
DHIS2 Guía de Implementación
DHIS2 Guía de Implementación
2.15
© 2006-2014
Equipo de Documentación DHIS2
1181
Version 2.15 2014-10-18 14:00:34
Garantía: ESTE DOCUMENTO HA SIDO FACILITADO POR LOS AUTORES EN EL ESTADO
EN QUE SE ENCUENTRA Y SE RENUNCIARÁ RECURRIR A CUALQUIER TIPO DE
GARANTÍA IMPLÍCITA O EXPLÍCITA, INCLUYENDO DE FORMA NO LIMITANTE LAS
GARANTÍAS IMPLÍCITAS DE COMERCIALIZACIÓN E IDONEIDAD PARA PROPÓSITOS
PARTICULARES. EN NINGÚN CASO LOS AUTORES O COLABORADORES ASUMIRÁN
RESPONSABILIDADES POR DAÑO ALGUNO DIRECTO, INDIRECTO, FORTUITO,
ESPECIAL, EJEMPLAR O CONSIGUIENTE (INCLUIDOS, PERO NO RESTRINGIDOS A, LA
ADQUISICIÓN DE BIENES O SERVICIOS SUSTITUTIVOS; PÉRDIDA DE USO, DATOS O
BENEFICIOS; O INTERRUPCIÓN DE LA ACTIVIDAD) PRODUCIDO EN MODO ALGUNO NI
POR NINGUNA VINCULACIÓN EXIGIBLE, YA SEA POR CONTRATO, RESPONSABILIDAD
ESTRICTA, O AGRAVIO (INCLUIDA NEGLIGENCIA O DE OTRO TIPO) QUE PUEDAN
SURGIR EN MODO ALGUNO DE LA UTILIZACIÓN DE ESTE MANUAL Y DE LOS
PRODUCTOS EN ÉL MENCIONADOS, INCLUSO SI EXISTE ADVERTENCIA PREVIA SOBRE
LA POSIBILIDAD DE TALES DAÑOS.
Licencia: Se garantiza el permiso para copiar, distribuir y/o modificar este documento bajo los
términos de la Licencia de Documentación Libre de GNU, Versión 1.3 o cualquier versión posterior
publicada por la Free Software Foundation; sin Secciones Invariables ("Invariant Sections"), sin
Textos de Portada ("Front-Cover Texts") y sin Textos de Contraportada ("Back-Cover Texts"). Las
fuentes de esta documentación incluyen una copia de la licencia, que también está disponible online:
http://www.gnu.org/licenses/fdl.html.
ii
DHIS2 Guía de Implementación
Contents
1. Recomendaciones para implementaciones nacionales de SIS .................................................................... 1
1.1. Desarrollo de bases de datos ................................................................................................... 1
1.2. Importar y mapear bases de datos existentes .............................................................................. 1
1.3. Asegurar los recursos necesarios para la implementación .............................................................. 1
1.4. Integración de sistemas paralelos ............................................................................................. 1
1.5. Establecer un servidor nacional online y fiable ........................................................................... 2
1.6. Fase piloto ........................................................................................................................... 2
1.7. Lanzamiento ......................................................................................................................... 2
1.8. Formación ............................................................................................................................ 3
1.9. Descentralización de la gestión y la captura de datos ................................................................... 3
1.10. Revisión y extensión ............................................................................................................ 4
2. Principios conceptuales de diseño ....................................................................................................... 5
2.1. Todos los metadatos pueden añadirse y modificarse a través del interfaz de usuario ........................... 5
2.2. Un modelo de datos flexible soporta que diferentes fuentes de datos puedan ser integradas en un
único repositorio de datos ............................................................................................................. 5
2.3. Entrada de datos != Salida de datos .......................................................................................... 6
2.4. Análisis de datos y reportes basados en indicadores ..................................................................... 7
2.5. Mantener los datos de establecimientos desagregados en la base de datos ........................................ 8
2.6. Soporte de análisis de datos a cualquier nivel del sistema de salud ................................................. 8
3. Instalación de una nueva base de datos ................................................................................................ 9
3.1. Estrategias para empezar ........................................................................................................ 9
3.2. ¿Un proceso controlado o un proceso abierto? ............................................................................ 9
3.3. Pasos para elaborar una base de datos ..................................................................................... 10
3.3.1. Jerarquía organizativa ................................................................................................ 10
3.3.2. Elementos de datos .................................................................................................... 10
3.3.3. Sets de datos y formularios de entrada de datos .............................................................. 10
3.3.4. Reglas de validación .................................................................................................. 11
3.3.5. Indicadores ............................................................................................................... 11
3.3.6. Tablas de reporte e informes ....................................................................................... 12
3.3.7. SIG (Mapas) ............................................................................................................. 12
3.3.8. Gráficas y dashboard ................................................................................................. 12
4. Estrategias de despliegue ................................................................................................................. 13
4.1. Despliegue Desconectado (Offline) ......................................................................................... 13
4.2. Despliegue Conectado (Online) .............................................................................................. 13
4.3. Despliegue Híbrido .............................................................................................................. 14
4.4. Alojamiento de servidor ........................................................................................................ 15
5. DHIS 2 es un Data Warehouse ......................................................................................................... 17
5.1. Data warehouse frente a sistemas funcionales ........................................................................... 17
