
APUNTES DE ESTADÍSTICA. Prof. Germán Ernesto Rincón Rey.
APUNTES DE ESTADÍSTICA. Prof. Germán Ernesto Rincón Rey. Departamento De Ciencias Básicas, Unidades Tecnológicas de Santander. Departamentos de Ciencias Básicas 2013 Contenido Introducción ................................................................................................................................................................. 1 1 ARREGLO Y PRESENTACIÓN DE DATOS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 1.1 ASPECTOS GENERALES DE LA ESTADÍSTICA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 1.1.1 LOS FENÓMENOS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 1.1.2 LOS FENÓMENOS PRODUCEN INFORMACIÓN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 2 1.1.3 DEFINICIÓN DE ESTADÍSTICA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 1.1.4 IMPORTANCIA DE LA ESTADÍSTICA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 1.1.5 DIVISIÓN DE LA ESTADÍSTICA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 1.1.6 ESTADÍSTICA DESCRIPTIVA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 1.1.7 INFERENCIA ESTADÍSTICA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 1.1.8 FASES DE UNA INVESTIGACIÓN ESTADÍSTICA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 3 1.2 CONCEPTOS BÁSICOS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 1.2.1 DATO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 1.2.2 ELEMENTO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 5 1.2.3 EJEMPLOS DE ELEMENTOS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6 1.2.4 POBLACIÓN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6 1.2.5 COMO SE DEFINE UNA POBLACIÓN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6 1.2.6 TAMAÑO DE UNA POBLACIÓN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 6 1.2.7 CLASES DE POBLACIONES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7 1.2.8 Poblaciones Finitas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7 1.2.9 Poblaciones infinitas . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7 1.2.10 CARACTERÍSTICAS OBSERVABLES EN UNA POBLACIÓN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7 1.2.11 CARACTERÍSTICAS CONSTANTES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 7 1.2.12 CARACTERÍSTICAS VARIABLES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 8 1.2.13 CENSO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9 1.2.14 MUESTRA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9 1.2.15 TAMAÑO DE LA MUESTRA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9 1.2.16 PARÁMETRO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9 1.2.17 ESTADÍSTICO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 9 1.2.18 TIPOS DE ESTUDIOS ESTADÍSTICOS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10 1.2.19 UNIDAD DE OBSERVACIÓN O DE INVESTIGACIÓN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10 1.2.20 ESTADÍSTICAS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 10 1.3 ARREGLO DE DATOS DE VARIABLE CONTINUA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11 1.3.1 INTRODUCCIÓN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11 1.3.2 CONCEPTO DE CLASE O CATEGORÍA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11 Estadística Departamento de Ciencias Básicas uts CONTENIDO 3 1.3.3 CLASE ESTADÍSTICA O CATEGORÍA ESTADÍSTICA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11 1.3.4 AMPLITUD DE CLASE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 11 1.3.5 CARACTERÍSTICAS DE LOS CONJUNTOS DE CLASES ESTADÍSTICAS . . . . . . . . . . . . . . . . . . . . . . . . . 11 1.3.6 NÚMERO DE CLASES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 12 1.3.7 MÉTODO ESTADÍSTICO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13 1.3.8 PROCEDIMIENTO PARA PRINCIPIANTES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 13 1.3.9 DESARROLLO DEL EJEMPLO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 14 1.3.10 LOS TIPOS DE FRECUENCIAS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15 1.3.11 LECTURA DE LA DISTRIBUCIÓN DE FRECUENCIAS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15 1.3.12 LA TABLA MENOR QUE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 15 1.3.13 REPRESENTACIÓN GRÁFICA DE LA SITUACIÓN EN ESTUDIO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16 1.3.14 EL HISTOGRAMA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16 1.3.15 EL POLÍGONO DE FRECUENCIAS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16 1.3.16 MARCA DE CLASE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 16 1.3.17 COMO INTERPRETAR UN HISTOGRAMA O UN POLÍGONO DE FRECUENCIAS . . . . . . . . . . . . . . . . . . . . . 18 1.3.18 LA OJIVA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 18 1.3.19 LA INTERPOLACIÓN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 19 1.4 ARREGLO DE DATOS DE VARIABLE DISCRETA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21 1.4.1 PROCEDIMIENTO PARA PRINCIPIANTES . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21 1.4.2 EJEMPLO PRÁCTICO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 21 1.4.3 REPRESENTACIÓN GRÁFICA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 23 1.5 ARREGLO DE DATOS PARA VARIABLE DISCRETA EN CLASES DE AMPLITUD CERO . . . . . . . . . . 26 1.5.1 EJEMPLO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 26 1.6 ARREGLO DE DATOS CUALITATIVOS . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27 1.6.1 EJEMPLO . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 27 2 MEDIDAS DE TENDENCIA CENTRAL, DE POSICIÓN Y DE DISPERSIÓN . . . . . . . . . 29 2.1 MEDIDAS DE TENDENCIA CENTRAL Y DE POSICIÓN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29 2.1.1 Formas estadísticas de describir un fenómeno . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29 2.1.2 Concepto de medida en Estadística . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29 2.1.3 Parámetros y Estadísticos . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 29 2.1.4 Clases de medidas en Estadística 2.1.5 Las medidas de Tendencia Central . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30 2.1.6 Las medidas de Tendencia No Central o de Posición . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30 2.1.7 Las medidas de dispersión . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30 2.1.8 Medidas para poblaciones y medidas para muestras . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30 2.1.9 Clases de medidas de Tendencia Central . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30 2.1.10 LA MEDIA ARITMÉTICA SIMPLE . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30 2.1.11 Media Aritmética para datos agrupados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 32 2.1.12 Significado de la Media Aritmética . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33 2.1.13 LA MEDIA ARITMÉTICA PONDERADA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 33 2.1.14 Propiedades de la Media Aritmética 2.1.15 LA MEDIA GEOMÉTRICA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 35 2.1.16 Propiedad de la Media Geométrica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38 2.1.17 Usos de la Media Geométrica . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38 2.1.18 LA MEDIANA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 38 uts . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 30 . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 34 Estadística Departamento de Ciencias Básicas 4 CONTENIDO 2.1.19 Interpretación de la mediana . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39 2.1.20 Símbolo de la mediana . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39 2.1.21 Cálculo de la mediana para datos no agrupados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 39 2.1.22 Cálculo de la mediana para datos agrupados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 40 2.1.23 MEDIDAS DE TENDENCIA NO CENTRAL O DE POSICIÓN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42 2.1.24 Los Cuartiles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 42 2.1.25 Cuartiles para datos agrupados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 43 2.1.26 Los Percentiles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45 2.1.27 Percentiles para datos agrupados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 45 2.1.28 Propiedades de la mediana, cuartiles y percentiles . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 47 2.1.29 LA MODA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48 2.1.30 Símbolo de la moda . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48 2.1.31 Moda para datos no agrupados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 48 2.1.32 Moda para datos no agrupados . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 49 2.1.33 Propiedades de la moda . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 51 2.1.34 CASOS ESPECIALES DE LA MEDIANA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 52 2.1.35 Distribuciones de frecuencias para datos de variable discreta agrupados en clases con amplitud igual a cero . . . . . 52 2.2 MEDIDAS DE DISPERSIÓN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 54 2.2.1 Concepto de dispersión . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55 2.2.2 Dispersión y variabilidad . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 55 2.2.3 Importancia de la dispersión . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 56 2.2.4 Clases de medidas de dispersión . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57 2.2.5 El Rango . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57 2.2.6 Ejemplo: . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 57 2.2.7 Características del rango . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58 2.2.8 El Rango Intercuartílico . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 58 2.2.9 La Desviación Media . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 59 2.2.10 La Varianza . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 61 2.2.11 La varianza poblacional . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 62 2.2.12 Varianza Muestral . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 63 2.2.13 La Desviación Estándar . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 65 2.2.14 El coeficiente de Variación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 67 3 REGRESIÓN Y CORRELACIÓN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70 3.1 REGRESIÓN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70 3.1.1 Introducción . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70 3.1.2 Concepto de Regresión . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 70 3.1.3 Importancia de la Regresión . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71 3.1.4 Variables dependientes e independientes . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71 3.1.5 Gráfico de dispersión . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 71 3.1.6 Tipos de relación entre dos o mas variables . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 72 3.1.7 Tipos de regresión . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73 3.1.8 Regresión Lineal Directa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 73 3.1.9 Regresión lineal Inversa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 74 3.1.10 Regresión curvilínea Directa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 75 3.1.11 Regresión Curvilínea Inversa . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 76 3.1.12 Ninguna relación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 77 Estadística Departamento de Ciencias Básicas uts CONTENIDO 1 3.1.13 La Regresión Lineal . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 78 3.2 LA CORRELACIÓN . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 80 3.2.1 Relación entre el coeficiente de correlación y la pendiente de la recta de regresión . . . . . . . . . . . . . . . . . . . . . 82 3.2.2 El Coeficiente de Determinación . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 82 4 BIBLIOGRAFÍA . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . . 84 uts Estadística Departamento de Ciencias Básicas Introducción 1 1.1 1.1.1 ARREGLO Y PRESENTACIÓN DE DATOS ASPECTOS GENERALES DE LA ESTADÍSTICA LOS FENÓMENOS Un fenómeno es cualquier manifestación de las actividades humanas o de la naturaleza que puede ser percibido por los sentidos o la razón. Algunos ejemplos de fenómenos son los siguientes: . El crecimiento de una planta. . El comportamiento del clima. . Las ventas por periodo de una empresa. . Las personas, por día, que son afectadas por una enfermedad. . Los accidentes de tránsito en diferentes lugares de una ciudad. . La variación mensual del costo de vida. 1.1.2 LOS FENÓMENOS PRODUCEN INFORMACIÓN Por muchos motivos los seres humanos desean poseer información sobre el comportamiento de diversos fenómenos y para ello realizan registros sobre el estado de estos fenómenos en diferentes momentos o espacios. Estos registros o mediciones generan diversos volúmenes de datos y para que estos datos se conviertan en información se deben procesar de diferentes maneras. Una de las formas como se pueden tratar los datos para extraer la información que ellos contienen es utilizando las técnicas estadísticas. Estadística Departamento de Ciencias Básicas uts 3 1.1.3 DEFINICIÓN DE ESTADÍSTICA Es una ciencia que estudia cómo debe emplearse información para facilitar la toma de decisiones en situaciones prácticas que se manifiestan bajo incertidumbre. 1.1.4 IMPORTANCIA DE LA ESTADÍSTICA La actividad más importantes para las personas que trabajan en las organizaciones empresariales es la toma de decisiones. Dado el enorme aumento de la disponibilidad de datos (gracias a los sistemas de información), y dada la complejidad creciente de las operaciones empresariales, los procesos de decisión se ven sometidos a presiones extraordinarias. Una de las técnicas más valiosa que ayudan en los procesos de toma de decisiones es la Estadística. Por lo que es indispensable que los hombres y mujeres que dirigen organizaciones o que de alguna manera participan en la toma de decisiones estén familiarizados con las técnicas estadísticas para poder determinar cuando se puede examinar un problema existente mediante la aplicación del análisis estadístico. 1.1.5 DIVISIÓN DE LA ESTADÍSTICA La Estadística se divide en dos grandes ramas: . La Estadística Descriptiva . La Inferencia Estadística 1.1.6 ESTADÍSTICA DESCRIPTIVA Son los conocimientos y métodos que tratan de la recolección, organización y presentación numérica y gráfica de los datos. Los análisis que se hacen con las herramientas de la estadística descriptiva se limitan, únicamente, al conjunto de datos que se recolectaron. Palabras sinónimas de fenómeno son: suceso, hecho o acontecimiento. 