programa final que se pude ejecutar se necesita de un programa llamado montador o
enlazador (linker), ver figura 4. En el apartado 6: Lenguaje C se detallarán las fases
que se siguen al momento de compilar para obtener de un programa fuente un programa
ejecutable.
Programa fuente
Compilador (traductor)
Programa objeto
Montador
Programa ejecutable en lenguaje máquina
Figura 4. Fases de compilación
4. DATOS Y EXPRESIONES EN UN PROGRAMA
Todo programa de computadora tiene dos entidades a considerar: los datos y el
programa en sí.
Un dato es la expresión general que describe a los objetos con los cuales opera
una computadora. Existen dos clases de datos: simples (sin estructura) y estructurados
(compuestos). La principal característica de los datos simples es que ocupan sólo una
casilla de memoria y los datos estructurados se caracterizan por el hecho de que con un
10
nombre se hace referencia a un grupo de casillas de memoria, es decir, un dato
estructurado tiene varios componentes.
Los distintos tipos de datos se representan en diferentes formas en la
computadora, a nivel de máquina, un dato es un conjunto o secuencia de bits (dígitos 0
y 1) pero los lenguajes de alto nivel usan los siguientes datos simples:
Numéricos:
o entero, llamado de punto o coma fija, y es un subconjunto finito de los
números enteros.
o real, llamado de coma flotante o punto flotante5, que consiste en un
subconjunto de los números reales.
Caracter: es un conjunto finito y ordenado de símbolos que la computadora
reconoce. Con éstos en sucesión se forman cadenas de caracteres.
Lógico o booleano, indican los dos posibles valores: verdadero o falso.
Por otro lado, los datos estructurados más conocidos son: arreglos, cadenas de
caracteres y registros (en apartados posteriores se revisarán los arreglos y las cadenas de
caracteres).
Las constantes son elementos cuyo valor no cambia durante todo el desarrollo
del algoritmo o durante la ejecución del programa, pueden ser enteras, reales, lógicas,
de caracter o de cadena.
Una variable es un elemento cuyo valor puede cambiar durante el desarrollo del
algoritmo o ejecución del programa. Son localidades de memoria en una computadora
que almacenan un valor. Dicho valor puede ser entero, real, lógico o caracter,
dependiendo del lenguaje que se utilice. Es de un cierto tipo y puede tomar únicamente
valores de ese tipo, es decir si es entera, no puede contener caracteres o reales, si es real
no puede tomar valores lógicos, etc. Si se intenta dar valor a una variable que no es de
su tipo, se genera un error de tipo.
Los nombres que se les asignan a los datos simples, por ejemplo: una variable o
constante, o a los datos estructurados, por ejemplo: un arreglo, se conocen como
identificadores. Un identificador se forma por medio de letras, dígitos y el caracter
guion bajo, comenzando siempre con un carácter ya sea en minúsculas o mayúsculas.
Ejemplos de identificadores que representan a variables de cierto tipo se muestran en la
tabla 3.
5
La representación coma flotante o punto flotante es una forma de notación científica usada por la
computadoras para representar números racionales extremadamente grandes y pequeños de una manera
eficiente y compacta con la que se puede realizar operaciones aritméticas.
11
Una expresión es una combinación de operadores, operandos, paréntesis y
nombres de funciones especiales. Los operandos pueden ser constantes, variables u
otras expresiones. Los operadores puedes ser símbolos de operación: aritméticos,
lógicos (AND, OR, NOT) y/o relacionales (>, <, >=, <=, =, < >).
Tabla 3. Identificadores de variables.
Nombre de la variable (Identificador)
altura
Valor
2
Tipo
Entero
base
5
Entero
Radio
2.5
Real
simbolo_1
‘a’
Caracter
Simbolo_2
‘#’
Caracter
5. PROCESO DE RESOLUCIÓN DE PROBLEMAS UTILIZANDO
UN LENGUAJE DE PROGRAMACIÓN
Pueden ser identificadas dos etapas en el proceso de resolución de problemas
utilizando un lenguaje de programación (Cairó, 2006):
1. Fase de solución
2. Fase de implementación del diseño en un lenguaje de programación
5.1 Fase de solución
Análisis del problema: en esta etapa se debe definir claramente el problema y
entender lo que se pide, se deben detectar los datos o elementos
que se tienen para usar, llamados datos de entrada, e identificar
los datos que se van a dar como salida o resultados.
Diseño o construcción de la solución: En este proceso se diseña o plantea el
algoritmo a utilizar, para esto se tienen diferentes herramientas:
descripciones narradas, diagramas o pseudocódigo.
Verificación del algoritmo (llamado también pruebas de escritorio) para
comprobar que el algoritmo es correcto para cualquier caso
posible. Se hace a mano siguiendo las instrucciones que se
plantearon en el algoritmo o bien usando algún software especial.
12
Diseño de un algoritmo
Los problemas complejos se pueden resolver eficazmente con la computadora
cuando se rompen en subproblemas que sean más fáciles de solucionar que el original.
Este método se suele denominar: divide y vencerás.
Descomponer el problema original en subproblemas más simples y, a
continuación, dividir esos subproblemas en otros más simples, que pueden ser
implementados para su solución en la computadora, se denomina diseño descendente
(top-down design). Normalmente, los pasos diseñados en el primer esbozo del algoritmo
son incompletos e indicarán sólo unos pocos pasos. Tras esta primera descripción, éstos
se amplían en una descripción más detallada con más pasos específicos. Este proceso se
denomina refinamiento del algoritmo. Para problemas más complejos se necesitan con
frecuencia diferentes niveles de refinamiento antes de que se pueda obtener un
algoritmo claro, preciso y completo (Bermúdez, et. al., 2003).
Las ventajas más importantes del diseño descendente son: el problema es más
comprensible al dividirse en partes más simples denominados módulos, las
modificaciones en dichos módulos son más sencillas de realizar y la comprobación del
problema es asequible. La programación de cada módulo se hace mediante:
programación estructurada.
La programación estructurada es un conjunto de técnicas para desarrollar
algoritmos fáciles de escribir, verificar, leer y modificar; aquí algunas de sus
características:
Tiene un solo punto de entrada y uno de salida.
Toda acción del algoritmo es accesible, es decir, existe al menos un camino que
va desde el inicio hasta el fin del algoritmo, se puede seguir y pasa a través de
dicha acción.
No posee lazos o bucles (ciclos) infinitos.
Ahora bien, un programa puede ser escrito utilizando únicamente tres tipos de
estructuras: secuencial (instrucciones que se dan paso a paso), selectiva (para tomar
decisiones) y repetitiva (para procesar un conjunto de datos); todas ellas se verán más
adelante.
Métodos para representar algoritmos
Existen tres métodos para representar un algoritmo: descripción narrada, diagramas
de flujo y pseudocódigo; a continuación se detalla cada uno de ellos.
Descripción narrada: consiste en hacer un relato de la solución en lenguaje
natural.
13
Pseudocódigo, utiliza palabras en lenguaje natural (generalmente inglés, aunque
también existe en castellano como el que se utiliza la herramienta de software
PSeInt, abreviatura de Pseudo Intérprete) reservados para representar una acción
en específico, similares a sus homónimas en los lenguajes de programación.
Diagrama de flujo, flowchart u ordinogramas: es la representación gráfica de
un algoritmo, es decir, representa la solución del problema utilizando símbolos
que tienen un significado único y específico. En la tabla 4 se presentan los
símbolos que satisfacen las recomendaciones de la International Organization
for Standardization (ISO) y el American National Standars Institute (ANSI)
(Cairó, 2006).
Actualmente existen diversas herramientas de software que permiten tanto
elaborar como probar el funcionamiento de un diagrama de flujo a través de
trazas, sirviendo además para el aprendizaje de algoritmos estructurados.
Ejemplos de estas herramientas son (Arellano, Nieva, Solar y Arista, 2012):
-
DFD (última actualización en octubre de 2008),
-
RAPTOR (acrónimo del inglés Rapid Algorithmic Prototyping Tool for
Ordered Reasoning; actualizado constantemente),
-
PSeInt (abreviatura de Pseudo Intérprete; facilita escribir algoritmos en
pseudocódigo generando el diagrama de flujo a partir de este; también se
actualiza constantemente),
-
Progranimate, etc.
Cada una de estas herramientas utiliza su propia simbología para algunos de los
significados que se presentan en la tabla 4, no respetando el estándar ISO y
ANSI, así, en la tabla 5 se muestran los símbolos equivalentes de las
herramientas DFD, RAPTOR y PSeInt
Tabla 4. Simbología en un diagrama de flujo según la ISO y el ANSI.
Símbolo
Significado
Símbolo
Significado
Se utiliza para marcar el
inicio y el fin del
diagrama de flujo.
Representa conexión de
una parte del diagrama
con otra parte del
diagrama entre páginas
diferentes.
Se utiliza para introducir
datos de entrada.
Expresa lectura.
Se utiliza para representar
la impresión de un
resultado, expresa salida
o escritura.
Expresa conexión de una
parte del diagrama con
otra parte de dicho
diagrama en una misma
página.
Representa un proceso, en
su interior se colocan
asignaciones, operaciones
aritméticas, etc.
14
selector
acciones
Flechas de dirección o
flujo del diagrama.
Flechas de dirección o
flujo del diagrama.
Se utiliza para
representar una decisión
múltiple, en su interior
se almacena un selector
y dependiendo de su
valor se sigue por una de
las ramas o caminos.
Representa una decisión,
en su interior se coloca
una condición y
dependiendo de la
evaluación se sigue uno u
otro camino.
Se utiliza para expresar
un módulo de un
problema (subproblema)
que hay que resolver
antes de continuar con el
flujo normal del
diagrama.
Se utiliza para representar
al ciclo for o para, es
decir, un conjunto de
acciones se repiten un
número determinado de
veces, según lo dicte la
condición especificada.
Se utiliza para representar
al ciclo hasta que: un
conjunto de acciones se
realizan mientras la
condición es falsa, o en
otras palabras, el ciclo
termina hasta que la
condición sea verdadera,
aunque al menos una vez
se realizan las acciones.
Se utiliza para
representar al ciclo while
o mientras, es decir, un
conjunto de acciones se
repiten mientras la
condición es verdadera.
acciones
acciones
Tabla 5. Simbología en un diagrama de flujo según DFD, RAPTOR y PSeInt.
Significado
Simbología DFD
Simbología RAPTOR
Simbología PSeInt
Entrada o
lectura
Salida o
escritura
Ciclo while o
mientras
MQ
acciones
Fin (MQ)
15
Para
Ciclo for o
para, no
existe en
RAPTOR
acciones
Fin (para)
Módulo de un
problema
(subproblema)
Decisión
múltiple, no
disponible ni
en DFD ni en
RAPTOR
Reglas para la construcción de un diagrama de flujo
Las siguientes reglas fueron tomadas de (Cairó, 2006).
1. Todo diagrama de flujo debe tener un inicio y un fin, construyéndose de arriba
hacia abajo (top-down) y de izquierda a derecha (right-toleft).
2. Las líneas utilizadas para indicar la dirección del flujo del diagrama deben ser
rectas: verticales u horizontales y estar conectadas a otros símbolos: lectura,
decisión, salida, proceso, etc., pero no pueden quedar sin apuntar a un símbolo.
3. La notación utilizada en el diagrama de flujo debe ser independiente del lenguaje
de programación a utilizarse. La solución presentada se puede escribir
posteriormente en diferentes lenguajes de programación.
4. Es conveniente colocar comentarios que ayuden a entender lo que se está
realizando.
5.2 Fase de implementación del diseño
16
Codificar o escribir el programa, traducir el algoritmo a un específico lenguaje
de programación (el concepto de codificar se revisó en el apartado 1:
Preliminares, conceptos básicos).
Ejecutar o correr el programa: que lleve a cabo cada una de las instrucciones
que lo conforman.
Verificar que funcione correctamente el programa.
Instrucciones generales de un programa
Tipo de instrucciones básicas que contiene cualquier lenguaje de programación:
1. Instrucciones de inicio/fin
2. Instrucciones de asignación
3. Instrucciones de lectura conocidas también como de entrada
4. Instrucciones de escritura conocidas también conocidas como de salida
5. Instrucciones de bifurcación o decisión
Elementos básicos de un programa:
1. Palabras reservadas son palabras que tienen un significado especial para un
compilador por lo que no pueden utilizarse para cualquier otro propósito distinto
para el que fueron identificadas.
2. Identificadores (por ejemplo: nombres de variables, constantes o funciones
declaradas por el usuario)
3. Caracteres especiales (por ejemplo: coma, apóstrofo, comillas, etc.)
4. Expresiones
5. Estructuras: secuenciales, selectivas, repetitivas
6. Contadores: variables cuyo valor se incrementa o decrementa en una cantidad
constante en cada iteración si se utilizan ciclos.
7. Acumuladores: variables cuya misión es almacenar cantidades resultantes de
sumas sucesivas. Realiza la misma función que un contador con la diferencia de
que el incremento o decremento de cada suma es variable en lugar de constante.
17
8. Interruptores o conmutadores (switch) a veces se les denomina indicadores o
banderas, son variables que puede tomar diversos valores a lo largo de la
ejecución del programa y que permite comunicar información de una parte a otra
del mismo. Los interruptores pueden tomar dos valores diferentes: 1 y 0
(encendido/apagado o abierto/cerrado).
Tipos de errores presentados en la fase de implementación
Errores de sintaxis. Esta clase de errores se presenta al momento de compilar el
programa, generalmente por cometer errores al escribir una instrucción o los
signos de puntuación correctos que violan la sintaxis con la que se escriben
programas en el lenguaje que se esté usando. De acuerdo al compilador que se
utilice, éste marca la línea donde se ha cometido el error y la clase de error para
poder corregirlo.
Errores lógicos. Estos se presentan al momento de ejecutar el programa, ya que
no obtenemos los resultados esperados porque el algoritmo que se planteó no fue
el correcto o porque la traducción o implementación al lenguaje de
programación utilizado no fue el adecuado, malinterpretando el algoritmo. Esta
clase de errores son más difíciles de corregir.
Errores en tiempo de ejecución. Estos errores se presentan al momento de
ejecutar o correr el programa, por ejemplo, si nuestro programa hace referencia
al lector de una memoria externa y dicho lector no está listo con una memoria,
entonces marcará un error; otro ejemplo sería si se espera que el usuario ingrese
un dato de tipo entero y lo que ingresa es un dato de tipo caracter o decimal,
entre otros ejemplos.
Warnings. No propiamente son errores, sino advertencias de que algo debería
cambiarse porque es obsoleto o puede causar conflictos.
6. LENGUAJE C
Historia breve del lenguaje C
El lenguaje C fue creado por el científico estadounidense Dennis Ritchie en
1972 como derivado de un lenguaje de programación conocido como B. Hacia finales
de los 70, el lenguaje C evolucionó a lo que hoy se le conoce como C tradicional y su
rápida expansión sobre varios tipos de computadoras, denominadas plataformas de
hardware, provocó muchas variantes que, aunque similares no eran compatibles. Esto
generó problemas para los desarrolladores de programas que necesitaban escribir
códigos que pudieran funcionar en varias plataformas. Por tanto, en 1989 se aprobó un
estándar para el lenguaje C con una definición no ambigua e independiente de la
máquina donde se desarrollara. El documento que plasma esto se conoce como
18
ANSI/ISO6 9899: 1990, por ello, esta versión se conoce como ANSI C, es la versión
estandarizada que se utiliza en todo el mundo (Deitel & Deitel, 1995).
Características generales del lenguaje C
Es un lenguaje de propósito general, es decir, puede ser usado para varios
propósitos como: cálculos matemáticos, crear sistemas operativos, manejar
bases de datos, comunicación entre computadoras, capturar datos, etc.
El código que produce es eficiente y cuenta con características de los lenguajes
de bajo nivel que permiten realizar implementaciones óptimas (rápidas).
Es portátil, es decir, los códigos o programas generados con el lenguaje pueden
ejecutarse en cualquier arquitectura de computadora o cualquier sistema
operativo con variantes mínimas.
Es estructural, en otras palabras, el programa se divide en subprogramas o
segmentos con estructuras simples de secuencia, selección e iteración.
Es sensitivo al (del) contexto, es decir, distingue instrucciones e identificadores
escritos en mayúsculas y minúsculas, por ejemplo, una variable identificada
como A, es diferente a la variable identificada como a, o bien, la instrucción If
no será reconocida por el compilador, más la instrucción if sí lo será.
A continuación se detallan las tres partes principales de las que consta todo
sistema en C:
Un entorno
Biblioteca estándar
El lenguaje en sí
Entorno
Existen diferentes IDEs (acrónimo del inglés: Integrated Development
Enviroment y en español: Entorno Integrado de Desarrollo) que incluyen o integran una
6
ANSI (American National Standards Institute) que corresponde al Instituto Nacional Estadounidense de
Estándares es una organización sin fines de lucro que supervisa el desarrollo de estándares para
productos, servicios, procesos y sistemas en los Estados Unidos. Es miembro de la Organización
Internacional para la Estandarización (ISO). También coordina estándares del país estadounidense con
estándares internacionales, de tal modo que los productos de dicho país puedan usarse en todo el mundo.
Esta organización aprueba estándares que se obtienen como fruto del desarrollo de tentativas de
estándares por parte de otras organizaciones, agencias gubernamentales, compañías y otras entidades.
Estos estándares aseguran que las características y las prestaciones de los productos son consistentes, es
decir, que la gente use dichos productos en los mismos términos y que esta categoría de productos se vea
afectada por las mismas pruebas de validez y calidad (Wikipedia, 2015).