5.2. Estrategia de agregación en DHIS 2 ........................................................................................ 18
5.3. La propuesta de almacenamiento de datos ................................................................................ 19
6. Capacitación de usuarios ................................................................................................................. 21
6.1. Qué capacitación se necesita .................................................................................................. 21
6.2. Estrategias de capacitación .................................................................................................... 21
6.2.1. Formación de formadores ........................................................................................... 21
6.2.2. Workshops y formación in-situ .................................................................................... 21
6.2.3. Formación continua ................................................................................................... 22
6.3. Materiales y cursos .............................................................................................................. 22
7. Integración .................................................................................................................................... 23
7.1. Integración e interoperabilidad ............................................................................................... 23
7.2. Beneficios de la integración ................................................................................................... 23
7.3. Qué facilita la integración y la interoperabilidad ........................................................................ 24
7.4. Arquitectura de SIS interoperables .......................................................................................... 24
8. Instalación ..................................................................................................................................... 27
8.1. Montaje del servidor ............................................................................................................ 27
8.2. Configuración de proxy inverso ............................................................................................. 30
8.2.1. Instalación básica de nginx ......................................................................................... 30
8.2.2. Habilitando SSL en nginx ........................................................................................... 31
iii
DHIS2 Guía de Implementación
Contents
8.2.3. Scripts de control para nginx ....................................................................................... 32
8.2.4. Colocar recursos disponibles con nginx ......................................................................... 33
8.2.5. Configuración básica de proxy inverso con Apache ......................................................... 34
8.2.6. Balanceo de carga básico con Apache y Tomcat ............................................................. 34
8.2.7. Encriptado básico SSL con Apache .............................................................................. 35
8.3. Instalación de DHIS 2 Live ................................................................................................... 36
8.4. Copias de seguridad (Backup) ................................................................................................ 37
8.5. Trabajando con la base de datos PostgreSQL ............................................................................ 37
8.6. Usando los Servicios Web Amazon ........................................................................................ 37
9. Soporte ......................................................................................................................................... 41
9.1. Página principal: dhis2.org .................................................................................................... 41
9.2. Plataforma colaborativa: launchpad.net/dhis2 ............................................................................ 41
10. Unidades Organizativas ................................................................................................................. 43
10.1. Diseño de la jerarquía de unidades organizativas ..................................................................... 43
10.2. Grupos de unidades organizativas y sets de grupos ................................................................... 44
11. Elementos de datos y dimensiones personalizados .............................................................................. 47
11.1. Elementos de datos ............................................................................................................. 47
11.2. Categorías y dimensiones personalizadas ................................................................................ 47
11.3. Grupos de elementos de datos .............................................................................................. 48
12. Sets de datos y formularios ............................................................................................................ 49
12.1. ¿Qué es un set de datos? ..................................................................................................... 49
12.2. ¿Qué es un formulario de entrada de datos? ............................................................................ 49
12.2.1. Tipos de formularios de entrada de datos ..................................................................... 49
12.2.1.1. Formularios por defecto ................................................................................. 49
12.2.1.2. Formularios de Sección .................................................................................. 50
12.2.1.3. Formularios personalizados ............................................................................. 50
12.3. Lecciones aprendidas: de los formularios en papel a los formularios electrónicos ........................... 50
12.3.1. Identificar elementos de datos autónomos .................................................................... 50
12.3.2. Dejar los cálculos y las repeticiones a la computadora: capturar solo datos en bruto .............. 51
13. Calidad de los datos ...................................................................................................................... 53
13.1. Cómo medir la calidad de los datos ....................................................................................... 53
13.2. Causas de una baja calidad de datos ...................................................................................... 53
