
Muestreo Aleatorio Simple
. ANGEL FRANCISCO ARVELO LUJAN Angel Francisco Arvelo Luján es un Profesor Universitario Venezolano en el área de Probabilidad y Estadística, con más de 40 años de experiencia en las más reconocidas universidades del área metropolitana de Caracas. Universidad Católica “Andrés Bello”: Profesor Titular Jubilado 1970 a 2003 Universidad Central de Venezuela: Profesor por Concurso de Oposición desde 1993 al presente Universidad Simón Bolívar: Profesor desde 2005 al presente Universidad Metropolitana: Profesor desde 1973 a 1987 Universidad Nacional Abierta: Revisor de contenidos, desde 1979 hasta 2004 Sus datos personales son: Lugar y Fecha de Nacimiento: Caracas, 16-02-1947 Correo electrónico: [email protected] Teléfono: 58 416 6357636 Estudios realizados: Ingeniero Industrial. UCAB Caracas 1968 Máster en Estadística Matemática CIENES, Universidad de Chile 1972 Cursos de Especialización en Estadística No Paramétrica Universidad de Michigan 1982 Doctorado en Gestión Tecnológica: Universidad Politécnica de Madrid 2006 al Presente El Profesor Arvelo fue Director de la Escuela de Ingeniería Industrial de la Universidad Católica “Andrés Bello” (1974-1979) , Coordinador de los Laboratorios de esa misma Universidad especializados en ensayos de Calidad, Auditor de Calidad, y autor del libro “Capacidad de Procesos Industriales” UCAB 1998. En numerosas oportunidades, el Profesor Arvelo ha dictado cursos empresariales en el área de “Estadística General” y “Control Estadístico de Procesos”. Otras publicaciones del Prof. Arvelo, pueden ser obtenidos en la siguiente página web: www.arvelo.com.ve Muestreo Aleatorio Angel Francisco Arvelo Pag. 2 I INTRODUCCION I.1 Población y Muestra La Estadística tiene por objeto el estudio de los colectivos, y de las relaciones que existen entre ellos, entendiendo por colectivo, o universo, a un conjunto de elementos, personas o cosas, donde cada uno de ellos posee un carácter, que se denomina la variable estadística. La variable estadística puede ser cualitativa o cuantitativa. Así por ejemplo, en el caso de un estudio electoral, la variable estadística se refiere al candidato preferido por cada elector (variable cualitativa), mientras que en un estudio de calidad, la variable estadística se refiere a la longitud en milímetros de una cierta pieza (variable cuantitativa). El conjunto de valores de la variable estadística en cada uno de los elementos del universo se denomina “la población”. Un mismo universo puede tener varias poblaciones, ya que puede ocurrir que sobre cada elemento se definan varias variables estadísticas. Así por ejemplo, sobre un universo de personas podemos definir las variables estadísticas, sexo, edad, estatura y peso, lo que ocasiona que tengamos cuatro poblaciones diferentes en el mismo universo. El elemento sobre el cual se realiza la medición se denomina “la unidad de muestreo”, mientras que el número de unidades de muestreo existentes en la población se denomina “tamaño de la población” La Estadística no estudia casos individuales, como el ingreso de una persona, o la preferencia de un elector, sino conjuntos numerosos de personas en lo referente a su ingreso, o de electores en lo referente a la preferencia de cada uno de ellos. Una población puede tener un número finito de unidades de muestreo, o puede ser tan grande, que puede ser tratada como si fuera infinita. En “Estadística Matemática” por lo general, la población se considera infinita, pues el experimento puede ser repetido una y otra vez, y por lo tanto es posible coleccionar un número infinito de observaciones para la variable en estudio. Se llama “Parámetro Poblacional” a un valor que depende que los caracteres de cada uno de los elementos que forman la población, como por ejemplo, el porcentaje de elementos que posee un cierto atributo, o la suma de todos los caracteres asociados a cada uno de los elementos, en el caso de que éste sea un valor numérico, como por ejemplo el total de habitantes que residen en una localidad, que es la suma de los habitantes que residen en cada una de las viviendas ubicadas en esa localidad. Para obtener el valor de un parámetro poblacional, es necesario conocer el carácter de cada uno de los elementos de la población, y como la observación de todos ellos resulta prácticamente imposible por el elevado costo que representa, se procede a analizar sólo una parte de ella, con el objeto de inferir de ella el valor del parámetro poblacional. Esta parte de la población se denomina “muestra”; de manera que en un sentido amplio, una muestra es un subconjunto cualquiera de la población. El objetivo de Muestreo Aleatorio Angel Francisco Arvelo Pag. 3 la “Inferencia Estadística” tal como se dijo antes, es analizar esta muestra, y de allí obtener conclusiones para la población. Figura N° 1: Relación entre la muestra y la población La forma como se haga la selección de los elementos de la población para integrar la muestra se denomina “el plan de muestreo”, y determina la metodología estadística a seguir para hacer la inferencia. Según sea el “Plan de muestreo”, las muestras se clasifican de la siguiente forma: Tipos de No Probabilisticas Aleatoria muestras Estratificada Pr obabilisticas Sistematica Conglomerados Una muestra es no probabilística cuando la selección de los elementos de la población que pasan a formar parte de la muestra se hace a criterio de la persona que está tomando la muestra, sin que medie ningún tipo de procedimiento aleatorio para su selección. Los procedimientos de Inferencia Estadística no son aplicables a este tipo de muestras. Una muestra se dice probabilística cuando la selección de los elementos que intervienen en ella se hace a través de algún procedimiento aleatorio, o sorteo, que le concede a cada uno de los elementos de la población, un cierto chance de caer en ella. Existen diversos tipos de muestras probabilísticas: Muestra aleatoria simple: Es aquella en donde todas las muestras posibles son igualmente probables, y en consecuencia cada elemento de la población tiene idéntica probabilidad de caer en la muestra. Muestra Estratificada: Es aquella en donde antes de tomar la muestra se divide a la población en grupos excluyentes llamados “estratos”, y posteriormente dentro de cada estrato se toma una muestra aleatoria simple. Muestra Sistemática: En este tipo de muestras, la metodología es como sigue: Muestreo Aleatorio Angel Francisco Arvelo Pag. 4 Se divide la población en bloques de “k” elementos cada uno, y se numeran desde 1 hasta “k”. Se elige un número entero al azar entre 1 y k. Dentro de cada uno de los bloques se elige el elemento que corresponda al número aleatorio seleccionado. La muestra queda formada por los elementos elegidos, uno en cada uno de los bloques. Ejemplo: Supongamos que en una población de 3.000 elementos queremos tomar una muestra sistemática de 10 elementos. Para definir los elementos que van a formar parte de la muestra dividimos a la población en 10 bloques de 300 elementos cada uno. A continuación se elige un número al azar entre 1 y 300, digamos 158. La muestra quedará conformada por los elementos que ocupen el puesto N° 158 en cada uno de los diez bloques. Muestra por Conglomerados: Este tipo de muestreo consiste en dividir también a la población en grupos que se denominan “conglomerados”, y luego elegir aleatoriamente algunos de ellos. En los conglomerados que resulten seleccionados se realiza un censo, es decir, son examinados la totalidad de los elementos que lo conforman. La elección del “Plan de Muestreo” a utilizar en cada situación depende de varios factores tales como: La homogeneidad o heterogeneidad de la población en estudio. La factibilidad de poder identificar a todos los elementos que conforman a un determinado grupo, estrato o conglomerado. El costo del muestreo. Antes de proceder a seleccionar el “Plan de Muestreo” a seguir, es necesario ponderar cada uno de estos factores, así como también la precisión del muestreo. I.2 Variables Estadísticas y su clasificación Hemos visto que el universo está formada por elementos, y que cada uno de estos elementos posee un carácter, que varía de un elemento a otro. El conjunto de todos estos caracteres se denomina la población. Este carácter puede ser de muy variada índole; puede ser la estatura de cada uno de los habitantes de un país, el canal de televisión que en un momento determinado están siendo sintonizados en cada hogar de una ciudad, etc. Este carácter en estudio, y que puede ser diferente para cada uno de los elementos del universo se denomina la variable estadística. Las variables estadísticas se clasifican de la siguiente forma: Nominales Cualitativas Ordinales Variables Estadísticas: Discretas CuantitativasContinuas Muestreo Aleatorio Angel Francisco Arvelo Pag. 5 Se dice que una variable estadística es cualitativa cuando representa una cualidad o un atributo, como por ejemplo la ciudad en que reside un habitante de un país, o la religión que profesa una persona. Las variables cualitativas se clasifican en: Variables Nominales o Categóricas. Este es el caso en que entre los distintos valores de la variable no existe ninguna relación de orden o de jerarquía. Tal es el caso por ejemplo, en que la variable estadística en estudio es el estado civil de los empleados de una empresa. Aquí los posibles valores de esta variable son: Soltero, Casado, Viudo y Divorciado. En algunos casos, a ciertas variables nominales, por comodidad en el tratamiento de los datos se les asignan valores numéricos, sin que este artificio le haga perder su condición de Variable Nominal. Por ejemplo, en una encuesta se podría presentar la siguiente situación: Pregunta: ¿Cual canal de televisión prefiere Ud.? Respuestas: 1- El Canal 2. 2- El Canal 4. 3- El Canal 5. 4- El Canal 8. 5- El Canal 10. En este caso ni los números que identifican a la respuesta del encuestado (1,2,3,4 o 5) , ni los números que corresponden a cada uno de los canales de televisión (2,4,5,8 o 10), cuantifican una magnitud en sí, sino que representan una cualidad como es la preferencia del televidente. De forma pues que esta variable, a pesar de tomar valores numéricos, es una Variable Cualitativa, y además Nominal, puesto que los números mencionados no sugieren una relación de orden, debido a que no podemos decir que el televidente de un determinado canal, es mejor o peor que el televidente de otro canal, porque el número que identifica al canal es mayor o menor que el otro. b) Variables Ordinales. Este es el caso en que entre las diferentes cualidades existe una relación de orden jerárquico entre ellas, y es posible decir que cierta categoría es mayor o menor, o mejor o peor, que otra. Por ejemplo, al clasificar a un grupo de personas según sus edades en infantes, adolescentes, adultos, maduros y ancianos , es posible establecer un orden , o también al clasificar a los miembros del ejército según su rango, es posible establecer un orden , y decir que ser General de División es más que ser Coronel, etc. Algunas veces, variables estadísticas que pueden ser medidas numéricamente por comodidad de trabajo, son tratadas como variables cualitativas ordinales. Tal es el caso por ejemplo, de la clasificación socio - económica que se suele hacer en grupos familiares , tomando únicamente como elemento de juicio su nivel de ingresos, y clasificarla así en Clase Alta, Media Alta, Media, Media Baja o Marginal . Aquí se está tomando en cuenta una variable numérica, como es el ingreso familiar, para decidir acerca de una cualidad como es la condición de vida de la familia. En estos casos se presenta el problema de definir cuáles son las fronteras numéricas, para ubicar a un elemento en una u otra escala. Muestreo Aleatorio Angel Francisco Arvelo Pag. 6 Las variables cuantitativas son aquellas que se refieren a magnitudes numéricas, tales como la estatura de un grupo de personas, o el número de personas que residen en una vivienda. Las variables cuantitativas se clasifican en discretas y continuas. Una variable es discreta cuando el conjunto de valores que puede tomar es finito o infinito numerable, es decir que puede ponerse en correspondencia con el conjunto de los números naturales. Por ejemplo, si en una determinada investigación estamos analizando el número de vehículos que posee cada una de las residencias de una urbanización, el resultado de nuestras observaciones serán números naturales, o cero; ésta es pues una variable discreta. Otros ejemplos de investigaciones que dan lugar a variables discretas son: Número de hijos que posee un matrimonio, número de clientes que acuden diariamente a un comercio, etc... Se dice que una variable es continua cuando puede tomar cualquier valor dentro de un intervalo real. Así por ejemplo, si consideramos el peso de una persona, el resultado de nuestra observación será un número real positivo, sin limitación en el número de cifras decimales. Hay que advertir que una variable continua no puede ser jamás medida en su exacto valor, pues por más pequeña que sea la unidad de medida que utilicemos, siempre podremos encontrar valores más pequeños que esa unidad. Así por ejemplo cuando decimos que un bombillo falló a las 532 horas de uso, esto no significa que la falla ocurrió en el preciso instante en que cumplía las 532 horas. Lo que significa es que falló en algún instante entre las 532 y las 533 horas, lo que representa un intervalo de tiempo. La variable discreta por el contrario, si puede ser medida en su valor exacto, y así por ejemplo, cuando decimos acudieron 532 clientes a un banco durante un día determinado, ésta cifra representa un valor exacto, y es puntual. Las variables continuas más frecuentes suelen ser el tiempo, longitud, área, volumen, etc. I.3 Escalas de Medición Una vez que ha sido definida la variable estadística que va a ser analizada, nos encontramos con el problema de cómo medirla. En muchas oportunidades este asunto no presenta ninguna dificultad, pues la variable considerada ya tiene una unidad de medida perfectamente definida. Tal es el caso por ejemplo, de una longitud, en donde ya existen varias unidades de medición universalmente aceptadas, como pudieran ser el metro, la pulgada, el milímetro, etc. En otros casos sin embargo, la situación no es tan clara, pues no existe tal unidad de medida, y se hace necesario definir una escala de medición. Por ejemplo, si el universo es el conjunto de clientes de una empresa de servicios, y lo que se quiere estudiar es el nivel de satisfacción de cada uno de ellos por el servicio prestado, inmediatamente nos preguntaremos: ¿cómo medir ese nivel de satisfacción? Muestreo Aleatorio Angel Francisco Arvelo Pag. 7 La selección de una escala de medición adecuada es una decisión importante en cualquier investigación, pues de ella dependerá la metodología estadística a seguir, y las conclusiones que se deriven de la investigación. En 1948, el científico S.S. Stevens propuso una clasificación lógica para los tipos de medición, con la que no todos los estadísticos concuerdan, pero que es la más divulgada y conocida. Stevens señaló que si no existieran mediciones el mundo sería caótico, y no existiría ciencia estadística, y si las mediciones fuesen totalmente exactas, habría una demanda mucho más reducida para emplear la Estadística. Stevens reconoce cuatro tipos de escalas de medición: nominal, ordinal, de intervalos, y de razón. Las escalas nominales se emplean para medir variables cualitativas nominales, y se utilizan como medidas de identidad. Una escala de este tipo tendría que ser necesariamente usada para representar los distintos valores de variables como sexo, religión, etc. En una escala nominal, los diferentes valores de la variable se suelen numerar por orden alfabético de las categorías, y los números asignados no corresponden a ninguna medición, ni entre ellos existe relación jerárquica alguna. La escala ordinal refleja orden o jerarquía entre los distintos niveles de la variable, y se disponen de la más alta a la más baja, o viceversa. El ejemplo clásico de este tipo de escala es el empleado para evaluar la dureza de los minerales. Esta propiedad se define como el grado de resistencia a la abrasión, y en esta escala el número 1 corresponde a un material muy suave y fácil de desmenuzar como el talco, mientras que el número 10 en el extremo opuesto de la escala, corresponde al diamante, que puede rayar a todos los demás, y no puede ser rayado por ninguno. Con relación a este tipo de escalas, hay dos comentarios importantes que hacer: Iguales diferencias entre los números de la escala, no necesariamente reflejan iguales diferencias de intensidad para la variable medida. Consideremos por ejemplo, el siguiente caso: Supongamos que para medir el grado de satisfacción de los clientes por un determinado servicio, se propone la siguiente escala nominal: 1. Totalmente insatisfecho. 