19
interfaz visual con iconos, menús y ventanas, para trabajar con comodidad con un editor
de textos para escribir el código fuente en el lenguaje C, uno o varios compiladores,
enlazadores, depuradores y demás herramientas. Suelen presentar diferentes asistencias
para la escritura de programas, como: sugerencias de autocompletado, coloreado de la
sintaxis del código fuente, ayuda acerca del lenguaje, etc.
Es necesario recalcar que un IDE no es un compilador, este último es parte de
todo el IDE. Ejemplos de IDEs son (Novara, 2010):
DevC++ (disponible sólo para el sistema operativo Windows),
Visual Studio (disponible sólo para el sistema operativo Windows),
Eclipse,
Monodevelop,
ZinjaI, (estos último tres disponibles para los sistemas operativos Windows,
Mac y GNU/Linux)
etc.
Ya sea que se utilice un IDE o no, en general, cuando se crea un programa en C
se siguen diferentes fases para obtener un código ejecutable a partir del código fuente.
La diferencia con utilizar un IDE está en que el usuario o programador no usa comandos
para llevar a cabo las diferentes fases, sino los iconos y menús que proporciona el
propio IDE.
En la figura 5 se pueden observar las diferentes fases que se siguen para obtener
un programa ejecutable. Primero, el programador escribe el programa en C utilizando
un editor de texto, generando con ello un archivo fuente con la extensión .c. Segundo,
se hace el llamado al compilador que traduce el programa fuente a código máquina, éste
conocido también como código objeto, pero justo antes de ello, el propio compilador
llama a un programa conocido como preprocesador, el cual manipula el programa
fuente, incluyendo otros archivos a compilar y reemplazando símbolos especiales con
texto de programa (por ejemplo, cambiando el nombre de una constante por su
correspondiente valor). Tercero, el compilador propiamente traduce el código fuente
para generar el código objeto, éste es un código aún no ejecutable pues generalmente,
estará incompleto. Cuarto y último, para obtener el código binario final, se ejecuta el
enlazador, el cual se encargará de vincular el código objeto con el código de las
funciones a las que se haya hecho referencia en el programa fuente pero cuyo código se
encuentra en otro u otros archivos, por ejemplo, en la biblioteca estándar (este concepto
será revisado en la siguiente sección de este apartado) o bibliotecas creadas por los
propios programadores (Deitel & Deitel, 1995).
Cabe mencionar que, cada IDE puede hacer uso de uno o varios tipos de
compiladores para C, entre los existentes están:
Borland C++
GCC
20
DJGPP
Miracle C
LCC Win 32
Intel C++ Compiler (conocido como ICC o ICL)
Mingw
Errores y warnings
(advertencias)
Compilador
Editor de
textos
Archivo fuente
.c
Preprocesador
Salida estándar
Código objeto
Archivo
binario
ejecutable
Enlazador
Salida estándar
Errores y warnings
(advertencias)
Figura 5. Fases para producir código ejecutable a partir de código fuente en C.
Biblioteca Estándar
La biblioteca estándar de C contiene una amplia colección de funciones que
resuelven problemas particulares y comunes, por ejemplo: cálculos matemáticos,
manipulación de cadenas o caracteres, detección de errores, mandar o recibir datos hacia
o desde los dispositivos de salida y entrada respectivamente, obtención de fecha y hora,
etc. Estas funciones mejoran tanto el rendimiento de los programas como la portabilidad
pero no forman parte en sí del lenguaje C (Deitel & Deitel, 1995). Las funciones que
pertenecen a la biblioteca estándar ayudan a ahorrar tiempo al programar, evitando que
se reescriba código para resolver un problema cuando la función ya existe, pues
permiten la reutilización de código.
Por otro lado, la biblioteca estándar hace uso de archivos de cabecera, los cuales
contienen tanto los prototipos de función de cada una de las funciones a las que hacen
referencia como las definiciones de varios tipos de datos y constantes requeridas para
dichas funciones. Un archivo de cabecera tiene un nombre con la extensión de archivo
.h y se incluye en un programa a través de la instrucción include como se detalla a
continuación.
#include <Nombre_del_archivo_de_cabecera.h>
Lo anterior, indica al preprocesador (concepto revisado en la sección Entorno de este
apartado) que incluya el archivo identificado por Nombre_del_archivo_de_cabecera.h,
el cual se delimita entre los símbolos < >, va seguido del carácter almohadilla y la
21
palabra reservada include. Ejemplos de nombres de archivos de cabecera son: stdio.h,
stdlib.h, math.h, string.h, time.h, cyte.h, errno.h, etc. Estos ficheros se encuentran
almacenados en el directorio por default o por defecto donde está almacenado el
compilador al momento de instalarlo.
El archivo de cabecera ctype.h contiene, por ejemplo, las funciones prototipo
que pueden ser utilizadas para convertir letras de minúsculas a mayúsculas o viceversa;
el archivo de cabecera math.h contiene prototipos para las funciones matemáticas
trigonométricas, raíz cuadrada, potencia, etc.; el archivo de cabecera stdlib.h contiene
entre otras cosas, prototipos de función para generar números aleatorios.
Ahora bien, un prototipo de función (el tema de funciones se verá a detalle en el
apartado 13: Funciones) es útil para: indicar al compilador el tipo de dato que regresará
la función (entero, real, caracter, etc.), la cantidad de argumentos que espera recibir la
función para procesarlos, así como el tipo y el orden en que la función espera recibir a
dichos argumentos. De esta forma, el compilador puede determinar errores por parte del
programador al momento de llamar a una función evitando problemas en tiempo de
ejecución de un programa (Deitel & Deitel, 1995).
Tanto en el resto de este apartado como en los apartados posteriores, se
describirán los elementos que conforman al lenguaje C.
Estructura de un programa
Todo programa en C está conformado por funciones (el tema de funciones será
revisado con mayor detalle en el apartado 13: Funciones), ya sean las que se
encuentran en la biblioteca estándar o las que son creadas por el propio programador
para resolver un problema en particular. Además, consta de una función indispensable
llamada main( ) a partir de donde el programa comienza a ejecutarse. Después,
contiene la llave izquierda que abre { para dar inicio al cuerpo de la función principal y
termina con la llave derecha que cierra }. Estas llaves y la porción de programa que
existe entre ellas se les conocen como bloque (Deitel & Deitel, 1995). Este bloque
puede estar constituido por varios elementos que conforman al lenguaje C: operadores
relacionales, de asignación, condicionales, variables, constantes, ciclos, etc., todos ellos
se revisarán a lo largo de este documento.
En general, un programa escrito en el lenguaje C puede contener las siguientes
secciones y/o elementos:
Sección include (se explicó en la sección Biblioteca Estándar de este mismo
apartado).
Cabe mencionar que, cuando se van a agregar funciones que no pertenecen a la
biblioteca estándar, sino que fueron elaboradas por el programador y forman
parte de un archivo de cabecera, entonces, esta sección tiene la siguiente
sintaxis:
#include “Nombre_del_archivo”
22
Como se ve, lo único que se modifica son los signos de mayor y menor que, por
las comillas dobles; el nombre del archivo de cabecera no precisamente debe
contener la extensión .h. Con esta forma se indican dos cosas al compilador: que
incluya el archivo especificado en el programa fuente y que dicho archivo se
encuentra en una ruta distinta a la que se tiene por defecto. Si entre comillas se
especifica la ruta además del nombre del archivo, entonces el compilador
buscará al archivo en esa ruta, pero si no se especifica, el compilador buscará al
archivo en el miso directorio donde se encuentra el fichero fuente.
Sección de declaración de constantes (se explicará más adelante en este
apartado) y tipos de datos estructurados.
Sección de declaración de variables globales (se explicará en el apartado 13:
Funciones).
Declaración de prototipo de funciones o forward (se explicará en el apartado
13: Funciones).
Si no existieran funciones prototipo, puede existir sólo un bloque de funciones
creadas por el programador.
Función main o función principal.
Si se declararon prototipo de funciones y la programación de cada función se
encuentra en el mismo archivo fuente, generalmente constituyen la sección final
del programa.
Ejemplo de una estructura:
/*Sección include, agregado de archivos de cabecera de la biblioteca
estándar*/
#include <stdio.h>
#include <stdlib.h>
#include <time.h>
/*Declaración de constantes*/
#define TAM 99
#define FREC 10
/*Prototipo de función*/
void moda(int []);
/*Función principal*/
int main( )
{
int i, respuestas[TAM];
srand(time(NULL));
23
for(i=0;i<TAM;i++) respuestas[i]=1 + (rand()%9);
moda(respuestas);
return 0;
}
/*Función declarada por el programador*/
void moda(int resultados[ ])
{
int i,j,mayor=0,posicion,frecuencia[FREC]={0};
for(i=0;i<TAM;i++)
++frecuencia[resultados[i]];
printf("\n%s%15s%15s\n","Respuesta", "Frecuencia","Histograma");
for(i=1;i<FREC;i++)
{
printf("%8d%10d
",i,frecuencia[i]);
if (frecuencia[i]>mayor)
{
mayor=frecuencia[i];
posicion=i;
}
for(j=1;j<=frecuencia[i];j++) printf("*");
printf("\n");
}
printf("\nLa moda es = %d y se repitio %d veces",
posicion,mayor);
return;
}
Identificadores
Son nombres dados a constantes, variables, funciones, tipos, etiquetas de un
programa, y están formados por una secuencia de letras (mayúsculas y/o minúsculas),
dígitos y el caracter guion bajo. El primer carácter de un identificador debe ser una letra
o el carácter de subrayado, y serán significativos los primeros 31 caracteres, toda
carácter más allá de este límite será ignorado por cualquier compilador (Ceballos,
1997).
Palabras clave o reservadas del lenguaje C
Existen un total de 32 palabras clave que están reservadas para uso exclusivo
del compilador C y que tienen un significado especial para dicho compilador, por lo que
no pueden utilizarse como identificadores. Algunas versiones de compiladores pueden
tener palabras adicionales (Ceballos, 1997).
Las palabras reservadas son:
24
Palabras que se refieren a los tipos de datos que se pueden utilizar: int,
float, long, double, short, char, unsigned,
signed, volatile, const, enum, static, typedef,
sizeof.
Palabras que se refieren a instrucciones que controlan el flujo de datos:
if, else, switch, case, default, break, for,
while, do, continue, goto.
Otras: struct,
void, auto.
return,
union,
register,
extern,
Tipos de dato estándar
Los tipos de datos básicos en el lenguaje C son:
1. caracter (que se declara con la palabra reservada char) para poder
manejar cualquier caracter del teclado;
2. real (que se declara con la palabras reservadas double o float) para
manejar números con parte decimal (1.7, 1.0923321e5, 33.092332e-3) y
3. entero (que se declara con la palabra reservada int) para manejar
números enteros.
Con el tipo de dato caracter, se puede formar una variable de tipo cadena, que es
una secuencia de caracteres entre comillas. La tabla 6 muestra una lista detallada de los
tipos de datos que existen en el lenguaje C.
Tabla 6. Tipos de datos estándar en el lenguaje C (Bermúdez et. al. , 2003).
Tipo de dato
char
Lo que representa
cualquier caracter del teclado, que se forma con la
combinación de 8 bits
unsigned char
cualquier caracter del teclado, que se forma con la
combinación de 8 bits
signed char
cualquier caracter del teclado, que se forma con la
combinación de 8 bits
int
un número entero dentro del intervalo cerrado [-32768,
32767] formado por la combinación de 16 bits
unsigned int
unsigned short
int
un número entero positivo dentro del intervalo cerrado [0,
65535] formado por la combinación de 16 bits
signed int
short int
un número entero dentro del intervalo cerrado [-32768,
32767] formado por la combinación de 16 bits
25
long int
un número entero dentro del intervalo cerrado [-2147483648,
2147483647] formado por la combinación de 32 bits
signed long int
un número entero dentro del intervalo cerrado [-2147483648,
2147483647] formado por la combinación de 32 bits
unsigned long
int
un número entero positivo dentro del intervalo cerrado [0,
4294967295] formado por la combinación de 32 bits
float
un número real dentro del intervalo cerrado [3.4E-38,
3.4E+38]
double
un número real dentro del intervalo cerrado [1.7E-308,
1.7E+308]
long double
un número real dentro del intervalo cerrado [1.7E-308,
1.7E+308]
Declaración de variables y constantes
Todas las variables que se vayan a utilizar en un programa deben declararse
antes de usarse. Una variable en C se declara de la siguiente manera:
tipo_de_dato
identificador_1, identificador_2, …, identificador_n ;
donde tipo_de_dato puede ser: int, char, double, etc.
Una constante en C se define de la siguiente manera:
#define
identificador
valor
donde valor puede ser un caracter, un número entero, real o una cadena.
Asignación simple
El signo de igualdad = es el operador básico de asignación. Con este operador
se inicializa el valor de una variable y se le cambia su valor a lo largo de un programa.
variable = expresión ;
Por ejemplo, i = 7;
donde la variable i toma el valor inicial de 7
NOTA IMPORTANTE: La inicialización de una variable en el mismo
momento en que es declarada reduce el tiempo de ejecución de un programa.
26
Proposiciones
Cuando una expresión va seguida de un punto y coma, se convierte en
proposición.
Ejemplos:
i = 7;
printf (“Hola”);
Operadores aritméticos
La tabla 7 muestra los operadores aritméticos permisibles en el lenguaje C.
Tabla 7. Operadores aritméticos (Bermúdez et. al. , 2003).
Operador
+
Operación que realiza
Suma enteros o reales
-
Resta enteros o reales
*
Multiplica enteros o reales
/
Divide enteros o reales. Si ambos operandos son enteros el resultado es
entero, en el resto de los casos el resultado es real
%
Devuelve el módulo o resto de la división de enteros solamente
El operando entero o real es multiplicado por -1
(unario)
Prioridad de los operadores
La tabla 8 muestra el orden de prioridad dado a cada operador aritmético y de
asignación.
Tabla 8. Prioridad de operadores aritméticos (Bermúdez et. al., 2003).
Operadores
-(unario)
Asociatividad
Derecha a izquierda
*
/
Izquierda a derecha
+
-
=
%
Izquierda a derecha
Derecha a izquierda
Operadores de relación y lógicos
27
Cada operador relacional toma dos expresiones como operando y da como
resultado el valor 0 o 1. En el lenguaje C cualquier valor distinto de 0 se considera
verdadero y el valor 0 se considera falso. La tabla 9 muestra los operadores
relacionales existentes en el lenguaje C.
Tabla 9. Operadores relacionales (Bermúdez et. al. , 2003).
Operador Operación
<
Primer operando menor que el
segundo
>
Primer operando mayor que el
segundo
<=
Primer operando menor o igual que
el segundo
>=
Primero operando mayor o igual que
el segundo
==
Primer operando igual que el
segundo
!=
Primer operando distinto del segundo
Ejemplos
a < 3
b > w
-7.7 <= 99.335
-1.3 >= (2.0 * x + 3.3)
c == ’w’
x != -2.5
Los operadores lógicos al igual que los operadores anteriores cuando se aplican
a expresiones producen los valores 0 o 1 de acuerdo a su tabla de verdad. La tabla 10
muestra los operadores lógicos existentes en el lenguaje C.
Tabla 10. Operadores lógicos (Bermúdez et. al. , 2003).
Operador Operación
Ejemplo
AND lógico. Da como resultado el valor
lógico 1 si ambos operandos son distintos de
&&
0. Si uno de ellos es 0 el resultado es el valor (z<x) && (y>w)
lógico 0.
||
OR lógico. El resultado es cero si ambos
operandos son cero. Si uno de los operándoos
(x ==y) || (z!=p)
tiene un valor distinto de 0, el resultado es 1.
!
NOT lógico. El resultado es 0 si el operando
tiene un valor distinto de cero, y 1 en caso !a
contrario.
Operadores de asignación
Además del operador de asignación simple presentado anteriormente, existen los
operadores de asignación que se muestran en la tabla 11.
28
Tabla 11. Operadores de asignación (Bermúdez et. al., 2003).
Operador Operación
Asignación simple
=
+=
Suma más asignación
-=
Resta más asignación
*=
Multiplicación más asignación
/=
División más asignación
%=
Módulo más asignación
++
Incremento
--
Decremento
Si expr1 y expr2 son expresiones y op un operador aritmético, entonces:
expr1 op= expr2
es equivalente a
expr1 = (expr1) op (expr2)
Ejemplos:
c += 3 es equivalente a c = c+3
k *= 3+x es equivalente a k = k*(3+x)
NOTA IMPORTANTE 1: una expresión con un operador de asignación (como
en c+=3) se compila más aprisa que la expresión equivalente expandida (c = c+3)
porque en la primera expresión, la variable c se evalúa únicamente una vez, en tanto que
en la segunda se evalúa dos veces.
NOTA IMPORTANTE 2: Los nombres de variables se dice que son lvalues
(por “left values”) porque pueden ser utilizados en el lado izquierdo de un operador de
asignación. Las constantes se dice que son rvalues (por “right values”) porque sólo
pueden ser utilizadas en el lado derecho de un operador de asignación. Los lvalues
también pueden ser utilizados como rvalues, pero no al revés.
Operadores incrementales y decrementales
Los operadores de incremento ++ y decremento -- son unarios y tienen la misma
prioridad que el operador unario -, éstos se asocian de derecha a izquierda. Tanto ++
como -- se pueden aplicar a variables pero no a constantes o expresiones. Además
pueden estar en la posición de prefijos o sufijos, con diferentes significados posibles.
Incremento: ++, añade o suma 1 a una variable
29
Decremento: --, resta 1 a una variable
Ejemplo:
x = x + 1 es equivalente a ++x
x = x - 1 es equivalente a --x
Estos operadores pueden ir antes o después de la variable:
1. Antes de la variable (preincremento o predecremento). Si el operador ++ o -aparece antes del operando entonces el operando se incrementa o decrementa
antes de que se evalúe la expresión
Ejemplo:
x = 10;
y = ++x;
después de esta evaluación: y = 11 y x = 11
2. Después del operando (postincremento o postdecremento). Si el operador ++ o
-- aparece después del operando, entonces primero se evalúa la expresión con el
valor actual del operando y posteriormente se incrementa o decrementa el
operando.