1.1.7 INFERENCIA ESTADÍSTICA Son los conocimientos y métodos que permiten: . Sacar conclusiones sobre el comportamiento total de un fenómeno basándose únicamente en la información recolectada sobre una parte de ese mismo fenómeno. Estas conclusiones se obtienen bajo incertidumbre. . Estimar el comportamiento futuro de un fenómeno. 1.1.8 FASES DE UNA INVESTIGACIÓN ESTADÍSTICA 1. Planeamiento . Fin de la investigación . Unidad de investigación uts Estadística Departamento de Ciencias Básicas 4 ARREGLO Y PRESENTACIÓN DE DATOS . Definir la población . Naturaleza o clase de los datos . Fuentes de la información . Procedimiento para recolectar los datos . Diseño de instrumentos . Presupuesto 2. Recolección de los datos 3. Crítica y codificación 4. Tabulación, gráficas y medidas 5. Análisis e interpretación Estadística Departamento de Ciencias Básicas uts 5 1.2 1.2.1 CONCEPTOS BÁSICOS DATO En términos generales un dato es un registro o anotación que se hace del estado de un fenómeno en un momento determina. 1.2.2 ELEMENTO En general, un elemento es una parte indivisible de un todo o un componente indivisible o básico de un cuerpo. Pero, en estadística se llama elemento a las entidades que tienen una o varias características cuyo estado nos interesa registrar. El registro del estado de estas características es lo que constituye los datos. Estos elementos pueden ser individuos, objetos o sucesos. Los individuos pueden ser personas o seres vivos animales o vegetales. Los sucesos pueden ser, por ejemplo, los accidentes de tránsito, los encuentros deportivos, los recorridos que realiza un vehículo o los días del año. Figura 1.1: Tabla No.1 uts Estadística Departamento de Ciencias Básicas 6 ARREGLO Y PRESENTACIÓN DE DATOS 1.2.3 EJEMPLOS DE ELEMENTOS . En una investigación sobre el comportamiento de los salarios de trabajadores los elementos son los trabajadores (personas), y la característica que se observa a cada elemento es el valor de su salario. . En una investigación sobre comportamiento de las ventas de una comercializadora los elementos podrían ser las facturas (un objeto), y la característica observada es el valor de cada factura. . También, en una investigación sobre comportamiento de las ventas de una comercializadora los elementos podrían ser los meses (un suceso), y la característica observada el valor de las ventas de cada mes. . En una investigación sobre los accidentes de tránsito los elementos son los accidentes (un suceso), y la característica observada podría ser el número de personas lesionadas por accidente observado. Los fenómenos se producen cuando el estado de las características observadas varía, usualmente, de un elemento a otro. 1.2.4 POBLACIÓN . Todos los elementos que presentan una característica común . Es el conjunto de todos los elementos que hacen parte de una situación que se está estudiando y sobre la cual se intenta sacar conclusiones Las poblaciones se deben definir con toda claridad de tal manera que no exista confusión sobre si un determinado elemento pertenece o no a la población 1.2.5 COMO SE DEFINE UNA POBLACIÓN Las poblaciones se deben definir con toda claridad de tal manera que no exista confusión sobre si un determinado elemento pertenece o no a la población. Para facilitar esta definición, en muchos casos, las palabras que la componen se pueden ordenar de acuerdo a la siguiente sintaxis: TODOS(AS) + DESCRIPCIÓN DEL ELEMENTO + CONDICIÓN RESTRICTIVA Significa que una definición de población debe empezar por la palabra ?Todos? o ?Todas? seguida de una descripción del elemento que se está observando mas una restricción al alcance de la palabra Todos(as) Ejemplo: En un estudio del nivel salarial de los operarios del sector de confecciones de la ciudad, una definición de población podría ser la siguiente: Todos los operarios del sector de confecciones de la ciudad 1.2.6 TAMAÑO DE UNA POBLACIÓN Es el número total de elementos que componen una población. El tamaño de una población se suele representar por la letra N Estadística Departamento de Ciencias Básicas uts 7 EJEMPLO: Para indicar que una población tiene 670 elementos se indica así: N = 670 1.2.7 CLASES DE POBLACIONES Las poblaciones se dividen en dos clases: . Poblaciones finitas . Poblaciones infinitas 1.2.8 Poblaciones Finitas Son las poblaciones a las cuales se les pueden determinar fácilmente el número de elementos que las componen, es decir, su tamaño. EJEMPLO: Situación o fenómeno: La edad de los estudiantes de las UTS Población: Todos los estudiantes de las UTS Tipo de población: Finita, porque fácilmente se pueden contabilizar sus elementos acudiendo a la oficina de la institución que registra estos datos 1.2.9 Poblaciones infinitas . Son las poblaciones que físicamente es imposible numerarlas o determinar su tamaño . Son las poblaciones que aunque se puede determinar su tamaño, no es conveniente hacerlo por razones económicas o de tiempo EJEMPLO: Situación:Accidentes por día en un cruce de calles de la ciudad Población: Todas los días mientras exista este cruce Tipo de población: Infinita. Es imposible determinar cuántos elementos tiene esta población. EJEMPLO: Situación: Número promedio de hijos por pareja de un barrio de la ciudad Población: todas las parejas que habitan en el barrio Tipo de población: Infinita. Es muy costoso o demanda mucho tiempo determinar su tamaño 1.2.10 CARACTERÍSTICAS OBSERVABLES EN UNA POBLACIÓN A los elementos de una población se les observan sus características o la intensidad con que se presenta una magnitud. De acuerdo con su comportamiento las características que se observan en los elementos de una población se pueden clasificar en constantes o variables 1.2.11 CARACTERÍSTICAS CONSTANTES Una característica es constante cuando el valor que presenta esta característica no varía de un elemento a otro o varía muy poco; por ejemplo, la estatura de una persona adulta observada en los últimos 20 meses o la profesión de un graduado universitario. uts Estadística Departamento de Ciencias Básicas 8 ARREGLO Y PRESENTACIÓN DE DATOS 1.2.12 CARACTERÍSTICAS VARIABLES . Es una característica que cambia frecuentemente de valor cuando se observa en algunos o en todos los elementos de la población . Es un símbolo que puede tomar diversos valores dentro de un conjunto determinado de valores que reciben el nombre de dominio de la variable.(Significado matemático) La estadística solamente estudia las características variables Estas características variables, comúnmente denominadas variables, pueden ser de dos clases: . Variables cualitativas o categóricas . Variables cuantitativas 1.2.12.1 Variables Cualitativas o Categóricas Son las que describen el estado de la característica únicamente mediante palabras. Se refieren a atributos, cualidades, actitudes o preferencias de los elementos que se están estudiando EJEMPLOS . Las profesiones u ocupaciones de un grupo de personas: Abogado, maestro, panadero, ingeniero, etc . El estado civil de un grupo de personas: Soltero, casado, unión libre, etc. . El sabor de las naranjas de una cosecha: dulce, insípido, ácido . El color favorito de un grupo de individuos: Blanco, rojo, verde, etc. . Pasatiempos de un grupo de estudiantes: Deportes, lectura, reuniones sociales, labores manuales, etc . La calidad de un producto: Bueno, regular o defectuoso Como se puede observar, en los ejemplos, cada una de estas variables se expresa a través de dos o más modalidades o categorías: soltero, casado, unión libre; bueno, regular, defectuoso.? Los datos que se registran cuando las variables son cualitativas o categóricas corresponden a la cantidad o proporción de elementos que caen dentro de cada categoría que toma la variable, por ejemplo: el número de abogados o de maestros, el número de individuos que prefieren el color blanco, la proporción de productos defectuosos. Las variables categóricas se pueden a su vez subdividir en variables nominales y variables ordinales 1.2.12.2 Variables Nominales: Son las que no tienen una forma particular de organizar sus categorías. Por ejemplo, no existe una forma común de ordenar los colores o el estado civil de las personas. Cuando existe una forma común de organizar las categorías que toma la variable. Por ejemplo: las modalidades como se puede expresar la calidad de un producto se pueden ordenar como bueno, regular, defectuoso o al contrario, en defectuoso, regular, bueno. Las categorías con las que se califica el servicio que presta una EPS se pueden ordenar como pésimo, malo, regular, bueno o excelente. 1.2.12.3 Variables ordinales : Variables cuantitativas: Son las que se describen por medio de números, por ejemplo, la edad de los empleados de una empresa, las personas que visitan por día un museo, los saldos de las cuentas por cobrar de una empresa, el peso de los paquetes que moviliza una empresa transportadora, el número de vehículos que vende un concesionario, etc. 1.2.12.4 Estadística Departamento de Ciencias Básicas uts 9 Las variables cuantitativas se pueden clasificar, también, en discretas o continuas: Son las que únicamente pueden tomar valores enteros tales como el número de vehículos que vende un concesionario o el número de personas que asisten a una sala de cine 1.2.12.5 Variables cuantitativas discretas : 1.2.12.6 Variables cuantitativas continuas: Son las que se refieren a mediciones de magnitudes físicas o a características apreciables en unidades monetarias y admiten valores fraccionarios o decimales tales como el peso de los paquetes que moviliza una transportadora, los saldos de las cuentas de ahorro de una entidad financiera o el tiempo que dura el recorrido de un bus urbano. Cuando se quiere facilitar el manejo de los datos o aumentar la comprensión de un fenómeno, las variable cuantitativas se pueden convertir en categóricas, como cuando las personas que miden menos de 1.50 metros se clasifican como de estatura pequeña, las personas que miden entre 1.50 metros y menos de 1.70 se clasifican como de estatura mediana y las personas que miden 1.70 metros o más se clasifican como de estatura alta. 1.2.12.7 Variables cuantitativas categóricas : 1.2.13 CENSO Es cuando se observa y registra el estado de una característica examinado a todos los elementos de una población. Los censos rara vez se realizan debido al tiempo que demandan y a la cantidad de recursos que necesitan por lo que se recurre a tomar datos del estado de la variable en algunos de los elementos de la población. 1.2.14 MUESTRA Es cuando se observa y registra el estado de una característica variable examinado a una parte de los elementos que pertenecen a una población Las muestras deben ser representativas y para esto se requiere que las características de la población estén representadas en la muestra, en la misma proporción en que están incluidas en la población 1.2.15 TAMAÑO DE LA MUESTRA Es el número de elementos que componen la muestra. Se suele indicar con la letra n EJEMPLO: Para indicar que una muestra tiene 350 elementos se indica así: n = 350 1.2.16 PARÁMETRO Es el resultado de una medida o cálculo que se hace utilizando los datos relacionados con el valor que toma una característica variable cuando se observan todos los elementos de una población, es decir, cuando se hace un censo. Por ejemplo, la edad promedio de los niños que cursan primer grado, este año, en todas las escuelas oficiales de la ciudad. El parámetro siempre es un valor constante. 1.2.17 ESTADÍSTICO Es el resultado de una medida o cálculo que se hace utilizando los datos relacionados con el valor que toma una característica variable cuando se observan algunos de los elementos de una población, o sea, una muestra. Por ejemplo, la edad promedio de los niños de primer grado de algunas escuelas oficiales de la ciudad escogidas al azar. El estadístico es un valor que varía de muestra en muestra. uts Estadística Departamento de Ciencias Básicas 10 ARREGLO Y PRESENTACIÓN DE DATOS 1.2.18 TIPOS DE ESTUDIOS ESTADÍSTICOS Los estudios estadísticos pueden ser experimentales y de observación En los estudios estadísticos experimentales el investigador controla o manipula una o varias variables con el fin de determinar su comportamiento en determinadas condiciones En los estudios estadísticos de observación el investigador registra el estado de la característica variable que le interesa sin ejercer ninguna influencia sobre ella. El estudio estadístico de observación mas común es la encuesta 1.2.19 UNIDAD DE OBSERVACIÓN O DE INVESTIGACIÓN Se llama Unidad de Observación o de Investigación a alguno de los siguientes conceptos: . Al nombre genérico, que se le da a los elementos cuya característica se está registrando . A la entidad que se investiga o de la que se recolectan los datos . Al soporte de donde se extraen los datos 1.2.20 ESTADÍSTICAS Es cualquier conjunto ordenado de datos como por ejemplo las estadísticas de un torneo de fútbol, las estadísticas de ventas de una empresa o las estadísticas de accidentes Estadística Departamento de Ciencias Básicas uts 11 1.3 1.3.1 ARREGLO DE DATOS DE VARIABLE CONTINUA INTRODUCCIÓN Para visualizar las características de una situación representada por un conjunto de datos o establecer el patrón de comportamiento de esta situación, los datos se deben organizar de alguna manera. La Estadística propone una metodología que consiste en agrupar los datos recolectados en conjuntos de categorías o clases estadísticas y con este conjunto construir una tabla que se llama Distribución de Frecuencias 1.3.2 CONCEPTO DE CLASE O CATEGORÍA En general, una clase o categoría es un conjunto de elementos que tienen una o varias características en común, por ejemplo, las personas que compiten en algún deporte pertenecen a la clase de los deportistas, las personas mayores de 60 años pertenecen a la clase de la tercera edad 1.3.3 CLASE ESTADÍSTICA O CATEGORÍA ESTADÍSTICA En estadística se llama clase, únicamente, a un conjunto de datos que están dentro de un intervalo determinado de valores. Por ejemplo, para datos correspondientes a ingresos de personas podemos crear una clase de las personas que tienen ingresos entre $500.000 y $800.000. Toda clase estadística tiene, por lo tanto, un límite inferior ($500.000),y un límite superior ($800.000) 1.3.4 AMPLITUD DE CLASE Es la distancia o diferencia que hay entre los límites de una clase. En el ejemplo anterior la amplitud de la clase de ingresos es de $300.000. Es decir, que para calcular la amplitud de clase se resta del límite superior de la clase el límite inferior. Para expresar estas ideas en símbolos, llamamos A a la amplitud de la clase, LS al límite superior de la clase y LI al límite inferior de la clase, expresando aritméticamente la amplitud de la clase así: Para el ejemplo: A = LS − LI = $800.000 − $500.000 = $300.000 Entonces, para visualizar las características de un conjunto de datos, la Estadística propone que se agrupen estos datos en intervalos de valores o categorías o clases 1.3.5 CARACTERÍSTICAS DE LOS CONJUNTOS DE CLASES ESTADÍSTICAS Un conjunto de clases o categorías es considerado como un conjunto de clases estadístico sí todas las clases, del conjunto, tienen, simultáneamente, las siguientes tres características: . Amplitud constante . Mutuamente excluyentes . Exhaustivas se refiere a que la amplitud de todas las clases de un conjunto de clases en que se agrupa un determinado grupo de datos debe ser la misma para todo el conjunto 1.3.5.1 uts Amplitud constante Estadística Departamento de Ciencias Básicas 12 ARREGLO Y PRESENTACIÓN DE DATOS Conjunto de clases mutuamente excluyentes se refiere a que cualquier dato, de un grupo de datos en estudio, debe corresponder únicamente a una sola clase 1.3.5.2 1.3.5.3 Conjunto de clases exhaustivas cuando el conjunto de clases puede contener a todos los datos de una muestra. 