2. Bastante insatisfecho. 3. Medianamente satisfecho. 4. Bastante satisfecho. 5. Totalmente satisfecho. En esta escala, a pesar de que la diferencia 5 - 3 = 3 -1, no podemos decir que la diferencia entre el grado de satisfacción entre los clientes del nivel 5 y los del nivel 3, es la misma que entre los clientes del nivel 3 y el nivel 1. En una escala nominal tampoco podemos hacer comparaciones de razón entre los diferentes niveles o números de la escala. Así por ejemplo, en el caso anterior sería absurdo decir que como 4 es el doble de 2, entonces los clientes del nivel 4 están doblemente satisfechos que los del nivel 2. Muestreo Aleatorio Angel Francisco Arvelo Pag. 8 La escala de intervalos es para variables cuantitativas, y por lo tanto proporciona valores numéricos .En este tipo de escala hay que seleccionar una unidad de medida, y la medición expresa el número de unidades que posee el elemento medido. En una escala por intervalos hay tres características fundamentales: El cero es completamente arbitrario, y no significa necesariamente la ausencia de la cantidad medida. Diferencias iguales reflejan idénticas diferencias, entre los niveles de la variable en estudio. No se pueden hacer comparaciones de razón. Un ejemplo de escala por intervalos es la utilizada para medir la hora del día. En esta escala el cero que corresponde a la medianoche, es completamente arbitrario, el tiempo transcurrido entre las 5:00 y las 8:00, es el mismo que entre las 14:00 y las 17:00, y no se puede decir que 8:00 a.m. es el doble de 4:00 am. Otro ejemplo de escala por intervalos es la utilizada para medir la temperatura, bien sea en °C o en °F. En la escala centígrada el cero es arbitrario, y corresponde a la temperatura de congelación del agua, y la diferencia de temperatura entre 10°C y 14°C es la misma que entre 25°C y 29°C. En una escala por intervalos no se pueden hacer comparaciones de razón entre los valores de la variable, y así por ejemplo si en un día la temperatura fue de 15°C y en otro de 30°C, es incorrecto decir que en el segundo día hizo el doble de calor que en el primero. La escala de razón o de cociente es también para variables cuantitativas, y se diferencia de la de intervalos en que en ella el cero no es arbitrario, y corresponde realmente a una total ausencia de la propiedad estudiada. En una escala de razón, lo mismo que en una de intervalos, a iguales diferencias entre los números asignados corresponden iguales diferencias de intensidad de la variable en estudio, pero ahora si es posible hacer comparaciones de razón entre los elementos, y decir que en un elemento “A” el valor de la variable es tres veces o cuatro veces el valor de otro elemento "B”. El peso y la estatura son ejemplos claros de una escala de razón, pues una persona que pese 90 Kg., pesa el triple que un niño que pese 30 Kg. I.4 Etapas de una Investigación por Muestreo El muestreo es una herramienta fundamental en cualquier investigación, bien sea científica o social, y su aplicación requiere de una cierta metodología. Por lo general los problemas más frecuentes que hay que resolver a la hora de aplicar técnicas de muestreo en una investigación, son en este orden los siguientes: Formulación del problema: Esta es la fase conceptual de la investigación , y consiste en definir en primer lugar el objetivo de la investigación que se va a Muestreo Aleatorio Angel Francisco Arvelo Pag. 9 realizar , las hipótesis que se pretenden probar , la definición de la población a considerar, y la selección de las variables a medir . En muchas oportunidades, esta fase también exige la creación de una escala de medición, porque la misma no existe para algunas de las variables que van a ser analizadas. Esta es quizás la fase más importante en la investigación, pues es la que condiciona todas las posteriores, y la validez de las conclusiones. Diseño del experimento: Una vez que ha sido definido el problema, el investigador debe decidir si estudiar toda la población o sólo una muestra. En caso de que decida hacer un muestreo, habrá que definir el tipo de muestreo a utilizar, si aleatorio simple, estratificado, por conglomerados, etc. También será necesario calcular el tamaño de muestra requerido, el cual dependerá de la precisión que se le quiera dar al muestreo; y también será necesario diseñar un cuestionario, o formato para ser llenado por la personas que van posteriormente a recoger la información. El diseño de la encuesta y la redacción de las preguntas es un aspecto muy importante en esta fase, pues de la sinceridad de las respuestas dependerá la validez de la investigación. Este es un problema más de carácter psicológico que estadístico, pues la Estadística supone que la respuesta obtenida es sincera, y en la práctica no necesariamente esto es cierto. La apariencia física del encuestador, el momento de realizar la encuesta, y la forma de hacer las preguntas son aspectos muy importantes a considerar aquí. En el caso de investigaciones en un laboratorio, esta fase exige también la selección de los instrumentos de medición, su calibración y la metrología. Otro aspecto que también debe ser analizado en esta fase es el relativo a los programas de computación que van a ser utilizados posteriormente para procesar la información recogida en el muestreo. Recolección de datos. Esta es la fase de campo propiamente dicha, en la que el investigador hace el sorteo aleatorio de las unidades de la población que van a pasar a formar parte de la muestra, y posteriormente las entrevista, o las ensaya en caso de que se trate de una investigación hecha en un laboratorio. En esta fase, el investigador debe poner especial cuidado en que la muestra quede conformada por estrictamente las unidades que resultaron sorteadas, y no por otras que le resulten más cómodas al encuestador. Cualquier error en este sentido haría que la investigación pierda fuerza, y podría incluso invalidar sus conclusiones. Tabulación y Descripción de los resultados. Esta es la fase descriptiva de la investigación, en donde los datos tomados en la fase anterior son organizados y resumidos en tablas estadísticas, y también representados en gráficas que de una manera rápida permitan visualizar su comportamiento. Muestreo Aleatorio Angel Francisco Arvelo Pag. 10 En esta fase es indispensable el manejo de las técnicas de Estadística Descriptiva, y debe contarse con la ayuda del programa de computación seleccionado en la fase de diseño. Inferencia Estadística y Conclusiones: Esta es la fase final de la investigación, en donde los resultados obtenidos en la muestra son analizados con los métodos de la Inferencia Estadística, y se obtienen conclusiones para la población. Las conclusiones obtenidas en esta fase se refieren a las hipótesis que habían sido formuladas en la fase inicial, o también a la estimación del valor de ciertos parámetros poblacionales que eran desconocidos al comienzo de la investigación. II. ESTIMACION II.1 Concepto de estimador Un parámetro poblacional es un valor que se calcula en base a todos y cada uno de los elementos de la población. Así por ejemplo, si en el universo de estudiantes inscritos en una Universidad, consideramos la variable estadística “estatura de cada uno de ellos”, la población será el conjunto de valores numéricos que representan sus respectivas estaturas. Si llamamos “N” al número de estudiantes en esta Universidad (Tamaño de la población), el conjunto de valores numéricos de sus estaturas {𝑥1 , 𝑥2 ⋯ , 𝑥𝑁 } representa a la población. Sobre esta población podemos definir al siguiente parámetro poblacional: 𝑥 +𝑥 ⋯+𝑥 ∑𝑁 𝑥 𝑦 +𝑦 ⋯+𝑦 ∑𝑛 𝑁 𝑖 𝜇 = 1 2+𝑁 = 𝑖=1 = Media Poblacional 𝑁 Resulta obvio, que en la gran mayoría de las situaciones prácticas, este valor resultará desconocido, porque para calcularlo necesitaríamos conocer las estaturas de todos los estudiantes de la referida Universidad. El objetivo principal del muestreo es justamente, estimar el valor de estos parámetros poblacionales, a partir del resultado arrojado por una muestra de esta población; y de allí la necesidad de introducir el concepto de estimador. Un estimador es un valor calculado sobre la base del resultado muestral obtenido, y que se utilizará para estimar a un parámetro poblacional. En el ejemplo anterior, al tomar una muestra de “n” estudiantes (tamaño de la muestra), y medir sus estaturas, encontraremos un conjunto de valores numéricos {𝑦1 , 𝑦2 ⋯ , 𝑦𝑛 }, sobre los cuales podemos definir la siguiente función: 𝑦 𝑛 𝑖 𝑦̅ = 1 2+𝑛 = 𝑖=1 = Media muestral 𝑛 Este valor, como veremos más adelante, va a ser utilizado para estimar a su correspondiente poblacional, y diremos que 𝑦̅ es el estimador de 𝜇 , lo que se designará mediante la siguiente notación: 𝜇̂ = 𝑦̅ Para una mejor comprensión de los problemas del muestreo, es importante resaltar las diferencias básicas entre el parámetro poblacional y su estimador: El valor del parámetro poblacional es una constante desconocida, mientras que el de su estimador es conocido para una muestra particular, pero variable entre las diferentes muestras posibles Muestreo Aleatorio Angel Francisco Arvelo Pag. 11 En efecto, regresando al ejemplo, la media poblacional 𝜇 es una constante cuyo valor no conocemos, mientras que el valor de la media muestal 𝑦̅ lo conocemos para la muestra particular tomada, pero pudo haber sido otro, si el azar hubiese dispuesto que la muestra seleccionada hubiese sido otra. De lo anterior se desprende que un estimador es una variable aleatoria, pues puede variar de una muestra a otra, y que lo que obtenemos al tomar una muestra, es un valor particular de dicha variable aleatoria. Inmediatamente surgen las siguientes preguntas: 1. ¿Cómo hacemos para obtener el mejor estimador para un parámetro poblacional cualquiera? 2. Si el estimador es una variable aleatoria, ¿cuál es su distribución de probabilidad? 3. ¿Cómo hacemos para inferir el valor del parámetro poblacional a partir de ese valor particular del estimador? La respuesta a estas preguntas no es sencilla, y no constituye el objetivo de este humilde resumen, pues representa la esencia de lo que se denomina “Inferencia Estadística”; sin embargo, aquí haremos uso de algunos de los resultados que allí se obtienen, y se demuestran, por lo que se recomienda al lector interesado en profundizar en estos aspectos consultar un texto de “Estadística Matemática e Inferencia Estadística” El siguiente cuadro resume las diferencias entre Parámetro Poblacional y Estimador: Se calcula: Comportamiento Conocimiento Parámetro Sobre toda Constante Desconocido Poblacional la población Estimador Sobre Aleatorio Conocido solo un la muestra valor particular II.2 Propiedades de un buen estimador Un problema muy frecuente en Inferencia Estadística es el de comparar estimadores, pues a pesar de que existen diversos métodos y criterios para hacer la estimación, no siempre todos ellos conducen al mismo estimador, y por lo tanto, se hace necesario decidir cuál es el mejor. Con el objeto de facilitar las definiciones, adoptemos la siguiente nomenclatura: θ = Valor verdadero de un parámetro poblacional desconocido 𝜃̂ = Estimador de θ Al ser 𝜃̂ una variable aleatoria, tendrá una cierta Distribución de Probabilidad, y en consecuencia un determinado valor esperado, y una cierta varianza E (𝜃̂ ) = Valor Esperado de 𝜃̂ Var (𝜃̂ )= Varianza de 𝜃̂ Las siguientes propiedades nos permiten reconocer a un buen estimador, y serán explicadas de una manera intuitiva, sin el tratamiento riguroso propio de la Estadística Matemática Muestreo Aleatorio Angel Francisco Arvelo Pag. 12 1 Estimadores insesgados: Se dice que un estimador es insesgado, cuando su valor esperado coincide con el parámetro poblacional que pretende estimar, es decir cuando E (𝜃̂ ) = θ; caso contrario, se dice que es sesgado. Para entender mejor desde un punto de vista práctico lo que significa sesgar una muestra consideremos el siguiente caso hipotético. Imaginemos que para realizar una encuesta electoral seleccionamos la muestra entre los asistentes a una concentración a favor de un candidato. Resulta obvio, que en esa muestra no esperamos encontrar un reflejo de lo que realmente opina la población. En este caso diremos que la muestra está sesgada, es decir adulterada. Un estimador sesgado es como un arma que no tiene la mira calibrada, que pretende dar en un blanco pero está apuntando a otro; mientras que un estimador insesgado es uno que realmente apunta hacia al blanco, en el caso de muestreo el parámetro poblacional θ, y que espera dar en él. Suponiendo que tenemos dos estimadores 𝜃̂1 y 𝜃̂2 que siguen cada uno, una distribución normal, el primero insesgado y el segundo no, la siguiente gráfica nos muestra como con el primer estimador estamos en condiciones de hacer una mejor estimación que con el segundo, debido a que se espera que el primero coincida con el parámetro poblacional a estimar, mientras que con el segundo se esperar caer en un punto alejado de él Figura N° 2: Comparación entre un estimador insesgado y otro sesgado Un estimador puede presentar un sesgo negativo, cuando se espera tome un valor a la izquierda del parámetro poblacional a estimar, es decir lo subestime; o puede presentar un sesgo positivo, cuando se espera caiga a su derecha y lo sobreestime como en el ejemplo de la encuesta electoral antes mencionada. 