Ejemplo:
x = 10;
y = x++; después de esta evaluación: y = 10 y x = 11
Es importante hacer notar que al incrementar o decrementar una variable en un
enunciado por sí mismo, es decir, que no se encuentra involucrado con otras
expresiones, las formas de preincremento o predecremento, y postincremento o
postdecremento tienen el mismo efecto. Es decir:
++x;
x++;
son iguales
--x;
x--;
son iguales
Expresiones como ++(x+1) son un error, ya que sólo se utilizan de forma directa
en variables.
Por lo explicado anteriormente, los operadores de incremento y decremento al
afectar el valor de una variable, se les consideran operadores de asignación como se
listaron en la tabla 11.
Tabla de prioridad y orden de evaluación
La tabla 12 muestra el orden de prioridad más completo que el mostrado en la
tabla 7, considerando todos los operadores mencionados hasta ahora.
30
Tabla 12. Prioridad de operadores (Bermúdez et. al. , 2003).
Operadores
( )
Asociatividad
Izquierda a derecha
- (unario)
*
/
+
-
<
<=
==
++
--
!
%
Derecha a izquierda
Izquierda a derecha
Izquierda a derecha
>
>=
Izquierda a derecha
!=
Izquierda a derecha
&&
Izquierda a derecha
||
Izquierda a derecha
=
+=
-=
*=
%=
Derecha a izquierda
Ejemplos de prioridad de operadores: se declaran tres variables tipo entero y se les
asignan los siguientes valores, la tabla 13 muestra los valores resultantes de cada
variable según la operación realizada con cada una de ellas en forma secuencial:
int a,b,c,d;
a=2; b=-3; c=7; d=-19;
Tabla 13. Valores resultantes según expresiones aplicadas a las variables a, b, c y d (Bermúdez
et. al., 2003).
Expresión
Expresión equivalente
Valor resultante
a/b
b/b/a
c%a
a%b
d/b%a
-a*d
a%-b*c
9/c+-20/d
-d%c-b/a*5+5
0
0
1
2
0
38
14
2
15
7-a%(3+b)
(a / b)
(b/b)/a
(c%a)
(a%b)
(d/b)%a
(-a)*d
(a%(-b))*c
(9/c) + ((-20)/d)
(((-d)%c)((b/a)*5)) +5
7-(a%(3+b))
---a
a=b=c=-33
-(-(-a))
a=(b=(c=-33))
Error. Floating point exception,
puesto que no se puede dividir
entre el número cero
-2
a=-33
b=-33
c=-33
31
Símbolos para escribir comentarios en un programa
Lo programadores insertan comentarios para documentar los programas y
mejorar la legibilidad de estos. Los comentarios no hacen que la computadora lleve a
cabo acción alguna cuando se ejecute el programa, pues es tratado como texto simple,
no como enunciados, instrucciones o palabras reservadas. Los símbolos que nos
permiten hacer esto son:
/* cualquier_texto */
o bien:
// cualquier_texto
La diferencia entre ellos radica en que, el primero permite que el texto utilice
más de un renglón y el segundo sólo un renglón.
Ejemplo 1
Ejemplo 2
/* Programa que imprime un mensaje
en pantalla y muestra el uso de
comentarios */
#include <stdio.h>
#include <stdio.h>
int main( )
{
printf (“Ejemplo . . . ”);
int main( )
{
int i;//i sirve como contador
i = 10;
//Resto del programa
}
return 0;
}
7. INSTRUCCIONES DE ENTRADA Y SALIDA
Las operaciones de entrada y salida (abreviadas E/S en español o I/O en inglés)
permitir leer y escribir datos, a y desde archivos (también llamados ficheros), o bien,
dispositivos de entrada y salida en general, como lo es el teclado y la pantalla
respectivamente. Dichas operaciones no forman parte del conjunto de sentencias del
lenguaje C sino que pertenecen al conjunto de funciones de la biblioteca estándar de C
(la biblioteca estándar fue descrita en el apartado 6: Lenguaje C). Por lo tanto, todo
programa deberá contener la línea inicial: #include <stdio.h>. Esta línea le dice al
compilador que incluya el archivo de cabecera stdio.h (Standard Input Output Header)
en el programa permitiendo así usar las funciones que manipulan la entrada y salida de
datos (Ceballos, 1997).
32
Las siguientes funciones son algunas de las más utilizadas para entrada y salida
de datos: printf, scanf, getchar, putchar, puts y gets. Cada una de estas funciones tiene
una sintaxis que las identifica y en este apartado se explican únicamente: printf, scanf,
getchar y putchar. Tanto la función puts como gets se ven con más detalle en el
apartado 12: Caracteres, cadenas de caracteres y arreglos de caracteres.
Función printf( )
Se le llama instrucción de salida porque permite presentar información en un
dispositivo de salida, generalmente la pantalla, dando formato al texto o a los valores.
Su sintaxis es (Ceballos, 1997):
printf (cadena de control, lista de argumentos);
donde:
cadena de control especifica el texto que se mandará a pantalla y el formato que se le
dará tanto al texto como a los valores que se quieran presentar. Es una cadena de
caracteres delimitada por comillas dobles “ ” y formada por: texto, secuencias de escape
y especificaciones de formato.
Una secuencia de escape está formada por el carácter \ seguida de una letra o
combinación de dígitos que se utiliza para acciones como: salto de línea, tabular y
representar caracteres no imprimibles (ver tabla 14).
Una especificación de formato siempre comienza con el caracter % seguido de
una serie de símbolos para dar formato a la presentación de los valores, seguidos de una
o dos letras que especifica el tipo de datos que se mostrarán en pantalla: numéricos,
caracter, etc. (ver tabla 15). Cada especificación de formato debe corresponder con un
argumento en la lista de argumentos (la lista de argumentos se describe a continuación).
lista de argumentos representa el valor o valores a escribir en pantalla, estos pueden ser:
variables, constantes, resultados de evaluaciones de funciones o de evaluaciones de
distintas operaciones aritméticas; cuando es más de un argumento deben ir separados
por comas.
Tabla 14. Secuencias de escape para printf (Ceballos, 1997).
Secuencia Nombre
\n
\t
\v
\b
\r
Genera una nueva línea.
Genera una tabulación horizontal.
Genera una tabulación vertical.
Retrocede el cursor una posición borrando el caracter sobre el que
se posiciona.
Genera un retorno de carro, es decir, el cursor se posiciona al inicio
33
\a
\”
\\
de la línea donde se encuentra el cursor, por lo que, si se escribe
algún texto éste sobreescribirá a lo que ya exista en la línea.
Emite un sonido.
Imprime la comilla doble.
Imprime la barra hacia atrás conocida como diagonal invertida.
Tabla 15. Especificaciones de formato para printf (Ceballos, 1997).
Código
%d
%i
Formato
El argumento a mandar a un dispositivo de salida es un número entero
con signo en notación decimal
%u
El argumento a mandar a un dispositivo de salida es un número entero
sin signo, en notación decimal
%hd
%hi
El argumento a mandar a un dispositivo de salida es un número entero
corto, base 10
%hu
El argumento a mandar a un dispositivo de salida es un número entero
corto sin signo, base 10
%lu
El argumento a mandar a un dispositivo de salida es un número entero
largo sin signo, base 10
%ld
El argumento a mandar a un dispositivo de salida es un número entero
largo
%o
El argumento a mandar a un dispositivo de salida es un número entero
sin signo, en notación octal
%x,
%X
El argumento a mandar a un dispositivo de salida es un número entero
sin signo, en notación hexadecimal, minúscula o mayúscula
%g,
%G
Despliega en un dispositivo de salida un valor en punto flotante, ya sea
en forma de punto flotante f, o en la forma exponencial: e o E
%f
El argumento a mandar a un dispositivo de salida es un número real
(como flotante, con decimales), para tipo double y float
%Lf
El argumento a mandar a un dispositivo de salida es un número real
largo con signo
%e,
%E
%c
%s
El argumento a mandar a un dispositivo de salida es un número real
con notación científica en minúscula o mayúscula
El argumento a mandar a un dispositivo de salida es un solo carácter
El argumento a mandar a un dispositivo de salida es una cadena de
caracteres
34
%%
El argumento a mandar a un dispositivo de salida es el caracter signo
de tanto por ciento
%p
El argumento a mandar a un dispositivo de salida es el valor en
hexadecimal de la dirección física que ocupada una variable en la
memoria.
Función scanf( )
Permite leer o ingresar datos desde el teclado, por lo que se le conoce como una
instrucción de entrada. Su sintaxis es (Ceballos, 1997):
scanf (cadena de control, lista de argumentos);
donde:
cadena de control está formada por códigos de formato de entrada que están precedidos
por un signo % y delimitados por comillas “ ” para especificar el tipo de valor que se
leerá desde teclado (ver la tabla 16).
lista de argumentos que se forma con una o más variables que almacenarán el valor o
valores que se van a leer desde el teclado; cada nombre de variable debe ir precedida
por el carácter & (si las variables son de tipo numérico o caracter, no así con las de tipo
cadena) y separados por comas. Cuando se especifica más de un argumento, los valores
correspondientes en la entrada (al momento de teclearlos o introducirlos) hay que
separarlos por uno o más espacios en blanco, tabuladores o enter.
El carácter & (llamado ampersand), es conocido como el operador de
dirección en C. Al ser combinado con un nombre de variable, le indica a la
computadora la posición en memoria donde se almacenará el valor. La computadora
entonces almacena el valor en esa posición.
Tabla 16. Códigos de formato para scanf (Ceballos, 1997).
Código
Formato
%d
%hu
Lee desde el teclado un número entero base10
Lee desde el teclado un entero decimal, octal, hexadecimal,
opcionalmente signado
Lee desde teclado un número entero corto sin signo, base 10
%u
Lee desde el teclado un número entero sin signo, base 10
%o
Lee desde el teclado un número en octal
%x
Lee desde el teclado un número en hexadecimal
%i
35
%hd
%hi
%lu
%f
%e,
%E
%g,
%G
%ld
%li
%c
Lee desde el teclado un número entero corto, base 10
Lee desde el teclado un número entero largo sin signo, base 10
Lee desde el teclado un número real (como flotante, con
decimales)
Lee desde el teclado un número entero largo, base 10
%s
Lee desde el teclado un solo caracter
Lee desde el teclado una palabra o cadena de caracteres sin
espacios
%lf
Lee desde el teclado un número real (tipo double)
%Lf
Lee desde el teclado un número real largo (tipo long double)
Función getchar( )
Lee un único caracter desde el teclado (Cairó, 2006). Por ejemplo, el siguiente
código permitirá al usuario ingresar desde teclado un caracter y dicho caracter será
almacenado en la variable car.
car = getchar( );
Función putchar( )
Imprime un único caracter en la pantalla (Cairó, 2006). Por ejemplo, el siguiente
código mostrará en la pantalla el caracter que contenga la variable car.
putchar(car);
Buffer o memoria intermedia
Las funciones estándar de E/S tiene la característica fundamental de que la E/S
se realiza a través de un buffer o memoria intermedia. La utilización de un buffer o
memoria intermedia para realizar las operaciones de E/S es una técnica implementada
en software, diseñada para hacer las operaciones de E/S más eficientes (Ceballos, 1997).
Un buffer es un área de datos en la memoria RAM asignada por el programa que
se está ejecutando y que abre automáticamente cinco archivos:
stdin: dispositivo de entrada estándar (teclado)
stdout: dispositivo de salida estándar (pantalla)
36
stderr: dispositivo de error estándar (pantalla)
sdtaux: dispositivo auxiliar estándar (puerto serie)
stdprn: dispositivo de impresión estándar (impresora paralelo)
De estos cinco, dos de ellos, el dispositivo serie y el de impresión paralela,
dependen de la configuración de la máquina, por lo tanto pueden no estar presentes.
Las funciones scanf y getchar tienen una característica común: leen los datos
requeridos de la entrada estándar referenciada por stdin. Es necesario tener presente que
los datos, cuando son tecleados no son leídos directamente del dispositivo, sino que
éstos son depositados en la memoria intermedia buffer, asociada con el dispositivo de
entrada. Los datos son leídos de la memoria intermedia cuando son validados, esto
ocurre cada vez que pulsamos la tecla Enter.
Las funciones scanf y getchar interpretan el carácter \n (nueva línea) como un
separador. Al pulsar Enter se transmiten en realidad dos caracteres CR + LF (en el
sistema operativo GNU/ Linux equivalen a un sólo carácter ‘\n’). Esto quiere decir que,
el caracter que actúa como separador es CR, quedando almacenado en el buffer
asociado con stdin, el caracter LF. Éste es un caracter válido para las funciones scanf y
getchar por lo que si se usan nuevamente estas funciones en el mismo programa no
esperan una nueva entrada desde teclado sino toman lo que ha quedado almacenado en
el buffer de entrada, es decir LF, generando problemas de lecturas no deseadas
(Ceballos, 1997).
La solución a lo anterior es limpiar el buffer asociado con stdin antes de una
lectura con las funciones scanf y getchar, por ejemplo, usando la función:
fflush(stdin) disponible en el sistema operativo Windows, o bien,
__fpurge(stdin) disponible en el sistema operativo GNU/Linux.
En al apartado 12: Caracteres, cadenas de caracteres y arreglos de caracteres
se tratará a fondo el tema de los caracteres en el lenguaje C.
8. ESTRUCTURAS SECUENCIALES Y SELECTIVAS
8. 1 Estructura secuencial
Es aquella en la que una acción (instrucción) sigue a otra en secuencia o en
orden. La salida de una es la entrada de la siguiente y así sucesivamente (ver figura 6).
Dichas acciones puedes ser instrucciones de entrada, salida o proceso (Deitel & Deitel,
1995).
37
Acción 1
Acción 2
...
Acción n
Figura 6. Estructura secuencial
8. 2 Estructuras selectivas
Se utilizan para tomar decisiones lógicas. Se les llama estructuras de decisión o
alternativas. Pueden ser: simples, dobles o múltiples.
8.2.1 Alternativa simple (si-entonces)
Ejecuta una o varias acciones cuando se cumple una determinada condición, es
decir, se evalúa la condición y si ésta es verdadera se ejecuta la acción o acciones
específicas, pero si la condición es falsa entonces se hace nada como se muestra en la
figura 7.
condición
falso
verdadero
acciones
Figura 7. Alternativa simple
En el lenguaje C, la estructura de alternativa simple se especifica mediante la
instrucción if, cuya sintaxis se muestra a continuación.
if (expresión)
{
proposiciones;
}
proposición_siguiente;
38
donde la expresión debe ser de tipo numérica, relacional o lógica.
Si el resultado de evaluar expresión es verdadero entonces se ejecutarán las
proposiciones (que pueden ser una o varias instrucciones de entrada, salida, proceso,
otra condicional o ciclos) y después proposición_siguiente. Por otra parte, si el
resultado de la evaluación es falso entonces no se realiza ninguna acción y continúa el
flujo del programa a la siguiente línea de código proposición_siguiente.
Ahora bien, si se tiene sólo una proposición o instrucción a ejecutarse, no es
necesario colocar llaves para englobar la sentencia, pero si es más de una, sí son
necesarias.
8.2.2 Alternativa doble (si entonces sino)
Como se muestra en la figura 8, se ejecutará la acción o acciones S1 si al
evaluarse una condición ésta es verdadera, o bien se realizará la o las acciones S2 si la
condición es falsa, pero nunca ambas acciones (S1 y S2) al mismo tiempo.
verdadero
falso
condición
Acción S1
Acción S2
Figura 8. Alternativa doble
En el lenguaje C, la estructura de alternativa doble se especifica mediante la
instrucción if else, cuya sintaxis se muestra a continuación.
if (expresión)
{
proposiciones_1;
}
else
{
proposiciones_2;
}
proposición_siguiente;
donde la expresión debe ser de tipo numérica, relacional o lógica.
39
Si el resultado de evaluar expresión es verdadero entonces se ejecutarán las
proposiciones_1 (que puede ser una o varias instrucciones de entrada, salida, proceso,
otra condicional o ciclos). Por otro lado, si el resultado de la evaluación es falso
entonces no se realizarán proposiciones_1 sino que se ejecutarán las proposiciones_2
(que también pueden ser una o varias instrucciones de entrada, salida, proceso, otra
condicional o ciclos). Después de evaluarse la condición y ejecutarse lo pertinente si la
condición es verdadera o falsa se continúa con el flujo del programa a la siguiente línea
de código proposición_siguiente.
Al igual que en la alternativa simple, si se tiene sólo una proposición o
instrucción a ejecutarse, no es necesario colocar llaves para englobar la sentencias tanto
para el if como para el else, pero si es más de una, sí son necesarias.
8.2.3 Alternativa múltiple (selector)
La estructura de decisión múltiple (selector) evaluará únicamente el valor de una
variable que podría tomar n valores distintos. Según se elija uno de esos valores de la
variable, se realizará una y sólo una de las n acciones, o lo que es igual, el flujo del
algoritmo seguirá un determinado camino entre los n posibles como se muestra en la
figura 9 (Cairó, 2006).
valor n
valor1
variable
valor2
Acción 1
Acción 2
valor3
valor4
Acción n
Acción 4
Acción 3
…
Figura 9. Alternativa múltiple (selector)
En el lenguaje C, esta estructura se especifica como se muestra a continuación.
switch (expresión)
{
case constante1: sentencias1;
break;
case constante2: sentencias2;
break;
case constante3: sentencias3;
break;
…
default:
sentenciasN;
break;
40
}
donde expresión es una variable de tipo entera o caracter y sentencias puede ser una o
varias instrucciones de entrada, salida, proceso, condicionales o ciclos.