1.3.6 NÚMERO DE CLASES Una de las primeras inquietudes que surge cuando se van a agrupar un conjunto de datos en clases estadísticas es en cuantas clases es conveniente o adecuado agrupar estos datos. Hay varios criterios para resolver este problema: . El número de clases es determinado por una circunstancia deseable u obligante . Determinar el número de clases de clases orientándose por una norma empírica de la estadística . Determinar el número de clases utilizando la expresión empírica: No.C = 2K . Determinar el número de clases utilizando la expresión empírica: No.C = 1 + 3, 3log(n) . Otros criterios El primer caso se presenta, por ejemplo, cuando el estudio actual se va a comparar con un estudio anterior o un estudio realizado por otro investigador. Entonces, para facilitar las comparaciones entre los dos estudios, es deseable que los datos del estudio actual se agrupen con el mismo número de clases del estudio anterior La norma empírica de la estadística indica que el número de clases en que se deben agrupar cualquier conjunto de datos debe ser como mínimo 5 ó 6 clases y como máximo alrededor de 20 clases En la expresión No.C = 2K, No.C es abreviatura de número de clases y K indica las clases en que, según esta expresión, se deben agrupar los datos. Por ejemplo, para un estudio contiene 155 datos esta expresión funciona así: Sí K = 6 clases, entonces, No.C = 26 = 64 como 64 < 155 el número de clases igual a 6 no es conveniente Sí K = 7 clases, entonces, No.C = 27 = 128 como 128 < 155 el número de clases igual a 7 no es conveniente Sí K = 8 clases, entonces, No.C = 28 = 256 como 256 > 155 el número de clases igual a 8, según este procedimiento, es el más adecuado para agrupar los 155 datos del estudio. En la expresión No.C = 1 + 3, 3log(n), No,C es también, abreviatura de número de clases, log se refiere a logaritmo con base 10 y n es la cantidad de datos que se desean agrupar Por ejemplo, para el estudio de 155 datos se tiene: No.C = 1 + 3, 3log(155) = 8, 23, quiere decir que el número conveniente de clases, para agrupar estos 155 datos es de 8 clases Otros criterios pueden ser, por ejemplo, números de clases que hacen que los límites de las clases sean muy fáciles de establecer o que las clases automáticamente queden mutuamente excluyentes. Estadística Departamento de Ciencias Básicas uts 13 Este ejemplo es útil para fines de aprendizaje, porque en situaciones reales, se suelen manejar volúmenes de datos muy superiores al del presente ejemplo La siguiente tabla se refiere a los galones de gasolina corriente que tanquearon la semana pasada, en un autoservicio, una muestra de vehículos escogidos al azar Este ejemplo es útil para fines de aprendizaje, porque en situaciones reales, se suelen manejar volúmenes de datos muy superiores al del presente ejemplo 1.3.7 MÉTODO ESTADÍSTICO Como se dijo al comienzo de este tema, para describir una situación representada por un conjunto de datos, como el anterior, la estadística propone agrupar los datos en un conjunto de clases o categorías y con este conjunto construir una tabla que se llama Tabla de Frecuencias o Distribución de Frecuencias. Para realizar este proceso se deben resolver, en primera instancia, las siguientes preguntas: . ¿En cuántas clases o categorías es más conveniente o se desea agrupar las datos recolectados? . ¿Cuál es el tipo de variable relacionada con la situación o fenómeno en estudio? . ¿Cómo se construyen estas clases o categorías? . ¿Cómo se construye una Distribución de Frecuencias? Para resolver estas preguntas se propone el siguiente procedimiento: 1.3.8 PROCEDIMIENTO PARA PRINCIPIANTES 1. Para establecer el número de clases: . Por conveniencia . Norma empírica . Fórmulas exponencial o logarítmica 2. Tipo de variable relacionada con la situación en estudio . (Revisar el tema en el módulo CONCEPTOS BÁSICOS) 3. Construcción de las clases o categorías Existen muchas formas para realizar este paso. A continuación se propone una de ellas: . Determinar los valores máximo y mínimo del conjunto de datos: Xmax y Xmin . Calcular el Rango, R = Xmax − Xmin . Calcular la amplitud de las clases: A = R No.C . Modificar la amplitud teniendo en cuenta los decimales de los datos ( Amod ) uts Estadística Departamento de Ciencias Básicas 14 ARREGLO Y PRESENTACIÓN DE DATOS . Ajustar el rango ( Rmod ), para que coincida con la nueva amplitud modificada . Ajustar Xmin o Xmax o ambos para que coincidan con el rango modificado . Fijar el limite inferior de la primera clase . Construir los límites de las clases . Verificar que las clases cumplan con las tres características de las clases estadísticas 4. Construcción de la Distribución de frecuencias . Establecer el número de observaciones dentro de cada clase ( FA ) ( tabla de conteo ) . Calcular la frecuencia relativa ( FR ) . Ajustar la frecuencia relativa para que la suma de igual a 1 . Calcular la frecuencia relativa acumulada ( FRA) 1.3.9 DESARROLLO DEL EJEMPLO 1. Determinar el número de clases El número de clases se puede determinar de acuerdo a los siguientes criterios: . Por conveniencia: Cuando exista alguna circunstancia que haga conveniente o deseable un determinado número de clases . Norma empírica: Se puede escoger cualquier número de clases entre 6 y 20 dependiendo del criterio o preferencia personal del analista y se hacen varios tanteos hasta encontrar un número de clases satisfactorio . Aplicando las fórmulas exponencial o logarítmica Aplicando la fórmula No.C = 2k Para K = 5 entonces 25 = 32 < 39 quiere decir que 5 no es un número conveniente de clases Para K = 6 entonces 26 = 64 > 39 quiere decir que 6 es el número conveniente de clases Aplicando la fórmula No.C = 1 + 3, 3log(n) = 1 + 3, 3log(39) = 6, 25 quiere decir que el número de clases conveniente es de 6 2. Tipo de variable: En este caso es una variable continua 3. Construcción de las clases o categorías: Estos pasos se presentan en la siguiente tabla y son específicos para variable continua TABLA No.1 N0C = 6 Xmax = 6, 9 Xmin = 1, 7 R = 5, 2 A = 0, 866667 Amod = 0, 9 Rmod = 5, 4 Rmod − R = 0, 2 0 Xmin = 1, 5 0 Xmin se refiere al límite inferior de la primera clase Estadística Departamento de Ciencias Básicas uts 15 4. Construcción de la Distribución de Frecuencias: El resultado de este proceso se presenta en la tabla No.2: La tabla No.2 recibe el nombre de DISTRIBUCIÓN DE FRECUENCIAS o TABLA DE FRECUENCIAS y los detalles de su construcción serán explicados por el docente en la exposición que haga sobre este tema y el significado de las columnas FA, FR y FRA se expone a continuación 1.3.10 LOS TIPOS DE FRECUENCIAS Los tipos de frecuencias que se presentan en la tabla No.2 son los siguientes: . Frecuencia Absoluta FA: Es la cantidad de datos de la muestra que corresponden a cada clase. Se obtiene por conteo. En la tabla No.2 corresponde al Número de Vehículos. . Frecuencia Absoluta Acumulada FAA: Se obtiene, para cada clase, sumando la frecuencia absoluta de la clase, FA, con la frecuencia absoluta de la clase anterior . Frecuencia Relativa FR: Se calcula, para cada clase, dividiendo la frecuencia absoluta de la clase, FA, entre el total de datos de la muestra. Es práctico que los valores de la frecuencia relativa se tomen con dos decimales y su suma se ajuste para que dé exactamente uno . Frecuencia Relativa Acumulada FRA: Se calcula, para cualquier clase, sumando la frecuencia relativa de la clase, FR, con la frecuencia relativa de la clase anterior 1.3.11 LECTURA DE LA DISTRIBUCIÓN DE FRECUENCIAS Esta tabla permite describir la situación histórica de la venta de gasolina en esta estación de servicio, por ejemplo, la mayoría de los vehículos de la muestra, un 36%, tanquearon entre 2,4 y 3,3 galones de gasolina, el 5% de los vehículos de la muestra tanquearon entre 5,1 y 6,0 galones de gasolina y fue la clase con menor frecuencia de tanqueo. Solamente tres vehículos de la muestra tanquearon más de 6,0 galones 1.3.12 LA TABLA MENOR QUE Es una tabla auxiliar que se construye a partir de las distribuciones de frecuencias acumuladas, FAA y FRA, con el fin de facilitar la descripción de la situación utilizando estas frecuencias. Esta tabla se encuentra al lado de la tabla de distribución de frecuencias y se utilizó, en este caso, la columna de frecuencia relativa acumulada. Observando esta tabla se puede ver que el 59% de los vehículos de la muestra tanquearon menos de 3,3 galones de gasolina o que el 13% de los vehículos de la muestra tanquearon mas de 5,1 galones uts Estadística Departamento de Ciencias Básicas 16 ARREGLO Y PRESENTACIÓN DE DATOS 1.3.13 REPRESENTACIÓN GRÁFICA DE LA SITUACIÓN EN ESTUDIO La Estadística Descriptiva utiliza tres tipos de gráficos para representar cualquier situación o fenómeno en estudio: . El histograma . El polígono de frecuencias . La ojiva Estos gráficos permiten visualizar de manera fácil y rápida los resultados que se presentan en la distribución de frecuencias 1.3.14 EL HISTOGRAMA Es un gráfico de frecuencia absoluta, FA o la frecuencia relativa, FR, donde las clases se representan mediante rectángulos. El siguiente histograma se refiere al ejemplo práctico y se utilizó la frecuencia relativa 1.3.15 EL POLÍGONO DE FRECUENCIAS Se hace a partir del histograma uniendo las marcas de clase proyectadas sobre el lado superior de los rectángulos y agregando, para cerrar la figura, dos clases adicionales, una, por encima del límite superior de la clase más alta y la otra, por debajo del límite inferior de la clase más baja Para construir el polígono de frecuencias necesitamos introducir el concepto de Marca de Clase 1.3.16 MARCA DE CLASE Es el punto medio de una clase. Se calcula sumando los límites de cada clase y dividiendo este total por 2. El símbolo que usualmente se utiliza para representar la marca de clase es xi Estadística Departamento de Ciencias Básicas uts 17 La expresión matemática de la marca de clase es: LS + LI 2 Donde LS es el límite superior de la clase y LI es el límite inferior de la clase. Por ejemplo, para construir la marca de clase de la primera clase se procede así: xi = xi = 1, 5 + 2, 4 = 1, 95 2 Las marcas de clase se utilizan, también, cuando se requiere representar todos los valores de una clase por un solo número. Por ejemplo, 1,95 galones representa todos los valores de la muestra que se encuentran entre 1,5 galones y 2,4 galones Se puede construir, entonces, con las marcas de clase, una tabla auxiliar de cálculos que permita elaborar fácilmente el polígono de frecuencias, como se presenta a continuación: Obsérvese que la tabla tiene ahora 8 clases porque se han agregado dos clases, la número cero y la número 7. A estas clases se les llama clases falsas porque no hay observaciones para ellas; su finalidad es presentar el polígono de frecuencias como una figura cerrada uts Estadística Departamento de Ciencias Básicas 18 ARREGLO Y PRESENTACIÓN DE DATOS Tanto el histograma como el polígono de frecuencias permiten visualizar algunas de las características de la situación o fenómeno que se está estudiando, tales como: . El rango de los datos . Alrededor de qué valores tienden a agruparse los datos . Valores de la muestra que se presentan con más o menos frecuencia . A qué lado de la gráfica parecen agruparse más los datos Los demás detalles de la construcción del polígono de frecuencias serán explicados por el docente en la exposición que haga sobre este tema 1.3.17 COMO INTERPRETAR UN HISTOGRAMA O UN POLÍGONO DE FRECUENCIAS Los histogramas y los polígonos de frecuencias facilitan a las personas que tienen que tomar decisiones sobre una determinada situación una visión rápida del comportamiento y características de la situación que se estudia. Algunas de las preguntas que se pueden responder observando estas gráficas son: . ¿Cuál es el rango de los datos? . ¿En qué clases se concentran el mayor número de datos? . ¿Cuál clase contiene menos datos? . ¿Qué valores de la muestra se presentan con más o menos frecuencia? . ¿A qué lado de la gráfica parecen concentrarse más los datos? . ¿Se presentan huecos o clases vacías? . ¿Se presentan valores aislados de los demás? . ¿La gráfica presenta subidas o bajadas bruscas o suaves? . ¿Cuántos picos tiene la gráfica? . ¿Es simétrica la gráfica? 