2. Estimadores consistentes: Un estimador se dice consistente, cuando a medida que el tamaño de muestra es mayor, el estimador nos recompensa, proporcionándonos una mejor estimación; es decir, que a mayor tamaño de muestra existe una mayor probabilidad de que el estimador caiga muy cercano al parámetro poblacional que pretende estimar. Un estimador que carezca de esta propiedad queda prácticamente descalificado, pues no devuelve en precisión el esfuerzo de tomar un mayor tamaño de muestra. Muestreo Aleatorio Angel Francisco Arvelo Pag. 13 Resulta fácil intuir que 𝑦̅ es un estimador consistente para “μ”, pues a medida que más grande sea el tamaño de muestra, más elementos de la población se incorporan a ella, y por lo tanto el valor de 𝑦̅ se acercará más al de “μ”. De hecho cuanto n = N (censo), podemos afirmar con certeza que 𝑦̅ = μ 3. Estimadores suficientes: Se dice que un estimador es suficiente cuando utiliza toda la información contenida en la muestra, es decir, cuando no desperdicia información y toma en cuenta a todas las observaciones muéstrales. Así por ejemplo 𝑦̅ es un estimador suficiente puesto que para calcular su valor, necesitamos conocer el valor de todas las observaciones que cayeron en la muestra; si falta por determinar alguna de ellas, ya no podremos calcular 𝑦̅. La mediana de una muestra es un ejemplo típico de un estimador que no es suficiente, pues para calcularla sólo tomamos en cuenta a los valores centrales, descartando a los extremos. 4. Estimadores de mínima varianza: Resulta frecuente que al comparar dos estimadores, ambos sean insesgados. En estos casos, el de menor varianza resulta ser el mejor, pues los valores que toma están más concentrados alrededor del parámetro que se desea estimar. La siguiente figura nos señala que con el estimador de menor varianza, se tiene una mayor probabilidad de realizar una mejor estimación debido a que presenta una menor dispersión. Figura N° 3: Comparación entre dos estimadores insesgados La Estadística Matemática proporciona una herramienta conocida como lo cota de Cramer - Rao, que permite reconocer al estimador insesgado con la mínima varianza; de manera que cuando lo encontremos, estaremos en presencia del mejor estimador posible para el parámetro poblacional que deseamos estimar. En lo sucesivo, vamos a suponer que los estimadores propuestos en los diferentes casos que estudiaremos son los óptimos, y omitiremos el análisis de sus propiedades. II.3 Errores en el muestreo Resulta natural que a la hora de hacer una estimación por muestreo no podamos pretender que ésta coincida exactamente con el verdadero valor del parámetro que queremos estimar, y que en consecuencia aparezcan errores. Muestreo Aleatorio Angel Francisco Arvelo Pag. 14 Las causas que ocasionan estos errores pueden ser clasificados en dos categorías: asignables y aleatorias Las causas asignables son aquellas que se pueden identificar y corregir, y que son responsabilidad del investigador, tales como errores en el diseño de la encuesta, preguntas mal redactadas, entrenamiento inadecuado a los encuestadores, imprecisiones en la escala de medición, o fallas en la calibración de los instrumentos de medición. Lamentablemente, muchas veces este tipo de fallas son detectadas después que se ha tomado la muestra, lo que ocasiona un atraso en los estudios por muestreo y una pérdida de los recursos invertidos en la toma de la muestra. De allí la importancia de tomar muestras preliminares o pilotos, que permitan detectar de manera temprana tales errores. Las causas aleatorias son producto de la variabilidad propia del estimador. En efecto, hemos visto que todo estimador es una variable aleatoria, y que por lo tanto su valor varía de una muestra a otra. El valor que toma el estimador en una muestra específica representa un valor particular de esa variable que no necesariamente tiene que ser igual al parámetro que se quiere estimar. Se define como error de muestreo a la diferencia absoluta entre el valor que tomó el estimador en la muestra y el verdadero valor del parámetro poblacional, es decir: Error de muestreo = │𝛉̂ - θ│ Por ejemplo, si estimamos que un parámetro vale 1251 y después resulta que su verdadero valor es 1280, hemos cometido un error de │1251-1280│= 29 unidades El valor absoluto se debe a que el error de estimación puede ser negativo en caso de una subestimación, o positivo si se trata de una sobrestimación. Cuando se realiza un estudio por muestreo, el investigador debe establecer cuál es el máximo error que está dispuesto a tolerar en la muestra, y este se designa designará por ε = Máximo error absoluto tolerado La fijación del valor de “ε” dependerá del orden de magnitud del parámetro que se pretende estimar. Así por ejemplo, si se quiere estimar un parámetro que pensamos está en el orden de los millones, sería absurdo fijar “ε” en el orden de las unidades, pues le estaríamos exigiendo a la muestra un nivel de precisión tal, que seguramente redundará en un tamaño de muestra prácticamente igual a un censo. En caso de que el investigador no tenga idea alguna sobre el orden de magnitud del parámetro que está estimando, lo más prudente es fijar el error tolerado de muestreo en forma relativa o porcentual, definido por la siguiente expresión: Error porcentual de estimación = ̂−θ│ │θ θ 100% En el ejemplo anterior, si un parámetro cuyo verdadero valor es 1280 fue estimado con un error absoluto de 29 unidades, entonces el error relativo de estimación es de 29 1280 100% = 2,27% Al analizar el informe de la muestra, el lector debe estar atento acerca del margen de error de la muestra, e identificar si el error de muestreo está expresado de manera absoluta o de manera relativa. Una regla muy simple para hacer esta identificación es la siguiente: Muestreo Aleatorio Angel Francisco Arvelo Pag. 15 El error absoluto viene expresado en las mismas unidades que el parámetro a estimar, mientras que el error relativo siempre viene expresado en porcentaje Esta regla presenta una única excepción: Cuando el parámetro a estimar es un porcentaje, el error absoluto viene expresado también como un porcentaje, y no se trata de una cifra relativa Por ejemplo, si una encuesta electoral predice que un cierto candidato obtendrá un 32% de la votación, y una vez celebrada las elecciones resulta que obtuvo el 34% de los votos, entonces el error de estimación fue del 2% , y se trata una cifra absoluta, no relativa. Es práctica común en los estudios por muestreo fijar el máximo error relativo tolerado en 1%, 2,5% o 5% en el caso general, y en esos mismos valores porcentuales para el error absoluto, cuando se trate de la estimación de porcentajes. Lo anterior significa que cuando un estudio por muestreo concluye en una cierta estimación para un parámetro, el lector debe interpretar que el verdadero valor es anunciado ± el porcentaje de error; de manera que si se lee en el informe, 𝜃̂ = 1251 unidades, ε=2,5 % entonces se debe inferir que el verdadero valor de θ está en el 1251 ± (2,5% de 1251) = 1251 ± 31,275, es decir dentro del intervalo [1219,725 ; 1282,275] , mientras que si el informe se refiere a la estimación de un porcentaje, como en el caso de una encuesta electoral, que dice 𝜃̂ =32%, ε=2,5 %, entonces la inferencia es que θ= Verdadero Porcentaje Poblacional, está en el intervalo 32% ± 2,5%, es decir dentro del intervalo [29,5%; 34,5%] II.4 Riesgo y Confianza en una estimación por muestreo Tal como hemos visto en la sección anterior, cuando se hace una estimación por muestreo, lo ideal es que el error de estimación resulte como máximo igual al tolerado. Esto sucede cuando │θ̂ - θ│≤ ε Sin embargo, en el momento de tomar la muestra no se puede garantizar que esto realmente va a ocurrir así, pues al ser el estimador una variable aleatoria, existe una cierta probabilidad de que el error de estimación sea mayor que el tolerado, y que por lo tanto, la muestra no satisfaga nuestras expectativas. Esta probabilidad se define como el riesgo del muestreo, y la designaremos por “α” Para ilustrar mejor esta idea, tomemos el siguiente caso: Si se efectúan 100 lanzamientos de una moneda legal, existe una probabilidad de aproximadamente 95% de que el número de caras obtenidas caerá en el intervalo 50 ± 10, ósea en el intervalo [40; 60]. Sin embargo, si tomamos una muestra de este experimento, es decir, si lo realizamos una sola vez, tendremos una probabilidad de aproximadamente 5% de que la predicción no se cumpla, lo representa el riesgo de hacer la predicción. Muestreo Aleatorio Angel Francisco Arvelo Pag. 16 De igual manera en el muestreo, cuando tomamos una muestra de una población, ésta es una de las tantas muestras diferentes que pudieran ser tomadas, tantas como combinaciones podamos hacer entre los elementos que conforman el universo, y por lo tanto, es posible tener la mala suerte que resulte conformada por elementos extremistas, y en consecuencia se cometa un error mayor que el tolerado. En síntesis: El riesgo del muestreo “α” representa la probabilidad de que el error absoluto en la estimación sea mayor que el máximo tolerado α = P(│𝛉̂ - θ│> ε) El complemento del riesgo, es decir, la probabilidad de que el error absoluto en la estimación resulte menor o igual que el máximo tolerado se define como la confianza que proporciona la muestra. 1 -α = P (│𝛉̂ - θ│≤ ε) Suponiendo que el estimador es insesgado y que sigue una Distribución Normal, el siguiente gráfico explica los conceptos de riesgo y confianza del muestreo: = Riesgo del muestreo = P(│𝛉̂ - θ│> ε) 1-α= Confianza= P(│𝛉̂ - θ│≤ ε) Si el estimador se sale de la zona de buena estimación, se incurre en un error mayor que el tolerado La zona de buena estimación es: │𝛉̂ - θ│≤ ε Figura N° 4: Riesgo y Confianza del muestreo A partir del concepto de confianza, la Inferencia Estadística desarrolla la teoría de estimación por intervalos, y obtiene los llamados intervalos de confianza para un parámetro poblacional. Dado que en las diferentes metodologías de muestreo que analizaremos más adelante se utilizará este concepto, se recomienda al lector que consulte en textos de Inferencia Estadística, los procedimientos a seguir para obtener un intervalo de confianza Muestreo Aleatorio Angel Francisco Arvelo Pag. 17 Un Intervalo del (1-α) de confianza para un parámetro poblacional desconocido ̂1 ; 𝜃 ̂2 ] con 𝜃 ̂1 < 𝜃 ̂2 donde 𝜃 ̂1 𝑦 𝜃 ̂2 “θ”, se define como un intervalo aleatorio [𝜃 dependen exclusivamente del resultado de la muestra, y que antes de tomarla, tiene una probabilidad (1-α) de contener al parámetro θ, es decir: ̂ ̂ P(𝜃1 ≤ θ ≤ 𝜃2 ) = 1-α Para facilitar la comprensión de este concepto, consideremos el siguiente ejemplo: Supongamos que una persona anuncia tener 10 billetes, uno de los cuales es falso, y se selecciona al azar uno de ellos. Antes de hacer la selección podría decirse que la probabilidad de seleccionar un billete bueno es del 90%; pero después de hecha la selección, ya no se podría decir lo mismo, pues el hecho aleatorio que era la selección del billete ya se realizó. Lo que cabría decir después de hecha la selección es que al billete seleccionado le tenemos una confianza del 90%. Lo mismo ocurre con el muestreo, existen muchas muestras posibles, y cada una de ellas arrojará intervalos de confianza distintos. Algunos de ellos contienen al parámetro y otros no. Antes de tomar la muestra, la probabilidad de seleccionar a una que contenga al parámetro es 1-α, pero después de tomada la muestra, lo que le tenemos al intervalo seleccionado es una confianza de 1-α Para finalizar estas secciones introductorias, y comenzar a estudiar las diferentes metodologías de muestreo, es importante aclarar que muchas veces se oye decir la siguiente frase: “la muestra debe ser representativa de la población para no incurrir en los errores del muestreo”. Esta frase establece un principio que en la práctica resulta difícil de garantizar, pues se supone que no conocemos a los elementos de la población, ya que si los conociéramos no estaríamos muestreando, y por lo tanto, no sabemos si todos ellos van a quedar representados en la muestra. De allí que siempre tengamos el riesgo de realizar una estimación errónea. Para ilustrar esta idea, supongamos que queremos estimar la estatura media de los alumnos de un colegio, en donde hay niños y adolescentes, y lo que disponemos es de una lista de los alumnos inscritos en el colegio. Si la muestra la tomamos haciendo un sorteo entre todos los alumnos del colegio (muestreo aleatorio simple como veremos en la próxima sección) resulta obvio que existe el riesgo de que solo caigan niños o solo adolescentes, lo que nos va a conducir a una estimación errónea de la media poblacional. Pudiéramos disminuir este riesgo, si ahora en lugar de tener una lista general, obtenemos una en donde aparezcan solo los alumnos de primaria por un lado, y los de secundaria por el otro, y ahora tomamos la muestra seleccionando al azar alumnos de uno y otro grupo (muestreo aleatorio estratificado). Este nuevo procedimiento tampoco está exento de riesgo, porque es posible que en cada una de las dos muestras, caigan solo alumnos de los primeros años de primaria y de secundaria, o exclusivamente de los últimos años de cada nivel. Se puede continuar afinando nuestra estimación, y decir que ahora vamos a conseguir las listas de cada uno de los salones de clase, y que tomaremos la Muestreo Aleatorio Angel Francisco Arvelo Pag. 18 muestra seleccionando al azar un cierto número de alumnos en cada salón; pero también nos encontramos que en dichas muestras existe el riesgo de que caigan en ella solo los más bajos, o solo los más altos de cada salón. Llegado este punto, no faltará alguien que sugiera que entonces lo mejor es que se estratifique a los alumnos por niveles de estatura, bajos, medianos y altos y se tome una muestra al azar en cada categoría, y pronto caeremos en cuenta que esto no es posible porque para hacer dicha clasificación, necesitaríamos conocer la estatura de cada uno de los alumnos, y el muestreo ya no tendría sentido. Conclusión; El riesgo es inherente al muestreo Al igual que en una rifa, la única manera de garantizar que ganaremos el premio es comprando todos los boletos. Desde el mismo momento en que decidimos realizar un estudio por muestreo debemos estar conscientes de que estamos asumiendo un riesgo, y de allí la importancia de conocer el margen de error y el nivel de confianza que nos ofrece la muestra III. MUESTREO ALEATORIO SIMPLE Existen numerosas técnicas de muestreo, que se diferencian unas de otras, en la manera de seleccionar la muestra; en el muestreo aleatorio simple, la muestra debe ser tomada de manera que cada una de todas las posibles muestras, tenga la misma probabilidad de ser seleccionada. El principio de igualdad de probabilidad para todas las posibles muestras, es