La sentencia switch evalúa la expresión entre paréntesis y compara su valor con
las constantes de cada case, si coincide la expresión con alguna constante entonces se
ejecutarán todas las sentencias después de los dos puntos de dicho case de coincidencia
hasta la instrucción break, es decir, la instrucción break permite salir de la estructura
switch y no continuar con la ejecución de las sentencias de otro case con el cual no
coindice el valor de la variable, por tanto, se debe utilizar la sentencia break para
concluir le ejecución de las sentencias en cada case.
En el caso de que ninguna de las constantes coincida con la expresión entonces
se ejecutarán la o las sentenciasN que se encuentran después de los dos puntos de la
palabra clave default. La sentencia switch puede incluir cualquier número de cláusulas
case y opcionalmente la cláusula default si no se requiere realizar algo en particular al
no coincidir el valor de la variable con algún valor especificado en los distintos case.
Las sentencias pueden ser una o varias instrucciones de entrada, salida, proceso, otra
condicional o ciclos.
8.2.4 Alternativa múltiple
En una estructura de decisión múltiple (no selectora) existe más de una
condición a evaluarse como se muestra en la figura 10 y funciona de la siguiente
manera. Primero se evalúa Condición1 y si ésta es verdadera entonces se ejecutan
Acciones1 y continua con AccionesSiguientes, pero si la condición es falsa entonces se
evalúa Condición2, nuevamente, si la Condición2 es verdadera entonces se realizan
Acciones2 y continua con AccionesSiguientes pero si la condición es falsa entonces se
repite el proceso anterior por cada condición que exista, de tal manera que si se llega a
la CondiciónN y ésta es verdadera entonces se realizan las AccionesN y después
AccionesSiguientes pero si la condición es falsa entonces se ejecutan AccionesDefault,
es decir, ésta o éstas instrucciones se llevarán a cabo si ninguna de las condiciones fue
verdadera.
En el lenguaje C, la estructura de alternativa múltiple (no selectora) se especifica
mediante la instrucción if else if cuya sintaxis se muestra a continuación.
if (expresión1)
{
sentencias1;
}
else if (expresión2)
{
sentencias2;
}
else if (expresión3)
{
sentencias3;
41
}
…
else
{
sentenciasN;
}
proposición_siguiente;
donde la expresión1, expresión2, expresión3, etc. deben ser de tipo numérica, relacional
o lógica. Si la expresión1 es verdadera se ejecutan las sentencias1 (que puede ser una o
varias instrucciones de entrada, salida, proceso, otra condicional o ciclos) y continúa
con proposición_siguiente, pero si la condición es falsa entonces se examina la
expresión2 y nuevamente, si ésta es verdadera entonces se ejecutan las sentencias2 (que
puede ser una o varias instrucciones de entrada, salida, proceso, otra condicional o
ciclos) para continuar con proposición_siguiente pero si la condición es falsa se evalúa
la tercera expresión y así sucesivamente hasta llegar al else, ejecutándose las
sentenciasN sólo si todas las expresiones fueron falsas para continuar con
proposición_siguiente.
Figura 10. Alternativa múltiple (no selectora).
42
Al igual que en la alternativa simple y doble, si se tiene sólo una proposición o
instrucción a ejecutarse, no es necesario colocar llaves para englobar la sentencia para
el if, else if y else, pero si es más de una, sí son necesarias.
8.2.5 Estructuras de decisión anidadas o en cascada
Las estructuras si interiores a otras se denominan anidadas, encajadas o en
cascada. Una estructura de selección de n alternativas o de decisión múltiple puede ser
construida utilizando una estructura si anidada, es decir unas interiores a otras formando
una cascada o escalera como se muestran en las figuras 11,12 y 13.
8.2.6. Operador ternario
En el lenguaje C existe un operador conocido como ternario, es decir, necesita
tres argumentos (de ahí su nombre) obligatorios, que no se pueden omitir. El operador
evalúa una condición de tal manera que si ésta es verdadera entonces se ejecuta una
única instrucción o sentencia, pero si la condición es falsa entonces se ejecuta otra única
instrucción, en otras palabras, con este operador, a diferencia de las otras instrucciones
condicionales descritas, sólo se ejecuta una instrucción pero no un conjunto de
instrucciones.
En el operador ternario se usa el caracter de interrogación que cierra para separar
la condición de la instrucción que se realizará si la condición es verdadera, y se usa el
caracter de dos puntos para separar la instrucción que se realizará si la condición es
verdadera de la instrucción que se realizará si la condición es falsa. Su sintaxis es como
se muestra a continuación.
expresión1? sentenciaV : sentenciaF
Si expresión1 es verdadera, entonces se ejecuta sentenciaV, pero si es falsa se ejecuta
sentenciaF.
La importancia de este operador radica en que se utiliza comúnmente en la
asignación que se le hace a una variable dependiendo del resultado de una condicional.
Con este uso, la condicional aparece del lado derecho de una asignación como se ilustra
en el siguiente ejemplo:
mayor = a>b ? a : b;
En la sentencia anterior, se evalúa la expresión a>b y si ésta es verdadera
entonces a la variable mayor se le asignará el valor de la variable a, pero si la expresión
es falsa entonces a la variable mayor se le asignará el valor de la variable b.
43
Figura 11. Ejemplo de estructuras selectivas anidadas 1.
Figura 12. Ejemplo de estructuras selectivas anidadas 2.
44
Figura 13. Ejemplo de estructuras selectivas anidadas 3.
9. ESTRUCTURAS REPETITIVAS
En la práctica, durante la solución de problemas, es muy común encontrar
operaciones que se deben ejecutar un número determinado de veces, si bien las
instrucciones son las mismas los datos varían (Cairó, 2006).
Las estructuras que repiten una secuencia de instrucciones un número
determinado de veces se denominan bucles, y se llama iteración al hecho de repetir la
ejecución de una secuencia de acciones. En un bucle o ciclo se deben tener en cuenta
qué es lo que contiene el bucle y cuántas veces se debe repetir.
Para detener la ejecución de los bucles se utiliza una condición de parada, ésta
condición puede especificarse al principio o al final del bucle según el problema a
resolver. Se tienen así tres tipos de estructuras repetitivas o iterativas:
1. La condición de salida del bucle se verifica al principio de dicho bucle, por lo
que el ciclo se realiza mientras se cumple una condición.
2. La condición de salida se origina al final del bucle; el bucle se ejecuta mientras
se verifica una cierta condición pero después de haberse ejecutado por lo menos
una vez la o las instrucciones.
3.
La condición de salida se verifica con un contador que cuenta el número de
iteraciones a realizarse.
9.1 Estructura mientras
45
Cuando se ejecuta la instrucción mientras, lo primero que se realiza es la
evaluación de la condición (una expresión booleana), si se evalúa como falsa entonces
ninguna acción se ejecuta dentro del bucle y el programa prosigue en la siguiente
instrucción fuera del bucle. Si la expresión booleana es verdadera entonces se ejecuta el
cuerpo del ciclo, después de lo cual se evalúa de nuevo la expresión booleana. Este
proceso se repite una y otra vez mientras la condición es verdadera (ver figura 14).
falso
condición
verdadero
acciones
Figura 14. Estructura mientras.
En éste tipo de ciclos puede suceder que nunca se ejecuten acciones si la
condición nunca es verdadera, o bien, puede darse un ciclo infinito si la condición
nunca se vuelve falsa.
Como un caso particular, si el problema que se resuelve requiere leer una lista de
valores con un bucle mientras, se debe incluir algún tipo de mecanismo para terminar el
bucle como se lista a continuación (Deitel & Deitel, 1995):
a. Preguntar al usuario antes de la iteración,
b. Saber de antemano el número de iteraciones exactas que se van a llevar a cabo,
c. Con un valor llamado centinela, que es un valor especial usado para indicar el
final de una lista de datos.
Ahora bien, en el lenguaje C, la estructura repetitiva mientras se especifica mediante
la instrucción while cuya sintaxis se muestra en seguida.
while (expresión)
{
sentencias1;
}
sentencias2;
donde expresión es cualquier expresión numérica, relacional o lógica. Puede ser
numérica puesto que cualquier valor diferente de cero se considera un valor booleno
verdadero, mientras que el cero se considera un valor booleano falso.
La instrucción ejecuta una sentencia simple o compuesta cero o más veces
dependiendo del valor de la expresión, es decir, se ejecutarán las instrucciones mientras
46
la expresión es verdadera, en el momento en que se convierte en falsa se ejecuta la línea
después del fin del while, es decir, sentencias2.
Si se tiene sólo una proposición o instrucción a ejecutarse, no es necesario
colocar llaves para englobar la sentencia del ciclo, pero si es más de una, sí son
necesarias.
9.2 Estructura hacer mientras
Esta estructura se utiliza cuando se debe ejecutar al menos una vez un bucle
antes de comprobar la condición de repetición (ver figura 15).
acciones
condición
verdadero
falso
Figura 15. Estructura repetir hacer mientras.
La estructura hacer mientras se ejecuta mientras una condición determinada es
verdadera, la cual se comprueba al final del bucle pero cuando la condición es falsa
continúa con las instrucciones fuera del ciclo.
La estructura es adecuada cuando no se sabe el número de veces que se debe
repetir un ciclo pero se sabe que se debe ejecutar por lo menos una vez, además es
eficiente para verificar los datos de entrada en un programa (Cairó, 2006).
En el lenguaje C, la estructura repetitiva hacer mientras se especifica con las
instrucciones do while como se muestra a continuación.
do
{
sentencias;
}while ( expresión );
La sentencia do while funciona de la siguiente manera: se ejecuta primero la
sentencia o bloque de sentencias después del do, luego se evalúa la expresión y si es
falsa termina la proposición do while pero si es verdadera (diferente de cero) entonces
se repite la sentencia o sentencias dentro del do{ }.
47
En esta estructura si se tiene sólo una proposición no es necesario colocar llaves
para englobar la sentencia a ejecutarse, pero si es más de una sí son necesarias.
9.3 Estructura desde o para
Esta estructura se utiliza cuando se sabe cuántas veces se desea ejecutar las
acciones de un ciclo. Se utiliza para repetir un conjunto de instrucciones un número
definido de veces. Comienza con un valor inicial de la variable llamada índice y las
acciones especificadas se ejecutan a menos que el valor inicial sea mayor que el final
cuando la variable índice sufre incrementos, o bien se detiene si la variable índice es
menor que el final si la variable índice sufre decrementos, (Cairó, 2006) como se
aprecia en las figuras 16 y 17.
NOTA IMPORTANTE: toda estructura desde o para se puede sustituir por una
estructura mientras, y viceversa, sin embargo, se recomienda aplicar la estructura desde
o para sólo en aquellos problemas en los que se conoce previamente el número de veces
que se debe repetir el ciclo, y utilizar las estructura mientras en aquellos problemas en
que el número de veces que se tenga que repetir el ciclo dependa de la condición a
evaluar y no de un número determinado de veces.
En el lenguaje C, la estructura repetitiva desde o para se especifica con la
instrucción for como se muestra a continuación.
for (inicialización; condición; incremente/decremento)
{
Sentencias1;
}
Sentencias2;
donde:
inicialización es una proposición de asignación que se utiliza para establecer la variable
de control o índice. Se pueden utilizar varias variables de control en un ciclo de
repetición for, por lo que al inicializar más de una variable, éstas se separan por comas.
condición es una expresión relacional o lógica que determina cuándo terminará el ciclo
de repetición e
incremento/decremento define cómo cambiará la variable de control (variable índice) o
las variables de control (si hay más de una) en cada repetición; dichos cambios
generalmente son incrementos o decrementos sobre las variables índice.
Las tres partes que conforman el encabezado del ciclo for (inicialización,
condición e incremento/decremento) tienen que estar separadas por puntos y comas
independientemente de que se omita la inicialización o el incremento/decremento, pues
estas dos partes sí pueden omitirse no así la condición. Ahora bien, a pesar de que se
pueden omitir las dos partes antes mencionadas, se recomienda utilizar cada una de las
tres, es decir, se recomienda respetar la propia estructura de la instrucción. En caso de
omitir la inicialización, ésta se debe realizar en algún punto antes del ciclo; si lo que se
48
omite es el incremento/decremento, entonces éstos deben realizarse dentro del cuerpo de
la estructura for.
falso
falso
variable
índice >= o >
variable final
variable
índice <= o <
variable final
verdadero
verdadero
acciones
acciones
Incrementar
variable índice
Decrementar
variable índice
Figura 16. Estructura desde o para.
indicevi
indice <= o < o > o >= vf
indiceicremento o decremento
No
ivi
i <= o < o > o >= vf
iincremento o decremento
Si
Si
Acciones
Acciones
Figura 17. Otra forma de representar a la estructura desde o para (Bermúdez et. al., 2003).
Al igual que la estructura while y do while antes mencionadas, en la estructura
for, si se tiene sólo una proposición no es necesario colocar llaves para englobar la
sentencia a ejecutarse, pero si es más de una sí son necesarias.
Por último, como se explicó en la nota importante anterior de este apartado, todo
while tiene su equivalente en for y viceversa, a modo de ejemplo se presenta en seguida
el código equivalente.
49
Ejemplo de un ciclo for
for (expr1; expr2; expr3)
proposición;
Equivalencia con un ciclo while
expr1;
while(expr2){
proposición;
expr3;
}
9.4 Estructuras repetitivas anidadas
Como en las estructuras condicionales, es posible insertar un bucle dentro de
otro. La estructura interna debe estar incluida totalmente dentro de la externa y no puede
existir solapamiento. El anidamiento se puede dar entre mismas o diferentes estructuras
repetitivas, es decir, puede existir un ciclo mientras dentro de otro ciclo mientras, un
ciclo hacer mientras dentro de otro ciclo hacer mientras o un ciclo para dentro de otro
ciclo para; pero también, puede existir un ciclo mientras dentro de un ciclo para, un
ciclo hacer mientras dentro de un bucle mientras, o cualquier clase de combinación
dependiendo del problema a resolver.
Un ciclo interno completo se repetirá el número de veces que la condición del
ciclo externa sea verdadera. Por ejemplo, si se tuvieran dos anidamientos, es decir un
tercer ciclo dentro de un segundo y éste dentro de un primer ciclo, entonces el ciclo más
interno, o sea, el tercero, se ejecutará la cantidad de veces que sea verdadera la
condición del segundo ciclo multiplicado por la cantidad de veces que sea verdadera la
condición del primer ciclo; y el segundo bucle se ejecutará la cantidad de veces que la
condición del primer ciclo sea verdadera.
9.5 Instrucciones que alteran el flujo normal de un ciclo
En ocasiones es necesario disponer de instrucciones que permitan la salida en un
punto intermedio de cualquier bucle sin que se verifique la condición principal de dicho
bucle, es decir, salir del ciclo antes de llegar a la condición. Estas instrucciones sólo
están disponible en algunos lenguajes de programación y en general no es recomendable
usarlas, porque el programa no es tan legible o “limpio” como debe ser.
Sentencia break
Finaliza la ejecución de una proposición switch, for, while y do while en la cual
aparece dicha instrucción, saltándose la condición normal del ciclo de repetición.
Sentencia continue
Interrumpe la ejecución normal de un bucle (for, while y do while) pero no lo
finaliza, sino que, finaliza la iteración en curso, transfiriendo el control del programa a
la condicional del bucle, para decidir si se debe realizar una nueva iteración o no. Es
50
decir, continue termina la ejecución de la iteración actual de un bucle, pero no la
ejecución del bucle en sí como lo hace break. La instrucción continue evita que se
ejecuten las instrucciones que existan después de ella en la iteración del bucle, saltando
hasta la condicional.
Función exit( )
Otra forma de terminar un ciclo de repetición es utilizar la función exit. A
diferencia del break, terminará no sólo con la ejecución del bucle sino con la ejecución
del programa y regresa el control al sistema operativo.
10. NÚMEROS PSEUDOALEATORIOS EN EL LENGUAJE C
Existen multitud de problemas que requieren que una computadora simule el
comportamiento de un sistema con alguna variable o variables aleatorias, es decir, que
genere números cuyo orden no sea predecible y puedan considerarse al azar, por
ejemplo: el número de viajeros en una estación de autobuses, programación de juegos
(tirada de un dado), etc. Sin embargo, en la práctica, no existen números que, generados
por una computadora, sean realmente aleatorios, pues hay que tener en cuenta que una
computadora es una máquina determinista, es decir, determinada por las condiciones
iniciales y en la que no hay ni puede haber operaciones aleatorias puras. Pero, una
computadora sí puede generar números pseudoaleatorios (Rodríguez y Galindo, 2009).
Un número pseudoaleatorio es un número generado por la computadora que,
no es realmente aleatorio pero se comporta como si se hubiera producido al azar
(Rodríguez y Galindo, 2009).
El lenguaje C permite generar números pseudoaleatorios usando una de dos
funciones disponibles según en el sistema operativo en el que se esté trabajando: la
función random( ) en el sistema operativo GNU/Linux y la función rand( ) en el
sistema operativo Windows. Ambas funciones no necesitan un argumento entre
paréntesis y devuelven un número pseudoaleatorio entre los valores del intervalo
cerrado [0, RAND_MAX].
RAND_MAX es una constante del lenguaje C que equivale al menos al valor
32,767, que es lo máximo que se puede almacenar en una variable de tipo entero con
signo, aunque su valor depende de la biblioteca donde se haya implementado dicha
constante, es decir, depende del compilador que se esté utilizando (se habló de los
distintos tipos de compiladores para el lenguaje C en el apartado 6: Lenguaje C). El
valor 32,767 se encuentra en la mayoría de las bibliotecas, aunque se puede llegar a
encontrar como máximo el número: 2,147,483,647 (Rodríguez y Galindo, 2009).