1.3.18 LA OJIVA La ojiva es un gráfico de frecuencias acumuladas que describe que cuantas unidades o qué porcentaje de unidades se encuentran por encima o por debajo de un determinado valor de la variable. Este gráfico se construye a partir de la tabla MENOR QUE, utilizando la frecuencia absoluta acumulada, FAA o la frecuencia relativa acumulada, FRA. En el gráfico que se presenta a continuación se utilizó la frecuencia relativa acumulada. Estadística Departamento de Ciencias Básicas uts 19 Los detalles sobre la construcción de estos gráficos serán explicados por el docente en la exposición que haga sobre este tema 1.3.19 LA INTERPOLACIÓN En general, la interpolación, es un método de cálculo para establecer el valor de la ordenada de un valor de la variable que se encuentra ?dentro? de otros valores ya calculados en una tabla. En el caso de la Estadística Descriptiva, se utiliza para calcular valores de la frecuencia absoluta acumulada, FAA o de la frecuencia relativa acumulada, FRA, correspondientes a valores de la variable que no se encuentran en la tabla MENOR QUE, pero que están dentro de los valores mínimo y máximo recolectados en el estudio. Por ejemplo, si se quiere saber qué porcentaje de los vehículos tanquearon mas de 4,8 galones de gasolina, al buscar este valor en la tabla MENOR QUE se detecta que aunque no está tabulado, se encuentra entre los valores de la variable 4,2 y 5,1 galones. Con esta información se pueden disponer los datos existentes y los buscados de la siguiente manera: x0 = 4, 2 x1 = 4,8 x2 = 5, 1 y0 = 0, 74 y1 = ? y2 = 0, 87 La expresión matemática que permite realizar el cálculo de interpolación es la siguiente: 0 y1 = y0 + x1 − x0 (y2 − y0 ) x2 − x0 Reemplazando los símbolos por los valores se tiene: 0 y1 = 0, 74 + 4, 8 − 4, 2 (0, 87 − 0, 74) 5, 1 − 4, 2 0 y1 = 0, 827 ' 0, 83 uts Estadística Departamento de Ciencias Básicas 20 ARREGLO Y PRESENTACIÓN DE DATOS Esto quiere decir que el 83% de los vehículos de la muestra tanquearon menos de 4,8 galones, pero, como se quiere saber es que porcentaje tanqueó mas de 4,8 galones, se debe restar el resultado anterior de 1 1 − 0, 83 = 0, 17 = 17% es entonces, el porcentaje de vehículos de la muestra que tanquearon mas de 4,8 galones Estadística Departamento de Ciencias Básicas uts 21 1.4 1.4.1 ARREGLO DE DATOS DE VARIABLE DISCRETA PROCEDIMIENTO PARA PRINCIPIANTES 1. Para establecer el número de clases: • Por conveniencia • Norma empírica • Fórmulas exponencial o logarítmica 2. Tipo de variable relacionada con la situación en estudio • (Revisar el tema en el módulo CONCEPTOS BÁSICOS) 3. Construcción de las clases o categorías Este procedimiento es específico para variable discreta como se muestra a continuación: • Determinar los valores máximo y mínimo entre los datos: Xmax y Xmin • Calcular el Rango, R = Xmax ?Xmin R N0C • Modificar la amplitud eliminando la parte decimal del número calculado en el paso anterior (Amod) • Calcular la amplitud de las clases A = • Utilizar Xmin como el límite inferior de la primera clase • Construir los límites de las clases Al construir las clases con este procedimiento automáticamente quedan con las tres condiciones de las clases estadísticas, es decir, de amplitudes constantes, mutuamente excluyentes y exhaustivas. 4. Construcción de la Distribución de frecuencias • Establecer el número de observaciones dentro de cada clase (FA) (tabla de conteo) • Calcular la frecuencia relativa (FR) • Ajustar la frecuencia relativa para que la suma de igual a 1 • Calcular la frecuencia relativa acumulada (FRA) 1.4.2 EJEMPLO PRÁCTICO Una muestra de 41 días del número de transacciones que se realizaron por día en un cajero automático se presenta en la siguiente tabla: uts Estadística Departamento de Ciencias Básicas 22 ARREGLO Y PRESENTACIÓN DE DATOS 1.4.2.1 DESARROLLO DEL EJEMPLO 1. Establecer el número de clases • Por conveniencia: No existe, en este caso, ninguna circunstancia que haga conveniente o deseable un determinado número de clases • Norma empírica: Se puede escoger cualquier número de clases entre 5 y 20 dependiendo del criterio o preferencia personal del analista y se hacen varios tanteos hasta encontrar un número de clases satisfactorio • Aplicando las fórmulas exponencial o logarítmica Utilizando la expresión logarítmica como se muestra a continuación, se tiene que: N0 .C = 1 + 3, 3log(41) = 6, 3 que indica que un número conveniente de clases para esta cantidad de datos es de 6 clases. 2. Tipo de variable: En este caso es una variable discreta 3. Construcción de las clases o categorías: Los pasos se encuentran en la siguiente tabla y son específicos para variable discreta TABLA N0 .4 N0 .c = 6 Xmax = 91 Xmin = 36 R = xmax − xmin = 55 55 A= = 9, 1666667 36 Amod = 9 En el cálculo anterior se puede observar que para construir la amplitud modificada, se borra toda la parte decimal de la amplitud, A, calculada Cuando la amplitud modificada es un número impar, las marcas de clase, que se utilizan para representar a las clases, son valores fraccionarios, como ocurre en este ejemplo; esta situación es incómoda porque no refleja la realidad en los casos de variable discreta, por lo que se prefiere agrupar los datos en clases que sean de amplitud par, como se presenta a continuación, para el mismo ejemplo, donde la amplitud se cambió de 9 transacciones por día a 8 transacciones por día, esto hace que el número de clases pase de 6 a 7 Amod = 8 4. Construcción de la Distribución de Frecuencias: El resultado de este proceso se presenta en la tabla N0 .5: Estadística Departamento de Ciencias Básicas uts 23 Se observa, también, que el límite inferior de cada clase es igual al límite inferior de la clase anterior más uno. También se puede ver que el límite superior de la última clase, (98), no coincide con el Xmax = 91, de los datos y el límite inferior de la primera clase es el Xmin = 36, de los datos. Las clases construidas de esta manera se llaman CLASES CERRADAS, porque en cada clase se contabilizan todos los datos incluidos entre los dos límites de la clase. Sin embargo, estas clases, como se puede observar, son de amplitudes constantes, mutuamente excluyentes y exhaustivas. También se observa que la tabla MENOR QUE, se construye de manera un poco distinta a como se hizo para el caso de variable continua, nótese que el último valor de la columna Menor Que, no es igual al límite superior de la última clase, sino a ése valor más uno. 1.4.3 REPRESENTACIÓN GRÁFICA 1.4.3.1 HISTOGRAMA Para el caso de variable discreta el histograma, recibe también el nombre de DIAGRAMA DE FRECUENCIAS y en él las clases se encuentran separadas, como se ve en el siguiente gráfico: Con frecuencia, en lugar de identificar cada clase con sus límites de clase, es más práctico utilizar la marca de clase, como se muestra en este gráfico, a continuación uts Estadística Departamento de Ciencias Básicas 24 ARREGLO Y PRESENTACIÓN DE DATOS Ahora es mucho más fácil leer el diagrama de frecuencias, por ejemplo, en el 14% de los días de la muestra se realizaron 58 transacciones, el número de transacciones por día menos frecuente, en la muestra, fue de 40 transacciones por día Se construye de la misma manera, a partir del diagrama de frecuencias y las marcas de clase, como se hizo en el caso de variable continua. Nótese que en esta gráfica se presenta una distorsión debido a que las clases no son adyacentes 1.4.3.2 POLÍGONO DE FRECUENCIAS OJIVA Cuando la variable es discreta, como en este caso, la ojiva se construye de forma diferente, porque la variable sólo toma valores enteros, aunque, aquí también, este gráfico se construye a partir de la tabla MENOR QUE 1.4.3.3 Estadística Departamento de Ciencias Básicas uts 25 Los detalles sobre la construcción de este gráfico serán explicados por el docente en la exposición que haga sobre este tema uts Estadística Departamento de Ciencias Básicas 26 ARREGLO Y PRESENTACIÓN DE DATOS 1.5 ARREGLO DE DATOS PARA VARIABLE DISCRETA EN CLASES DE AMPLITUD CERO Cuando el intervalo de valores que toma la variable es reducido y la variable es discreta, es más práctico agrupar los datos en clases de amplitud cero, como se muestra en el siguiente caso. Aquí X simboliza los valores que toma la variable que son al mismo tiempo las clases estadísticas. Estas clases cumplen con las tres características de una clase estadística: son de amplitud constante, son mutuamente excluyentes y son exhaustivas 1.5.1 EJEMPLO Se tomó una muestra de 60 facturas registrando el número de errores por factura. Los resultados se presentan en la siguiente tabla: Estadística Departamento de Ciencias Básicas uts 27 1.6 ARREGLO DE DATOS CUALITATIVOS Cuando la variable es cualitativa, el arreglo y presentación de datos estadístico es limitado. Sólo se pueden construir distribuciones de frecuencias con las frecuencias absolutas y relativas y diagramas de frecuencias. Adicionalmente, se utilizan en estos casos otros tipos de gráficos como se presenta en el siguiente ejemplo: 1.6.1 EJEMPLO Se interrogó a una muestra de clientes de una cafetería sobre el tipo de bebida gaseosa que prefieren obteniéndose los siguientes resultados: uts Estadística Departamento de Ciencias Básicas 28 Estadística Departamento de Ciencias Básicas ARREGLO Y PRESENTACIÓN DE DATOS uts 2 2.1 2.1.1 MEDIDAS DE TENDENCIA CENTRAL, DE POSICIÓN Y DE DISPERSIÓN MEDIDAS DE TENDENCIA CENTRAL Y DE POSICIÓN Formas estadísticas de describir un fenómeno Anteriormente se vio que los fenómenos o hechos se pueden describir con tablas y gráficos pero, también se pueden describir con números 2.1.2 Concepto de medida en Estadística En estadística se llama medida a un cálculo u operación que se realiza sobre un conjunto de datos para extraer alguna información 2.1.2.1 Ejemplos • Calcular la estatura promedio de un grupo de personas • Hallar la diferencia entre el mayor y el menor valor de un conjunto de datos • Establecer el valor que más se repite dentro de un conjunto de datos 2.1.3 Parámetros y Estadísticos En la unidad anterior se vio que los cálculos o medidas que se realizan con los datos referidos a una situación pueden clasificarse de dos maneras: Parámetros: Cuando el cálculo se realiza con todos los datos de la población. Los parámetros son valores constantes Estadísticos: Cuando el cálculo se realiza con una parte de los datos de la población, es decir, una muestra. Los estadísticos son variables uts Estadística Departamento de Ciencias Básicas 30 MEDIDAS DE TENDENCIA CENTRAL, DE POSICIÓN Y DE DISPERSIÓN 2.1.4 Clases de medidas en Estadística En estadística existen tres clases de medidas: • Las medidas de tendencia central • Las medidas de tendencia no central o de posición • Las medidas de dispersión 2.1.5 Las medidas de Tendencia Central Son tres valores, con cada uno de los cuales, se pretende describir, parcialmente, el comportamiento de una muestra o de una población. Las medidas tendencia central, reciben este nombre porque al representar el resultado de un cálculo en un gráfico de una distribución de frecuencias (histograma o polígono de frecuencias), el valor calculado siempre se sitúa hacia el centro de la gráfica 2.1.6 Las medidas de Tendencia No Central o de Posición Las medidas tendencia no central, reciben este nombre porque al representar el resultado de un cálculo en un gráfico de una distribución de frecuencias (histograma o polígono de frecuencias), el valor calculado suele situarse hacia los extremos de la gráfica 2.1.7 Las medidas de dispersión Las medidas de dispersión son cálculos o valores que indican que tan concentrados están los datos alrededor de un valor especial que se toma como referencia 2.1.8 Medidas para poblaciones y medidas para muestras Las medidas de tendencia central y de dispersión pueden clasificarse como Parámetros o Estadísticos, según sea que los datos utilizados correspondan a una población o a una muestra. Los cálculos de las medidas de tendencia central y de dispersión para poblaciones, en algunos casos, son diferentes de los cálculos de las medidas de tendencia central y de dispersión para muestras, por lo que se utilizan, en estos casos, símbolos diferentes para cada tipo de medida. 2.1.9 Clases de medidas de Tendencia Central Existen tres clases de medidas de tendencia central: • La media aritmética o promedio • La mediana • la moda 2.1.10 LA MEDIA ARITMÉTICA SIMPLE Existen dos tipos de media aritmética: la Media Aritmética Simple y la Media Aritmética Ponderada. A la media aritmética simple se le llama usualmente La Media y la forma de calcularla depende de sí los datos están o no agrupados en clases. Estadística Departamento de Ciencias Básicas uts 31 2.1.10.1 La Media Aritmética para datos no agrupados La media aritmética, para datos no agrupados, se calcula sumando los valores registrados de la variable en estudio y dividiendo entre el total de estos valores registrados. La expresión matemática de este cálculo tiene dos presentaciones: una sí los datos registrados corresponden a una población y otra sí los datos corresponden a una muestra, tal como se indica a continuación. Para poblaciones: µ= Σxi N x̄ = Σxi n Para muestras: El significado de los símbolos es el siguiente: µ : Es la letra del alfabeto griego mu, simboliza la media aritmética calculada para una población x̄ : Se lee equis trazo o equis barra, simboliza la media aritmética calculada para una muestra N: Es el número de valores que toma la variable, en estudio, en la población n: Es el número de valores que toma la variable, en estudio, en la muestra xi : Es cada uno de los valores que toma la variable en la muestra o en la población Ejemplo Las comisiones que un vendedor ha recibido en los 6 primeros meses del año se presentan en la siguiente tabla: 2.1.10.2 Calcular la media aritmética e interpretar el significado La expresión para calcular la media aritmética indica que se deben sumar todos los valores que toma la variable y dividir por el número de datos x̄ = 800 + 950 + 920 + 1000 + 830 + 900 6 x̄ = $900 Como esta forma de cálculos es poco práctica se suman, mejor, los datos en columna como se muestra a continuación: uts Estadística Departamento de Ciencias Básicas 32 MEDIDAS DE TENDENCIA CENTRAL, DE POSICIÓN Y DE DISPERSIÓN Σxi = 5400 x̄ = Σxi 5400 = = $900 miles n 6 Interpretación: La media aritmética es el mismo promedio y es como sí en cada uno de los 6 meses el comisionista hubiera ganado $900.000 2.1.11 Media Aritmética para datos agrupados La media aritmética se calcula sumando los productos de las marcas de clase por sus respectivas frecuencias absolutas y dividiendo esta suma por el número total de datos registrados, como se muestra en las siguientes expresiones: µ= x̄ = Σxi FAi N Σxi FAi n Para poblaciones Para muestras el significado de los símbolos es el siguiente: µ :Es la letra del alfabeto griego mu, simboliza la media aritmética calculada para una población x̄ :Se lee equis trazo o equis barra, simboliza la media aritmética calculada para una muestra N : Es el tamaño de la población n : Es el tamaño de la muestra xi :Es la marca de clase de cada una de las clases en que se han agrupado los datos FAi :Es la frecuencia absoluta de cada una de las clases en que se han agrupado los datos Una muestra del valor de las facturas, en miles de pesos, que se cancelan con tarjetas de crédito en una cadena de almacenes de modas se presenta en la siguiente tabla: 2.1.11.1 Ejemplo Estadística Departamento de Ciencias Básicas uts 33 Calcular la media aritmética e interpretar el significado Como se debe calcular la marca de clase de cada clase y multiplicar cada uno de esto valores por su respectiva frecuencia absoluta, estas operaciones es más práctico realizarlas en forma tabular, como se muestra a continuación: SOLUCIÓN El total de la cuarta columna es Σxi FAi = 10.764 y el total de datos, n, es 224, por lo que la media aritmética buscada es: x̄ = 10.764 = $48.054 miles 224 Interpretación: El valor de promedio