quizás el más violado a la hora de seleccionar la muestra; debido a que el investigador generalmente clasifica a la población en grupos, y luego toma la muestra de manera que en ella caigan representantes de cada grupo, pensando que de esa manera, la muestra es más representativa. Esta manera de tomar la muestra no es que sea incorrecta, por el contrario, por lo general conduce a resultados más precisos, que los que se obtendrían, aplicando muestreo aleatorio simple; lo que si no es correcto, es pretender aplicar las fórmulas y principios del muestreo aleatorio simple, a una muestra tomada de forma estratificada; ya que las fórmulas correspondientes al muestreo aleatorio simple , son obtenidas bajo la premisa de que todas las muestras son igualmente probables; principio que obviamente no se cumple , cuando la muestra se toma de forma estratificada, ya que una muestra formada por elementos de un mismo grupo, tendría una probabilidad nula de ser tomada, mientras que una muestra formada por elementos de grupos diferentes tendría una probabilidad muy alta de ser tomada. En caso de que la muestra se tome de forma estratificada, las fórmulas y principios a aplicar, son otros, diferentes a los que se verán en esta sección Los pasos a seguir para obtener una muestra aleatoria simple son los siguientes: Muestreo Aleatorio Angel Francisco Arvelo Pag. 19 Paso 1: En primer lugar es necesario definir el universo sobre el cual se va a tomar la muestra Paso 2: En segundo lugar es necesario conseguir una lista numerada del 1 al N que contenga a todos los elementos del universo. La numeración puede ser hecha por cualquier criterio, alfabético, por el número de la cedula de identidad, etc. Si no es posible obtener esta lista, entonces se debe establecer previo a la muestra, una regla de conteo que permita identificar a cada elemento del universo. Ejemplo 3.1: En los estudios de calidad, es común que se deba examinar para su aceptación, lotes de piezas las cuales vienen empacadas dentro de una caja. Para tomar una muestra aleatoria, se deben enumerar las cajas, o en su defecto establecer una regla de numeración. Si están colocadas sobre el suelo, decir por ejemplo que la caja más a la izquierda es la No 1, luego la No 2, y así sucesivamente hasta la última. Posteriormente se debe también establecer otra regla de numeración dentro de la caja, que permita identificar cada pieza. Supongamos que se debe tomar una muestra de botellas para medir su contenido, y que estas se encuentran distribuidas en 100 cajas cada una de las cuales contiene 36 botellas. En este caso N = 100 x 36 = 3600 botellas Para identificar cada una de las botellas del universo, debemos asignarle un número a cada caja, y otro número a cada posición dentro de la caja, y así sabremos que la botella No 1 es la que ocupa la posición No 1 dentro de la caja No 1, la botella No 40 es la que ocupa la posición No 4 dentro de la caja N o 2, la botella No 348 la que ocupa la posición No 24 dentro de la caja No 10, etc., y la botella No 3600, la que ocupa la posición No 36 de la caja No 100. Paso 3: Hacer un sorteo sin reemplazo, seleccionando al azar y con igual probabilidad, “n” números cualesquiera dentro de los “N” que existen en el universo. Para efectuar este sorteo, existen varios procedimientos. El más antiguo es escribir “N” papeles con los números del 1 al N, colocarlos dentro de un sombrero, y seleccionar uno a uno, los “n” elementos que conformarán la muestra. Otro procedimiento un poco más moderno para hacer el sorteo, es mediante la tabla de números aleatorios, la cual se construye seleccionando con reemplazo los dígitos del 0 al 9, y según vayan apareciendo se colocan en filas y columnas. Con la aparición de las calculadoras electrónicas esta tabla cayó en desuso, y hoy en día, el procedimiento más usado es el de la generación de número aleatorios, que consiste en un sorteo simulado, en donde se le pide a la calculadora que genere números enteros al azar entre 1 y N, y a través de un algoritmo interno, la calculadora lo selecciona según una distribución uniforme discreta. Paso 4: Una vez seleccionados los números que conforman la muestra, debemos ir a los elementos de la población identificados con esos números, y medir o preguntarles el valor de la variable estadística asociada a cada uno de ellos. Muestreo Aleatorio Angel Francisco Arvelo Pag. 20 Es importante destacar que el número de muestras posibles en un muestreo N! N aleatorio simple es ( ) = n! (N−n)! , y que al ser cada una igualmente probable, la n 1 probabilidad de seleccionar una de ellas en particular es N ( n) Por ejemplo, si el universo está formado por los 5 elementos {a, b, c, d, e}, y se va a 5! 5 tomar una muestra de 2 de ellos, entonces existen ( ) = 2! 3!!= 10 muestras 2 posibles, que son {ab, ac, ad, ae, bc, bd, be, cd, ce, de}, y la probabilidad de seleccionar cualquiera de ellas es 1/10 Según sea el parámetro que se quiera estimar en la población, debemos distinguir entre "Muestreo aleatorio para Variables”, "Muestreo aleatorio para Proporciones y Porcentajes”, “Muestro aleatorio para Razones” III.1 Muestreo Aleatorio para Variables: En este caso, la población está formada por un conjunto de valores numéricos asociados a cada uno de los elementos del universo; tal como puede ser un grupo de personas, en donde estamos observando el peso de cada uno de ellos, o un conjunto de residencias que cada una tiene un número variable de habitantes, o una producción de cigarrillos, en donde cada uno tiene una longitud, o un diámetro distinto. La variable estadística en este caso es cuantitativa, y la población está formada por el conjunto de valores numéricos que ella toma sobre cada uno de los elementos del universo. La nomenclatura seguir es la siguiente: N = Tamaño de la Población Población = {x1 , x2 , x3 ⋯ , xN } xi = Valor de la variable estadística asociado al i-ésimo elemento de la población (i=1, 2,3...N); Cada xi es un número real i N x = i 1 = Total Poblacional. i i n x i i N i i N 2 (y i 1 = Media Poblacional. N i )2 N = Varianza Poblacional. n = Tamaño de la muestra. Muestra= {y1 , y2 , y3 ⋯ , yn } yj = Valor de la variable estadística asociado al j-ésimo elemento de la muestra (j=1, 2,3...n) Muestreo Aleatorio Angel Francisco Arvelo Pag. 21 j n y y j 1 j n = Media muestral = = Estimador de μ T = = N y = Estimador de j n s2 f= (y j 1 j y)2 n 1 = Varianza muestral = 2 = Estimador de 2 n = Fracción de muestreo. N La notación convencional en muestreo consiste en designar a los parámetros poblacionales con letras griegas, mientras que a sus correspondientes estimadores muéstrales con letras latinas. Cabe destacar que se emplean diferentes letras, “y” para designar a los valores muéstrales , “x” para los poblacionales, puesto que estos no tienen por qué coincidir; de hecho por ejemplo ,el décimo elemento de la población puede no salir en la muestra, o si sale, puede ser que ocupe otro lugar. Usualmente los valores poblacionales son desconocidos, puesto que para conocerlos habría que conocer los valores numéricos asociados a cada uno de los elementos de la población, lo que dejaría al muestreo sin sentido. Los parámetros poblacionales a estimar suelen ser la media poblacional y / o, el total poblacional. En lo que se refiere a los valores muéstrales, estos son conocidos para la muestra tomada, pero deben ser vistos como valores particulares de una variable aleatoria; puesto que el valor que ellos toman, depende obviamente de los elementos que formen la muestra, los cuales se seleccionan aleatoriamente. Una vez tomada la muestra, es posible definir intervalos de confianza tanto para la media poblacional, como para el total poblacional, los cuales vienen dados por las siguientes expresiones: ̅ ± zα/2 s √1 − f Intervalo de confianza para μ: y n √ Intervalo de confianza para : N 𝑦̅ ± N zα/2 s √n √1 − f zα/2 = Abscisa que en la Normal Tipificada deja a la derecha un área /2 El valor de z/2, depende del nivel de confianza (1-) deseado, siendo los más frecuentes 90%, 95% o 99% de confianza, para los cuales el valor de z/2 puede ser leído en las tablas de La Distribución Normal, encontrándose: Muestreo Aleatorio Angel Francisco Arvelo Pag. Confianza zα/2 90 % 95 % 99 % 1,645 1,960 2,576 22 Figura N° 5: Abscisas de la Distribución Normal para un nivel de confianza dado Es costumbre que los intervalos de confianza sean simétricos y que por lo tanto el riesgo “α” se reparta por mitad entre las dos colas de la Distribución Normal. El término sin multiplica por la abscisa z/2, se suele llamar “el error estándar de la estimación”, mientras que una vez multiplicarlo por la abscisa, representa el error de muestreo para el nivel de confianza establecido. 𝑠 Así por ejemplo 𝑛 √1 − 𝑓 es el error estándar en la estimación de μ, mientras que zα/2 s √n √ √1 − f representa el radio del intervalo de confianza, es decir el margen de error tolerado, para un nivel del (1-α) de confianza Un comentario importante en las expresiones para el intervalo de confianza es el que se refiere a la relación entre el radio del intervalo y el nivel de confianza. Fácilmente se puede observar que cuanto mayor sea la confianza, mayor será el radio del intervalo, y viceversa; lo cual es completamente lógico, pues si al hacer un disparo sobre un blanco, queremos aumentar la probabilidad de acierto, se debe aumentar el radio del blanco. Ejemplo: Una de las áreas en donde las técnicas de muestreo han encontrado un gran campo de aplicación, es en las auditorías contables. En efecto, así como el contador debe preocuparse para que las cuentas cuadren al céntimo, el auditor debe certificar que el estado financiero refleja cifras creíbles, y en este sentido, el muestreo constituye una herramienta muy útil, pues si la cifra dada en el estado financiero cae dentro del intervalo de confianza obtenido por muestreo, el auditor puede validar esa cifra, sin necesidad de examinar la totalidad de documentos. Consideremos el siguiente caso: Se quiere estimar el monto total de las ventas de una empresa durante un periodo de tiempo dado. Existen 32.500 facturas de venta emitidas durante ese lapso. Una muestra aleatoria simple de 100 facturas los siguientes montos expresados en unidades monetarias: 1.565,81 1.272,97 1.589,60 1.712,11 2.120,34 1.164,33 1.894,14 2.130,09 948,98 1.077,25 1.681,15 2.160,39 2.554,25 2.413,25 1.781,19 1.819,62 1.772,66 2.095,72 1.587,10 876,39 1.569,50 1.426,80 2.145,41 2.085,90 2.530,04 782,58 1.192,46 2.239,11 1.900,94 1.628,44 2.179,82 1.797,69 2.387,37 1.599,76 1.662,57 2.476,30 2.362,04 1.960,13 2.428,22 1.150,14 1.448,19 1.572,99 1.966,96 2.393,09 1.956,70 1.942,82 1.877,08 1.593,56 1.727,20 2.565,92 3.202,97 1.151,57 999,62 1.443,49 2.081,10 2.166,43 2.002,05 1.398,05 778,04 1.061,72 1.791,71 2.326,23 1.415,03 1.967,46 1.494,16 817,62 1.793,70 1.832,01 2.098,32 842,67 1.652,48 2.722,45 1.652,15 1.944,56 1.099,40 1.132,65 2.249,14 1.467,12 1.209,68 2.091,25 1.538,34 1.618,40 1.810,55 1.098,63 2.428,79 1.671,05 1.546,75 1.372,94 2.797,18 1.825,83 2.225,79 1.565,78 1.554,80 1.928,56 1.681,24 2.342,90 674,06 1.719,57 2.363,02 2.389,28 Muestreo Aleatorio Angel Francisco Arvelo Pag. 23 Para inferir en base a esta muestra el monto total de las ventas (Total poblacional) hay que calcular la media y la desviación estándar de la muestra, que dan por resultado: y̅ = 1.776,90; s = 505,35 En base a esta información, el intervalo del 95% de confianza para el monto promedio de estas 32.500 facturas resulta ser: 1.776,90 ± 1,96 505,35 √100 100 √1 − 32500 = 1.776,90 ± 98,90 Mientras que para el total poblacional, el intervalo del 95% de confianza es: 32500 x 1.776,90 ± 32500 x1, 96 505,35 √100 100 √1 − 32500 = 57.749.250,00 ± 3.214.123,25 Esto significa que con 95% de confianza, se puede afirmar que las ventas totales están dentro del intervalo [54.535.126,75; 60.963.373,25], de manera que si estado financiero reporta un monto comprendido dentro del intervalo, el auditor considerará aceptable esta cifra, caso contrario hará una investigación más exhaustiva. 3.214.123,25 representa el error absoluto en la estimación, mientras que (3.214.123,25/ 57.749.250,00) 100% = 5,57% el error relativo Ejemplo: De un lote de 10.000 pilas, se tomó una muestra de 25, y se observó su duración en horas, encontrándose los siguientes resultados: Duración Frecuencia (horas) 10-40 2 40-70 4 70-100 8 100-130 5 130-160 6 Obténgase un intervalo del 95% de confianza, para la duración media de las pilas del lote. Solución: En primer lugar, es necesario calcular la media y la desviación estándar de la muestra. Estas resultan ser: y = 95,80 s= 37,63 Se tiene n = 25, y Z0.025 = 1,96 para 95% de confianza Reemplazando, se obtiene que el intervalo del 95 % de confianza para μ es: 37,63 25 1 95,80 1,96 = 95,80 14,73 = 81,07; 110,53 10000 25 Determinación del tamaño de la muestra: En la estimación de parámetros a través del muestreo, la pregunta clave siempre suele ser el tamaño de la muestra que es necesario tomar. Responder esta pregunta no es fácil, y para ello, es necesario definir con anterioridad dos conceptos: Muestreo Aleatorio Angel Francisco Arvelo Pag. 24 Cuando se va a estimar un parámetro desconocido, como lo es μ, a través de un valor aleatorio muestral, como lo es y , no podemos esperar que ambos coincidan, y por lo tanto aparece un error de estimación definido por la diferencia absoluta entre ellos. Tenemos entonces que: Error absoluto de estimación = | y - μ| Evidentemente, este error de estimación es una medida de la precisión del muestreo, y cuanto menor sea el error que estamos dispuestos a aceptar, mayor será el tamaño de la muestra; hasta el punto, que si no estamos dispuestos a tolerar ningún error, no nos quedará más remedio, que hacer un censo de la población. El máximo error que estamos dispuestos a tolerar, lo designaremos por "", y representa entonces, la precisión con que estamos trabajando en el muestreo. = Error máximo tolerado = Max | y - μ| Es frecuente, que en lugar de definir al error en términos absolutos, tal como se hizo anteriormente, se haga en términos relativos, dividiendo al error absoluto entre el verdadero valor del parámetro, y expresándolo en términos porcentuales: Error relativo en la estimación de μ= % y 100% Fijar el error máximo que estamos dispuestos a tolerar, no basta para poder calcular el tamaño de la muestra, porque siendo ésta aleatoria, siempre tendremos un cierto riesgo de que este formada por elementos extremos, que nos lleven a una falsa inferencia; es por ello, que el otro término que hace falta fijar, para poder definir el tamaño de la muestra, es el riesgo del muestreo, que se define como la probabilidad de tomar una muestra que nos haga cometer un error de estimación mayor que el máximo tolerado; es decir: = Riesgo del muestreo = P( | y - μ| > ) Figura N° 6: Confianza en la estimación de una media poblacional Es también evidente, que cuanto menor sea el riesgo que estemos dispuestos a correr, mayor será el tamaño de muestra necesario, y que en el caso =0, se necesitará un censo, es decir: n = N. Usualmente el riesgo se fija en 1%, 5% o 10%. Una vez definido el error máximo tolerado, y el riesgo del muestreo, el tamaño de la muestra puede ser calculado mediante la aplicación de la siguiente fórmula: Muestreo Aleatorio Angel Francisco Arvelo Pag. 25 2 N zα/2 σ2 n= 2 2 zα/2σ + (N − 1) ε2 En donde: N = Tamaño de la población. 