13.3. Cómo mejorar la calidad de los datos .................................................................................... 53
13.4. Cómo utilizar DHIS 2 para mejorar la calidad de los datos ........................................................ 53
13.4.1. Validación en la introducción de datos ........................................................................ 54
13.4.2. Rangos Máximo y Mínimo ........................................................................................ 54
13.4.3. Reglas de validación ................................................................................................ 54
13.4.4. Análisis de outliers (valores atípicos) .......................................................................... 54
13.4.5. Reportes de integridad y de puntualidad ...................................................................... 54
14. Indicadores .................................................................................................................................. 55
14.1. Qué es un indicador ........................................................................................................... 55
14.2. El propósito de los indicadores ............................................................................................. 55
14.3. Recolección de datos por indicadores .................................................................................... 55
14.4. Gestión de indicadores ........................................................................................................ 56
15. Los usuarios y sus roles ................................................................................................................ 57
15.1. Usuarios ........................................................................................................................... 57
15.2. Roles de usuario ................................................................................................................ 57
16. Una perspectiva general de las herramientas de análisis de datos ........................................................... 59
16.1. Herramientas de análisis de datos ......................................................................................... 59
16.1.1. Reportes estándar .................................................................................................... 59
16.1.2. Reportes de sets de datos .......................................................................................... 59
16.1.3. Reportes de completitud de datos ............................................................................... 59
16.1.4. Reportes estáticos .................................................................................................... 59
16.1.5. Reportes de distribución de unidades organizativas ........................................................ 60
16.1.6. Tablas de reporte ..................................................................................................... 60
16.1.7. Gráficas ................................................................................................................. 60
16.1.8. Tablas Web dinámicas .............................................................................................. 60
iv
DHIS2 Guía de Implementación
Contents
16.1.9. SIG ....................................................................................................................... 60
16.1.10. Tablas My Datamart y tablas dinámicas Excel ............................................................ 60
17. Tablas dinámicas y la herramienta MyDatamart ................................................................................. 63
17.1. Diseño de tablas dinámicas .................................................................................................. 63
17.2. Conectando con la base de datos de DHIS 2 ........................................................................... 64
17.3. Manejando grandes cantidades de datos ................................................................................. 64
17.4. La herramienta MyDatamart ................................................................................................ 65
17.5. Utilizando tablas dinámicas Excel y MyDatamart - un ejemplo práctico ....................................... 66
17.5.1. Descargar y lanzar la herramienta MyDatamart por primera vez ....................................... 66
17.5.2. Crear y distribuir las tablas dinámicas ......................................................................... 66
17.5.3. Actualizar MyDatamart ............................................................................................. 66
17.5.4. Actualizar las tablas dinámicas ................................................................................... 66
17.5.5. Repetimos los pasos 3 y 4 cuando haya nuevos datos disponibles en el servidor central ......... 67
18. DHIS como plataforma .................................................................................................................. 69
18.1. Portales Web ..................................................................................................................... 70
18.2. Aplicaciones (Apps) ........................................................................................................... 71
18.3. Sistemas de Información ..................................................................................................... 71
19. Conceptos para la adaptación local .................................................................................................. 73
19.1. Utilizando el servidor de traducción DHIS2 ............................................................................ 73
19.2. Herramienta DHIS2 i18n ..................................................................................................... 74
19.3. Detalles a tener en mente .................................................................................................... 75
(2.15)
v
Recomendaciones para implementaciones
nacionales de SIS
Desarrollo de bases de datos
Capítulo 1. Recomendaciones para
implementaciones nacionales de SIS
Este texto pretende ofrecer una breve introducción a algunos de los aspectos clave en la implementación de Sistemas de
Información de Salud (SIS) recogidas por HISP a lo largo de numerosos proyectos en países en desarrollo. Los diversos
aspectos aquí mencionados pueden utilizarse como aportaciones para planificar nuevos esfuerzos de implementación
así como para la evaluación de procesos en curso.