de cada factura pagada con tarjeta de crédito es de $48.054 miles, que es como si cada factura fuera de este valor 2.1.12 Significado de la Media Aritmética La media aritmética o promedio calculada para un conjunto de datos significa que al remplazar el valor promedio por cada uno de los datos se obtiene el mismo resultado general 2.1.13 LA MEDIA ARITMÉTICA PONDERADA Existen situaciones en las cuales los datos registrados sobre una situación traen in formación adicional que indica que estos valores no tienen la misma importancia relativa, como se presenta en el siguiente caso: uts Estadística Departamento de Ciencias Básicas 34 MEDIDAS DE TENDENCIA CENTRAL, DE POSICIÓN Y DE DISPERSIÓN Ejemplo Las notas obtenidas por un estudiante en 3 quices de un corte y las notas finales, del semestre, extraídas del polígrafo correspondiente, se presentan en la siguiente tabla: 2.1.13.1 En el caso de los quices no existe ninguna información que permita pensar que estas tres notas tienen diferente nivel de importancia, por lo que su promedio se puede calcular utilizando la fórmula de la media para datos no agrupados, lo que no ocurre para el caso del polígrafo donde, por ejemplo, la nota de la asignatura B vale el doble que la nota de la asignatura A; en casos como este, para calcular el promedio, se utiliza una variante de la media aritmética que recibe el nombre de Media Aritmética Ponderada o Promedio Ponderado, cuya expresión matemática es la siguiente: x¯p = Σxi wi Σwi Media Aritmética Ponderada x¯p : Es el símbolo de la media ponderada xi : Representa los valores que toma la variable. En el ejemplo, las notas (4.9, 3.1 y 3.0) wi : Representa el valor relativo de cada uno de los datos, llamados Factores de Ponderación. En el ejemplo, los créditos de cada una de las asignaturas (2, 4 y 3) Aplicando la fórmula al ejemplo se tiene: Σxi wi = 31, 2 Σwi = 9 x¯p = 31,2 9 = 3, 47 Sí para este caso del polígrafo, el promedio se calculara como media aritmética simple, ignorando la información de los créditos, este cálculo daría 3,7 que es diferente del promedio ponderado que da un valor de 3,47 2.1.14 Propiedades de la Media Aritmética • El cálculo de la media aritmética tiene en cuenta todos los valores de la variable en estudio registrados Estadística Departamento de Ciencias Básicas uts 35 • A todas las variables cuantitativas se les puede calcular la media aritmética • Un conjunto de datos sólo tiene una media • La media permite hacer comparaciones entre poblaciones o muestras • La media se puede trabajar matemáticamente • La media es afectada por los valores extremos • No se puede calcular la media en distribuciones de frecuencias que tienen clase de extremo abierto 2.1.15 LA MEDIA GEOMÉTRICA En muchas situaciones los datos se presentan en valores relativos tales como porcentajes o proporciones. En tales casos el procedimiento de cálculo de la media, que se ha estado utilizando hasta ahora, puede apartarse de los resultados reales sí la variabilidad de los datos es alta. Existe, entonces, una expresión matemática especial para calcular promedios en los casos en que los datos provengan de tasas de interés, porcentajes o números índices, entre otros. A este expresión matemática se le llama la media geométrica y se suele representar por la letra G 2.1.15.1 Cálculo de la Media Geométrica G= p n (FC1 )(FC2 )(FC3 )........(FCn ) G Es el símbolo de la media geométrica FC1 , FC2 , FC3 ........FCn se llaman Factores de Crecimiento El índice de la raíz depende del número de factores de crecimiento. Sí los factores de crecimiento son 2, la raíz es cuadrada, sí los factores de crecimiento son 6 la raíz es sexta y así sucesivamente Los factores de crecimiento,FCi , se determinan con la siguiente expresión: FC = 1 + Valor en porcenta je 100 Como el valor en porcentaje se llama comúnmente Tasa, la expresión, más apropiada, para el Factor de Crecimiento es: FC = 1 + Tasa 100 Ejemplo La rentabilidad de un título valor ha estado variando en las últimas semanas como se presenta en la siguiente tabla: 2.1.15.2 uts Estadística Departamento de Ciencias Básicas 36 MEDIDAS DE TENDENCIA CENTRAL, DE POSICIÓN Y DE DISPERSIÓN ¿A qué tasa promedio semanal ha estado variando la rentabilidad de este título? Para aplicar la fórmula, las tasas de rentabilidad se deben convertir a factores de crecimiento Con los factores de crecimiento, de la tercera columna, se calcula G G= p 6 (1, 03)(1, 01)(0, 98)(1, 007)(1, 015)(1, 01) G = 1, 008557 ( factor de crecimiento promedio ) Como las unidades de este cálculo son Factores de Crecimiento, para convertir este resultado en tasa, se despeja ésta de la última fórmula Tasa 100 Tasa = (FC − 1)100 FC = 1 + Por lo tanto: Tasapromedio = (1, 00856 − 1)100 = 0, 856% ≈ 0, 9% Respuesta: El título ha estado aumentado a una tasa promedio del 0,9% semanal Cuando los datos se presentan en valores absolutos, pero, se debe calcular un porcentaje promedio, los factores de crecimiento se determinan como se indica en el siguiente ejemplo: Ejemplo Las ventas anuales de una empresa, en millones de pesos, se presentan en la siguiente tabla. ¿A qué tasa promedio anual están variando las ventas de esta empresa? 2.1.15.3 Estadística Departamento de Ciencias Básicas uts 37 Obsérvese que se pide la tasa promedio de crecimiento, que es un valor relativo y no la venta promedio anual, que es un valor absoluto Para convertir las ventas, que son valores absolutos, en factores de crecimiento, se divide el valor de un periodo cualquiera entre el valor del periodo inmediatamente anterior. Por ejemplo, el factor de crecimiento del año 2004 se consigue dividiendo 59 entre 32 así: FC = 59 32 = 1, 8438 Los demás cálculos se muestran en la tabla que se presenta a continuación. Nótese que no se puede calcular el factor de crecimiento del año 2001 porque no se conocen las ventas del año 2000. Con los datos de la tercera columna, FC, se calcula G G= p 6 (1, 1029)(0, 4267)(1, 8438)(1, 2373)(1, 2603)(1, 1739) G = 1, 08017 (Factor de crecimiento) Tasa promedio = (1, 08017 − 1) = 8, 017% ≈ 8% Respuesta: Las ventas están creciendo a una tasa promedio del 8% anual También se puede calcular la media geométrica para el caso de valores que varían en función del tiempo y sólo se conocen los valores iniciales y finales del periodo, como se puede ver en el siguiente ejemplo: Ejemplo Una persona invirtió $25 millones a 3 años, recibiendo al final de este periodo la suma de $33,306 millones ¿A qué tasa promedio mensual creció esta inversión? 2.1.15.4 La expresión de la media geométrica para casos como este, es la siguiente: G= q n Valor f inal Valor inicial Donde n es el número de periodos de tiempo durante el intervalo de la inversión Para el caso del ejemplo la expresión se aplica así: uts Estadística Departamento de Ciencias Básicas 38 MEDIDAS DE TENDENCIA CENTRAL, DE POSICIÓN Y DE DISPERSIÓN r G= 36 33, 306 25 Como la tasa que se pide es mensual el número de periodos es 36, por lo tanto, el índice de la raíz es 36 Para calcular la tasa promedio se aplica la expresión: Tasa = (FC − 1)100 Tasa promedio = (1, 008 − 1)100 = 0, 8% Respuesta: La inversión está creciendo, en promedio, al 0.8% mensual 2.1.16 Propiedad de la Media Geométrica La media geométrica siempre es menor o igual a la media aritmética, es decir: a ≤ b 2.1.17 Usos de la Media Geométrica La media geométrica se utiliza para calcular promedios de cantidades expresadas en porcentajes o en proporciones 2.1.18 LA MEDIANA La mediana es el valor que ocupa la posición central de un conjunto de datos cuando estos están ordenados de menor a mayor. Para aclarar este concepto veamos el siguiente ejemplo: 2.1.18.1 Ejemplo La siguiente tabla presenta las notas obtenidas por una muestra de estudiantes en un examen: Ordenando estos datos de menor a mayor, donde el menor está en el extremo izquierdo y el mayor en el extremo derecho de la fila se tiene: El número que ocupa la posición central es 3.8 porque por debajo de él hay 4 datos y por encima otros 4, por lo tanto, 3.8 es el valor mediano Estadística Departamento de Ciencias Básicas uts 39 2.1.19 Interpretación de la mediana El docente que tomó la muestra podría describir el comportamiento de los estudiantes en la prueba diciendo que la mitad de las notas de la muestra se encuentran por debajo de 3.8 o por encima de 3.8 Alternativamente, el docente podría haber utilizado el promedio o media aritmética para describir el comportamiento de los estudiantes en la muestra, como se vio anteriormente, pero, la mediana, entonces, es otra manera de describir una situación que es diferente de la media aritmética 2.1.20 Símbolo de la mediana El símbolo utilizado, en estas notas, para representar la mediana es: x̃ (una equis con una onda en la parte superior que se lee equis mediana) El cálculo de la mediana para el caso de las notas se expresa así: x̃ = 3.8 2.1.21 Cálculo de la mediana para datos no agrupados Número impar de datos Cuando en número de datos que componen la muestra es impar, como en el ejemplo de las notas, la mediana se puede calcular por simple inspección como se hizo anteriormente. Pero, para situaciones que representen un mayor número de datos existe una expresión matemática que es la siguiente: x̃ = x n+1 2 Esta expresión indica que el valor mediano ocupa la posición (n + 1)/2 cuando los datos están ordenados en orden ascendente Para aplicar esta expresión es preciso ordenar, entonces, los datos en orden ascendente e indicar la posición u orden de cada dato como se muestra a continuación: Los xi indican la posición de cada dato, por ejemplo, x7 indica que 4.3 ocupa la séptima posición cuando los datos están ordenados de forma ascendente Como el número de datos es 9, entonces (n + 1)/2 es igual a 5, esto quiere decir que el valor mediano es el valor que ocupa la quinta posición cuando los datos están ordenados de menor a mayor, por lo tanto, x̃ = x5 = 3, 8 tal como se había establecido anteriormente por simple inspección Número par de datos Cuando el número de datos sin agrupar es par, la expresión para calcular la mediana es la siguiente x̃ = uts x n2 + x n2 +1 2 Estadística Departamento de Ciencias Básicas 40 MEDIDAS DE TENDENCIA CENTRAL, DE POSICIÓN Y DE DISPERSIÓN Esto quiere decir que el valor mediano es el resultado de promediar los valores que ocupan las posiciones x n2 y x n2 +1 Para explicar esta expresión veamos el siguiente ejemplo: 2.1.21.1 Ejemplo Una muestra de las estaturas, en metros, de 10 estudiantes de una clase se presentan en la siguiente tabla: Al ordenar estos datos de forma ascendente e indicar la posición de cada uno de ellos se llega a la siguiente tabla: Como se puede observar, en esta ocasión, no existe un valor único que se localice en el centro del conjunto de datos ordenado, los valores X5 y X6 ocupan el centro de este conjunto y la mediana se localiza en el punto medio entre estos dos datos , por lo que para establecer su valor se promedian 1.69 y 1.71 así: x̃ = x5 + x6 1, 69 + 1, 71 = = 1, 70 2 2 Este valor se interpreta como que la mitad de los estudiantes de esta muestra miden menos de 1.70 metros Se deja al lector de estas notas, que como ejercicio, verifique que la expresión de la mediana para número par de datos produce el mismo resultado anterior. 2.1.22 Cálculo de la mediana para datos agrupados Recordemos que cuando se habla de datos agrupados nos referimos a datos agrupados en clases. Se presentan dos casos para el cálculo de la mediana Primer Caso La frecuencia absoluta acumulada, FAA, hasta alguna de las clases, de la distribución de frecuencias, coincide con la cantidad total de datos dividida entre 2, es decir, ( n / 2), como se puede ver en el siguiente ejemplo: Estadística Departamento de Ciencias Básicas uts 41 Como se puede observar el número de datos de la muestra n es 120, por lo tanto, n/2 es 60 y este valor coincide con la frecuencia absoluta acumulada, FAA, hasta la cuarta clase. En este caso la mediana es igual al límite superior de la cuarta clase, es decir: x̃ = Límite superior de la clase = $2,8 millones Este valor se puede interpretar diciendo que la venta mínima de la mitad de las tabernas de la muestra fue de $2.8 millones Segundo Caso El cálculo del total de datos de la muestra dividido entre 2, n/2, no coincide con el valor de la frecuencia absoluta acumulada, FAA, de ninguna de las clases. Para calcular la mediana en este caso se utiliza la siguiente fórmula de interpolación: n − FAAi−1 x̃ = Li + A 2 FAi Li : Es el límite inferior de la clase que contiene la mediana A : Es la amplitud de las clases n 2 : Es la cantidad total de datos de la muestra dividida entre 2 FAAi−1 : Es la frecuencia absoluta acumulada hasta la clase anterior a la clase que contiene la mediana FAi : Es la frecuencia absoluta de la clase que contiene la mediana Para saber cuál es la clase que contiene la mediana se compara n2 , el tamaño de la muestra dividido entre 2, con las frecuencias absolutas acumuladas, FAA, de la distribución de frecuencias. La mediana se encuentra en la clase cuya frecuencia absoluta acumulada, FAA, sea inmediatamente superior a n2 . A esta clase, en términos de la expresión anterior, se le llama la clase i, y la clase anterior a esta se le llama la clase i-1 Para aclarar estos conceptos revisemos el siguiente ejemplo: Los saldos de los depósitos al finalizar un mes en las cuentas de ahorro de un número de cuentahabientes, de los bancos locales, escogidos al azar, se presentan en la siguiente tabla: 2.1.22.1 uts Ejemplo Estadística Departamento de Ciencias Básicas 42 MEDIDAS DE TENDENCIA CENTRAL, DE POSICIÓN Y DE DISPERSIÓN El número total de datos de la muestra es 279 depósitos, por lo tanto, n2 es $139.5 miles. El valor, de la frecuencia absoluta acumulada, FAA; inmediatamente superior a éste es $154 miles, es decir, que la clase en la que se encuentra la mediana es la cuarta clase que va de $900 a $1.200 miles. Esta es entonces la clase i. La clase anterior a ésta es la tercera clase y su frecuencia absoluta acumulada hasta aquí es $112 miles. Reemplazando estos datos en la expresión de la mediana se obtiene lo siguiente: 139, 5 − 112 x̃ = 900 + 300 = $1, 096miles 42 Esto quiere decir que la mitad de los clientes de la muestra tenían un saldo, al final del mes, observado, inferior a $1.096.000 2.1.23 MEDIDAS DE TENDENCIA NO CENTRAL O DE POSICIÓN 2.1.24 Los Cuartiles Los cuartiles son tres valores que se determinan o calculan a partir de un conjunto de datos, con la particularidad de que dividen el conjunto de datos en cuatro partes iguales cuando este conjunto está ordenado en forma ascendente. Estos valores son: Primer cuartil o Q1 Es el valor por debajo del cual se encuentran la cuarta parte de los datos o 25% de los datos