2= Varianza Poblacional. = Máximo error absoluto tolerado. = Riesgo del muestreo z/2 = Abscisa que en la normal estándar deja a la derecha un área "/2". Con relación a la fórmula anterior, es importante hacer las siguientes observaciones: a) Una de las creencias más arraigadas, es la de pensar que para un nivel de riesgo y de error fijos, el tamaño de muestra es siempre un porcentaje fijo de la población. La fórmula anterior, nos muestra que esta creencia es falsa, puesto que si graficamos la forma como varia el tamaño de muestra al variar el tamaño de la población, manteniendo fijos el error tolerado, y el riesgo, encontramos una curva como la siguiente: En esta curva podemos fácilmente ver, que el tamaño de muestra no crece linealmente con el tamaño de población; por el contrario, crece mucho más lentamente, haciéndose asintótica a la recta horizontal: 𝑛∞ = N z2α/2 σ2 2 𝑁⟶∞ zα/2 σ2 +(N−1) ε2 Debido a que : lim = z2α/2 σ2 ε2 2 zα/2 σ2 ε2 lo que nos indica que en una población infinita, no necesitamos una muestra infinita. Es aquí donde radica la gran importancia del muestreo, puesto que cuanto mayor es la población, más económico es el muestreo en comparación con el censo; mientras que en poblaciones pequeñas, es posible que la muestra represente una proporción muy apreciable de ella. Muestreo Aleatorio Angel Francisco Arvelo Pag. 26 Una consecuencia práctica de este resultado es que cuando en una población no sabemos exactamente cuál es su tamaño, perfectamente podemos suponer que es infinita, y esto no ocasionara un incremento significativo en el tamaño de muestra requerido b) La segunda observación que es necesario plantear, con relación a la fórmula para obtener el tamaño de muestra, es la que se refiere al desconocimiento acerca del valor de la varianza poblacional 2 ; en efecto, todos los términos que intervienen en la fórmula : N, z/2 y son conocidos o fijados, a excepción de 2, el cual ni se conoce , ni se podrá conocer, puesto que para calcularla, sería necesario conocer los valores numéricos de la población, lo cual obviamente, dejaría sin objetivos al muestreo. Este detalle hace que no exista una solución matemáticamente exacta para resolver el problema del tamaño de muestra, y que la solución sugerida a continuación, solo nos brinde una aproximación. En la sección anterior vimos la conveniencia de realizar muestras preliminares o pilotos, para detectar de manera temprana posibles errores en el diseño de la encuesta. Este tipo de muestras también pueden ser utilizadas para obtener una estimación preliminar de σ2 , que sustituida dentro de la fórmula del tamaño de muestra, dará una solución aproximada al problema. La estimación preliminar de σ2 a partir de la muestra piloto, puede hacerse a través del su varianza muestral s2, o como sugieren algunos autores, estimando σ tomando la cuarta parte del rango de la muestra piloto (el rango es la diferencia 𝑦 −𝑦 entre el mayor y el menor valor de la muestra), es decir: 𝜎̂ = 𝑚𝑎𝑥 4 𝑚𝑖𝑛 Sin embargo, ahora aparecen dos nuevas preguntas, que no estaban planteadas inicialmente, que son: ¿de qué tamaño debe ser esta muestra piloto? , y ¿Qué garantía tenemos de que la estimación hecha de 2, a través de s2, o a través del rango de la muestra piloto, es satisfactoria? Lamentablemente, la solución a toda esta problemática nos conduce a un proceso iterativo de ensayo y error, que comienza asumiendo un tamaño de muestra piloto, que no debería exceder del 1% del tamaño de la población, o del 0,5% en el caso de poblaciones grandes; una vez tomada esta primera muestra piloto, se estima el valor de σ2, y se calcula "n”. Si este valor de “n”si resulta inferior al de la muestra piloto nos indica que con esta basta, y si resulta mayor, es necesario completar la muestra, hasta que al recalcular el valor de "n”, el tamaño resulte igual o menor que el tomado. La siguiente gráfica resume la metodología a seguir: Figura N° 6: Etapas en la investigación por muestreo Para más detalle sobre estas etapas, se recomienda ir a la sección I.4 Muestreo Aleatorio Angel Francisco Arvelo Pag. 27 c) Una tercera observación con relación a la fórmula del tamaño de muestra, es la que se refiere a la selección del "" (error máximo tolerado), el cual tiene que ser fijado en términos absolutos, para poder ser sustituido en la fórmula. Obviamente la fijación de un "" inadecuado, redundará negativamente en el tamaño de muestra a tomar, puesto que si "" es muy grande entonces el muestreo será impreciso y la estimación será poco confiable, y si "" es muy pequeño, entonces el tamaño de muestra resultará gigantesco, aproximándose casi a un censo, perdiendo así las ventajas del muestreo. Mucho más prudente, es fijar el error máximo tolerado en términos relativos, es decir como un porcentaje del parámetro a estimar; pero a la hora de sustituir dentro de la fórmula, éste debe ser absoluto, y entonces se plantea la pregunta de cómo calcularlo, si ignoramos el verdadero valor del parámetro. Es decir, si por ejemplo, decimos que la estimación de la media poblacional, debe ser con un error máximo del 5%, entonces estamos diciendo = 0,05 μ, pero "μ" lo ignoramos, y entonces ¿cómo lo sustituimos dentro de la fórmula? Esta situación se resuelve, fijando el error máximo tolerado en términos relativos, y a la hora de tomar la muestra piloto, entonces se utiliza el valor estimado del parámetro, que en el caso de la media poblacional sería, la media de la muestra piloto, para calcular el error máximo tolerado, en términos absolutos, el cual es sustituido dentro de la fórmula del tamaño de muestra, a lo fines de determinar si la muestra piloto fue insuficiente o no. Por supuesto, que ahora se plantea un nuevo elemento en la iteración, puesto que cada vez se complete la muestra, se necesita recalcular el valor estimado del parámetro, y por ende, del error máximo tolerado en términos absolutos. Ejemplo: En un lote de 20.000 bombillos, se quiere estimar su duración media con un error máximo del 1%, y un riesgo del 5%. Si una muestra piloto de 50 bombillos, arrojó una duración media de 5.200 horas, con una desviación típica de 350 horas. a) ¿Qué tamaño de muestra se necesita? b) Si la nueva muestra anterior arroja una duración media de 5640 horas con una desviación típica de 320 horas, ¿es suficiente con esa muestra? c) Obtenga un intervalo del 95% de confianza, para la duración media del lote Solución: a) Tomando la información de la muestra piloto, tenemos que 𝜎̂ = 350 𝜇̂ = 5200 Además ε= 1% de 5200 = 52 horas, zα/2= 1,96 Sustituyendo encontramos: 𝑛 = 20000 ∙ 1,962 ∙ 3502 1,962 ∙ 3502 + 19999 ∙ 522 = 172,54 Es decir, que se necesita una muestra de 173 bombillos. Como la muestra piloto era de solo 50 bombillos, es necesario examinar 123 adicionales (en teoría deberían ser otros 173 bombillos) b) Con la información de la nueva muestra se tiene: que 𝜎̂ = 320 𝜇̂ = 5640 Además ε= 1% de 5640 = 56,40 horas, zα/2= 1,96 Sustituyendo encontramos: 𝑛 = 20000 ∙ 1,962 ∙ 3202 1,962 ∙ 3202 + 19999 ∙ 56,402 = 122,91 < 173 Muestreo Aleatorio Angel Francisco Arvelo Pag. 28 Esto significa que la muestra con n= 173 es suficiente. Si “n” hubiese resultado mayor que 173, en teoría se debería continuar iterando, pero en la práctica se suele detener el proceso aquí, a pesar de que la estimación va a resultar con un margen de error mayor que el previsto. c) El intervalo de confianza para “μ” será entonces 5640± 1,96 320 √173 173 √1 − 20000 = 5640,00 ± 47,48 En caso de que el parámetro a estimar, sea el total poblacional, la fórmula anterior del tamaño de muestra, y los procedimientos iterativos descritos, siguen teniendo vigencia, pero distinguiendo dos casos: Caso 1. Si el error máximo tolerado para estimar al total poblacional “𝜏””esta fijado de manera relativa, la fórmula para el tamaño de muestra se aplica sin modificaciones, pues estimar al total poblacional con un determinado porcentaje de error equivale a estimar la media poblacional con ese mismo porcentaje de error. Caso 2. Si el error máximo tolerado para estimar al total poblacional “𝜏””esta fijado de manera absoluta, la fórmula para el tamaño de muestra se aplica pero tomando “ε” al error absoluto para el total poblacional dividido entre el tamaño de población. Esta modificación se debe a que en la dicha fórmula para el tamaño de muestra, “ε” representa el error tolerado en la estimación de “μ”, no en la estimación de “𝜏””, y 𝜏 𝜇=𝑁 Ejemplo Nº2: En un almacén en donde existen 5000 objetos diferentes, se quiere estimar el valor total de ellas, con un error no mayor del 5%, y un nivel de riesgo del 10%. Una muestra piloto de 20 piezas seleccionadas al azar arrojó los siguientes valores, según la opinión de un perito auditor: 134 276 784 756 503 1076 432 178 675 987 654 860 906 398 187 1655 543 765 534 610 a) Calcule el tamaño de la muestra que es necesario tomar. b) Si la muestra calculada anteriormente da una media de Bs. 685, con una desviación típica de Bs. 346. ¿Cree Ud. que la muestra tomada fue suficiente? c) Encuentre un intervalo del 90% de confianza para el valor total de las piezas almacenadas. Solución: a) En primer lugar, es necesario estimar σ, y para ello tenemos dos opciones, a partir de la desviación estándar de la muestra, o a partir de la cuarta parte del rango. Si lo hacemos a partir de la desviación estándar de la muestra: 𝜎̂ = s= 359,81 Si lo hacemos a partir de la cuarta parte del rango: 𝜎̂ = 1655−134 4 = 380,25 Muestreo Aleatorio Angel Francisco Arvelo Pag. 29 Cuanto mayor sea “σ”, mayor será el tamaño de muestra requerido, por lo tanto si se quiere un cálculo de “n” que evite futuras iteraciones, se deberá tomar la estimación mayor, en este caso 𝜎̂ =380,25 Hay que calcular también la media de la muestra piloto 𝑦̅ = 𝜇̂ = 645,65 Además N = 5000 ε= 5% de 645,55 =32,28, zα/2= 1,645 para 90 % de confianza Nótese que a pesar de que se desea estimar un total poblacional, se procede de la misma manera como si se tratara de una media poblacional. Esto es debido a que estimar un total poblacional con un error relativo del 5% es equivalente a estimar la media poblacional con ese mismo error relativo 𝑛= 5000 ∙ 1,6452 ∙ 380,252 1,6452 ∙ 380,252 + 4999 ∙ 32,282 = 349,23 > 20 ⇒ la muestra piloto fue insuficiente b) Si tomada ahora la muestra con n= 350 objetos, se encuentra 𝜎̂ =346 𝜇̂ = 685, se tiene entonces ε= 5% de 685= 34,25, y sustituyendo: 𝑛= 5000 ∙ 1,6452 ∙ 3462 1,6452 ∙ 3462 + 4999 ∙ 34,252 = 261,76 < 350 ⇒ la muestra es suficiente c) El intervalo del 90% de confianza para el total poblacional “𝜏” resulta: 5000 x 685 ± 5000 x 1,645 346 √350 350 √1 − 5000 = 3.425.00, 00 ± 146.696,40 III.2 Muestreo Aleatorio para proporciones y porcentajes: En numerosas oportunidades, el parámetro que se quiere estimar, es el porcentaje de elementos que en una población determinada, poseen una cierta característica o atributo. Este atributo puede ser cualquier cualidad que divida al universo en dos categorías, los que lo poseen, y los que no lo poseen; como por ejemplo, un universo de piezas que pueden ser clasificadas como buenas o defectuosas, o un universo de consumidores que prefieren o no prefieren una cierta marca. En tales casos, es posible aplicar el muestreo aleatorio simple, tomando por supuesto, la muestra de la misma manera como se describió al principio, con igualdad de chance para todas las muestras posibles. Este caso es un caso particular del anterior por variables. En efecto, en el muestreo por variables, la población está constituida por un conjunto de valores numéricos {x1 , x2 , x3 ⋯ , xN } en donde cada xi es un número real cualesquiera. En el muestreo por atributos: 0 ; si el i-ésimo elemento de la población no posee el atributo xi 1 ; si el i-ésimo elemento de la población posee el atributo La nomenclatura a seguir es la siguiente: N = Tamaño de la población. 𝜏 = Total de elementos que en la población, poseen una cierta característica. τ π = = Proporción de elementos con la característica, en la población. N n = Tamaño de la muestra. t = Total de elementos que en la muestra, poseen una cierta característica. Muestreo Aleatorio Angel Francisco Arvelo Pag. 30 𝑡 p = = Proporción de elementos con la característica, en la muestra. 𝑛 n 𝑓 = = Fracción de muestreo N En vista de que los xi de la población son ceros o unos, y los yi de la muestra también, el total poblacional = i N x i 1 i resulta ser el número de unos existentes en la población, pues evidentemente una suma de ceros y unos da por resultado el total de unos, es decir el total de elementos con el atributo en la población, mientras i n que t = y i representa el número de elementos con el atributo presentes en la i 1 muestra. Con este simple argumento, resulta fácil caer en cuenta, que en el muestreo por atributos, “π” desempeña el papel de “μ”, mientras que “p” el de 𝑦̅ Los parámetros a estimar por muestreo, suelen ser "π" y/o “𝜏”, siendo sus correspondientes intervalos de confianza: Intervalo del (1-α) de confianza para "π”: 𝑝 ± zα/2 √ p(1−p) n−1 Intervalo del (1-α) de confianza para“𝜏”: 𝑁𝑝 ± Nzα/2 √ √1 − f p(1−p) n−1 √1 − f Ejemplo: Si de un lote de 7.000 piezas, se toma una muestra aleatoria de 150 piezas, encontrándose 12 defectuosas. Halle un intervalo del 95% de confianza, para el porcentaje de defectuosas, y para el total de defectuosas en el lote. 12 Solución: 𝑝 = 150 = 0,08 N = 7000 z0,025 = 1,96 n= 150 Intervalo para "π”: 0.08 ± 1,96 √ (0,08) ∙(0,92) 149 150 √1 − 7000 = 0,0800 ± 0,0431 Es decir, que con 95% de confianza, se puede afirmar que el porcentaje de defectuosos en el lote está entre 3,69% y 12,31% Intervalo para “𝜏”:7000 (0.08) ± 7000 (1,96) √ (0,08) ∙(0,92) 149 150 √1 − 7000 = ± 301,70 Es decir, que con 95% de confianza, se puede afirmar que el número defectuosos en el lote está entre 278 y 882 580 de Determinación del tamaño de la muestra en muestreo para proporciones y porcentajes: Muestreo Aleatorio Angel Francisco Arvelo Pag. 31 Los conceptos anteriormente definidos de error y riesgo, siguen siendo necesarios en este tipo de muestreo, sin embargo, como este caso el parámetro a estimar es "π”, tenemos que: Error de estimación = | p -π | Error máximo tolerado = ε = Máxima diferencia tolerada de | p -π | Riesgo = α = Probabilidad (| p -π | > ε) Es importante aclarar, que en este tipo de estimación jamás se trabaja con errores relativos; siempre que se dé un error, este debe interpretarse como absoluto. Así por ejemplo, cuando decimos que se quiere estimar el porcentaje de votos que va a obtener un candidato en unas elecciones, con un error del 1%; este 1% debe interpretarse como la diferencia absoluta, entre la