Las funciones antes mencionadas generarán números pseudoaleatorios a partir
de un número inicial llamado semilla y, es con ese valor inicial que genera el primer
número, después, a partir de dicho número genera el segundo, con el segundo genera el
51
tercero y así sucesivamente hasta concluir con la cantidad de números pseudoaleatorios
que se necesiten producir.
Cuando se requiere cambiar el valor máximo del intervalo cerrado de números
pseudoaleatorios que da por default el lenguaje C, entonces se debe dimensionar
usando un factor de dimensionamiento, donde dicho factor determina el valor
máximo. Para ello, se usa la función que genera los números pseudoaleatorios seguida
del operador módulo y el factor de dimensionamiento antes mencionado. A
continuación se detalla el procedimiento suponiendo a n una variable entera como el
factor de dimensionamiento y proporcionada por el programador o usuario (Deitel &
Deitel, 1995):
random( ) % n
Es la sintaxis en el sistema operativo GNU/Linux para generar un número
pseudoaleatorio entre los valores del intervalo cerrado [0, n-1].
rand( ) % n
Es la sintaxis en el sistema operativo Windows para generar un número pseudoaleatorio
entre los valores del intervalo cerrado [0, n-1].
Ahora bien, cuando se requieren cambiar ambos valores del intervalo cerrado,
además del dimensionamiento, se debe llevar a cabo un desplazamiento. Suponiendo a
m y n como variables enteras proporcionadas por el programador o usuario y, m < n,
entonces:
random( ) % (n-m+1) + m
Es la sintaxis en el sistema operativo GNU/Linux para generar un número
pseudoaleatorio entre los valores del intervalo cerrado [m, n].
rand( ) % (n-m+1) + m
Es la sintaxis en el sistema operativo Windows para generar un número pseudoaleatorio
entre los valores del intervalo cerrado [m, n].
Ejemplos:
/*Se genera un número pseudoaleatorio en el sistema operativo GNU/Linux dentro del
intervalo cerrado [0, 7] y se almacena en la variable numero.*/
numero = random( ) % 8;
/*Se genera un número pseudoaleatorio en el sistema operativo GNU/Linux dentro del
intervalo cerrado [10, 50] y se almacena en la variable numero.*/
numero = random( ) % (50-10+1) + 10;
/*Se genera un número pseudoaleatorio en el sistema operativo Windows dentro del
intervalo cerrado [0, 7] y se almacena en la variable numero.*/
numero = rand( ) % 8;
52
/*Se genera un número pseudoaleatorio en el sistema operativo Windows dentro del
intervalo cerrado [10, 50] y se almacena en la variable numero.*/
numero = rand( ) % (50-10+1) + 10;
Ahora bien, en cada ejecución de un programa donde se usan las funciones antes
descritas, se obtiene la misma secuencia de números pseudoaleatorios porque la semilla
es un número fijo. Para evitar esto, se usa de la biblioteca stdlib.h la función
srandom( ) si se está trabajando en el sistema operativo GNU/Linux, o la función
srand( ) si se está trabajando en el sistema operativo Windows. Ambas funciones se
deben utilizar con un parámetro que servirá como semilla o número inicial. Si el
parámetro especificado es un número fijo (por ejemplo, una constante o un número
generado por las mismas funciones rand o random) se tiene el mismo problema, es
decir, se obtiene la misma secuencia de números pseudoaleatorios en cada corrida del
programa; para corregir esto, se puede hacer uso de alguna de las siguientes funciones:
-
Función time( ) del lenguaje C que se encuentra en la biblioteca time.h
Esta función devuelve la fecha y hora actual que tenga establecido el sistema
operativo.
La forma de utilizar la función descrita junto con la función srand o srandom
se muestra a continuación:
srandom( time(NULL) ) en el sistema operativo GNU/Linux, o
srand( time(NULL) ) en el sistema operativo Windows.
La función time( ) devuelve un valor en segundos correspondiente al instante
actual en que se ejecuta el programa, dicho valor se calcula a partir de las cero
horas del 1 de enero de 1970 (inicio en que se utilizó por primera vez el sistema
operativo Unix). En Windows también devuelve el tiempo en segundos
partiendo de un valor inicial7.
-
Función getpid( ) que se puede encontrar en las bibliotecas: sys/types.h o
unistd.h
Esta función devuelve el número de proceso que se le haya asignado al
programa que se está ejecutando actualmente, el cual siempre es distinto en cada
corrida de dicho programa.
La forma de utilizar la función descrita junto con la función srand o srandom
se muestra a continuación:
7
Nota: la función time( ) es de tipo long int. Un tipo de dato long int = 2,147,483,647; 1 año =
31,536,000 segundos, por lo que el valor máximo del long int se alcanzará aproximadamente el 18 de
febrero de 2038.
53
srandom( getpid( ) ) en el sistema operativo GNU/Linux, o
srand( getpid( ) ) en el sistema operativo Windows.
Por otra parte, la función drand48( ) se usa para obtener números
pseudoaleatorios con decimales y la función srand48( ) se usa para cambiar la semilla
de inicio, por lo que también puede hacer uso de time( ) y getpid( ) como se explicó
anteriormente. Estas funciones no se encuentran en el sistema operativo Windows.
Ejemplos:
numero = drand48( )*(20.0-10.0) + 10.0
numero = drand48( )*(n-m)+n
11. ARREGLOS
Introducción a las estructuras de datos
Una estructura de datos es una colección de datos simples que se caracterizan
por su organización y las operaciones que se definan en ella.
Datos simples
Estándar
Datos estructurados
Estáticos
Entero
Arreglos (vector o matriz)
Real
Registros
Caracter
Archivo o ficheros
Lógico
Conjuntos
Cadenas
Definido por el programador
Subrango
Enumerativo
Dinámicos
Listas (pilas o colas)
Listas enlazadas
Árboles
Grafos
Los tipos de datos simples o primitivos significan que no están compuestos de
otras estructuras de datos. Los más frecuentes y utilizados por casi todos los lenguajes
son: enteros, reales y caracter; siendo los tipos lógicos, subrango y enumerativos
propios de lenguajes estructurados como Pascal por ejemplo.
54
Los tipos de datos compuestos están construidos basándose en tipos de datos
primitivos, por ejemplo, las cadenas de caracteres están construidas por el tipo básico
caracter. Los tipos de datos compuestos pueden ser organizados en diferentes
estructuras de datos: estáticas o dinámicas.
Las estructuras de datos estáticas son aquellas en las que el tamaño ocupado en
memoria se define antes de que el programa se ejecute y no puede modificarse dicho
tamaño durante la ejecución del programa. Estas estructuras están implementadas en
casi todos los lenguajes de programación: arreglos, registros y ficheros o archivos.
Las estructuras de datos dinámicas no tienen las limitaciones o restricciones en
el tamaño de memoria ocupada. Mediante el uso de un tipo de dato específico,
denominado puntero, es posible construir estructuras de datos dinámicas que son
soportadas por la mayoría de los lenguajes. Las estructuras dinámicas por excelencia
son: listas, árboles y grafos.
Los tipos de datos simples tienen como característica común que cada variable
representa a un elemento, los tipos de datos estructurados tienen como característica
común que un identificador (nombre) puede representar múltiples datos individuales,
pudiendo cada uno de éstos ser referenciado independientemente.
En este curso se trabajan solamente estructuras de datos estáticas y en los
siguientes apartados se revisan en particular los arreglos.
Concepto de arreglo
Un arreglo es una colección finita, homogénea y ordenada de elementos, en otras
palabras, es una estructura compuesta por varios elementos, todos del mismo tipo
(entero, real, carácter o booleano) y almacenados consecutivamente en memoria. Cada
componente puede ser accedido directamente por el nombre del arreglo seguido de uno
o varios subíndices encerrados entre corchetes [ ] según sea la dimensión del arreglo; los
subíndices indican la posición de cada componente del arreglo y pueden ser únicamente
valores enteros positivos, variables tipo entero positivos o expresiones numéricas
enteras positivas (Cairó, 2006).
Existen 2 tipos de arreglos según su dimensión: unidimensional, porque para
acceder a un elemento del arreglo sólo se tiene que utilizar un índice; y
multidimensional, porque para acceder a un elemento del arreglo se utilizan múltiples
índices. Para este último tipo de arreglo, el más utilizado es el bidimensional, es decir,
el de dos dimensiones, por tanto, a continuación se describen el arreglo unidimensional
y el arreglo bidimensional.
11.1 Arreglos unidimensionales
El arreglo unidimensional, conocido también como vector, es una colección
finita, homogénea y ordenada de datos, en la que se hace referencia a cada elemento del
arreglo por medio de un índice. Este último indica la casilla en la que se encuentra el
elemento. Para hacer referencia a un componente de un arreglo se debe utilizar tanto el
55
nombre del arreglo como el índice del elemento (Cairó, 2006). En la figura 18 se puede
observar la representación gráfica de un arreglo unidimensional.
Figura 18. Representación gráfica de un arreglo unidimensional (Cairó, 2006).
En el lenguaje C, el arreglo unidimensional se declara de la siguiente manera:
tipo nombre[tamaño]
donde:
tipo es uno de los tipos predefinidos por el lenguaje: float, int, etc.
nombre: es un identificador que nombra el arreglo y sigue las mismas reglas
especificadas para dar nombre al identificador de una variable.
tamaño es una constante entera positiva que especifica el número de elementos
del arreglo.
En el lenguaje C, los arreglos unidimensionales inician en la posición cero [0],
por lo que la posición máxima del arreglo está dada por el número máximo de
elementos menos 1.
También, el lenguaje C no revisa los límites del arreglo unidimensional, por lo
que es responsabilidad del programador el realizar este tipo de operación para no
acceder a una posición negativa o mayor al límite de elementos.
Los elementos de un arreglo pueden ser inicializados en la declaración del
arreglo mismo, haciendo seguir a la declaración con el signo igual y una lista de valores
inicializadores separados por comas (la lista encerrada entre llaves).
Los elementos de un arreglo no son de forma automática inicializados a cero,
al menos que se inicialice el primer elemento a cero, para que los demás queden
automáticamente inicializados a ese valor.
Ejemplos de declaración e inicialización de arreglos unidimensionales (Cairó,
2006):
56
/*Declara un arreglo unidimensional llamado arreglo para
almacenar 10 elementos de tipo real o flotante de doble
precisión.*/
double arreglo[10];
/*Se declara el arreglo unidimensional llamado V con 10
elementos de tipo real y al mismo tiempo se inicializa cada
casilla del arreglo con cada uno de los valores que se
encuentran entre llaves y separados por comas. La
representación gráfica del arreglo V se muestra en la
figura 19.*/
float V[10] = {32.5,15.8, 70.1, 5.9, 0, -12.2, 13.3, 90.4,
56.6, -9.8};
Figura 19. Representación gráfica del vector V con 10 elementos de tipo real.
Si se quiere acceder al primer elemento del arreglo se debe escribir V[0], pero si se
quiere acceder al quinto elemento se debe escribir V[4]. Por otra parte, el valor de V[7]
es 90.4, el de V[3+5] es 56.6 y el resultado de V[2] + V[5] es 57.9.
/*Lo siguiente muestra un error de sintaxis porque se están
proporcionando más inicializadores de arreglo que elementos
existen dentro del mismo.*/
double Valores[5] = {32.1,27.3,64.4,18.6,95.7,14};
/*Si en la lista de inicialización se omite el tamaño del
arreglo, el número de elementos en el arreglo será el
número de elementos incluidos en la lista inicializadora.*/
int n[ ] = {1,2,3,4,5};
/*Si dentro del arreglo existe un número menor de
inicializadores que de elementos, los elementos restantes
son inicializados a cero automáticamente.*/
int A1[10] = {0};
/*El primer componente del arreglo se inicializa con el
número 5 y el resto con el número 0.*/
int B[5] = {5};
57
Una vez que se definen los arreglos, sus elementos pueden recibir valores a
través de múltiples asignaciones, o bien, como ocurre frecuentemente en la práctica, a
través de un ciclo, este último, generalmente un ciclo para o for, pues se conoce
previamente la cantidad de elementos que contiene el arreglo.
/*Ejemplo de asignación
declarado un arreglo. El
23.897*/
arreglo[0]=23.897
individual después de haber
primer valor de arreglo vale
Si las posiciones de un arreglo no son inicializados o no se les asigna
explícitamente un valor, se considera que almacenan “basura”, pues en memoria
siempre existen datos. No se debe olvidar almacenar datos en un arreglo antes de
realizar operaciones con ellos, tal como sucede con las variables.
Se pueden realizar distintas operaciones con arreglos unidimensionales durante
el proceso de resolución de un problema, pero generalmente se tiene:
Asignación
Lectura/escritura
Recorrido (acceso secuencial)
actualizar (añadir, borrar, insertar)
Ordenación
Búsqueda
Puesto que en un arreglo se trabaja más de un dato, generalmente las
operaciones antes listadas se tienen que realizar usando ciclos como se mencionó con la
inicialización.
11.2 Arreglos bidimensionales
El arreglo bidimensional se considera un vector de vectores, generalmente
llamado tabla (término financiero) o matriz. Formalmente es una colección finita,
homogénea y ordenada de datos, en la que se hace referencia a cada elemento del
arreglo por medio de dos índices, uno para indicar el renglón o fila y el segundo para
indicar la columna del arreglo (Cairó, 2006). La figura 20 muestra la representación
gráfica de un arreglo bidimensional.
58
Figura 20. Representación gráfica de un arreglo bidimensional (Cairó, 2006).
En el lenguaje C, la declaración de esta estructura es de la siguiente manera:
tipo nombre[num_renglones][num_columnas]
donde:
tipo es uno de los tipos predefinidos por el lenguaje: float, int, etc.
nombre: es un identificador que nombra el arreglo y sigue las mismas reglas
especificadas para dar nombre al identificador de una variable.
num_renglones es una constante entera positiva que especifica el número de filas
del arreglo.
num_columnas es una constante entera positiva que especifica el número de
columnas del arreglo.
En el lenguaje C, los arreglos bidimensionales inician en las posiciones [0][0],
por lo que la posición máxima del arreglo está dada por el número máximo de
renglones menos 1 con el número máximo de columnas menos 1. Suponiendo que se
tienen N renglones y M columnas, entonces la posición máxima está en [N-1][M-1],
además, se almacenarán N x M elementos del mismo tipo.
El lenguaje C no revisa los límites de un arreglo, es responsabilidad del
programador el realizar este tipo de operaciones para no acceder a una posición negativa
o mayor al límite de elementos tanto para los renglones como para las columnas.
59
Los elementos de un arreglo bidimensional no son de forma automática
inicializados a cero, al menos que se inicialice el primer elemento a cero, para que los
demás queden automáticamente inicializados a ese valor.
Ejemplos de declaración e inicialización de arreglos bidimensionales (Cairó,
2006):
/*Declara un arreglo bidimensional tipo entero llamado M
con 3 filas y 4 columnas*/
int M[3][4];
/*Declara un arreglo bidimensional llamado matriz de 4
renglones y 4 columnas, y un arreglo unidimensional llamado
b5 con 100 elementos, ambos arreglos tipo real o flotante*/
float matriz[4][4], b5[100];
/* Se almacena el valor 10 en el primer renglón y primera
columna de M*/
M[0][0]=10
/* Se almacena el valor 3.14 en el tercer renglón y tercera
columna de matriz*/
matriz[2][2]=3.14
/*Todos los elementos
cero.*/
int A[3][6] = {0};
del
arreglo
se
inicializan
con
/*Los primeros cuatro componentes de la primera fila se
inicializan con los valores; 3, 4, 6 y 8. El resto con
cero.*/
int B[3][6] = {3,4,6,8};
/*Cada componente del arreglo recibe un valor. La
asignación se realiza fila a fila.*/
int C[3][6] = {6, 23, 8, 4, 11, 33, 21, 0, 6, 10, 23, 4, 8,
2, 1, 6, 9, 15};
/*La asignación anterior también se puede realizar de esta
forma. La representación gráfica del arreglo bidimensional
C se muestra en la figura 21.*/
int C[3][6] = {{6, 23, 8, 4, 11, 33}, {21, 0, 6, 10, 23,
4}, {8, 2, 1, 6, 9, 15}};
60
Figura 21. Representación gráfica del arreglo bidimensional C con 3 x 6 elementos de tipo
entero (Cairó, 2006).
/*Error de sintaxis ya que la fila tiene espacio para seis
elementos y se asignan siete.*/
int C[3][6] = {{6, 23, 8, 4, 11, 35, 8}};
Si las posiciones de un arreglo no son inicializados o no se les asigna
explícitamente un valor, se considera que almacenan “basura”, pues en memoria
siempre existen datos. No se debe olvidar almacenar datos en un arreglo
bidimensional antes de realizar operaciones con ellos, tal como sucede con las
variables.
Algunas de las operaciones que se realizan con arreglos bidimensionales son
asignación, lectura/escritura, y aquellas propias para matrices matemáticas, por ejemplo:
suma, multiplicación, inversa, etc., por lo que, el acceso a las posiciones de la tabla o
matriz se realiza normalmente utilizando ciclos anidados, pues para una matriz de m
por n, donde n es el número de renglones y m el número de columnas, generalmente se
requiere recorrer m columnas por cada renglón que constituye a la matriz, es decir,
recorrer m columnas n veces.
Finalmente, el máximo de dimensiones que puede tener un arreglo
multidimensional de más de dos dimensiones, queda determinado por el lenguaje de
programación que se utiliza o por el espacio en memoria, por lo que la cantidad de
índices que se utilizan para acceder a sus valores, depende de la dimensión del arreglo.