1.1. Desarrollo de bases de datos
Cuando desarrollamos una nueva base de datos, la manera natural de empezar es definir los elementos de datos para los
cuales registrar datos y diseñar los formularios de entrada de datos. Los elementos de datos son los bloques centrales
de la base de datos y deben ser razonablemente estables antes de avanzar más en la implementación. El siguiente paso
sería definir las reglas de validación basadas en los elementos de datos mencionados para ser capaces de garantizar de
mejor manera la corrección de los datos que se están registrando.
Otro componente fundamental de la base de datos es la jerarquía organizativa que debe ser identificada y configurada en
una fase inicial. Los establecimientos de salud son generalmente la fuente de la información y la jerarquía organizativa
ordena los establecimientos tanto en la dimensión geográfica como administrativa. En la mayoría de países no hay
un registro máster definido estrictamente y actualizado permanentemente para los establecimientos de salud, de modo
que este proceso necesita involucrar a los diversos actores, inluido el nivel distrital, dado que son ellos los que mejor
conocen la situación.
1.2. Importar y mapear bases de datos existentes
Traer datos existentes al nuevo sistema añade un importante valor en las fases iniciales, ya que facilita enormemente la
exhibición de las capacidades de análisis de DHIS2 como son las gráficas y los reportes. Esto mejora nuestra capacidad
para convencer a actores clave como los programas de salud y los donantes para que apoyen el nuevo sistema. En la
mayoría de los casos existe una gran cantidad de datos almacenados electrónicamente de sistemas de bases de datos
internos, hojas de cálculo u otros sistemas de terceros. Siempre que sea posible, estos datos deberían importarse y
mapearse en elementos de datos y en unidades organizativas (ubicaciones, establecimiensos de salud) en el nuevo
sistema siguiendo cualquier solución técnica viable. Este proceso ha de realizarse una única vez para poner la base de
datos a punto y no debería convertirse en une rutina repetitiva.
1.3. Asegurar los recursos necesarios para la implementación
Realizar un lanzamiento nacional es un esfuerzo costoso que requiere financiación apropiada para los aspectos aquí
mencionados, incluyendo la compra de hardware, alojamiento en servidores, workshops y formación interna y externa.
La financiación puede venir del presupuesto gubernamental y/o de donantes externos. En todo caso es vital que incluso
cantidades pequeñas necesarias por ejemplo para la tarifa de conexión a Internet sean presupuestadas y gestionadas
para evitar así frustraciones y problemas innecesarios a los usuarios finales.
1.4. Integración de sistemas paralelos
La esfera gubernamental típica en salud tiene muchos actores y sistemas pre-existentes. En primer lugar, está claro que
una base de datos integrada que contenga datos de varias fuentes se vuelve mucho más valiosa y útil que una con datos
aislados y fragmentados. Por ejemplo, mejora su utilidad cuando el análisis de datos epidemiológicos se combina con
datos especializados de VIH/SIDA, TB, recursos humanos y financieros, o cuando la inmunización se combina con
datos de logística y stock, ya que nos ofrece un cuadro más completo de la situación. En segundo lugar, hay típicamente
muchos elementos de datos solapados que están siendo capturados en los diferentes sistemas paralelos. Por ejemplo, los
1
Recomendaciones para implementaciones
nacionales de SIS
Establecer un servidor nacional online y
fiable
elementos de datos relativos a VIH/SIDA son capturados por múltiples programas generales de conciliamiento y test
y también por el programa específico de VIH/SIDA, o los elementos de datos relativos a malaria durante el embarazo
son registrados tanto por el programa de salud reproductiva como por el programa de malaria. Si armonizamos las
herramientas de recogida y registro de datos de estos programas reduciremos la carga de trabajo total de los usuarios
finales. Esto implica que estas fuentes de datos estén integradas en el sistema nacional de información y armonizadas
con los elementos de datos existentes, que incluye requisitos tanto de entrada de datos como de análisis de datos y
exige un sistema software de información que sea flexible y escalable. Por tanto, es importante que las discusiones y
el trabajo individual se realicen junto a todos los actores relevantes incluidos todos los programas de salud.