estimación hecha, y el verdadero porcentaje de votos a favor del candidato. Una vez definido el error máximo tolerado y el riesgo, el tamaño de la muestra puede ser calculado mediante la aplicación de la siguiente fórmula: 2 𝑁𝑍𝛼/2 𝜋(1 − 𝜋) 𝑛= 2 (𝑁 − 1)𝜀 2 + 𝑍𝛼/2 𝜋(1 − 𝜋) Para poblaciones infinitas, el tamaño de muestra requerido resulta ser: 2 2 𝑁𝑍𝛼/2 𝜋(1 − 𝜋) 𝑍𝛼/2 𝜋(1 − 𝜋) 𝑛 = lim = 2 2 𝑁⟶∞ (𝑁 − 1)𝜀 + 𝑍 𝜀2 𝛼/2 𝜋(1 − 𝜋) Nuevamente aquí, se presenta la misma situación descrita antes, ya que como el valor de "π", es desconocido, el mismo debe ser estimado a través de una muestra piloto, lo que conduce a un proceso iterativo, que consiste en ir completando la muestra, hasta que al recalcular el valor de "n", se obtenga un valor igual o menor al ya tomado. Es importante aclarar sin embargo, que en caso de la estimación de proporciones y porcentajes, existe un artificio para obviar la muestra piloto, ya que matemáticamente, puede demostrarse que para un tamaño de población dado "N", el valor máximo del tamaño de muestra corresponde al caso π =0,50, lo que da por tamaño máximo: 2 𝑁𝑍𝛼/2 𝑛𝑚𝑎𝑥 = 2 4 (𝑁 − 1)𝜀 2 + 𝑍𝛼/2 de forma, que si el investigador, sospecha que el valor de "π" está cercano al 50%, puede tomar de una vez el máximo tamaño de muestra, sin necesidad de tomar muestra piloto. En caso de que el investigador sospeche que el valor de "π" está muy alejado del 50%, se justifica tomar las muestras piloto y el proceso iterativo, ya que tomar de entrada la muestra máxima, puede resultar antieconómico, debido a que Muestreo Aleatorio Angel Francisco Arvelo Pag. 32 posiblemente, esté tomando una muestra triple o cuádruple, de la que realmente necesita. El tamaño de la muestra máxima para poblaciones infinitas es: 𝑛 = 2 𝑍𝛼/2 4 𝜀2 , y representa el tamaño más desfavorable, para un error tolerado y un nivel riesgo dado. Otra opción es el de establecer a criterio, o por opinión de expertos, un intervalo donde se piense que debe estar π , y sustituir dentro de la fórmula aquel, que dentro del intervalo se encuentre más cercano a 0,5. Así por ejemplo, si se piensa que π debe estar entre 20% y 35%, 0,20 ≤ π ≤ 0,35, entonces sustituimos dentro de la fórmula el valor de π más desfavorable, es decir π=0,35; pero si se sospecha que π debe estar entre 40% y 60%, 0,40 ≤ π ≤ 0,60, entonces sustituimos dentro de la fórmula el valor de π más desfavorable, es decir π=0,50 Resumiendo: Para calcular el tamaño de muestra en el caso de proporciones y porcentajes, se puede aplicar uno de los siguientes criterios: 1o) Criterio de la muestra máxima: Consiste en sustituir dentro de la fórmula se π por 0,5, y obtener el máximo tamaño de muestra requerido para el nivel de riesgo y error permisible. Si se toma ese tamaño de muestra se obtiene siempre una solución válida para el problema. 2o) El criterio anterior puede resultar antieconómico cuando se sospeche que π anda muy alejado de 0,5, bien cercano a 0 o cercano a 1. En estos casos se recomienda tomar una muestra piloto, que además de evaluar el diseño de la encuesta, permita obtener una estimación preliminar de π. Este procedimiento presenta el riesgo de que puede requerir aproximaciones sucesivas, y a tener que tomar otras muestras piloto. 3o) Otro criterio es el de establecer un intervalo donde se sospeche debe estar π, y sustituir dentro de la fórmula aquel, que dentro del intervalo se encuentre más cercano a 0,5. Este procedimiento permite ahorrar recursos al tomar una muestra menor que la máxima, pero puede requerir futuras iteraciones, en caso de una sospecha errónea acerca del intervalo seleccionado. En caso de que el parámetro a estimar, sea el total de elementos con la característica en la población “𝜏”, las fórmulas y criterios para hallar el tamaño de muestra requerido son los mismos anteriores, pero teniendo en cuenta que el error tolerado en la estimación de “𝜏”, debe ser dividido entre "N", a fin de reducirlo, a un error tolerado en la estimación de "π”. Ejemplo: Se quiere estimar el porcentaje de defectuosas en un lote de 50.000 piezas, con un error no mayor del 2%, y 5% de riesgo. a) ¿Qué tamaño de muestra se necesita?, en cada uno de los siguientes casos: a.1) El experto en calidad opina que según su experiencia, el porcentaje de defectuosos en estos lotes suele ser entre 3% y 6% a.2) En una muestra piloto de 80 piezas se encontraron 10 defectuosas a.3) Muestra máxima Muestreo Aleatorio Angel Francisco Arvelo Pag. 33 b) Si en la muestra calculada en a.2, se encuentran 7% de defectuosas, determine un intervalo del 95% de confianza, para el porcentaje de defectuosas en el lote. Solución: a.1) En el caso de la opinión del experto, se toma como valor de “π” para ser sustituido dentro de la fórmula, aquel dentro del intervalo que proporcione un mayor tamaño de muestra, que es aquel valor más próximo a 0,5., en este caso 6% = 0,06 Se tiene entonces N= 50000, zα/2 = 1,96, ε= 0,02 y sustituyendo: 50000 (1,96)2 (0,06)(0,94) 𝑛 = (49999)(0,02)2 = 536 piezas +(1,96)2 (0,06)(0,94) Este cálculo de “n” presenta el inconveniente que si al tomar la muestra, la proporción de defectuosos contradice la opinión del experto, y resulta superior al 6%, entonces el error de estimación va a resultar mayor que el tolerado 0,02, y por lo tanto la muestra de 536 será insuficiente a.2) La estimación de π según la muestra piloto es π ̂= 50000 (1,96)2 (0,125)(0,875) 𝑛 = (49999)(0,02)2 +(1,96)2 (0,125)(0,875) 10 = 0,125, y sustituyendo: 80 = 1029 piezas Este cálculo de “n” presenta el inconveniente que si al tomar la muestra definitiva, la proporción de defectuosos contradice la estimación de la muestra piloto, y resulta superior al 12,5%, entonces el error de estimación va a resultar mayor que el tolerado 0,02, y por lo tanto la muestra piloto de 1029 será insuficiente. a.3) Para tomar la muestra máxima, basta con hacer π ̂ = 0,50 que representa el caso más desfavorable en cuanto a tamaño de muestra necesario 𝑛𝑚𝑎𝑥 = 2 𝑁𝑍𝛼/2 2 4 (𝑁−1)𝜀2 +𝑍𝛼/2 = 50000 (1,96)2 = 2291 piezas 4 (49999)(0,02)2 +(1,96)2 Este cálculo no puede resultar jamás insuficiente, pero tiene el inconveniente en caso de que el verdadero valor de π esté muy alejado del 50%, sobre estima el tamaño de muestra requerido, con el desperdicio de recurso que eso conlleva. Como se ve, cada uno de estos tres criterios para calcular el tamaño de muestra presenta sus pros y sus contras, y la decisión de cuál de ellos aplicar dependerá del investigador. b) Si la muestra de n=1029 arroja p= π ̂ = 0.07, entonces el intervalo de 95% de confianza para π es: 0.07 ± 1,96 √ (0,07) ∙(0,93) 1029−1 1029 √1 − 50000 = 0,0700 ± 0,0154 = 7,00% ± 1,54 % En error de muestreo resulto ser de 1,54 % < el 2 % tolerado, debido a que en la muestra definitiva de n= 1029, el porcentaje de defectuoso resultó ser menor que en la muestra piloto. De no haber sido así, el error de muestreo hubiese resultado mayor que el tolerado, y en consecuencia la muestra de n= 1029 hubiese sido Muestreo Aleatorio Angel Francisco Arvelo Pag. 34 insuficiente, cuestión esta que no puede ocurrir si de una vez se toma la muestra máxima. III.3 Muestreo aleatorio simple para razones: En algunos estudios, la población está formada por un conjunto de pares {(𝑥1 , 𝑦1 ) (𝑥2 , 𝑦2 ) ⋯ (𝑥𝑁 , 𝑦𝑁 )}, y el parámetro poblacional que se desea estima es: R= ∑𝑁 1 𝑦𝑖 ∑𝑁 1 𝑥𝑖 = 𝜏𝑦 𝜏𝑥 Este es el caso de un estudio en donde lo que se quiere estimar es por ejemplo “el ingreso per cápita” en una localidad en donde residen “N” familias, y la unidad de muestreo, es decir, lo que tiene igual probabilidad de ser seleccionado en la muestra, es la familia no la persona. Cada familia tendrá un par (X, Y), en donde: X= Número de personas que componen la familia Y = Ingreso familiar El ingreso per cápita en esa localidad viene dado por la sumatoria de todos los ingresos dividido entre el total de personas residentes en la localidad. Al tomar la muestra, caerán en ella “n” pares, y el estimador de “R” es: 𝑦̅ 𝑟 = 𝑅̂ = 𝑥̅ mientras que el intervalo del (1-α) de confianza para “R” resulta ser; r ± z𝛼/2 √1−f x̅ √n √ 2 n 2 n 2 ∑n 1 yi −2r ∑1 xi yi +r ∑1 xi n−1 En aquellos casos donde el valor de”𝜏𝑦 ” sea una porción de "𝜏𝑥 “, entonces el valor de “R” representa la proporción o el porcentaje que representa “Y” con relación a “X”. En estos casos, tanto “Y” como “X” deben estar expresados en las mismas unidades. Por ejemplo, si en el par (X, Y), Y representa el gasto que una familia dedica mensualmente para alimentación, y “X” representa el ingreso mensual de esa familia; entonces “R” representa la proporción de los ingresos familiares que son destinados para alimentación. Ejemplo: (Tomado del texto "Técnicas de Muestreo" de William G. Cochran, Pag. 58) La siguiente tabla, muestra el número de personas (Tamaño), el ingreso semanal ($) de la familia (Ingreso), y los gastos semanales ($) de la familia en alimentación (y). Una muestra aleatoria de 33 familias tomada al azar en una gran ciudad arrojó: Tamaño Ingreso Alimentación Tamaño Ingreso Alimentación 2 62 14.3 4 83 36.0 3 62 20.8 2 85 20.6 3 87 22.7 4 73 27.7 5 65 30.5 2 66 25.9 4 58 41.2 5 58 23.3 Muestreo Aleatorio Angel Francisco Arvelo 7 2 4 2 5 3 6 4 4 2 5 3 Pag. 92 88 79 83 62 63 62 60 75 90 75 69 28.2 24.2 30.0 24.2 44.4 13.4 19.8 29.4 27.1 22.2 37.7 22.6 Totales: 3 4 7 3 3 6 2 2 6 4 2 123 77 69 65 77 69 95 77 69 69 67 63 2394 35 39.8 16.8 37.8 34.8 28.7 63.0 19.5 21.6 18.2 20.1 20.7 907.2 A partir de la muestra, se quiere estimar con 95%, los siguientes parámetros poblacionales: a) el promedio de gasto semanal en alimentación por familia, b) el gasto semanal en alimentación por persona c) el porcentaje de los ingresos familiares que son destinados a alimentación. Solución: El caso a) es claramente una estimación por variables, pues cada familia tiene un solo valor numérico asociado, mientras que los casos b) y c) son estimaciones de razón. Las estimaciones puntuales obtenidas para estos tres parámetros, resultan: a) 907,2 907,20 907,20 𝑦̅ = 33 = 27.49 $/familia, b) 𝑟1 = 123 = 7,38 $/persona, y c) 𝑟2 = 2394 = 0,3789 o 37.98% de los ingresos familiares son destinados a alimentación. Para obtener intervalos del 95 % de confianza, es preciso realizar los siguientes cálculos, donde x1 = Tamaño, x2 = Ingreso, y= Alimentación 2 33 2 33 2 33 2 ∑33 𝑖=1 𝑥1𝑖 =533, ∑𝑖=1 𝑥2𝑖 =177254, ∑𝑖=1 𝑦𝑖 = 28224, ∑𝑖=1 𝑥1𝑖 𝑦𝑖 =3595,5 2 ∑33 𝑖=1 𝑥2𝑖 𝑦𝑖 = 66678 En los tres casos, la fracción de muestreo “f” se puede despreciar, pues la población se considera infinita. Sustituyendo, se obtienen los siguientes intervalos de confianza: ∑𝑖=33(𝑦 −𝑦̅)2 ∑33 𝑦 2 −33𝑦̅ 2 28224−33(27,49)2 𝑖 a) 𝑠𝑦2 = 𝑖=1 32𝑖 = 𝑖=1 32 = = 102,68⇒ 𝑠𝑦 = 10,13 32 Intervalo del 95 % de confianza para el ingreso medio poblacional por familia “μ Y”: 27, 49 ± 1, 96 10,13 = 27, 49 ±3, 46 √33 123 b) ̅̅̅ 𝑥1 = 33 = 3,73 Intervalo del 95% de confianza para 𝑅1 = 1 7,38 ± 1,96 3,73 √33 c) ̅̅̅ 𝑥2 = 2394 33 √ = 72,55 ∑𝑁 1 𝑦𝑖 ∑𝑁 1 𝑥1𝑖 28224 −2(7,38)(3595,50)+(7,38) 2 (533) 33−1 = 7,38 ± 1.05 Muestreo Aleatorio Angel Francisco Arvelo Pag. Intervalo del 95% de confianza para 𝑅2 = 1 0,3789 ± 1,96 72,55 √33 √ 36 ∑𝑁 1 𝑦𝑖 ∑𝑁 1 𝑥2𝑖 28224 −2(0,3789)(66678)+(0,3789) 2 (177254) 33−1 = 0,3789 ± 0,0466 En conclusión, con 95% de confianza se puede afirmar que entre el 33,23% y el 42,55% de los ingresos familiares, se destinan para alimentación PREGUNTAS Y EJERCICIOS DE RECAPITULACION 1º) Suponga que para seleccionar una muestra del universo de estudiantes en su Facultad, se utiliza el siguiente procedimiento: Se consigue la lista de la totalidad de asignaturas que se dictan, y de cada asignatura se seleccionan al azar dos estudiantes. ¿Considera Ud. que la muestra resultante cumple con los requisitos para ser considerada como aleatoria simple?, y en caso de que no lo sea, sugiera un procedimiento para obtenerla. 2º) Suponga que un universo está formado por las personas {𝑎, 𝑏, 𝑐, 𝑑, 𝑒} , cuyas edades son {12,15,24,30,48} años respectivamente, y que se va a tomar una muestra aleatoria simple de 3 de ellos, a los fines de estimar la media poblacional. a) Calcule el valor de μ y de σ2, media y varianza poblacional respectivamente b) ¿Cuántas muestras diferentes es posible tomar? c) ¿Cuál es la probabilidad de seleccionar cada una de estas muestras? d) Calcule el valor de la media muestral 𝑦̅ para cada una de estas muestras posibles e) Halle el valor esperado de 𝑦̅ , y verifique que E (𝑦̅ ) = μ. ¿Cómo se llama esta propiedad? e) Calcule ahora la varianza de la media muestral, y verifique que se satisface la siguiente propiedad: Var (𝑦̅ ) = 𝜎2 𝑁−𝑛 𝑛 ( 𝑁−1 ) 3º) En un estudio electoral, se quiere estimar el porcentaje de votos que va a obtener un cierto candidato, en una determinada zona, en donde existen 30.000 viviendas. No se disponen datos acerca del número de familias extranjeras que residen en la zona (los extranjeros no votan). A pesar de esto, se decidió tomar una muestra aleatoria de 10 viviendas, encontrándose los siguientes resultados: Familia Nº Habitantes Extranjeros 1 5 2 2 8 0 3 4 0 4 5 0 5 7 2 6 8 0 7 6 0 Niños 3 2 1 2 2 3 2 Votantes 0 6 3 3 3 5 4 Votantes a favor 0 4 0 1 1 5 1 Muestreo Aleatorio Angel Francisco Arvelo Pag. 37 8 7 4 3 0 0 9 4 0 2 2 2 10 5 0 1 4 2 Obtenga intervalos del 95% de confianza para cada uno de los siguientes parámetros poblacionales: a) Porcentaje de votos a favor del candidato, calculado sobre la base de la población votante. b) Número total de habitantes en la zona. c) Porcentaje de extranjeros en la zona, calculado sobre la base de la población adulta. d) Porcentaje de familias nacionales en la zona, asumiendo que las familias nacionales son aquellas en donde no reside ningún extranjero. 