En en el lenguaje C se declaran de la siguiente manera y como máximo se tienen
hasta 12 subíndices de arreglo:
tipo nombre[tamao1][tamaño2]…[tamaño_n]
61
NOTA IMPORTANTE: los corchetes, utilizados para cerrar el subíndice de un
arreglo de cualquier dimensión, son considerados como operadores y tienen el mismo
nivel de precedencia que los paréntesis (el orden de precedencia se revisó en la sección
Tabla de prioridad y orden de evaluación del apartado 6: Lenguaje C).
12. CARACTERES, CADENAS DE CARACTERES Y
ARREGLOS DE CARACTERES
12.1 Caracteres
Los lenguajes de programación utilizan juegos de caracteres llamados alfabetos
para comunicarse con las computadoras. Las primeras computadoras sólo utilizaban
información numérica digital mediante el código o alfabeto digital y los primeros
programas se escribieron en ese tipo de código denominado código máquina, basado en
los dígitos 0 y 1 (como se mencionó en el apartado 1: Preliminares, conceptos
básicos), por ser inteligible directamente por la computadora. La difícil tarea de
programar en código máquina hizo que el alfabeto evolucionara y los lenguajes de
programación comenzaran a utilizar códigos o juegos de caracteres similares a los
utilizados en los lenguajes humanos. Así, hasta el día de hoy, la mayoría de las
computadoras trabajan con diferentes tipos de juegos de caracteres, de los cuales
destacan el código ASCII (American Standard Code for Information Interchange) y el
EBCDIC (Extended Binary Coded Decimal Interchange Code) (Deitel & Deitel, 1995).
El código ASCII básico utiliza 7 bits (el concepto de bit se especificó en el
apartado 1: Preliminares y conceptos básicos) para cada caracter a representar, lo que
da un total de 27 = 128 caracteres distintos. El código ASCII ampliado utiliza 8 bits, y
en este caso, consta de 28 = 256 caracteres. Este código ASCII adquirió una gran
popularidad ya que es el estándar en todas las familias de computadoras personales y se
presenta en la tablas 17 y 18 (Deitel & Deitel, 1995).
En general, un caracter ocupará un byte (8 bits) de almacenamiento de memoria
y se puede definir como un símbolo del juego de caracteres de la computadora.
El código ASCII se compone de los siguientes tipos de caracteres (Deitel &
Deitel, 1995):
Alfabéticos (a…z A…Z)
Numéricos (0, 1, 2, 3, 4, 5, 6, 7, 8, 9)
Especiales (+, -, *, /, {, }, <, etc.)
De control: son caracteres no imprimibles que realizan una serie de funciones
relacionadas con la escritura, transmisión de datos, separador de archivos, etc.,
en realidad con los dispositivos de entrada/salida. Destacan entre ellos: del
(eliminar o borrar), cr (retorno de carro), lf (avance de línea), ff (avance de
página), stx (inicio de texto), etc.
62
Tabla 17. Código ASCII de caracteres de control.
Binario
0000 0000
0000 0001
0000 0010
0000 0011
0000 0100
0000 0101
0000 0110
0000 0111
0000 1000
0000 1001
0000 1010
0000 1011
0000 1100
0000 1101
0000 1110
0000 1111
0001 0000
0001 0001
Dec.
0
1
2
3
4
5
6
7
8
9
10
11
12
13
14
15
16
17
Hex.
00
01
02
03
04
05
06
07
08
09
0A
0B
0C
0D
0E
0F
10
11
Abreviatura
NUL
SOH
STX
ETX
EOT
ENQ
ACK
BEL
BS
HT
LF
VT
FF
CR
SO
SI
DLE
DC1
Representación
^@
^A
^B
^C
^D
^E
^F
^G
^H
^I
^J
^K
^L
^M
^N
^O
^P
^Q
0001 0010
0001 0011
18
19
12
13
DC2
DC3
^R
^S
0001 0100
0001 0101
20
21
14
15
DC4
NAK
^T
^U
0001 0110
0001 0111
22
23
16
17
SYN
ETB
^V
^W
0001
0001
0001
0001
0001
0001
0001
0001
0111
24
25
26
27
28
29
30
31
127
18
19
1A
1B
1C
1D
1E
1F
7F
CAN
EM
SUB
ESC
FS
GS
RS
US
DEL
^X
^Y
^Z
^[ or ESC
^\
^]
^^
^_
^?, Delete,
or
Backspace
1000
1001
1010
1011
1100
1101
1110
1111
1111
Nombre/significado
Caracter nulo
Inicio de encabezado
Inicio de texto
Fin de texto
Fin de transmisión
Enquiry
Acknowledgement
Timbre
Retroceso
Tabulación horizontal
Avance de línea
Tabulación vertical
Avance de página
Retorno de carro
Shift Out
Shift In
Data Link Escape
Control de dispositivo 1
XON
Control de dispositivo 2
Control de dispositivo
XOFF
Control de dispositivo 4
Negative
Acknowledgement
Synchronous Idle
Fin de transmisión de
bloque
Cancelar
End of Medium
Substitute
Escape
Separador de archivo
Separador de grupo
Separador de registro
Separador de unidad
Borrado o retroceso
Tabla 18. Código ASCII de caracteres alfabéticos, numéricos y especiales.
Binario
0010
0000
0010
0001
0010
Dec.
32
Hex.
20
Representación
espacio ( )
33
21
!
34
22
"
Binario
0101
0000
0101
0001
0101
Dec.
80
Hex.
50
Representación
P
81
51
Q
82
52
R
63
0010
0010
0011
0010
0100
0010
0101
0010
0110
0010
0111
0010
1000
0010
1001
0010
1010
0010
1011
0010
1100
0010
1101
0010
1110
0010
1111
0011
0000
0011
0001
0011
0010
0011
0011
0011
0100
0011
0101
0011
0110
0011
0111
0011
1000
0011
1001
0011
1010
0011
1011
0011
1100
0011
1101
35
23
#
36
24
$
37
25
%
38
26
&
39
27
'
40
28
(
41
29
)
42
2A
*
43
2B
+
44
2C
,
45
2D
-
46
2E
.
47
2F
/
48
30
0
49
31
1
50
32
2
51
33
3
52
34
4
53
35
5
54
36
6
55
37
7
56
38
8
57
39
9
58
3A
:
59
3B
;
60
3C
<
61
3D
=
0010
0101
0011
0101
0100
0101
0101
0101
0110
0101
0111
0101
1000
0101
1001
0101
1010
0101
1011
0101
1100
0101
1101
0101
1110
0101
1111
0110
0000
0110
0001
0110
0010
0110
0011
0110
0100
0110
0101
0110
0110
0110
0111
0110
1000
0110
1001
0110
1010
0110
1011
0110
1100
0110
1101
83
53
S
84
54
T
85
55
U
86
56
V
87
57
W
88
58
X
89
59
Y
90
5A
Z
91
5B
[
92
5C
\
93
5D
]
94
5E
^
95
5F
_
96
60
`
97
61
a
98
62
b
99
63
c
100
64
d
101
65
e
102
66
f
103
67
g
104
68
h
105
69
i
106
6A
j
107
6B
k
108
6C
l
109
6D
m
64
0011
1110
0011
1111
0100
0000
0100
0001
0100
0010
0100
0011
0100
0100
0100
0101
0100
0110
0100
0111
0100
1000
0100
1001
0100
1010
0100
1011
0100
1100
0100
1101
0100
1110
0100
1111
62
3E
>
63
3F
?
64
40
@
65
41
A
66
42
B
67
43
C
68
44
D
69
45
E
70
46
F
71
47
G
72
48
H
73
49
I
74
4A
J
75
4B
K
76
4C
L
77
4D
M
78
4E
N
79
4F
O
0110
1110
0110
1111
0111
0000
0111
0001
0111
0010
0111
0011
0111
0100
0111
0101
0111
0110
0111
0111
0111
1000
0111
1001
0111
1010
0111
1011
0111
1100
0111
1101
0111
1110
110
6E
n
111
6F
o
112
70
p
113
71
q
114
72
r
115
73
s
116
74
t
117
75
u
118
76
v
119
77
w
120
78
x
121
79
y
122
7A
z
123
7B
{
124
7C
|
125
7D
}
126
7E
~
Una constante caracter se define como cualquier caracter encerrado entre
apóstrofos o comilla sencilla, específicamente en el lenguaje C, se usa la comilla
sencilla.
Para ingresar o mostrar en un dispositivo de salida tipos de datos caracter en el
leguaje C, se usan las instrucciones vistas en el apartado 7: Instrucciones de entrada y
salida, las cuales pueden ser: scanf, printf, putchat o getchar.
Las operaciones que se realizan generalmente con caracteres suelen ser las
siguientes (Cairó, 2006):
Verificar si una caracter es o no es un dígito.
Verificar si un caracter es o no una letra
65
Verificar si un carácter es una letra minúscula o mayúscula
Convertir una letra a minúscula o mayúscula
Para realizar lo anterior, en el lenguaje C existen como parte de la biblioteca
ctype.h, las siguientes funciones: isdigit( ), isalpha( ), islower( ),
isupper( ), tolower( ) y toupper( ). Todas reciben como argumento el
valor que se quiere verificar o convertir (Cairó, 2006).
12.2 Cadenas de caracteres
Una cadena se define como una secuencia finita de caracteres que finaliza con el
caracter nulo ‘\0’ y se almacena en un área contigua de la memoria. Una constante
tipo cadena consiste en una cadena encerrada entre apóstrofos, comillas sencillas o
dobles comillas, específicamente en el lenguaje C, se encierra la cadena usando el
caracter de doble comilla, la cual no se puede modificar.
Las cadenas se pueden usar en aplicaciones de gestión, generación y
actualización de listas de dirección, inventarios, bases de datos, traductores de
lenguajes, etc.
Las operaciones comunes que se realizan con cadenas de caracteres son (Deitel
& Deitel, 1995):
Cálculo de longitud de la cadena (número de caracteres que contiene la cadena,
incluyendo el espacio en blanco, sin incluir el caracter nulo. La cadena que no
contiene ningún carácter se denomina cadena vacía o nula y su longitud es
cero).
Comparación de cadenas (saber si dos cadenas con iguales o diferentes).
Concatenación de cadenas (unir cadenas para formar nuevas cadenas).
Extracción de subcadenas (extraer una porción de una cadena a la cual se le da
el nombre de subcadena).
Búsqueda de información en una cadena (búsqueda de ciertos caracteres, frases,
etc.).
Insertar subcadenas (agregar nuevas cadenas a cadenas ya formadas).
Borrar cadenas (eliminar cierta cantidad de caracteres a partir de una posición,
es decir, borrar subcadenas).
Cambiar una cadena o subcadena por otra subcadena o cadena.
Convertir cadenas en números y viceversa.
Para ingresar o mostrar en un dispositivo de salida tipos de datos cadena en el
lenguaje C, se usan las instrucciones vistas en el apartado 7: Instrucciones de entrada y
66
salida, éstas son: scanf y printf. Así como las que describen en los ejemplos siguientes:
puts y gets.
A continuación se presentan ejemplos de declaración e inicialización de cadenas
en el lenguaje C.
char nombre[15];
/* Declara un arreglo para 15 caracteres. Si no se
especifica el caracter nulo al final de la inicialización,
lectura o asignación del arreglo, entonces, nombre es un
simple arreglo de caracteres, mas no una cadena, pero, si
en la inicialización, lectura o asignación de nombre se le
coloca el caracter nulo al final de todos los caracteres
que contenga, entonces no es un simple arreglo de
caracteres, sino una cadena. En resumen, la diferencia
entre un arreglo de caracteres y una cadena es la
existencia del caracter nulo. Si nombre debe ser una
cadena, entonces puede almacenar como máxima 14 caracteres,
pues además contendrá el caracter nulo.*/
char cadena[ ] = {‘p’,’r’,’i’,’m’,’e’,’r’,’o’,’\0’};
/* Se declara la cadena llamada cadena y se inicializa
caracter a caracter terminando con el caracter nulo. La
variable cadena contendrá la palabra “primero”, la cual
contiene 7 caracteres, pues en el conteo no se suma el
caracter nulo. El arreglo cadena se ajusta a un tamaño de 8
elementos en memoria, pues el caracter nulo ocupa un
espacio en memoria.*/
char frase[ ] = “El perro ladra sin parar.”;
/* Se declara la cadena llamada frase que contiene una
longitud de 25 caracteres, pero en memoria existen 26
asignaciones porque se agrega en automático el caracter
nulo a los caracteres.*/
#define SALUDO “Un saludo afectuoso”
/* Se declara una constante llamada SALUDO que contiene la
frase “Un saludo afectuoso”, es decir, la longitud de la
cadena es de 19 caracteres, mientras que en memoria se
almacenan 20 porque cuando no se inicializa caracter a
caracter sino como cadena (usando las comillas dobles)
automáticamente se agrega el caracter nulo.*/
Como se especificó en el apartado 7: Instrucciones de Entrada y Salida (E/S),
existe el parámetro %s para mandar a pantalla variables o constantes de tipo cadena y
67
para ingresar desde el teclado cadenas que se almacenarán en variables de tipo cadena,
por ejemplo:
printf(“%s”, “Un afectuoso saludo”);
/*Imprime la cadena “Un afectuoso saludo”*/
printf(“%s”, SALUDO);
/*Imprime el valor de la constante tipo cadena, llamada
SALUDO*/
printf(“%s”, cadena);
/*Imprime el valor de la variable cadena que contiene la
palabra “primero”*/
puts(frase);
/* Imprime lo que contiene la variable frase: “El perro
ladra sin parar.” La instrucción puts no necesita que se le
indique el tipo de datos que está enviando a pantalla como
con printf y es la más apropiada para escribir cadenas de
caracteres. Esta función baja automáticamente una línea
después de imprimir. (Cairó, 2006)*/
scanf(“%s”, nombre);
/* En la variable nombre se almacenarán los caracteres que
se ingresen desde el teclado. Cuando se da un valor a una
variable desde el teclado, no es necesario teclear el
caracter nulo, éste se asigna automáticamente después de
pulsar la tecla enter. El problema con esta forma de
ingresar datos, es que el carácter espacio en blanco no se
almacenará en la variable, de hecho, si se escriben
caracteres después de un espacio en blanco, todos ellos no
se almacenarán.*/
gets(cadena);
/* Otra forma de ingresar caracteres desde teclado y a
diferencia del ejemplo anterior, si se ingresan caracteres
en blanco, éstos serán también almacenados en la variable.
Esta función es la más apropiada para leer cadenas de
caracteres (Cairó, 2006). */
scanf(“%[^\n]”, frase);
/* En frase se almacenarán todos los caracteres que se
ingresen desde el teclado incluyendo el carácter de espacio
en blanco. El ingresar caracteres termina cuando se pulsa
la tecla enter, sin que este carácter se almacene en
68
memoria, al igual que la lectura con el tipo de dato %s, se
agrega automáticamente a la cadena el caracter nulo. En
realidad la traducción a lo que está entre corchetes es:
almacenas todo lo ingresado menos el caracter enter.*/
En el lenguaje C ya existen varias funciones para manipular cadenas. Dichas
funciones forman parte de la biblioteca string.h. Algunos ejemplos de dichas funciones
son:
strlen, para obtener la longitud de una cadena.
strcmp, para comparar si dos cadenas son iguales o no.
strcpy, para copiar el contenido de una cadena a otra cadena.
tolower, para convertir los caracteres de una cadena a minúsculas.
toupper, para convertir los caracteres de una cadena a mayúsculas.
12.3 Arreglos de caracteres
Un arreglo unidimensional de caracteres se define como una colección finita,
homogénea y ordenada de datos, en que se hace referencia a cada elemento del arreglo
por medio de un índice y no necesariamente finaliza con el caracter nulo (Cairó, 2006).
Como se mencionó en los ejemplos el apartado anterior, la diferencia sustancial entre
una cadena y un arreglo de caracteres es la existencia al final de la cadena del carácter
nulo.
Por otra parte, se pueden utilizar arreglos bidimensionales de caracteres para
manejar conjuntos de cadenas, esto es, dado que una cadena se define como un arreglo
unidimensional que termina con el caracter nulo, entonces, si se desea almacenar
cadenas de caracteres en arreglos bidimensionales, cada fila almacenaría una cadena y
cada columna almacenaría los caracteres correspondientes de cada cadena (Cairó,
2006). Por ejemplo, si se desea almacenar un grupo de 5 cadenas de caracteres con 40
caracteres como máximo para cada cadena, entonces se podría hacer una declaración
como la siguiente en el lenguaje C:
char cadenas[5][30];
así, el primer índice se utilizaría para hacer referencia a la fila, es decir a cada cadena; y
el segundo índice serviría para señalar el caracter de cada cadena.
13. FUNCIONES
Como se mencionó en la sección Diseño de un algoritmo del apartado 5:
Proceso de resolución de problemas utilizando un lenguaje de programación, la
69
resolución de un problema complejo se facilita si dicho problema se divide en
problemas más pequeños, es decir, si se divide en subproblemas, los cuales son tratados
de forma individual e independiente, diseñando así subalgoritmos que se convierten en
subprogramas (Bermúdez et. al., 2003). Los subprogramas que se forman con éste
método pueden ser de dos tipos: funciones o procedimientos, estos últimos también
conocidos como subrutinas.
Los subprogramas están diseñados para ejecutar alguna tarea específica, se
escriben solamente una vez, pero pueden utilizarse en diferentes puntos de un programa,
de manera que, se puede evitar la duplicación innecesaria de código.
Los subprogramas o módulos se escriben sin entrar en detalles con otros
módulos facilitando así la localización de errores.