cuando están ordenados de menor a mayor Segundo cuartil o Q2 Es el valor por debajo del cual se encuentran la mitad de los datos o 50% de los datos cuando están ordenados de menor a mayor, es decir, es la misma mediana Estadística Departamento de Ciencias Básicas uts 43 Tercer cuartil o Q3 Es el valor por debajo del cual se encuentran las tres cuartas partes de los datos o 75% de los datos cuando están ordenados de menor a mayor Precisemos estas ideas con el siguiente ejemplo: El número de clientes que atendieron en un día once vendedores de un centro comercial escogidos al azar se presenta en la siguiente tabla: 2.1.24.1 Ejemplo Este conjunto de datos ordenando de menor a mayor se muestra en la siguiente tabla: Como se puede observar los números 8, 15 y 23 dividen el conjunto en cuatro partes iguales. Estos valores reciben, respectivamente, los nombres de Primer Cuartil, Segundo Cuartil y Tercer Cuartil 2.1.25 Cuartiles para datos agrupados Primer caso La frecuencia absoluta acumulada, FAA, hasta alguna de las clases coincide con el valor de la operación Qi n 100 , donde: Qi : es el valor del cuartil que se pretende calcular, es decir: 25, 50 o 75 n : Es el tamaño de la muestra Cuando se da esta coincidencia, el cuartil buscado es igual al límite superior que está frente al valor de la frecuencia absoluta acumulada, FAA, igual al valor calculado 2.1.25.1 Ejemplo Las utilidades por acción del portafolio de inversiones de una empresa se presenta en la siguiente tabla: uts Estadística Departamento de Ciencias Básicas 44 MEDIDAS DE TENDENCIA CENTRAL, DE POSICIÓN Y DE DISPERSIÓN Calcule el primer cuartil e interprete el significado de este cálculo Para establecer la clase donde se encuentra el cuartil buscado, se realiza el siguiente cálculo: Qi n 100 = 25x1100 = 275 100 Como 275 es la FAA hasta la segunda clase, entonces, el primer cuartil es igual al límite superior de esa clase, es decir: Qi = 1500 Una interpretación: El 25% de las acciones, de este portafolio, dan una utilidad inferior a $1.500 Segundo caso La frecuencia absoluta acumulada, FAA, hasta cualquiera de las clases no coincide con el valor de la opin eración Q 100 En este caso, el cálculo del cuartil se hace de manera parecida al segundo caso del cálculo de la mediana. La expresión que se utiliza es la siguiente: " Qn = Li + A Qi n 100 − FAAi−1 # FAi Qn : Es el cuartil que se quiere calcular. Li : Es el límite inferior de la clase que contiene el curtil que se busca A : Es la amplitud de las clases Qi n : Es el producto del valor del cuartil que se quiere calcular por el tamaño n de la muestra dividido 100 entre 100. Qi toma el valor de 25, 50, ó 75, según que el cuartil que se pretenda calcular sea Q1 , Q2 o Q3 , respectivamente Esta operación se utiliza para localizar la clase donde se encuentra el cuartil. FAAi−1 : Es la frecuencia absoluta acumulada hasta la clase anterior a la clase que contiene el cuartil FAi : Es la frecuencia absoluta de la clase que contiene el cuartil Estadística Departamento de Ciencias Básicas uts 45 2.1.25.2 Ejemplo Para el mismo ejemplo del primer caso, calcule el tercer cuartil e interprete su signifi- cado Qi n 100 = 75x1100 = 825 100 El tercer cuartil se encuentra en la clase cuya FAA es inmediatamente superior a 825. A esta clase se le llama clase i. Reemplazando en la fórmula se tiene: 825 − 695 Q3 = 1700 + 100 = $1.787 150 Interpretación: El 75% de las acciones, de la muestra, tuvieron una utilidad inferior a $1.787 2.1.26 Los Percentiles Los percentiles son valores que dividen un conjunto de datos en 100 partes iguales, cuando este conjunto está ordenado de menor a mayor. Un percentil, por lo tanto, es un valor por debajo del cual se encuentra un determinado porcentaje de los datos. Por ejemplo: P30 = 200 que se lee: Percentil 30 igual a 200, quiere decir que por debajo del valor 200, del conjunto ordenado de datos, se encuentran el 30% de los datos. 2.1.27 Percentiles para datos agrupados Primer caso Pn La frecuencia absoluta acumulada hasta alguna de las clases coincide con el valor de la operación 100 Donde: P : Es el percentil que se quiere calcular n : es el tamaño de la muestra. Sí el percentil que se quiere calcular es igual al límite superior de la clase cuya frecuencia absoluta acumuPn lada, FAA, coincide con el valor de la operación 100 , entonces, el valor del percentil buscado es igual al límite superior de esa clase. uts Estadística Departamento de Ciencias Básicas 46 MEDIDAS DE TENDENCIA CENTRAL, DE POSICIÓN Y DE DISPERSIÓN Ejemplo La siguiente tabla se refiere a una muestra, al azar, del tiempo que duraron las llamadas telefónicas realizadas por el personal de oficina de una empresa 2.1.27.1 Calcule el percentil 20 e interprete el resultado para establecer la clase donde se encuentra el percentil buscado se realiza el siguiente cálculo: Pn 20x230 = = 46 100 100 Como 46 es la FAA hasta la primera clase, entonces, el percentil 20 es igual al límite superior de esa clase, es decir: P20 = 2, 0 Interpretación: el 20% de las llamadas, de la muestra, duraron menos de 2.0 minutos Segundo caso La frecuencia absoluta acumulada, FAA, hasta cualquiera de las clases no coincide con el valor de la Pn operación 100 En este caso, el cálculo del percentil se hace de manera parecida al segundo caso del cálculo de la mediana. La expresión que se utiliza es la siguiente: " Pn = Li + A Pn 100 − FAAi−1 # FAi Li : Es el límite inferior de la clase que contiene el percentil buscado A : Es la amplitud de las clases Pn : Es la operación que se hace para saber en qué clase se encuentra el percentil 100 FAAi−1 : Es la frecuencia absoluta acumulada hasta la clase anterior a la clase que contiene el percentil FAi : Es la frecuencia absoluta de la clase que contiene el percentil Pn Para saber cuál es la clase que contiene el percentil se compara la operación 100 con las frecuencias absolutas acumuladas, FAA, de la distribución de frecuencias. El percentil se encuentra en la clase cuya frecuencia Estadística Departamento de Ciencias Básicas uts 47 absoluta acumulada, FAA, sea inmediatamente superior al valor de esta operación. A esta clase, en términos de la expresión anterior, se le llama la clase i, y la clase anterior a esta se le llama la clase i − 1 Para aclarar estos procedimientos utilizamos el ejemplo de las llamadas telefónicas 2.1.27.2 Ejemplo calcular el percentil 70 e interpretar su significado Para establecer la clase donde se encuentra el percentil 70 se realiza el siguiente cálculo: Pn 70x230 = = 161 100 100 El percentil buscado se encuentra en la clase cuya FAA es inmediatamente superior a 161. A esta clase se le llama clase i Reemplazando en la fórmula se tiene: 161 − 157 P70 = 6, 0 + 2, 0 = 6, 26 minutos 31 Interpretación: El 70% de las llamadas, de la muestra, fue inferior a 6.26 minutos Ejemplo Para el mismo ejemplo de la duración de las llamadas ¿Cuál fue la duración mínima del 40% de las llamadas? 2.1.27.3 El valor que se pide es menor que el 40% de las llamadas, por lo tanto, este valor es superior al 60% de las llamadas de la muestra, lo que quiere decir que se requiere calcular el percentil 60 2.1.28 Propiedades de la mediana, cuartiles y percentiles • A la mediana, cuartiles y percentiles no los afectan los valores extremos • La mediana, cuartiles y percentiles se pueden calcular en distribuciones de frecuencias que tengan clases de extremo abierto uts Estadística Departamento de Ciencias Básicas 48 MEDIDAS DE TENDENCIA CENTRAL, DE POSICIÓN Y DE DISPERSIÓN • La mediana, cuartiles y percentiles se pueden calcular en distribuciones de frecuencias que tengan clases de extremo abierto • Los cálculos de la mediana, cuartiles y percentiles son más complejos que los de las demás medidas de tendencia central • La mediana, cuartiles y percentiles no se pueden operar matemáticamente • Para calcular la mediana, cuartiles y percentiles los datos deben estar ordenados 2.1.29 LA MODA La moda, de un conjunto de datos, es el valor que más se repite dentro de ese conjunto. 2.1.30 Símbolo de la moda El símbolo que se va a utilizar, en esta notas, para representar la moda es: x̂ que se lee equis moda 2.1.31 Moda para datos no agrupados Cuando los datos no están agrupados la moda se establece a simple vista. 2.1.31.1 Ejemplo Una muestra de las edades de la última promoción de graduados se presenta en la siguiente tabla: A simple vista, el valor que más se repite es 22 años por lo que éste es el valor modal, es decir: x̂= 22 años Interpretación: La edad más común en la muestra de egresados es 22 años Observación: En este caso hay un solo valor modal Los puntajes alcanzados, en una escala de 100 puntos, en las pruebas de ingreso, por los aspirantes a trabajar en una empresa se presentan en la siguiente tabla: 2.1.31.2 Ejemplo A simple vista se puede establecer que los puntajes que más se repiten son el 57 y el 68, con una frecuencia de 4 cada uno, por lo que el conjunto de datos tiene 2 modas, es decir: Estadística Departamento de Ciencias Básicas uts 49 x̂1 = 57 puntos x̂2 = 68 puntos Cuando un conjunto de datos tiene más de una moda, como en este caso, se llama conjunto de dato Polimodal Interpretación: Cuando un conjunto de datos tiene más de una moda, esta medida de tendencia central no es útil para describir el comportamiento de los datos El tiempo, en horas, que gastan los buses de una empresa de transportes en realizar el viaje entre dos ciudades determinadas, en una muestra de recorridos escogidos al azar, se presenta en la siguiente tabla: 2.1.31.3 Ejemplo A simple vista se puede establecer que ninguno de los datos se repite por lo que este conjunto de datos no tiene moda. Por lo tanto, no se puede utilizar la moda para describir el comportamiento de los datos de esta muestra 2.1.32 Moda para datos no agrupados Primer caso: Datos de variable discreta agrupados en clases de amplitud igual a cero Ejemplo Una muestra del número de motocicletas que vende por semana un distribuidor se presenta en la siguiente tabla: 2.1.32.1 La más alta frecuencia corresponde a 19 semanas y el valor de la variable para esta frecuencia es de 4 motos por semana, por lo que la moda es 4, es decir: x̂ = 4 motocicletas por semana Interpretación: El volumen de venta más frecuente es de 4 motos por semana uts Estadística Departamento de Ciencias Básicas 50 MEDIDAS DE TENDENCIA CENTRAL, DE POSICIÓN Y DE DISPERSIÓN Segundo caso: Datos de variable cualitativa Aquí, también, la moda corresponde al valor de la variable que tiene la más alta frecuencia Ejemplo Se preguntó a una muestra de profesionales, escogidos al azar, por la marca de celular que utilizan y el resultado se presenta en la siguiente tabla: 2.1.32.2 La más alta frecuencia corresponde a la marca Nokia, por lo tanto, esta es la moda, es decir: x̂ = Nokia Interpretación: La marca de celular que con más frecuencia utilizan los profesionales, de la muestra, es Nokia Como se puede observar se puede calcular la moda para datos de variable cualitativa Tercer caso: Datos de variable discreta o continua agrupados en clases de amplitud mayor que cero Ejemplo Utilizando un radar de carretera los agentes de tránsito tomaron una muestra de la velocidad, en kilómetros por hora, a la que se desplazan los vehículos al pasar por un puente. Los resultados están en la siguiente tabla: 2.1.32.3 En este caso, la moda se encuentra en la clase que tiene la más alta frecuencia. Esta clase es la No.4 que corresponde al intervalo de 60 a 70 kilómetros por hora. Para saber en qué punto de este clase se encuentra la moda se aplica la siguiente expresión: Estadística Departamento de Ciencias Básicas uts 51 d1 x̂ = Li + A d1 + d2 Li : Es el límite inferior de la clase que contiene la moda A :Es la amplitud de las clases d1 : Es la diferencia entre la frecuencia absoluta de la clase que contiene la moda y la frecuencia absoluta de la clase anterior a la clase que contiene la moda d2 : Es la diferencia entre la frecuencia absoluta de la clase que contiene la moda y la frecuencia absoluta de la clase posterior a la clase que contiene la moda Aplicando la fórmula al ejemplo se tiene: d1 = 61 − 44 = 17 d2 = 61 − 55 = 6 17 x̂ = 69 + 10 = 67, 39 Kmts/hora 17 + 6 Interpretación: Lo más común es que los vehículos de la muestra se desplacen por el puente a 67,39 Kmts/hora 2.1.33 Propiedades de la moda • La moda se puede calcular en situaciones de variables cualitativitas y cuantitativas • A la moda no la afectan los valores extremos • La moda se puede calcular en distribuciones de frecuencias que tengan clases de extremo abierto • Existen conjuntos de datos que no tienen moda o que tienen más de una moda • La moda no se puede operar matemáticamente uts Estadística Departamento de Ciencias Básicas 52 MEDIDAS DE TENDENCIA CENTRAL, DE POSICIÓN Y DE DISPERSIÓN 2.1.34 CASOS ESPECIALES DE LA MEDIANA 2.1.35 Distribuciones de frecuencias para datos de variable discreta agrupados en clases con amplitud igual a cero Para calcular la mediana, cuando se tienen distribuciones de frecuencia con amplitud igual a cero y datos correspondientes a variable discreta se tiene dos casos: Primer caso: La frecuencia acumulada hasta cualquiera de las clases es diferente de n2 Este caso se presenta cuando ninguno de los valores de la columna de frecuencias relativas acumuladas o FAA coincide con el tamaño de la muestra dividida entre 2, es decir, n2 La siguiente tabla se refiere a una muestra del número de computadores que vendieron en un mes 112 tiendas de tecnología del país escogidos al azar 2.1.35.1 Ejemplo: La distribución de frecuencias acumuladas de este ejemplo se presenta en la siguiente tabla, donde se enn cuentra que = 112 2 = 56 2 Como se observa ningún valor de FAA coincide con n2 en este caso la mediana se encuentra en la clase cuya FAA sea más próxima por arriba a n2 . Este valor es 75, entonces, la mediana se encuentra en la clase 4 (LI = 4 y LS = 4). Por lo tanto la mediana es 4, es decir: Estadística Departamento de Ciencias Básicas uts 53 x̂ = 4 unidades Segundo caso:Algún valor de la frecuencia absoluta acumulada, hasta alguna de las clases, coincide con 2n Se tomó una muestra del número de estufas eléctricas que vendieron en el año una muestra de distribuidores escogidos al azar, como se presenta en la siguiente tabla: 2.1.35.2 ejemplo: En este caso n 2 = 94 2 = 47 Como se puede ver un valor de la columna FAA coincide con n2 . En este caso la mediana se encuentra entre las clases 12 y 13 y para calcularla se promedian estos dos valores así: 12 + 13 = 12, 5 x̃ = 2 Este resultado se puede interpretar de dos maneras así: • La mitad de los distribuidores de la muestra vendieron 12 o menos unidades • La mitad de los distribuidores de la muestra vendieron 13 o más unidades uts Estadística Departamento de Ciencias Básicas 54 MEDIDAS DE TENDENCIA CENTRAL, DE POSICIÓN Y DE DISPERSIÓN 2.2 MEDIDAS DE DISPERSIÓN Se había dicho anteriormente que el objetivo de las medias de tendencia central es describir (parcialmente), el comportamiento de un conjunto de datos que pertenezcan a una muestra o a una población. Sin embargo, esta capacidad descriptiva de las medidas de tendencia central es parcial porque es necesario complementarla con otra característica de las muestras y poblaciones que es la dispersión. Para introducir el concepto de dispersión se presenta el siguiente caso: 2.2.0.3 Ejemplo: Las ventas mensuales, en millones de pesos, de dos empresas se presentan en las sigu- ientes tablas: Al calcular la venta promedio mensual de estas dos muestras se encuentra que es igual para ambas con un valor de $19,395 millones, por lo que se podría pensar que ambas empresas tienen un comportamiento similar en cuanto a las ventas. Sin embargo, si se comparan sus polígonos de frecuencias como se hace en el siguiente gráfico, se puede ver que sus ventas siguen patrones de comportamiento muy diferentes. Estadística Departamento de Ciencias Básicas uts 55 La diferencia se encuentra, entonces, en que las dos muestras tienen diferente dispersión de sus datos alrededor de la media. Las ventas de Diseños Galaxia son menos dispersas que las ventas de Creaciones Armany 2.2.1 Concepto de dispersión Se llama dispersión al grado de variabilidad o de dispersión de un conjunto de datos alrededor de algún valor que se toma como referencia. Usualmente se toma como referencia alguna de las medidas de tendencia central. 