4º) En un estudio de mercado, se quiere estimar el número total de personas que trabajan en una determinada zona de la ciudad, y que no poseen vivienda propia; a fin de decidir acerca de la factibilidad de desarrollar una zona residencial cercana. El número total de trabajadores en la zona se estima en 32.000, y se quiere realizar la estimación con un error no mayor de 500 personas, y con 10% de riesgo. Una muestra piloto de 200 trabajadores arrojó que 125 de ellos, no poseían vivienda propia. a) ¿Qué tamaño de muestra debe tomarse, para cumplir los requisitos establecidos? b) Si en la muestra calculada anteriormente, se encuentra que el 70% de los trabajadores no poseen vivienda propia. Construya un intervalo del 90% de confianza para la demanda que tendría este desarrollo residencial. Solución: a) n= 2402 b) 22.400 ± 473 5º) En una determinada zona residencial donde existen 2.000 viviendas, se quiere estimar el total de niños en edad escolar, a fin de establecer la capacidad mínima que ha de tener la escuela. Una muestra piloto efectuada entre 10 viviendas, dio los siguientes resultados: Niños en edad escolar 0 1 2 3 4 Frecuencia 2 4 2 1 1 Si se quiere que la estimación del total de niños en edad escolar realizada a través de un muestreo aleatorio simple, no difiera en más de 100 del verdadero valor, con un 95% de probabilidad. ¿Cuántas viviendas deben encuestarse como mínimo? Solución: n= 1106 6º) En una fábrica, se quiere estimar el total de piezas que se encuentran en un almacén. Estas piezas se encuentran dentro de cajas, que contienen un número aleatorio de piezas. En total hay 100 cajas en el almacén. Se toma una muestra aleatoria de 5 cajas, y se cuenta su contenido, clasificándolas en piezas buenas y defectuosas. Los resultados fueron: Caja Nº 1 2 3 4 5 Muestreo Aleatorio Angel Francisco Arvelo Total de piezas Piezas defectuosas Pag. 15 2 10 3 12 1 20 3 38 18 2 a) Construya un intervalo del 95% de confianza para el total de piezas almacenadas. b) Construya un intervalo del 95% de confianza para el porcentaje de piezas defectuosas. Solución: a) 1500 ± 352 b) (14.67 ± 5.24) % EJERCICIOS ESPECIALES 7º) Un investigador desea estimar la resistencia media a la compresión de un cierto material, y para tal fin, toma dos muestras de probetas de ese material, y las ensaya, examinando su resistencia. Los resultados obtenidos para cada muestra fueron: n1 = 8 y1 = 5,4 Kgs/cm2. s1= 0,6 Kgs/cm2. n2 = 15 y2 = 4,8 Kgs/cm2. s2= 0,4 Kgs/cm2. Encuentre un intervalo del 95% de confianza, de la menor amplitud posible, y que use la información contenida en las dos muestras, para la resistencia media de las probetas preparadas con ese material. Sugerencia: Deduzca fórmulas para calcular la media y la varianza de la unión de dos muestras, en función de las medias y las varianzas de cada una. 8º) Un fabricante de una nueva fibra sintética, desea estimar la diferencia en resistencia, entre su fibra con relación a la fibra natural, con un error no mayor de 10 Kgs., y 0.05 de riesgo. Mediante una muestra piloto, se sabe que la varianza en la resistencia de las fibras, es de 1636 Kgs2, para la natural, y de 1892 Kgs2, para la sintética. a) Si se utiliza como estimador de la diferencia de resistencias, a la diferencia de medias muéstrales. ¿Qué tamaño de muestra se necesita tomar, suponiendo tamaños iguales para cada tipo de cuerdas? b) Si con el tamaño de muestra calculado anteriormente, se obtuvo una resistencia media de 272 Kgs., con una desviación típica de 38 Kgs, para la fibra natural, y de 335 Kgs., con una desviación típica de 45 Kgs., para la fibra sintética. Construya un intervalo del 95% de confianza, para el incremento de resistencia dado por la fibra sintética. Solución: a) n= 136. b) (63.00 ± 9.90) Kgs. IV. MUESTREO ALEATORIO ESTRATIFICADO Cuando la población es muy heterogénea (Presenta una varianza grande), las estimaciones hechas con muestreo aleatorio simple suelen ser muy imprecisas, Muestreo Aleatorio Angel Francisco Arvelo Pag. 39 pues concluyen en un intervalo de confianza muy amplio, o requieren un tamaño de muestra demasiado grande, lo que ocasiona que el estudio hecho por esta metodología resulte extremadamente costoso. En estos casos, conviene estratificar a la población. La estratificación consiste en una partición del universo en subconjuntos llamados estratos, no necesariamente de igual tamaño, de manera que cada elemento del universo pertenezca a uno y solo a un estrato, y que además, la unión de todos ellos resulte igual al universo. Criterios para la estratificación Hay L estratos, no necesariamente de igual tamaño Cada elemento del universo pertenece a uno y solo a un estrato, es decir, la intersección entre cualquier par de estratos debe ser vacía: 𝐸𝑖 ∩ 𝐸𝑗 = ∅ La unión de todos los estratos es igual al Universo 𝐸1 ∪ 𝐸2 ⋯ ∪ 𝐸𝐿 = 𝑈𝑛𝑖𝑣𝑒𝑟𝑠𝑜 Figura N° 7: Partición del Universo en Estratos Teóricamente, la estratificación puede ser hecha por cualquier criterio que satisfaga los criterios antes señalados; pero en la práctica, si se quiere obtener una estimación precisa utilizando esta metodología, es necesario utilizar un criterio que proporcione estratos que sean muy homogéneos, es decir que la varianza dentro de cada uno de ellos sea muy pequeña. Metodología de muestreo: El principio básico que se debe respetar al tomar una muestra estratificada, es que cada muestra dentro de un mismo estrato debe ser aleatoria simple, es decir, que dentro de cada estrato, las muestras deben tomarse aplicando los principios de muestreo aleatorio simple, como si cada estrato fuese una población en sí misma. Lo anterior significa que todas las muestras posibles dentro de un mismo estrato deben tener idéntica probabilidad de ser seleccionadas, pero esto no implica que esa probabilidad sea la misma, cuando se le compara con la de otro estrato. Para tomar la muestra estratificada es necesario entonces contar con una lista numerada de los elementos de cada estrato, y realizar el sorteo aleatorio o la generación de números aleatorios ya descrita anteriormente, para configurar una muestra en cada estrato, teniendo en cuenta que el tamaño de muestra, y la fracción de muestreo para cada estrato podrá ser diferente. Al igual que el muestreo aleatorio simple, el estratificado puede ser utilizado en el caso de variables, o en el caso de atributos. Muestreo Aleatorio Angel Francisco Arvelo Pag. 40 IV.1 Muestreo estratificado para variables En este caso, la nomenclatura a seguir es la siguiente: L = Número de estratos Ni = Tamaño del estrato i, i = 1, 2,……, L N = Tamaño de población = ∑i=L i=1 Ni Wi = Ni 𝑁 = Factor de ponderación o Peso del estrato i Obviamente W 1 + W 2 + …..+ W L = 1 {𝑥𝑖1 , 𝑥𝑖2 . ⋯ , 𝑥𝑖𝑁𝑖 }= Población perteneciente al estrato i 𝑗=𝑁 𝜏𝑖 = ∑𝑗=1 𝑖 𝑥𝑖𝑗 = Total del estrato i μi = τi j=N = ∑j=1 i xij = Media del estrato i Ni Ni Ni ∑ (xij −μi )2 σ2i = 1 = Varianza del estrato i Ni 𝑖=𝐿 𝑗=𝑁𝑖 𝜏 = ∑𝑖=𝐿 𝑖=1 𝜏𝑖 = ∑𝑖=1 ∑𝑗=1 𝑥𝑖𝑗 = Total Poblacional ∑𝐿 𝜏 𝜏 ∑𝐿 𝑁 𝜇 𝜇 = 𝑁 = 1𝑁 𝑖 = 1 𝑁𝑖 𝑖 = ∑𝐿𝑖=1 𝑊𝑖 𝜇𝑖 = Media Poblacional Lo anterior significa que la Media Poblacional es la Media Ponderada entre las medias de los diferentes estratos según el peso de cada uno de ellos ni = Tamaño de muestra en el estrato i, i = 1, 2,……, L n = Tamaño total de muestra = ∑i=L i=1 ni {𝑦𝑖1 , 𝑦𝑖2 . ⋯ , 𝑦𝑖𝑛𝑖 }= Valores que cayeron en la muestra del estrato i j=n 𝑦̅= 𝑖 ∑j=1 i yij si2 = = Media muestral del estrato i ni 𝑗=n ∑j=1 i(yij −𝑦̅𝑖 )2 ni −1 = Varianza muestral del estrato i Aunque los parámetros a estimar en el muestreo estratificado pueden ser muy variados, tales como diferencia entre medias de dos estratos, o diferencia entre totales de dos estratos, aquí nos limitaremos al caso tradicional donde se quiere estimar la Media Poblacional “μ” , y/o el Total Poblacional "𝜏”, siendo sus correspondientes estimadores: 𝜇̂ = ∑𝑖=𝐿 ̅𝑖 = ̅̅̅̅̅ 𝑦 𝑠𝑡 𝑖=1 𝑊𝑖 𝑦 𝜏̂ = N ̅̅̅̅ 𝑦𝑠𝑡 ̅̅̅̅ 𝑦 conocida como “media muestral estratificada”, corresponde a la media 𝑠𝑡 ponderada entre las media muéstrales de cada estrato. Muestreo Aleatorio Angel Francisco Arvelo Pag. 41 Una vez tomada la muestra dentro de cada estrato, el intervalo de confianza para cada uno de estos dos parámetros poblacionales resulta ser: 𝑦𝑠𝑡 ± zα/2 √∑L1 ̅̅̅̅ Para μ: Para 𝜏: W2i S2i ni W2i S2i N ̅̅̅̅ 𝑦𝑠𝑡 ± N zα/2 √∑L1 ni 𝑛𝑖 (1 − 𝑁𝑖 (1 − ) ni Ni ) Ejemplo: Se quiere estimar la nómina de una organización que tiene en total 6500 empleados, pero dado que existen diferencias importantes entre sus sueldos, según sus responsabilidades, se decide estratificarlos en tres categorías: E1 obreros, E2 empleados administrativos y E3 personal profesional, donde caen 1000, 5000 y 500 personas respectivamente. Se tomó una muestra de 50 obreros, 100 empleados administrativos y 20 profesionales, encontrándose una media mensual de $1200, $ 1800 y $ 4000, con desviaciones típicas de $180, $350 y $ 250 respectivamente. En base a esta información, obtenga un intervalo del 95% de confianza para la nómina mensual. 1000 5000 500 Solución: Los pesos de cada estrato son: W 1 =6500 , W 2 =6500 , W 3 =6500 𝑦𝑠𝑡 = ̅̅̅̅ 1000 6500 (1200) + 5000 6500 (1800) + 500 6500 (4000) =1876,92 El intervalo del 95% para la nómina mensual "𝜏” es: 10 2 ( ) 6500(1876,92)±(6500)(1,96)√ 65 (180)2 50 (1 − 50 1000 )+ 50 2 ) (350)2 65 ( 100 (1 − 100 5000 )+ ( 5 2 ) (250)2 65 20 (1 − 20 500 ) = 12.200.000,00 ± 347.191,75 Criterios de estratificación y coeficiente de variación: No siempre el muestreo estratificado proporciona resultados más precisos que el aleatorio simple; depende de la manera como se realice la estratificación. En efecto, si se analiza el error estándar en la estimación de “μ” con muestreo estratificado, encontramos que este es √∑L1 muestreo aleatorio simple es s √n W2i S2i ni (1 − 𝑛𝑖 𝑁𝑖 ) ; mientras que con √1 − f Al comparar estas dos expresiones, se puede fácilmente ver que en el muestreo aleatorio simple, el error estándar depende de la varianza poblacional pues “s 2” es el estimador de σ2, mientras que en el estratificado depende de las varianzas de cada uno de los estratos. Debido a que σ2 es una constante propia de la población, lo anterior significa que con el muestreo aleatorio simple, el investigador no tiene ningún poder para reducir el error estándar salvo incrementando el tamaño de la muestra, mientras que con Muestreo Aleatorio Angel Francisco Arvelo Pag. 42 el estratificado, si se definen los estratos de manera que su variabilidad interna resulte muy pequeña, entonces a pesar de que exista una gran variabilidad en la población, la estimación resultará muy precisa. De hecho, si se lograra hacer una estratificación tan perfecta en donde todos los elementos de un mismo estrato fuesen iguales entre si y por tanto σ i2 = 0 para todos los estratos, entonces el error estándar seria 0. Si por el contrario, la estratificación se hace a través de un criterio que arroje estratos heterogéneos, y por lo tanto σ i2 resulte muy grande para cada estrato, entonces lo que se habrá logrado es un efecto contraproducente en la estimación, pues el error estándar resulta quizás tan grande como el correspondiente por muestreo aleatorio simple, a pesar del trabajo adicional que representa la estratificación. Si decide estratificar el investigador se encuentra ahora con el dilema de cómo hacerlo, pues existen varias alternativas, puede por ejemplo estratificar por regiones, estratificar por edades, estratificar por sexo, por niveles sociales, etc. A la hora de decidir cuál criterio utilizar, debe hacerse dos preguntas básicas: 1. ¿Se dispone o se puede obtener un listado que permita identificar a los elementos de cada estrato? 2. ¿Son esos estratos así definidos lo suficientemente homogéneos como para lograr una buena precisión en la estimación? Si la respuesta a la primera pregunta es negativa, entonces ese criterio de estratificación no es factible, debido a que no se podrá tomar una muestra aleatoria simple dentro de cada estrato. Si la respuesta es positiva, no necesariamente el criterio es adecuado, pues ahora debe responder la segunda pregunta, y analizar si los estratos son lo suficientemente homogéneos, como para garantizar precisión. La varianza dentro del estrato es una medida de su variabilidad, pero no basta para medir su homogeneidad, pues se trata de una cifra dimensional cuyas unidades son unidades cuadradas de la variable en estudio. Una forma mucho más efectiva para medir la homogeneidad de un estrato, es a través de su dispersión relativa o coeficiente de variación, definido por: σi C. Vi = Coeficiente de variación del Estrato “i” = 100% μi Este coeficiente tiene la ventaja de ser una cifra adimensional, libre de unidades, que compara de manera porcentual, la magnitud de la desviación estándar de un estrato con su correspondiente media. En términos generales, podría decirse que un estrato con un coeficiente de variación de hasta 10% o 15%, podría considerarse bastante homogéneo, y hasta de 30% con una variabilidad aceptable. Por supuesto, que nuevamente se presenta el ya conocido inconveniente de que ni μi , ni σi son conocidos, pues al hacer la estratificación se ignoran los parámetros con que resultaran los diferentes estratos. En este sentido, las muestras piloto representan una ayuda importante, pues ellas nos pueden advertir acerca de la bondad del criterio de estratificación utilizado. Muestreo Aleatorio Angel Francisco Arvelo Pag. 43 Es perfectamente posible que después de tomada la muestra piloto, además de corregir posibles errores en el diseño de la encuesta, se deba revisar el criterio de estratificación utilizado, pues estratos que inicialmente se creían homogéneos, en realidad no lo sean, o viceversa; y por lo tanto se deban subdividir estratos, o en otros casos fundir estratos en uno solo, según su heterogeneidad u homogeneidad respectivamente. En el ejemplo anterior, el coeficiente de variación para cada estrato resulto ser: 180 350 Obreros: 1200 ∙ 100% = 15% ; Empleados: 1800 ∙ 100% = 19,44% 250 Profesionales: 4000 ∙ 100% = 6,25 % Dado que el estrato de empleados es el de mayor peso, y a la vez el de mayor variabilidad, si la muestra tomada fuese una piloto, cabría preguntarse ¿es posible subdividir al estrato de empleados en dos nuevos estratos según algún otro criterio, como su antigüedad? Tamaño de muestra requerido: Los conceptos de error de estimación, de riesgo y de confianza se mantienen en el muestreo aleatorio estratificado, y por lo tanto, el error absoluto en la estimación de la media poblacional es: |̅̅̅̅ 𝑦𝑠𝑡 - μ| ≤ ε Mientras que 1-α = Confianza = Probabilidad (|̅̅̅̅ 𝑦𝑠𝑡 - μ| ≤ ε) Sin embargo, el cálculo del tamaño de muestra puede complicarse por que es necesario calcular el correspondiente para cada estrato. Es importante aclarar que cuando se fija un máximo error tolerado para el parámetro poblacional, este mismo máximo error tolerado no aplica para cada estrato individualmente; en otras palabras, exigir un error máximo tolerado de por ejemplo 2% para media poblacional no implica estimar la media de cada estrato con ese mismo 2% de error, pues perfectamente puede suceder que un estrato tenga un peso muy bajo dentro de la población, y un error grande en la estimación de su media no influya de manera significativa dentro de estimación poblacional. Por lo anteriormente explicado, el tamaño de muestra para cada estrato no puede ser calculado a través de las fórmulas de las secciones precedentes, como si cada estrato fuese una población aislada en sí misma. La manera como la muestra se reparte entre los diferentes estratos, se denomina la asignación, y existen varios criterios para realizarla: Asignación proporcional Asignación de Neyman Asignación óptima Aquellos lectores que deseen profundizar más sobre este asunto deben consultar el excelente texto: "Técnicas de Muestreo" de William G. Cochran. En este humilde resumen, nos vamos a limitar exclusivamente al criterio de asignación proporcional, que a pesar de no ser el mejor en todos los casos, resulta ser el más intuitivo, y sobre todo el más fácil de defender a la hora de presentar un estudio por muestreo. Se dice que la asignación es proporcional, cuando a cada estrato le corresponde la misma porción de muestra que lo que ese estrato representa en la población. Muestreo Aleatorio Angel Francisco Arvelo Pag. 44 Así por ejemplo, si un estrato representa el 20% de la población, con asignación proporcional, a ese estrato le corresponde el 