Un subprograma puede realizar las mismas acciones que un programa: leer datos
desde dispositivos de entrada, hacer asignaciones, realizar cálculos, devolver resultados
a través de un dispositivo de salida, etc., pero en general se utiliza para un propósito
específico. El subprograma recibe datos desde el programa principal o desde cualquier
subprograma que lo llama, procesa dichos datos, y si es necesario, devuelve resultados
al programa o subprograma que lo haya llamado.
El enfoque en éstos apuntes será sobre los subprogramas llamados funciones,
que son los únicos que existen en el lenguaje C.
Función
Matemáticamente hablando una función es una operación que toma uno o más
valores llamados argumentos y produce un valor denominado resultado, es decir,
genera el valor de la función para los argumentos dados, por otro lado, una función
computacionalmente hablando es una colección de sentencias que ejecutan una tarea
específica y no puede contener a otra función (Ceballos, 1997).
Todos los lenguajes de programación tienen funciones incorporadas o intrínsecas
que se utilizan escribiendo sus nombres con los argumentos adecuados entre paréntesis,
(como las funciones matemáticas del lenguaje C: sqrt, pow, sin, etc.) y funciones
definidas por el usuario o programador, es decir, escritas por él mismo.
Las funciones incorporadas al sistema se denominan funciones internas o
intrínsecas y las funciones definidas por el usuario, funciones externas o extrínsecas.
Cuando las funciones estándares o internas no permiten realizar el tipo de cálculo
deseado es necesario recurrir a las funciones externas.
Una vez que una función ha sido escrita y depurada puede utilizarse una y otra
vez. Cuando una función se manda a llamar, el control se pasa a dicha función para su
ejecución y cuando ésta finaliza, el control es devuelto al módulo que la llamó para
continuar con la ejecución del mismo después de donde se efectuó la llamada, como se
muestra en la figura 22 (Bermúdez et. al., 2003). En ese ejemplo, dentro de la función
principal del lenguaje C, o sea, la función main se hace el llamado a la función
denominada func1, por lo que la secuencia de ejecución se pasa a dicha función,
70
realizándose una a una las instrucciones dentro de func1, pero al llegar al llamado de
func2, nuevamente la secuencia de la ejecución se desvía hacia la función func2. Se
ejecutan las instrucciones que existan dentro de la función func2 hasta alcanzar el
return, con lo cual se regresa el control a func1 para continuar con la ejecución de las
instrucciones que contenga hasta llegar al return de func1, con lo cual se regresa el
control a la función principal main. Como nuevamente se hace el llamado a la función
func1, se vuelve a realizar el proceso descrito hasta regresar a la función principal main
para ejecutarse todas las instrucciones que contenga main hasta llegar al final del
programa, en conclusión, como se muestra en la figura 22, el orden de ejecución es
conforme la numeración 1 al 8.
main( )
{
func1( );
…
func1( );
return;}
1
5
4
func1( )
{
func2( );
…
return;
}
2
6
func2( )
{
…
3
return;
7
}
8
Figura 22. Ejemplo del llamado de una función en el lenguaje C (Ceballos, 1997).
13.1 Funciones definidas por el usuario en el lenguaje C
Todo programa en C consta al menos de la función main( ), que es donde inicia
la ejecución de un programa. También puede constar de otras funciones que ya ofrece el
lenguaje y de aquellas que diseña el programador.
Las funciones que declara el usuario pueden aparecer en cualquier orden y en uno o
varios archivos fuente, conformándose de un encabezado y un cuerpo. De manera explícita se
puede decir que, es un bloque o una proposición compuesta. La estructura básica de la
definición de una función es la siguiente:
tipo_de_retorno nombre (parámetros formales)
{
declaraciones;
proposiciones;
return(expresión);
}
a) Encabezado de una función
tipo_de_retorno indica el tipo del valor devuelto por la función. Puede ser cualquier
tipo básico, estructura o unión. Por defecto es del tipo int. Cuando no se requiere que
devuelva algún valor se usará el tipo void.
71
nombre es un identificador que indica el nombre de la función. Sigue las mismas reglas
que se tienen para nombrar una variable.
Parámetros formales es una secuencia de declaraciones separadas por coma. Cada
parámetro, es decir, variable o arreglo, debe ir con el tipo de dato correspondiente. Si no
se pasan argumentos a la función se puede utilizar la palabra reservada void.
Generalmente se usa la palabra parámetro formal para una variable nombrada en la
lista entre paréntesis de la definición de función, y argumento o parámetro actual para
el valor empleado al hacer la llamada de la función.
b) Cuerpo de la función
Está formado por una sentencia compuesta que contiene sentencias que definen
lo que hace la función. Las declaraciones de variables utilizadas en la función por
defecto son locales a la función, es decir, sólo son definidas, vistas y válidas dentro de
la función donde son empleadas, pero fuera de dicha función, no son conocidas y no
tienen valor.
return (expresión) se utiliza para devolver el valor de la función, el cual debe ser del
mismo tipo declarado en el encabezado de la función. Si la sentencia return no se
especifica o se especifica sin contener una expresión, la función no devuelve un valor.
Cuando explícitamente se devuelve un valor, éste puede ir o no entre paréntesis, es
decir, los paréntesis son opcionales.
La instrucción return puede ser o no la última que aparezca en el cuerpo de la
función y puede aparecer más de una vez, dependiendo del problema que se esté
resolviendo. En el caso de que la función no retorne algún valor, la instrucción se puede
omitir.
c) Llamado de una función
Para ejecutar una función hay que llamarla. La llamada a una función se hace
mediante su nombre con los argumentos o parámetros actuales o reales entre
paréntesis. Generalmente se asigna el valor que regresa una función a una variable del
mismo tipo de ésta.
Cuando se llama a una función, el valor del primer parámetro actual es pasado al
primer parámetro formal, el valor del segundo parámetro actual es pasado al segundo
parámetro formal y así sucesivamente. Todos los argumentos excepto los arreglos, son
pasados por valor. Esto es, a la función se pasa una copia del argumento, no su
dirección en memoria, esto hace que la función C no pueda alterar los contenidos de las
variables transmitidas. Si se desea poder alterar los contenidos de los argumentos en la
llamada entonces hay que pasarlos por referencia (método que se verá más adelante, en
la sección 13.5).
Ejemplos:
Ejemplo 1
Ejemplo 2
72
#include <stdio.h>
#include <stdio.h>
void letrero(void)
{
void letrero2(int i)
{
printf(“\n Esta es una función
if (i>0)
printf(“\n i
muy simple”);
positivo”);
else
printf(“\n
i
return;
negativo”);
}
es
es
}
int main( ) {
int main( ) {
letrero2(10);
letrero( );
return 0;
return 0;
}
}
Ejemplo 3
int n2=55;
#include <stdio.h>
res = suma(5,10) ;
int suma(int a, int b)
{
int valor;
valor = a+b;
printf( “La suma es: %d \n”, res);
res = suma(n1,n2);
printf(“La suma de %d + %d =
\n”, n1,n2,res);
%d
return (valor);
}
int main( )
{
int res;
int n1=23;
printf(“La suma de
%d”,suma(-25,-12));
-25
+
-12
=
return 0;
}
13. 2 Prototipo de funciones
Antes de usar o llamar a una función, el lenguaje C debe tener conocimiento del
tipo de dato que regresará y el tipo de los parámetros que la función espera recibir. Por
tanto, esos valores los conoce el lenguaje cuando la función se declara y define, es decir,
cuando la función se programa antes de la función main, o en general, antes de su
llamado en cualquier parte del programa. Sin embargo, existen casos donde la función
es llamada sin ser declarada previamente o sin conocer el código que la conforma
provocando errores de compilación, por lo que, el lenguaje permite el uso de
declaraciones forward (también llamadas prototipos de funciones) o bien, genera
automáticamente una declaración prototipo implícita (Ceballos, 1997).
73
Un prototipo de función (declaración forward) permite conocer el nombre de la
función, el tipo de resultado que devolverá, así como los tipos y nombres de los
parámetros a recibir; todo ello antes de especificar el cuerpo de la función, es decir,
antes de haberla definido o programado8.
La importancia de usar prototipos de funciones o declaración explícita radica
en que:
Se hace el código más estructurado y por lo tanto más fácil de leer.
Permite conocer las características de la función antes de ser utilizada.
Lo anterior aplica dependiendo del alcance de la función. Básicamente si una
función ha sido definida antes de que sea usada o llamada, entonces se puede usar la
función sin problemas.
Ejemplo (Deitel & Deitel, 1995):
/*Encontrar el mayor de tres números reales*/
#include <stdio.h>
float maximo(float, float, float);
maximo */
/* Prototipo de la función
int main( )
{
float a, b, c;
printf(“Ingrese los tres datos:”);
scanf(“%f%f%f”, &a, &b, &c);
printf(“El máximo es: %f\n”, máximo(a,b,c));
return 0;
}
float maximo (float x, float y, float z)
{
float max = x;
if (y > max) max = y;
if (z > max) max = z;
return max;
}
8
Las funciones prototipo de las funciones pertenecientes a la biblioteca estándar del
lenguaje C son provistas por los ficheros de cabecera estándar: archivos .h, como se
mencionó en el apartado 6: Lenguaje C.
74
El prototipo de la función maximo es: float maximo(float, float,
float;
Ese prototipo tiene la misma sintaxis que la primera línea de la definición de la
función (la que se encuentra después de la función main), excepto que termina con
punto y coma y no contiene los nombres de los parámetros: x, y, z, de hecho son
opcionales en el prototipo de una función, de modo que, para el prototipo se puede
escribir también:
float maximo(float x, float y, float z);
Lo más común es omitir los identificadores para colocar sólo los tipos.
Es importante recalcar que si la definición de una función o cualquier uso que
de ella se haga no corresponda con su prototipo ocasionará un error.
Conversiones de tipo
En el prototipo de función, es importante que los argumentos coincidan con el
tipo apropiado, es decir, que haya coerción de argumentos. Por ejemplo, la función
matemática sqrt de la biblioteca estándar puede ser llamada con un argumento entero,
aun cuando el prototipo de la función en el archivo de cabecera math.h especifica un
parámetro de tipo double, sin que esto ocasione un error en el resultado. El prototipo de
función hará que el valor entero se convierta a double. (Deitel & Deitel, 1995).
En general, los valores de los argumentos que no correspondan precisamente a
los tipos de los parámetros del prototipo de función serán convertidos al tipo
apropiado, antes de que la función sea llamada. Estas conversiones pueden llevar a
resultados incorrectos si no son seguidas las reglas de promoción del leguaje C. Las
reglas de promoción definen cómo deben ser convertidos los tipos a otros tipos, sin
perder datos. Por ejemplo, un tipo double convertido a entero truncará la parte
fraccional del valor double. Nuevamente, en general, convertir tipos enteros grandes a
tipos enteros pequeños puede dar domo resultado valores modificados (Deitel & Deitel,
1995).
Las reglas de promoción se aplican automáticamente a expresiones que
contengan valores de dos o más tipos distintos de datos (también conocidas como
expresiones de tipo mixto). El tipo de cada valor en una expresión de tipo mixto es
automáticamente promovido al tipo más alto en la expresión (se crea una versión
temporal de cada valor y se utiliza para la expresión conservándose sin cambios los
valores originales) (Deitel & Deitel, 1995). A continuación se presentan las reglas de
promoción que se aplican automáticamente (Ceballos, 1997):
1. Si en una operación, el operador de precisión más alta es de tipo long double,
entonces, el otro operador es convertido a tipo long double.
2. Si en una operación, el operador de precisión más alta es de tipo double,
entonces, el otro operador es convertido a tipo double.
3. Si en una operación, el operador de precisión más alta es de tipo float, entonces,
el otro operador es convertido a tipo float.
75
4. Si en una operación, el operador de precisión más alta es de tipo unsigned long
int, entonces, el otro operador es convertido a tipo unsigned long int.
5. Si en una operación, el operador de precisión más alta es de tipo long int,
entonces, el otro operador es convertido a tipo long int.
6. Si en una operación, el operador de precisión más alta es de tipo unsigned int,
entonces, el otro operador es convertido a tipo unsigned int.
7. Si en una operación, el operador de precisión más alta es de tipo int, entonces, el
otro operador es convertido a tipo int.
8. En una operación, cualquier operando de tipo short es convertido a tipo int.
9. En una operación, cualquier operando tipo char, es convertido a tipo int.
10. Cualquier operando de tipo unsigned short es convertido a tipo unsigned int.
11. Cualquier operando de tipo unsigned char es convertido a tipo unsigned int.
La conversión de valores a tipos inferiores, por lo regular resulta en un valor
incorrecto. Por lo tanto, un valor puede ser convertido sólo a un valor inferior,
asignando de manera explícita el valor a una variable de tipo inferior, o mediante el uso
de un operador cast. Los valores de los argumentos de las funciones son convertidos a
los tipos de parámetro en un prototipo de función, como si hubieran sido asignados
directamente a las variables de esos tipos, es decir, las conversiones son ejecutadas
independientemente sobre cada argumento en la llamada (Deitel & Deitel, 1995). En
general, los reales son convertidos a enteros, truncando la parte fraccionaria y un double
pasa a float redondeando y perdiendo precisión si el valor double no puede ser
representado exactamente como float.
Ahora bien, el operador cast (casting) permite realizar una conversión forzada o
explícita con la siguiente sintaxis:
(nombre_de_tipo_de_dato) expresión
Lo anterior provoca la conversión del valor de la expresión al tipo nombrado
entre paréntesis, aplicando las reglas de conversión expuestas anteriormente.
Ejemplos:
float r;
int i;
r = i; /* i es convertido a float para ser asignado a r */
i = r;
/*r es truncada para quedar como entero y ser
asignado a i */
i
r
i
r
=
=
=
=
7/3
/* i = 2 */
7/3
/* i = 2.000000 */
12.6/3
/* i = 4 */
12.6/3
/* i = 4.2 */
76
Declaración de prototipo implícita
La declaración de prototipo implícita, la cual se mencionó al inicio de esta
sección, se da cuando la función es llamada sin existir una declaración previa de la
misma y la definición o código de la función se hace o se escribe después de la función
principal main. En este caso, el lenguaje C por defecto construye una función prototipo
con tipo de resultado int, pero no se supone nada en relación con los argumentos. Esto
obliga entonces a que el tipo del resultado en la definición de la función sea del tipo int
y a que, si los argumentos pasados a la función no son correctos, el compilador no los
detecte (Ceballos, 1997).
Ejemplo:
#include <stdio.h>
int main( )
{
int r, b = 5 ;
r = escribir(b) ;
printf(“%d\n”, r);
return 0;
}
int escribir (int y)
{
return y * 3 ;
}
La función escribir es declarada implícitamente para retornar un valor int, ya
que es invocada antes de su definición. El compilador crea automáticamente una
función prototipo utilizando la información de la llamada a la función.
13.3 Paso de parámetros por valor y por referencia
En C existen dos tipos de parámetros en el llamado a una función: por valor o
por referencia.
Paso de parámetros por valor
77
Significa que la función que se invoca recibe los valores de sus argumentos en
variables temporales y no en las originales, por lo que la función no puede alterar
directamente una variable de la función que hace la llamada, sólo puede modificar su
copia privada y temporal. Significa también copiar los parámetros actuales en sus
correspondientes parámetros formales, operación que se hace automáticamente cuando
se llama a una función, con lo cual no se modifican los parámetros actuales. Con este
método pueden ser transferidas constantes, variables y expresiones.
Paso de parámetros por referencia o dirección
Lo que se transfiere no son los valores sino las direcciones de las variables que
contienen esos valores, con lo cual los argumentos actuales de la función pueden verse
modificados. Una variable tiene una posición de memoria asignada (área de
almacenamiento o dirección) desde la cual se puede obtener o actualizar su valor, por
tanto, el paso de parámetros por referencia es útil cuando la función llamadora requiere
que la función llamada modifique el valor de las variables que se pasan como
argumentos.
Lo anterior se logra utilizando apuntadores (el tema de apuntadores no se trata
ampliamente en este documento, pues corresponde a la asignatura Programación II, sin
embargo, se menciona de forma básica y concisa, de tal manera que se pueda entender
el paso de parámetros por referencia).
Apuntadores
Una variable por lo regular almacena un valor específico, por su parte, un
apuntador almacena la dirección de una variable que contiene un valor específico. En
este sentido, un nombre de variable se refiere directamente a un valor y, un apuntador
se refiere indirectamente a un valor. El referirse a un valor a través de un apuntador se
conoce como indirección (Deitel & Deitel, 1995).
Los apuntadores, como cualquier otra variable, deben ser declarados antes de
que puedan usarse, lo cual se hace de la siguiente manera:
Tipo_de_dato *nombre_del_apuntador
Donde:
Tipo_de_dato es cualquiera de los que existen en el lenguaje C
* es el símbolo obligatorio que se coloca antes del nombre del apuntador
Nombre_del_apuntador sigue las mismas reglas que los identificadores de variables
También, los apuntadores deben ser inicializados cuando son declarados en una
expresión de asignación, ya sea con el valor de la constante simbólica NULL, o bien,
con una dirección de memoria. Un apuntador con el valor NULL apunta a nada.
En la figura 23 se muestra un ejemplo gráfico de apuntadores. Los rectángulos
representan porciones de memoria; arriba de ellos se encuentran los identificadores de
las variables, es decir, los nombres con los que se reconocen esas porciones de memoria
78
por parte del programador, y los números debajo de los rectángulos son las posiciones
reales de memoria (en hexadecimal) que ocupan las variables. El contenido de cada
rectángulo es el valor que almacena cada variable. En la parte izquierda se tiene una
representación gráfica del apuntador aptValor “apuntando” a la variable valor”, y en la
parte derecha se muestra la dirección real que almacena, la cual corresponde a la
variable valor. Además, el apuntador aptSuma al haberse inicializado con el valor
NULL, no apunta a alguna porción de memoria como lo hace aptValor.
int valor = 55,
aptValor
*aptSuma = NULL,
valor
*aptValor = &valor;
aptSuma
0028FEE8
55
0028FEEC
0028FEE8
aptValor
0028FEE4
0028FEEC
Figura 23. Representación gráfica y en memoria de variables y apuntadores.