2.2.2 Dispersión y variabilidad La variabilidad hace referencia a qué tan diferentes son entre sí los datos de una muestra o una población. La dispersión y la variabilidad son conceptos sinónimos como se puede ver en los siguientes ejemplos: En este caso todas las notas son iguales, por lo tanto, no hay ninguna variabilidad y ninguna dispersión uts Estadística Departamento de Ciencias Básicas 56 MEDIDAS DE TENDENCIA CENTRAL, DE POSICIÓN Y DE DISPERSIÓN Ahora hay una nota diferente a las demás, por lo tanto, existe una pequeña variabilidad entre los datos y una pequeña dispersión con respecto a la primera muestra En esta última muestra, hay un aumento notorio en la variabilidad entre los datos y en la dispersión con respecto a la muestra anterior. Es preciso resaltar, que la dispersión es un concepto relativo, siempre se evalúa comparando una muestra o población con algún valor de referencia o con otra muestra o población 2.2.3 Importancia de la dispersión Para que una medida de tendencia central sea representativa de los datos que la originaron se requiere que su valor sea similar a los datos de esa muestra o población que pretende describir, como se puede ver en el siguiente ejemplo: x̄ = 3, 6 x̄ = 2, 9 Como se puede observar, en la muestra de baja dispersión, el valor del promedio es similar o está cerca de los valores de la muestra, en cambio, en la muestra de alta dispersión, ninguno de los valores de la muestra es parecido al valor de la media. Por lo tanto, el promedio de la primera muestra es verdaderamente representativo de los datos de esta muestra y el de la segunda muestra no lo es. El concepto de dispersión, entonces, es importante porque entre mayor sea la dispersión de un conjunto de datos, menor es la fuerza representativa que tiene la medida de tendencia central calculada con esos datos Estadística Departamento de Ciencias Básicas uts 57 2.2.4 Clases de medidas de dispersión Las medidas de dispersión que se van a estudiar en estos apuntes son las siguientes: • El Rango • El Rango Intercuartílico • La Desviación Media • La Varianza • La Desviación Estándar 2.2.5 El Rango Es la diferencia o distancia entre el mayor valor, de un conjunto de datos y el valor menor. Este concepto ya se había mencionado para agrupar los datos en clases estadísticas, por lo tanto se utilizará para enunciarlo el mismo símbolo, es decir la letra R, es decir: R = xmax − xmin 2.2.6 Ejemplo: Calcular el rango de los siguientes conjuntos de datos: R = 3, 9 − 3, 2 = 0, 7 R = 5, 0 − 0, 1 = 4, 9 La dispersión de la muestra superior, medida por el rango, es menor que la dispersión de la muestra inferior El cálculo anterior se realizó con muestras de datos que no están agrupados. Cuando los datos ya están agrupados en clases el rango se establece restando del valor del límite superior de la clase mas alta el valor del límite inferior de la clase mas baja. En símbolos: R = LSclase mas alta − LIclase mas ba ja Una muestra de las facturas que se cancelan con tarjetas de crédito en una cadena de almacenes de modas se presenta en la siguiente tabla: 2.2.6.1 uts Ejemplo Estadística Departamento de Ciencias Básicas 58 MEDIDAS DE TENDENCIA CENTRAL, DE POSICIÓN Y DE DISPERSIÓN R = LSclase mas alta − LIclase mas ba ja R = 66 − 30 = $36 miles Como no se tiene el rango de otro conjunto de datos o un valor de referencia, para comparar, entonces, no se puede decir sí este conjunto de datos es o no disperso. 2.2.7 Características del rango • Es fácil de entender y de calcular • Da una idea rápida de la dispersión • En el cálculo únicamente se tienen en cuenta los valores máximo y mínimo • Varía mucho de una muestra a otra • No se puede calcular con distribuciones de frecuencia que tienen clases de extremo abierto 2.2.8 El Rango Intercuartílico Una de las desventajas del rango es que solamente se tienen en cuenta, para su cálculo, los valores máximo y mínimo, por lo que no indica como están distribuidos internamente los datos. Esta desventaja se puede corregir con el Rango Intercuartílico. Para simbolizar el rango intercuartílico se utiliza, en estas notas, RQ y se calcula restando la diferencia entre el primero y el tercer cuartil, es decir: R Q = Q3 − Q1 Este rango muestra la dispersión de la porción más central de los datos que abarca el 50% del total Las distancias en kilómetros, recorrida en un día por dos muestras de vehículos se presentan en las siguiente tablas: 2.2.8.1 Ejemplo Estadística Departamento de Ciencias Básicas uts 59 R = Xmax − Xmin = 85 − 25 = 60 kmts Q1 = 47, 7 Kmts Q3 = 67, 75 kmts RQ = 20, 05 kmts R = Xmax − Xmin = 85 − 25 = 60 kmts Q1 = 48, 0 Kmts Q3 = 64, 9 kmts RQ = 16, 9 kmts Como se ve, aunque las dos muestras tienen el mismo rango, R, el rango intercuartílico es diferente, lo que indica que la muestra B es menos dispersa que la muestra A 2.2.9 La Desviación Media Es la diferencia promedio, en valor absoluto, de los datos de la muestra o población con respecto a su propia media. La forma de la expresión de cálculo varía dependiendo de que se trate de datos no agrupados o datos agrupados. El símbolo que se utiliza en estos apuntes para la desviación media son las iniciales: DM Desviación Media para Datos No Agrupados DM = uts Σ|xi − x̄| n Estadística Departamento de Ciencias Básicas 60 MEDIDAS DE TENDENCIA CENTRAL, DE POSICIÓN Y DE DISPERSIÓN Donde: DM : Es el símbolo de la desviación media xi : cada uno de los datos de la muestra x̄ : Es la media aritmética de la muestra n : Es el número de datos de la muestra La razón por la cual se extrae el valor absoluto es porque los números tienen una propiedad que consiste en que la suma de las diferencias de un conjunto de números con respecto a su media siempre da igual a cero Ejemplo Una muestra, al azar, del tiempo, en minutos, que duran las llamadas que se hacen desde un teléfono, se presenta en la siguiente tabla: 2.2.9.1 Hallar la desviación media de esta muestra. x̄ = 11, 5 minutos DM = 31 = 5, 2 minutos 6 Desviación Media para Datos Agrupados DM = Σ|xi − x̄|FAi n Donde: Donde: DM : Es el símbolo de la desviación media xi : cada uno de los datos de la muestra x̄ : Es la media aritmética de la muestra FAi : Es la frecuencia absoluta de la clase i n : Es el número de datos de la muestra La siguiente tabla es una muestra, en miles de pesos, del valor del arriendo mensual de vivienda del estrato tres. 2.2.9.2 Ejemplo Estadística Departamento de Ciencias Básicas uts 61 x̄ = $271, 92 miles DM = 3836, 48 = $30.7 miles 125 Interpretación: En promedio, los arriendos de la muestra, se diferencian de la media en $30,7 miles La desviación media tiene en cuenta, para su cálculo, todos los datos de la muestra y es fácil de interpretar. Pero, la operación del valor absoluto para soslayar la propiedad anteriormente mencionada de los de los números, da una descripción incompleta de la situación. Obsérvese que no se sabe sí la diferencia de $30,7 miles, del ejemplo anterior, es por encima o por debajo de la media. Parta evitar este inconveniente existe otra medida de dispersión que aprovecha otra propiedad de los números que consiste en que todo número elevado al cuadrado tiene signo positivo. Esta medida de dispersión es la varianza. 2.2.10 La Varianza La Varianza, al igual que la desviación media utiliza, para medir la dispersión, las desviaciones de los datos con respecto a la media, pero, en este caso, estas desviaciones se elevan al cuadrado. Por lo tanto, se puede uts Estadística Departamento de Ciencias Básicas 62 MEDIDAS DE TENDENCIA CENTRAL, DE POSICIÓN Y DE DISPERSIÓN decir que la varianza es el promedio de las desviaciones, de los datos, con respecto a la media elevadas al cuadrado. Para el cálculo de la varianza, lo mismo que para las medidas de dispersión estudiadas anteriormente, se debe tener en cuenta sí los datos están o no agrupados, pero, adicionalmente, el cálculo de la varianza es ligeramente diferente según se trate con poblaciones o muestras, por lo que se utilizan símbolos diferentes para indicar cada una de estas dos situaciones. 2.2.11 La varianza poblacional Es la varianza que se calcula utilizando todos los datos de una población. Símbolo: σ2 Varianza Poblacional para datos no agrupados σ2 = Σ(xi −µ)2 N Donde: xi : Cada dato de la población µ : La media de la población N : El tamaño de la población 2.2.11.1 Ejemplo Los siguientes datos corresponden a los puntajes obtenidos por los aspirantes a un cargo en una empresa 681, 5 6 σ2 = 113, 58 puntosalcuadrado σ2 = Varianza Poblacional para datos agrupados σ2 Estadística Departamento de Ciencias Básicas = Σ(xi −µ)2 FAi N uts 63 Donde: xi : Cada dato de la población µ : La media de la población FAi : Es la frecuencia absoluta de cada clase N : El tamaño de la población Ejemplo En un programa sobre riesgo cardiovascular, se registró el peso en kilogramos de todos los empleados de una empresa 2.2.11.2 µ = 74, 2kilogramos 31894, 04 151 σ2 = 211, 22 kilogramos al cuadrado σ2 = 2.2.12 Varianza Muestral Es la varianza que se calcula sobre los datos de una muestra. El cálculo con respecto a la varianza poblacional difiere en que, el divisor de la expresión ya no es N, el tamaño de la población, ahora es (n − 1), que es el tamaño de la muestra, n, menos una unidad. 2 Símbolo : s uts Estadística Departamento de Ciencias Básicas 64 MEDIDAS DE TENDENCIA CENTRAL, DE POSICIÓN Y DE DISPERSIÓN Varianza Muestral para datos no agrupados s2 = Σ(xi −x̄)2 n−1 Donde: xi : Es cada uno de los datos de la muestra x̄ : Es la media de la muestra n : Es el tamaño de la muestra La razón por la cual se divide entre n − 1 es porque, de esta manera, s2 , es un estimador insesgado de la varianza de la población de la cual se extrajo la muestra. El concepto de estimador insesgado se estudia en el curso de Estadística Inferencial. Los saldos de las cuentas de ahorro, de empleados, de una muestra de las cuentas de ahorro de una cooperativa, escogidas al azar, se presentan en la siguiente tabla: 2.2.12.1 Ejemplo x̄ = $212, 5 Miles 143435, 5 (6 − 1) s2 = 28687, 10 miles de pesos al cuadrado s2 = Varianza Muestral para datos agrupados s2 = Σ(xi −x̄)2 FAi n−1 Donde: xi : Es la marca de clase de c/u de las clases en que se agrupa la muestra x̄ : Es la media aritmética de la muestra FAi : Es la frecuencia absoluta de cada clase n : Es el tamaño de la muestra Estadística Departamento de Ciencias Básicas uts 65 Ejemplo Una muestra del tiempo, en horas, que demora el almacén de materiales de una fábrica en surtir los pedidos que recibe: 2.2.12.2 x̄ = 6, 3 horas s2 = 943, 40 = 6, 8 horas al cuadrado (14 − 1) Como se puede observar, en los ejemplos anteriores, todas las unidades de la desviación estándar están elevadas al cuadrado por lo que es difícil interpretar el significado del valor de la varianza; esta en una de las razones por las cuales, para medir la dispersión, se prefiere otra medida que es la Desviación Estándar 2.2.13 La Desviación Estándar Conocida también como Desviación Típica, la desviación estándar es la raíz cuadrada de la varianza. Los símbolos que se utilizan son σ, para cálculo de la dispersión en poblaciones y s, para el cálculo de la dispersión en muestras Desviación Estándar para poblaciones Datos no agrupados q σ= uts Σ(xi −µ)2 N Estadística Departamento de Ciencias Básicas 66 MEDIDAS DE TENDENCIA CENTRAL, DE POSICIÓN Y DE DISPERSIÓN Datos Agrupados q σ= Σ(xi −µ)2 FAi N Desviación Estándar para muestras Datos no agrupados q s= Σ(xi −x̄)2 n−1 Datos Agrupados q s= Σ(xi −x̄)2 FAi n−1 Las tablas de cálculo para la desviación estándar son idénticas a las que se utilizan para la varianza, con un cálculo adicional: extraer la raíz cuadrada de la varianza 2.2.13.1 Ejemplo En un ejemplo anterior se vio que los puntajes de los aspirantes a un cargo, en una empresa fueron: y se calculó que: σ2 = 113, 58 puntosalcuadrado Por lo tanto: σ= √ √ σ2 = 113, 58 = 10, 7puntos Ejemplo En otro caso se estableció que el tiempo, en horas, que demora el almacén de materiales de una fábrica en surtir los pedidos que recibe Estadística Departamento de Ciencias Básicas uts 67 y se calculó que: s2 = 6, 8 horas al cuadrado √ s = s = 2, 6 horas Aunque es indispensable que se conozca, a ciencia cierta, como se obtienen la cifras de los cálculos de la media aritmética y la desviación estándar, en la práctica, la tecnología disponible permite que estas operaciones se hagan de forma más rápida y segura utilizando las funciones estadísticas de las calculadoras científicas o de las hojas electrónicas de los programas de computador, por lo que se debe consultar, por lo menos, en los manuales de las calculadoras, los detalles de la forma como se ejecutan estas funciones. 