20% de la muestra. En el ejemplo recién analizado sobre la nómina de la empresa, fácilmente se puede ver que la asignación no es proporcional. Para una asignación proporcional se verifica: ni n = Ni N = Wi ⇒ ni = Wi n De manera, que una vez calculado el tamaño de muestra “n”, lo que le corresponde a cada estrato se calcula según su parte proporcional. Para un error absoluto tolerado “ε” y un riesgo “α”, el tamaño total de muestra necesario para estimar a la media poblacional “μ”, con asignación proporcional, puede ser calculado con la siguiente fórmula: n= 2 ∑L1 Wi σ2i Nzα/2 2 ∑L1 Wi σ2i + N ε2 zα/2 Al igual que en las secciones precedentes, el desconocimiento de las varianzas de cada estrato σi2 , hace que se necesiten muestras piloto, con el objeto de obtener una estimación preliminar de cada una de ellas, y también una estimación de “μ”, en caso de que el error “ε” se fije de manera relativa. Por lo general, la muestra piloto se reparte de manera proporcional, y es posible que se deban reformular los estratos, en caso de que algunos de ellos resulten con un coeficiente de variación alto. Ejemplo: Se desea estimar el consumo total de agua en una determinada zona de la ciudad, en donde existen 200 industrias y 10.000 residencias. Una muestra piloto entre 5 industrias dio: Consumo (Litros) Frecuencia 0 - 1000 1 1000-2000 1 2000-3000 2 3000-4000 1 Una muestra piloto entre 20 residencias arrojó: Consumo (Litros) Frecuencia 0 - 500 4 500-1000 6 1000-1500 7 1500-2000 3 a) ¿Qué tamaño total de muestra se requiere, si se quiere un error relativo de estimación del 5 % como máximo, con un riesgo también del 5%? b) Si en esa muestra se obtiene un consumo medio de 2000 litros para las industrias, con una desviación típica de 1400; y de 750 litros con una desviación típica de 200 litros para las residencias. Obtenga un intervalo del 95% de confianza para el consumo total de agua. Muestreo Aleatorio Angel Francisco Arvelo Pag. 45 Solución: En primer lugar, hay que calcular la media y la desviación estándar de cada estrato, según lo obtenido en la muestra piloto. y 975,00 y 2100,00 Industrias: 1 Residencias 2 s2 499,34 s1 1140,18 Al analizar el resultado de la muestra piloto, se encuentra que el coeficiente de variación para cada estrato es relativamente alto 54,29% para las industrias, y 51,21% para las residencias, lo que sugiere una reformulación de los estratos, y a preguntarnos si es posible subdividirlos, y considerar si es posible por ejemplo distinguir varios tipos de industrias, y varios tipos de residencias, como por ejemplo, quintas y apartamentos. Suponiendo que decide seguir adelante con estos dos estratos, para calcular el tamaño de muestra se necesita ahora fijar el error absoluto tolerado, para lo que se debe hacer una estimación preliminar de “μ”, a partir de la muestra piloto: 200 10000 𝜇̂ = 10200 (2100) + 10200 (975) = 997,06 ⟹ ε = 5% de 997,06 = 49,85 200 y por consiguiente: n = 10000 10200 (1,96)2 (102001140,182 + 10200499,342 ) 200 1140,182 10200 (1,96)2 ( 10000 + 10200499,342 )+10200(49,85)2 = 401 la cual deberá ser repartida proporcionalmente entre los dos estratos 200 10000 𝑛1 = 10200 401 ≈ 8 industrias; mientras que: 𝑛2 = 10200 401 ≈ 393 residencias b) Al suponer que en esa muestra se obtuvo: y 2000 y 750 Industrias: 1 Residencias 2 s1 1400 s2 200 200 10000 𝜇̂ =𝑦 ̅̅̅̅ 𝑠𝑡 =10200 (2000) + 10200 (750) = 774,51 litros El intervalo del 95% de confianza para μ es: 774,51 ± 1,96 √ ( 200 2 ) (1400)2 10200 8 (1 − 8 200 )+ ( 10000 2 ) (200)2 10200 393 (1 − 393 10000 )= 27,15 774,71 ± 27,15; lo que representa un error relativo de 774,71 100% = 3,50% La estimación de 𝜏 = Consumo total de agua en la zona, es 10200 (774,71 ± 27,15)= (7.902.042 ± 276.930) litros en total, con 95% de confianza IV.2 Muestreo estratificado por atributos Al igual que en el muestreo aleatorio simple, lo que se quiere estimar en un muestreo por atributos es la proporción y / o el total de elementos, que dentro de una población posee un cierto atributo, con la diferencia de ahora la población va a ser subdividida en estratos. Muestreo Aleatorio Angel Francisco Arvelo Pag. 46 Ya hemos visto que en este caso, la población solo contiene unos y ceros, según el elemento posea o no posea el atributo respectivamente. La nomenclatura a seguir es la siguiente: L = Número de estratos Ni = Tamaño del estrato i, i = 1, 2,……, L N = Tamaño de población = ∑i=L i=1 Ni Wi = Ni 𝑁 = Factor de ponderación o Peso del estrato i Obviamente W 1 + W 2 + …..+ W L = 1 {𝑥𝑖1 , 𝑥𝑖2 . ⋯ , 𝑥𝑖𝑁𝑖 }= Población perteneciente al estrato i 𝑥𝑖𝑗 = 0 o 1 𝑗=𝑁 𝜏𝑖 = ∑𝑗=1 𝑖 𝑥𝑖𝑗 = Total de elementos con el atributo en el estrato i πi = 𝜏= τi j=N = ∑j=1 i xij Ni Ni 𝑖=𝐿 ∑𝑖=1 𝜏𝑖 = ∑𝐿 𝜏 𝜏 = Proporción de elementos con el atributo en el estrato i 𝑗=𝑁𝑖 ∑𝑖=𝐿 𝑖=1 ∑𝑗=1 𝑥𝑖𝑗 = Total Poblacional ∑𝐿 𝑁 𝜋 𝜋 = 𝑁 = 1𝑁 𝑖 = 1 𝑁𝑖 𝑖 = ∑𝐿𝑖=1 𝑊𝑖 𝜋𝑖 = Proporción Poblacional Lo anterior significa que la Proporción Poblacional es la Media Ponderada entre las proporciones de los diferentes estratos según el peso de cada uno de ellos ni = Tamaño de muestra en el estrato i, i = 1, 2,……, L n = Tamaño total de muestra = ∑i=L i=1 ni {𝑦𝑖1 , 𝑦𝑖2 . ⋯ , 𝑦𝑖𝑛𝑖 }= Valores que cayeron en la muestra del estrato i; 𝑦𝑖𝑗 = 0 o 1 j=n pi= fi = ∑j=1 i yij ni 𝑁𝑖 ni = Proporción muestral del estrato i = Fracción de muestreo en el estrato i Los parámetros a estimar son π y 𝜏 , cuyos estimadores son: 𝜋̂ = pst = ∑𝐿𝑖=1 𝑊𝑖 𝑝𝑖 ; 𝜏̂ =N pst = N ∑𝐿𝑖=1 𝑊𝑖 𝑝𝑖 = ∑𝐿𝑖=1 𝑁𝑖 𝑝𝑖 Muestreo Aleatorio Angel Francisco Arvelo Pag. 47 El intervalo de confianza para cada uno de ellos es: Para π : pst ± 𝑧𝛼/2 √∑𝐿𝑖 𝑊𝑖2 𝑝𝑖 (1−𝑝𝑖 ) Para 𝜏 : N pst ± 𝑧𝛼/2 √∑𝐿𝑖 𝑛𝑖 −1 (1 − 𝑓𝑖 ) 𝑁𝑖2 𝑝𝑖 (1−𝑝𝑖 ) 𝑛𝑖 −1 (1 − 𝑓𝑖 ) Ejemplo: En un estudio de mercado se quiere estimar la proporción de consumidores que prefiere una determinada marca de consumo masivo. Se decidió estratificar por sexo, pues se piensa que existe una diferencia significativa entre las proporciones de hombres y mujeres que prefieren dicha marca. Dado que el universo de consumidores es muy grande, la población se puede considerar infinita, y que está repartida por igual entre hombre y mujeres. Una muestra aleatoria de 500 hombres y de 500 mujeres, arrojó que 80 y 360 respectivamente, preferían la marca. Obtenga un intervalo del 95% para la proporción poblacional. Solución: Por tratarse de una población infinita, las fracciones de muestreo fi se pueden considerar nulas, y además se tiene W 1=W 2= 0,50= ½ 80 360 Para los hombres: p1 = 500 = 0,16; Para los mujeres: p2 = 500 = 0,72 En consecuencia 𝜋̂ = pst = ½ (0,16) + ½ (0,72) = 0,44 = 44% El intervalo del 95% para la proporción poblacional "𝜋” es: 1 2 ( ) 0,44 ± (1,96)√ 2 (0,16)(1−0,16) 500−1 + 1 2 2 ( ) (072)(1−0,72) 500−1 = 0.4400 ± 0.0254 = 44.00% ± 2.54% Criterios de estratificación y coeficiente de variación: Al igual que en el muestreo estratificado por variables, en el caso de atributos, el investigador debe ser muy cuidadoso al momento de definir los estratos, pues no siempre, la estratificación conduce a intervalos de confianza más estrechos que los que se obtendrían por muestreo aleatorio simple. La estratificación debe ser hecha de manera que los estratos resultantes sean homogéneos; en el caso de variables, esta homogeneidad se mide a través del coeficiente de variación, pero en el caso de atributos no es así. En efecto, al observar el error estándar del estimador “pst” se observa que este es √∑𝐿𝑖 𝑊𝑖2 𝑝𝑖 (1−𝑝𝑖 ) 𝑛𝑖 −1 (1 − 𝑓𝑖 ) el cual se ve obviamente afectado por el valor del producto pi (1-pi) para cada estrato, y resulta ser que este producto alcanza su valor máximo cuando pi = ½ De lo anterior se deduce que si la estratificación es tal que el atributo en cuestión divide a cada estrato en dos mitades iguales, mitad que lo tiene y mitad que no lo tiene, entonces se habrá hecho una pésima estratificación, pues el error estándar alcanzará su valor máximo, y el intervalo de confianza resultará muy amplio. Muestreo Aleatorio Angel Francisco Arvelo Pag. 48 Por el contrario, cuando pi este cercano a 0 ó cercano a 1, en cualquiera de estos dos casos, el producto pi (1-pi) resultara próximo a cero, y en consecuencia el error estándar será muy pequeño. De allí se deduce la siguiente regla para hacer la estratificación: Los estratos deben ser definidos de manera tal que el atributo en cuestión sea muy raro o muy frecuente dentro de cada estrato. Por supuesto que al hacer la estratificación no se sabe de antemano si esta regla se cumplirá, y de allí la importancia de las muestras piloto que permitan redefinir aquellos estratos que no la cumplan. Resulta difícil decir con exactitud cuándo se puede considerar a un estrato homogéneo y cuando no; pero en términos generales, un estrato que en la muestra piloto tenga pi ≤0,10 o pi ≥0,90 podría decirse que es muy homogéneo, mientras que otro que resulte con 0,35 ≤ pi ≤ 0,65 es bastante heterogéneo, y debería plantearse una subdivisión en él. Tamaño de muestra requerido: Tan pronto como se tengan las estimaciones preliminares de cada una de las proporciones de cada estrato πi, mediante las correspondientes proporciones muéstrales obtenidas en la muestra piloto, y una vez fijado el error máximo absoluto tolerado en la estimación de π, es decir |̅̅̅̅ 𝑝𝑠𝑡 - π| ≤ ε, y el riesgo α = Probabilidad (|̅̅̅̅ 𝑝𝑠𝑡 - π| > ε) , el tamaño de muestra de la muestra definitiva, suponiendo asignación proporcional puede ser calculado mediante la expresión siguiente En poblaciones finitas: n= 2 ∑L1 Wi 𝜋𝑖 (1 − 𝜋𝑖 ) Nzα/2 2 ∑L1 Wi 𝜋𝑖 (1 − 𝜋𝑖 ) + N ε2 zα/2 En poblaciones infinitas: z2α/2 ∑L1 Wi 𝜋𝑖 (1 − 𝜋𝑖 ) 𝑛∞ = ε2 Muestreo Aleatorio Angel Francisco Arvelo Pag. 49 En caso de que el investigador considere que no es conveniente tomar una muestra piloto para obtener una estimación preliminar de cada uno de los π i, le quedan las siguientes dos opciones: a) Tomar la muestra máxima dada por: 𝑛𝑚𝑎𝑥𝑖𝑚𝑎 = z2α/2 Nz2α/2 z2α/2 +4 N ε2 para poblaciones finitas, o 𝑛∞,𝑚𝑎𝑥𝑖𝑚𝑎 = 4 ε2 para poblaciones infinitas, y luego repartirla proporcionalmente dentro de los estratos. Este procedimiento puede resultar extremadamente costoso, pues conduce a una muestra mucho más grande de la necesaria, ya que equivale a realizar el cálculo del tamaño de muestra desde el punto de vista más pesimista posible, que es suponer que cada πi = ½, lo que significa que la estratificación ha sido muy mal hecha. b) Basarse en encuestas anteriores, en estudios similares o en opinión de expertos para establecer un posible intervalo en donde se considere puede encontrarse cada uno de los πi, y tomar como valor de πi para ser sustituido dentro de la fórmula del tamaño de muestra, aquel valor que dentro del intervalo se encuentre más cercano a ½, o igual a ½ si lo contiene. Lo negativo de esta metodología es que puede conducir a tamaños de muestra insuficientes, debido a que el intervalo de predicción antes señalado puede resultar erróneo. Ejemplo: En un estudio que considera dos estratos, se quiere estimar la proporción "π" de elementos que en la población posee una cierta característica. El primer estrato representa el 75% de la población, y el segundo estrato el 25% restante. Se quiere que la estimación de “π” a través de la proporción muestral estratificada (pst) no difiera de "π", en más de 1%, con 90% de probabilidad. a) SI la asignación de la muestra se va a realizar proporcionalmente. Calcule el tamaño de muestra necesario en cada estrato, sabiendo que una muestra preliminar arrojó que el 20% en el primer estrato, y el 45% en el segundo estrato, posee la característica. (Suponga que la población es grande, y que por lo tanto, se puede despreciar la fracción de muestreo). b) Si con el tamaño de muestra calculado anteriormente, se encuentra que el 25% en el primer estrato, y el 38% en el segundo, posee la característica. Construya un intervalo del 90% de confianza para la "Proporción Poblacional". Solución: El hecho de encontrar en la muestra piloto del 2º estrato un 45% de elementos con el atributo, sugiere que este estrato resultó heterogéneo, y que debería subdividirse a fin de lograr una mayor homogeneidad. De no ser factible esta corrección, el cálculo del tamaño de muestra es: 𝑛∞ = z2α/2 ∑L1 Wi𝜋𝑖 (1−𝜋𝑖 ) ε2 = (1,645)2 (0,75 (0,20)(1−0,20)+(0,25 (0,45)(1−0,45)) (0,01)2 = 4922 Muestreo Aleatorio Angel Francisco Arvelo Pag. 50 Al repartir proporcionalmente este tamaño total de muestra, entre los dos estratos, n 0,75(4922) 3692 se obtiene: 1 n2 0,25(4922) 1231 La estimación puntual de “π” es: π ̂ = pst = 0,75(0,25) + 0,25(0,38) = 0,2825 y el intervalo del 90% de confianza para “π”: 0,2825 ± 1,645 √ (0,75) 2 (0,25)(1−0,25) 3692−1 + (0,25) 2 (038)(1−0,38) 1231−1 = 0,2825 ± 0,0105 = 28,25 % ± 1.05 % EJERCICIOS POPUESTOS 1°) Una industria tiene dos máquinas, que trabajan en paralelo para producir un mismo artículo. Las características de estas máquinas son: Máquina 1: Es una máquina moderna, cuya velocidad de producción es el triple de la otra, y que según una muestra piloto, produce apenas un 1% de defectuosas. Máquina 2: Es una máquina antigua, cuya velocidad de producción es la tercera parte de la otra, y que según una muestra piloto, produce un 8% de defectuosas. Se quiere estimar el porcentaje de piezas defectuosas dentro de la producción total, con un error no mayor al 0.5%, y un 5% de riesgo. Calcule con ese tamaño de muestra, se obtiene un 0.8% de defectuosas en la máquina 1, y un 8.6 % de defectuosas en la máquina 2, establezca un intervalo del 95 % de confianza, para el porcentaje de defectuosos producidos por la industria. 2°) Se tiene un lote de 60.000 bombillos, de los cuales 40.000 son de una marca “A” y 20.000 de otra marca “B”. Se quiere estimar la duración media de los bombillos del lote, con un error no mayor al 2,5% y 5% de riesgo. Una muestra piloto de ambas marcas, arrojó los siguientes resultados: Duración (hrs) 0 a 100 100 a 200 200 a 300 300 a 400 400 a 500 Marca “A” 2 8 25 31 14 Marca “B” 6 24 10 5 0 a) Con asignación proporcional, calcule el tamaño de muestra necesario para cada marca b) Suponga que con el tamaño de muestra calculado en a.3, se obtienen los siguientes resultados: Media Muestral (hrs) Desviación estándar (hrs) Marca “A” 320 90 Marca “B” 170 50 Obtenga un intervalo del 95% de confianza para la duración media de los bombillos del lote. Muestreo Aleatorio Angel Francisco Arvelo Pag. 51 3°) En una población con 100.000 elementos, se quiere estimar el total poblacional, a través de un muestreo estratificado, que considera dos estratos que representan el 35% y 65%. Una muestra piloto arrojó las siguientes estimaciones preliminares: Estrato 1 Estrato 2 Media 80 220 Desviación típica 21 30 a) Calcule el tamaño de muestra para cada estrato, utilizando asignación proporcional, y se quiere un error no mayor al 3%, con 5% de riesgo b) Suponga que con los tamaños de muestra calculados, se obtiene: Estrato 1 Estrato 2 Media 85 208 Desviación típica 20 25 Obtenga un intervalo del 95% de confianza para el total poblacional.
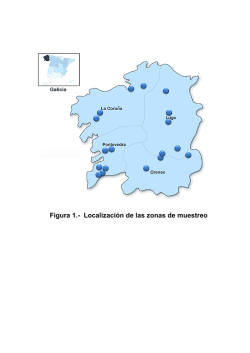

© Copyright 2026