Como se observa en el ejemplo, con los apuntadores se hace uso del operador de
referencia & u operador de dirección (que como se ha visto antes, se usa con la
instrucción scanf), el cual regresa la dirección del operando que lo acompaña. Así, a la
variable aptValor se le asigna la dirección de memoria de la variable valor, por lo que
se suele decir que “aptValor apunta a la variable valor”. Por otro lado, el operador de
dirección no puede ser aplicado a constantes o expresiones.
Otro operador que se usa con apuntadores es el *, conocido como el operador de
indirección o de desreferencia. Este operador lo que hace es devolver el valor al que
apunta (valga la redundancia) un apuntador. Retomando el ejemplo anterior, si se usara
la instrucción: printf(“%d”, *aptValor), se tendría en pantalla el valor 55.
NOTA: para mandar a pantalla el valor de las direcciones de memoria en
hexadecimal se puede utilizar la especificación de formato %p en la instrucción de
salida printf (revisar la tabla especificaciones de formato para printf del apartado 7:
Instrucciones de entrada y salida). Por ejemplo: printf(“%p-%p-%p”, &valor,
aptValor, &aptValor); tendría como salida: 0028FEE8-0028FEE80028FEEC.
Llamadas por referencia en una función
Cuando se llama a una función con argumentos que deban ser modificados, se
pasan las direcciones de los argumentos. Esto puede necesitarse cuando se requiere
modificar una o más variables del llamador o cuando se requiere pasar un apuntador a
un objeto de datos grades, como una estructura de datos o arreglo, evitando así el hacer
demasiadas copias de los valores (Deitel & Deitel, 1995).
79
Por regla, cuando se llama a una función, los argumentos enviados en la llamada
son pasados por valor, a menos que se use el operador de dirección (&) a las variables
cuyos valores serán modificados, pues con ello, se estará especificando que los
argumentos se pasan por referencia. Los arreglos no se pasan con el operador & porque
el lenguaje C pasa de forma automática la posición inicial en memoria del arreglo, de
hecho, el nombre de un arreglo es equivalente a escribir &nombre_arreglo[0] (Deitel &
Deitel, 1995). En otras palabras, los arreglos automáticamente se pasan por
referencia escribiendo sólo su nombre.
Cuando se pasa a una función la dirección de una variable, se puede utilizar el
operador de indireccion (*) dentro de la función para modificar el valor de esa posición
de memoria, es decir, para modificar el valor de la variable del llamador.
Ejemplo (Ceballos, 1997):
#include <stdio.h>
void sumar(int, int, int, int *);
/*Prototipo de la función sumar*/
int main( )
{
int v = 5, res = 0;
sumar(4, v, v*2-1, &res);
printf(“%d”,res);
return 0;
}
void sumar(int a, int b, int c, int *s)
{
b+=2;
*s = a + b + c;
}
La llamada a la función sumar pasa los parámetros 4, v, y v*2-1 por valor; el
primero es una constante, el segundo es una variable y el terceo una expresión
aritmética; pero el parámetro res es pasado por referencia. Cualquier cambio que sufra
el argumento s, sucede también en su correspondiente parámetro actual res. En cambio,
la variable v no se ve modificada, a pesar de haber variado b dentro de la función, ya
que ha sido pasada por valor. Aquí, la variable res dentro de main se inicia con el valor
0, pero al pasarse su dirección de memoria, el apuntador s apunta a dicha variable; como
dentro de la función sumar, se usa el operador de indirección para modificar el valor al
que apunta s, entonces el valor de la variable res es cambiado por la suma de los valores
80
que contienen las variables a, b y c. Es decir, la salida a pantalla del valor que almacena
res no será 0, sino 20.
Por último, como se mencionó antes, en el prototipo de una función se pueden
omitir los nombres de los parámetros, por ello, en el prototipo de la función sumar, el
apuntador sólo se especifica con el tipo de dato al que apunta y el *, sin escribir el
nombre s.
13. 4 Reglas básicas de alcance o ámbito (scope)
El alcance o ámbito de un identificador es la porción del programa en el cual
dicho identificador puede ser referenciado. Por ejemplo, cuando en un bloque
declaramos una variable local, puede ser referenciada sólo en ese bloque o en los
bloques anidados dentro de él. Los tres alcances posibles para un identificador son:
alcance de archivo, alcance de bloque y alcance del prototipo de función.
Un identificador declarado por fuera de cualquier función tiene alcance de
archivo. Tal identificador es conocido en todas las funciones desde el punto donde el
identificador se declara hasta el final del archivo. Las variables globales, las
definiciones de funciones y los prototipos de función colocados fuera de una función
tienen alcance de archivo (Deitel & Deitel, 1995).
Los identificadores dentro de un bloque, tienen alcance llamado así, de bloque.
Se entiende por bloque lo que se encierra entre llaves. Las variables locales declaradas
al principio de una función tienen alcance de bloque como lo tienen los parámetros de
función, que son consideradas por la función como variables locales. Cualquier bloque
puede contener declaraciones de variables. Cuando los bloques están anidados y un
identificador de un bloque externo tiene el mismo nombre que un identificador de un
bloque interno, el identificador del bloque externo estará “oculto” hasta que el bloque
interno termine. Esto significa que, en tanto se ejecute el bloque interno, éste ve el valor
de su propio identificador local y no el valor del identificador de nombre idéntico del
bloque que lo contiene (Deitel & Deitel, 1995).
Los únicos identificadores con alcance de prototipo de función son aquellos que
se utilizan en la lista de parámetros del prototipo de una función. Tal y como se
mencionó, los prototipos de función no requieren de nombres en la lista de parámetros,
sólo requieren de tipos. Si en la lista de parámetros de un prototipo de función se utiliza
un nombre, el compilador ignorará dicho nombre. Los identificadores utilizados en un
prototipo de función, pueden ser reutilizados en cualquier parte del programa, sin
ambigüedad (Deitel & Deitel, 1995).
Ejemplo:
{
int a = 5;
printf(“\n%d”, a);
{
int a = 7;
81
printf(“\n%d”, a);
}
printf(“\n%d”, ++a);
}
Se ha declarado la misma variable dos veces, pero aunque tengan el mismo
nombre son variables distintas y por lo tanto sus valores son distintos, en la segunda
declaración de la variable a, ésta se destruye cuando alcanza el fin del bloque de
proposiciones (primer llave cerrada), por lo que los valores que se verán impresos en
pantalla son: 7 y 6.
13.5 Variables locales y variables globales
La regla de alcance es utilizada comúnmente para utilizar variables globales y
locales.
Las variables globales se declaran al inicio del programa fuera del main y fuera
de cualquier función, en cambio las variables locales se declaran dentro de algún
bloque. La diferencia sustancial entre estos dos tipos de variables es el alance: las
variables globales pueden modificar su valor en cualquier parte del programa, mientras
que las variables locales sólo pueden ser usadas en el bloque donde fueron definidas.
Cada variable local de una función comienza a existir sólo cuando se llama a la
función y desaparece cuando la función termina. Debido a que las variables locales
aparecen y desaparecen con la invocación de funciones, no retienen sus valores entre
dos llamadas sucesivas y deben ser inicializadas explícitamente en cada entrada, de no
hacerlo, contendrán basura, es decir, cualquier dato que se halle en la localidad de
memoria a la que apunta.
Las variables globales (externas) se mantienen permanentemente en existencia,
en lugar de aparecer y desaparecer cuando se llaman y terminan las funciones,
mantienen sus valores aún después de que se regresa del llamado a la función que les
fijó algún valor.
Ejemplo (Ceballos, 1997):
#include <stdio.h>
int x = 20;
void escribe_x(void);
int main( )
82
{
int x = 12;
escribe_x ( );
printf (“El valor de x (local) es= %d
\n”, x);
return 0;
}
void escribe_x( )
{
printf(“El valor de x (global) es = %d \n”, x);
}
La salida será: 20, 12.
Una variable local a un subprograma no tiene significado en otros subprogramas.
Si un subprograma asigna un valor a una de sus variables locales, este valor no es
accesible a otros programas, es decir, no pueden utilizar ese valor. A veces, también es
necesario que una variable tenga el mismo nombre en diferentes subprogramas. Por el
contrario, las variables globales tienen la ventaja de compartir información de diferentes
subprogramas sin una correspondiente entrada en la lista de parámetros.
Las variables definidas en un ámbito son accesibles en el mismo, es decir, en
todos los procedimientos interiores. La figura 24 presenta un ejemplo de declaración de
variables en distintos bloques de código y con ello, especifica desde dónde son válidas o
accesibles dichas variables.
A
B
C
D
E
F
Variables definidas
en
Accesibles desde
A
B
C
D
E
F
G
A, B, C, D, E, F, G
B, C
C
D, E, F, G
E, F, G
F
G
G
Figura 24. Ejemplo del alcance de una variable en el lenguaje C (Deitel & Deite, 1995).
83
14. ANEXOS
14.1 Prácticas sanas de programación (tomado de Deitel & Deitel
(1995))
Sobre estructuras secuenciales
1. Seleccionar nombres de variables significativas, es decir, que indiquen lo que
almacenarán.
2. Si las variables van a constar de varias palabras, utilizar el guión bajo para
separar dichas palabras.
3. Separar declaraciones de variables y enunciados ejecutables por una línea en
blanco para enfatizar dónde terminan las declaraciones y dónde comienzan los
enunciados ejecutables.
4. Colocar una línea en blanco antes y después de cada estructura de control en un
programa para mayor legibilidad.
5. Colocar espacios en blanco a ambos lados de un operador lógico o relacional
para resaltar el operador y hacer que el programa sea más legible.
6. Colocar una sangría en el o los enunciados del cuerpo de una estructura if.
7. Si no se está totalmente seguro del orden de evaluación en una expresión
compleja, utilizar paréntesis para obligar al orden, exactamente como se haría en
expresiones algebraicas.
8. Utilizar sólo letras mayúsculas para los nombres de constantes simbólicas, así
resaltarán en el programa y harán recordar que no se pueden cambiar sus valores
porque son constantes y no variables.
9. En expresiones donde se utilice el operador lógico &&, colocar primero la
condición que más probabilidades tenga de ser falsa; en expresiones que utilicen
el operador lógico ||colocar primero la condición que más probabilidades tenga
de ser verdadera. Esto puede reducir el tiempo de ejecución de un programa.
10. Escribir las llaves de principio y de terminación de los enunciados compuestos
(como los ciclos o condiciones simples) antes de empezar a escribir en el interior
de dichas llaves los enunciados individuales; esto ayudará a evitar la omisión de
una llave o ambas.
11. Inicializar variables que se utilicen como contadores o como totales.
12. Al ejecutar una división por una expresión cuyo valor pudiera ser cero, probar de
forma explícita este caso y manejarlo de manera apropiada en el programa que
se esté creando, por ejemplo, se puede imprimir un mensaje de error en lugar de
permitir que ocurra un error fatal al momento de ejecutarse el programa.
13. En una estructura switch, cuando la cláusula default se enlista al final, el
enunciado break no es requerido, pero se recomienda incluirlo para fines de
claridad y simetría con otros cases.
84
Sobre estructuras repetitivas
1. Controlar el contador de ciclos con valores enteros, es decir, aunque se permite
usar variables reales, lo adecuado es usar variables de tipo int.
2. Coloca sangrías en los enunciados del cuerpo de cada estructura de control
repetitiva.
3. Demasiados niveles anidados pueden dificultar la comprensión de un programa.
Como regla general evitar el uso de más de tres niveles.
4. Colocar sólo expresiones que involucren las variables de control en las secciones
de inicialización y de incremento de una estructura for. Las manipulaciones de
las demás variables deberían de aparecer, ya se antes del ciclo (si se ejecutan una
vez, como los enunciados de inicialización) o dentro del cuerpo del ciclo (si se
ejecutan una vez en cada repetición, como son los enunciados incrementales o
decrementales).
5. Aunque el valor de la variable de control puede ser modificado en el cuerpo de
un ciclo for, ello podría ocasiones a errores sutiles, por tanto, lo mejor es no
cambiarlo.
6. Al ciclar a través de un arreglo, el subíndice de un arreglo no debe de pasar
nunca por debajo de 0 y siempre tiene que ser menor que el número total de
elementos del arreglo (tamaño - 1).
7. Asegurarse que la condición de terminación del ciclo impida el acceso a
elementos fuera de ese rango.
Sobre funciones
1. Colocar una o dos líneas en blanco entre definiciones de función para separarlas
y para mejorar la legibilidad del programa.
2. Aunque una función por omisión regrese un valor de tipo entero, no omitirlo en
la declaración de la función sino utilizar el tipo int en forma explícita.
3. Aunque hacerlo no es incorrecto, no utilizar los mismos nombres para los
argumentos que se pasan a una función y los que se usan en el momento de la
definición de la función, para evitar cualquier ambigüedad.
4. Dar nombres a las funciones de acuerdo a lo que evaluarán como se sugiere con
las variables.
5. Incluir prototipos de función para todas las funciones que se vayan a utilizar.
6. Si se requiere que una función regrese más de un valor o, una función recibirá
demasiados parámetros, entonces se sugiere dividir a esa función en funciones
más pequeñas.
7. La declaración de una variable como global en lugar de local, permite que
ocurran efectos colaterales no deseados cuando una función que no requiere de
acceso a dicha variable, la modifica accidentalmente. En general, el uso de
variables globales debe ser evitado.
85
¿Cómo NO realizar una práctica de programación?
1. Ignorar los mensajes de error.
2. Ignorar las advertencias (warnings).
3. Escribir código directamente sin plantear un algoritmo.
4. Aunque el código no compile o no funcione, seguir programando.
5. Si el código tiene un error que no se produce siempre, ignorarlo y seguir
escribiendo.
6. Si el código tiene un error que se produce siempre, cambiar cosas
aleatoreamente hasta que desaparezca.
7. Construir enormes porciones de código sin compilar, ejecutar y probar.
8. No escribir comentarios, salvo los obligatorios.
9. Ignorar los enunciados y detalles que se especifican en un problema a resolver.
10. Ignora las normas de programación y estructura de un programa.
11. No aprender a utilizar el depurador ni otras herramientas.
12. No aislar o separar el problema en subproblemas.
86
REFERENCIAS
Arellano Pimentel, J. J., Nieva García O. S., Solar González, R. y Arista López, G.
(2012). Software para la enseñanza-aprendizaje de algoritmos estructurados. Revista
Iberoamericana de Educación en Tecnología y Tecnología en Educación. No. 8. ISSN
1850-9959. Red de universidades Nacionales con Carrera en Informática – Universidad
Nacional de la La Plata (RedUNCI-UNLP).
Bermúdez Juárez B., Beltrán Martínez, B., Bello López, P., Cervantes Márquez, A. P.,
Castillo Zacatelco, H., De La Rosa Flores, R., Galicia Hernández, Y., López Ramírez,
C., Martín Ortíz, M., Mendoza Alonso, L., Somodevilla Garcia, M.J., Vazquez Flores,
A. (2003). Notas de Curso. Facultad de Ciencias de la Computación de la Benemérita
Universidad Autónoma de Puebla, México.
Berzal Galiano, F. (s.f.). Introducción
http://elvex.ugr.es/decsai/java/
a
la
informática.
Recuperado
de:
Cairó Battistutti, O. (2006). Fundamentos de programación. Piensa en C (1ra. ed.).
México: Pearson Educación de México, S.A. de C.V.
Ceballos, F.J. (1997). Enciclopedia del Lenguaje C. México: Alfaomega Grupo Editor.
Deitel, H.M. & Deitel, P. J. (1995). Cómo programar en C/C++ (2da. ed.). México:
Prentice Hall Hispanoamericana, S.A.
DRAE (2014). Diccionario de la Real Academia Española. Recuperado de:
http://www.rae.es/ (concepto de pixel o píxel en el apartado 1 conceptos básicos)
Hooshyar, D., Alrashdan, M. and Mikhak, Masih. (2013). Flowchart-based
Programming Environments Aimed at Novices. International Journal of Innovative
Ideas. ISSN: 2232-1942. Vol. 3. No. 1.
Novara, Pablo. (2010). Fundamentos de programación, Asignatura correspondiente al
plan de estudios de la carrera de Ingeniería Informática (Anexo 1). Universidad
Nacional del Litoral, Facultad de Ingeniería y Ciencias Hídricas, Departamento de
Informática. Recuperado de: http://zinjai.sourceforge.net/Anexo1.pdf
Marzal, A. & Gracia, I. (2006). Introducción a la programación con Python, Edición
Internet. Departamento de Lenguajes y Sistemas Informáticos, Universitat Jaume I.
Rodríguez Corral, J.M. y Galindo Gómez, J. (2009). Aprendiendo C (3ra. ed.). España:
Servicio de Publicaciones de la Universidad de Cádiz.
Wikipedia. (2015). Instituto Nacional Estadounidense de Estándares. Recuperado de:
http://es.wikipedia.org/wiki/Instituto_Nacional_Estadounidense_de_Est%C3%A1ndares
87
![Primer Exámen Departamental [14/FEB/2015]](http://s2.esdocs.com/store/data/000592674_1-7d96ea8b87365b49685a94897bc90082-250x500.png)
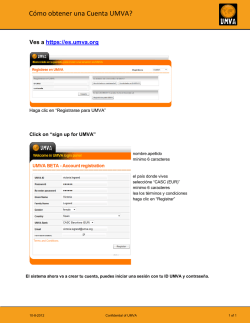

© Copyright 2026