2.2.14 El coeficiente de Variación Para introducir el concepto del coeficiente de variación se analiza la siguiente situación: La primera impresión que se obtiene de una observación desprevenida de estos resultados es que las dos muestras tienen la misma dispersión porque sus desviaciones estándar son iguales. Sin embargo, si se examina con más atención, se puede ver que en el caso de la sección de materiales livianos, la desviación estándar equivale a la mitad del peso promedio de los materiales de la muestra. En cambio, en la sección de materiales pesados la desviación estándar equivale únicamente a 1/25 del peso promedio de los paquetes. Por lo que comparadas las dos desviaciones estándar con la magnitud de su respectivo promedio, es mucho más alta la dispersión de la sección de materiales livianos. De este análisis se concluye que la desviación estándar en casos como el del ejemplo, no permite comparar la dispersión de dos muestras y se puede agregar que esta dificultad se presenta cuando las medias de las muestras que se están comparando son muy diferentes entre sí. Para resolver este inconveniente, la estadística dispone de un indicador para medir la dispersión. Este indicador es el Coeficiente de Variación y se calcula con la siguiente expresión: uts Estadística Departamento de Ciencias Básicas 68 MEDIDAS DE TENDENCIA CENTRAL, DE POSICIÓN Y DE DISPERSIÓN El coeficiente de variación es un número sin dimensiones por lo que se puede expresar en fracciones decimales o en porcentaje. Como se puede notar, la desviación estándar del vendedor A es mayor que la desviación estándar del vendedor B; sin embargo, las ventas de la muestra del vendedor A son menos dispersas que las ventas de la muestra del vendedor B, porque el coeficiente de variación de las ventas del vendedor A es menor que el coeficiente de variación de las ventas del vendedor B Ejemplo: Una muestra de las ventas por día de un almacén de ropa de moda y un gran distribuidor textil se presentan en la siguientes distribuciones de frecuencias. ¿Cuál de los dos promedios de ventas por día es más confiable? Estadística Departamento de Ciencias Básicas uts 69 x̄ = 1, 70630636 s = 0, 30489321 CV = 0, 17868609 = 18% x̄ = 12, 26428571 s = 1, 62566714 CV = 0, 13255294 = 13% Respuesta: Es más confiable el promedio diario de Distrimoda porque tiene el menor coeficiente de variación. uts Estadística Departamento de Ciencias Básicas 3 3.1 3.1.1 REGRESIÓN Y CORRELACIÓN REGRESIÓN Introducción En muchas circunstancias de las actividades administrativas o cotidianas se encuentra que el comportamiento de dos o más hechos o situaciones parece estar relacionado de alguna manera, como por ejemplo en los siguientes casos: • El número de vehículos que circulan por las vías de una ciudad y los índices de contaminación de la misma • La tasa de desempleo y las ventas del comercio • Las ventas de licor y el número de accidentes de tránsito • Las horas de tutorías y el número de estudiantes que reprueban los parciales • El número de apartamentos construidos en un determinado periodo y las ventas de muebles • El número de personas que se movilizan en bus y las ventas de motos y el estado del clima 3.1.2 Concepto de Regresión Es un método de cálculo para establecer la relación matemática que existe entre dos o más situaciones o variables, que la observación o el sentido común indican que tienen comportamientos que están relacionados Estadística Departamento de Ciencias Básicas uts 71 3.1.3 Importancia de la Regresión Este método aplicado al análisis estadístico permite predecir matemáticamente el comportamiento de una variable a partir del comportamiento conocido de otra u otras variables. Esta relación entre las variables se establece a través de una ecuación que se llama Ecuación de Regresión 3.1.4 Variables dependientes e independientes Al establecer la relación entre dos variables se encuentra que el comportamiento de una variable depende del comportamiento de otra u otras variables o que la manifestación de una variable ocurre primero que la manifestación de otra u otras variables. A la variable que ocurre primero o que determina el comportamiento de otra se le llama Variable Independiente y se suele representar por la letra x y a la otra variable se le llama Variable Dependiente y se suele representar por la letra y Ejemplos: • Tasa de desempleo y ventas del comercio: La variable independiente o variable x es la tasa de desempleo y la variable dependiente o variable y es las ventas del comercio • Accidentes de tránsito y ventas de licor: La variable independiente es las ventas de licor y la variable dependiente los accidentes de tránsito • El número de personas que se movilizan en bus puede depender de las ventas de motocicletas y del estado del clima, por lo que el número de personas que utilizan el servicio de bus es la variable dependiente y las otras dos son las variables independientes 3.1.5 Gráfico de dispersión Es la representación gráfica, en el plano cartesiano, en forma simultánea, de los valores que toman la variable independiente: x y la variable dependiente: y Ejemplo Se tomaron datos sobre el kilometraje recorrido por un vehículo y el consumo de gasolina, en galones, como se presenta en la siguiente tabla: uts Estadística Departamento de Ciencias Básicas 72 REGRESIÓN Y CORRELACIÓN La representación gráfica de los valores de esta tabla en el plano cartesiano, recibe el nombre de Gráfico de Dispersión como se muestra a continuación: 3.1.6 Tipos de relación entre dos o mas variables La relación entre dos o más variables que, como dijimos anteriormente, recibe matemáticamente el nombre de regresión se puede clasificar de dos formas: • Atendiendo a la cantidad de variables que se relacionan se clasifica en Regresión Univariada o Regresión Multivariada • Atendiendo a la representación gráfica de la ecuación de regresión se clasifica en Regresión Lineal o Regresión Curvilínea Esta clasificación se puede visualizar en la siguiente gráfica: Estadística Departamento de Ciencias Básicas uts 73 3.1.7 Tipos de regresión • Regresión univariada: Se presenta cuando sólo interviene una variable independiente • Regresión Multivariada: Se presenta cuando interviene más de una variable independiente • Regresión lineal: Se presenta cuando la representación gráfica de la ecuación de regresión es una línea recta • Regresión Curvilínea: Se presenta cuando la representación gráfica de la ecuación de regresión es una curva Tanto la regresión lineal como la curvilínea tienen dos formas de manifestarse: en forma directa o en forma inversa 3.1.8 Regresión Lineal Directa Ocurre cuando al aumentar el valor de la variable independiente aumenta, proporcionalmente, el valor de la variable dependiente. Por lo tanto, una recta parece describir de manera apropiada la relación entre estas variables, como se puede ver en el siguiente gráfico: uts Estadística Departamento de Ciencias Básicas 74 REGRESIÓN Y CORRELACIÓN La curva de regresión (una recta), que mejor describe la relación entre estas dos variables, se presenta en la siguiente gráfica: 3.1.9 Regresión lineal Inversa Ocurre cuando al aumentar el valor de la variable independiente disminuye el valor de la variable dependiente en una proporción similar Estadística Departamento de Ciencias Básicas uts 75 La curva de regresión (una recta), que mejor describe la relación entre estas dos variables, se presenta en la siguiente gráfica: 3.1.10 Regresión curvilínea Directa Ocurre cuando al aumentar de valor la variable independiente, la variable dependiente aumenta mas que proporcionalmente uts Estadística Departamento de Ciencias Básicas 76 REGRESIÓN Y CORRELACIÓN La curva de regresión, que mejor describe la relación entre estas dos variables, se presenta en la siguiente gráfica 3.1.11 Regresión Curvilínea Inversa Ocurre cuando al aumentar de valor la variable independiente, la variable dependiente disminuye de valor en forma más que proporcional Estadística Departamento de Ciencias Básicas uts 77 La curva de regresión, que mejor describe la relación entre estas dos variables, se presenta en la siguiente gráfica: 3.1.12 Ninguna relación Ocurre cuando la relación entre la variable dependiente e independiente no se puede describir con ningún tipo de curva uts Estadística Departamento de Ciencias Básicas 78 3.1.13 REGRESIÓN Y CORRELACIÓN La Regresión Lineal Cuando los puntos del gráfico de dispersión se pueden relacionar con una recta que pase lo mas cerca posible de todos ellos, a esta recta se le llama Recta de Mínimos Cuadrados, porque la suma de las distancias al cuadrado, de los puntos del gráfico a esta recta es mínima Esta recta tiene por ecuación Y = A + BX, donde A es el punto donde la recta corta al eje Y , y B es la pendiente de la recta. El proceso para determinar el valor de los parámetros A y B es complejo, pero, el estudiante interesado lo puede consultar en cualquier texto de estadística. En el curso, se determinarán utilizando las funciones de las calculadoras científicas. Ejemplo Se comparó el tiempo total que realmente dura encendido, de forma intermitente, un celular, con la duración de su batería, obteniendo los valores que se presentan en la siguiente tabla: Estadística Departamento de Ciencias Básicas uts 79 Como el tiempo de duración de la batería depende del tiempo total, que de forma intermitente dura encendido el celular, la variable dependiente es el tiempo de duración de la batería y la variable independiente el tiempo en segundos que dura encendido el celular, como se presenta a continuación: El gráfico de dispersión de estos datos es el siguiente: Trazando una recta que pase lo más cerca posible de todos los puntos, el gráfico queda así: uts Estadística Departamento de Ciencias Básicas 80 REGRESIÓN Y CORRELACIÓN Entre más tiempo dure el celular encendido menos tiempo durará la batería por lo que la relación entre las dos variables en inversa y la pendiente de la recta es, por lo tanto negativa. Adicionalmente, se observa que la relación entre las dos variables es de tipo lineal, donde los parámetros de la recta de regresión son: A = 4, 7764201 B = −0, 0055024 Y la ecuación de regresión que relaciona las dos variables es: y = 4, 7764201 − 0, 0055024x Para un tiempo de encendido total intermitente del celular de 500 segundos, la duración que se puede esperar de la batería es: y = 4, 7764201 − 0, 0055024(500) y = 2 horas 3.2 LA CORRELACIÓN El interés del analista no está solamente en establecer la forma como se relacionan dos variables, sino, también, en medir que tan fuerte es el grado de esta relación. La regresión univariada es un caso extraño, lo común es que en comportamiento total de una variable dependiente sea el resultado de la interacción de varias variables dependientes, como se muestra en las siguientes gráficas: Estadística Departamento de Ciencias Básicas uts 81 Como es lógico pensar, la influencia que tiene cada una de estas variables independientes en el comportamiento total de la variable dependiente no es igual para todas las variables independientes. Habrá algunas variables independientes que determinan, en buena medida, el comportamiento de la variable independientey, también, habrá algunas variables independientes cuya influencia en el costo de reparación de vías o en el consumo de combustible, para estos ejemplos, es muy reducida. Para cualquier observador que analice estas situaciones, es de capital importancia determinar cuáles son las variables que ejercen un efecto notable en el comportamiento de otra, es decir, establecer la fuerza o intensidad con la que una variable independiente y otra dependiente están relacionadas. A esta fuerza o intensidad se le llama Correlación Es una medida del grado en que una variable independiente influye en una variable dependiente 3.2.0.1 uts El Coeficiente de Correlación Estadística Departamento de Ciencias Básicas 82 REGRESIÓN Y CORRELACIÓN Este grado de la relación entre dos variables se mide con un indicador que recibe el nombre de coeficiente de correlación. El coeficiente de correlación es un número adimensional que se representa por la letra r y toma valores entre −1 y +1. El significado de estos valores que toma r es el siguiente: • Sí r = −1 ó r = +1 la correlación entre las variables es perfecta, es decir, la fuerza de la relación entre la variable independiente y la variable dependiente, es la máxima posible. Esto quiere decir, que el comportamiento de la variable dependiente depende completamente del comportamiento de la variable dependiente • Sí r > 0, es decir, es positiva, la relación entre las variables es directa • Sí r < 0, es decir, es negativa, la relación entre las variables es inversa • Sí 0, 9 ≤ r < 1 ó −1 < r ≤ −0, 9 la correlación entre las variables se considera óptima • Sí r = 0 no existe correlación entre las variables Como el coeficiente de correlación es un número adimensional se puede expresar también en porcentaje. Se suelen preferir valores de coeficientes de correlación superiores al 90% 3.2.1 Relación entre el coeficiente de correlación y la pendiente de la recta de regresión • Sí la relación entre las variables dependiente e independiente es directa el coeficiente de correlación r y la pendiente de la recta de regresión son ambos de signo positivo • Sí la relación entre las variables dependiente e independiente es inversa el coeficiente de correlación r y la pendiente de la recta de regresión son ambos de signo negativo Ejemplo Para el mismo caso de la duración de la batería del celular, el valor del coeficiente de regresión es: r = −94% Que significa que la correlación entre las dos variables es inversa y óptima 3.2.2 El Coeficiente de Determinación El coeficiente de determinación es el cuadrado del coeficiente de correlación y explica el porcentaje de cambio de la variable dependiente que se puede explicar por el cambio de la variable independiente. Por ejemplo, un coeficiente de determinación de 64% entre los litros de licor vendidos los fines de semana y el número de accidentes de tránsito, en esos días, significa que el 64% de los accidentes de tránsito de los fines de semana se pueden Estadística Departamento de Ciencias Básicas uts 83 explicar por las ventas de licor Para el mismo caso que estamos estudiando de la duración de la batería del celular, el coeficiente de determinación es: r2 = 88% Que significa que el 88% de las variaciones en la duración de la batería del celular se deben a las variaciones en el tiempo total que demora el celular prendido de forma intermitente uts Estadística Departamento de Ciencias Básicas 4 BIBLIOGRAFÍA • LEVIN y RUBIN Estadística para Administradores. Séptima edición. Editorial THOMSON • MARTÍNEZ B, Ciro. Estadística y Muestreo. Décimo Tercera edición. Editorial ECOE • LIND, MARCHAL Y OTRO. Estadística Aplicada a los Negocios y la Economía Décimo Quinta edición. Editorial McGraw Hill • ANDERSON, SWEENEY Y OTRO. Estadística para Administración y Economía. 11ª edición. Editorial CENGAGE LEARNING Estadística Departamento de Ciencias Básicas uts

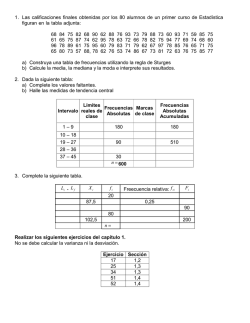
© Copyright 2026