1.5. Establecer un servidor nacional online y fiable
Dado que el desarrollo tecnológico avanza, muchos países disponen ya de red celular y cobertura para buena parte de
los distritos. La utilización de sistemas de información en red que pueden ser accedidos a través de Internet (también
conocidos como "cloud computing") unido a modems de Internet que usan la red celular es un gran acercamiento
a la rápida escalabilidad. Esto requiere tener un servidor online fiable a nivel nacional. El enfoque recomendado
consiste en conseguir servicios de alojamiento en proveedores externos (como Linode o Amazon) que libera al gobierno
de proporcionar acciones necesarias como soluciones de back-up eléctrico, copias de seguridad y respaldo de datos
frecuentes, mantenimiento de servidor, seguridad y acceso fiable en red/Internet. Una preocupación típica aquí es
la política y la localización dentro del país del almacenamiento de datos, pero esto puede solucionarse negociando
condiciones especiales con el proveedor.
1.6. Fase piloto
Antes de comenzar el lanzamiento del sistema nacional es preciso realizar una fase piloto, típicamente para todos los
distrituos de una provincia o región concreta. El objetivo es realizar una prueba de campo y obtener retroalimentación
del sistema por parte de todos los actores involucrados. Normalmente los usuarios aportarán retroalimentación sobre la
experiencia de entrada de datos, los diseños de formularios para entrada de datos, la usabilidad de la funcionalidad de
entrada de datos, el contenido de los reportes y otras herramientas de análisis, la viabilidad de realizar entrada de datos
online (calidad de las conexiones) u offline (fiabilidad de la instalación local). Generalmente sucede que hay cierta
resistencia por parte de los usuarios finales en cuanto al cambio de paradigma del sistema basado en papel al sistema
electrónico, por ejemplo en relación a desacoplar los formularios de entrada de datos y las herramientas de análisis de
datos. Es preciso testear la viabilidad de la conexión de red y la configuración del servidor nacional considerando el
rendimiento y el tiempo de funcionamiento del sistema.
Dada la situación de que haya un sistema heredado en funcionamiento, es vital apagar ese sistema en el zona del piloto.
Si tal sistema todavía está en producción, los usuarios seguirán enfocándose en introducir los datos en ese sistema y
al sistema piloto solo se le prestará atención de forma periférica obteniendo como resultado un testeo y un aprendizaje
subóptimos. Si mantener el sistema anterios es una prioridad, entonces los datos deberán ser transferidos al nuevo
sistema por el equipo técnico sin molestar a los usuarios finales.
1.7. Lanzamiento
El proceso de lanzamiento está asociado tradicionalmente a la instalación del sistema y la formación inicial básica de
los usuarios. Sin embargo, es siempre útil considerarlo como un proceso más integral constituido por múltiples fases.
La primera fase corresponde a las actividades tradicionales en las que el primer objetivo es la integridad de los datos:
para garantizar que cerca del 100% de los datos están siendo recogidos. En primer lugar esto implica que el sistema
deberá ser implementado y utilizado en todos los distritos del país. En segundo lugar, implica que los datos para todos
los elementos de datos incluidos en los formularios se reportan realmente desde los distritos o los establecimientos de
salud. El hecho de que los datos que sean informados en una franja de tiempo razonable - puntualidad -es también
relevante en este contexto.
El segundo objetivo está ligado a la calidad de los datos: para garantizar que los errores en la captura de datos se
reducen al mínimo. Es posible aplicar muchas mediciones diferentes para lograr este objetivo: primero, la entrada de
2
Recomendaciones para implementaciones
nacionales de SIS
Formación
datos y la revisión de datos debe realizarse por personal cualificado, segundo, se deberán aplicar métodos de evaluación
automática de datos tales como reglas de validación y análisis de outliers (valores atípicos).
La segunda fase tiene que ver con capacitar al personal de los hospitales y unidades distritales a utilizar herramientas
estándar de análisis como reportes, gráficas y tablas dinámicas. Los usuarios deberían ser capaces de encontrar y
ejecutar esas herramientas sobre los datos relevantes. Esto debe seguirse de una comprensión básica del propósito,
sentido y consecuencias del uso de esas herramientas y de los datos que sometidos a análisis.
La tercera fase involucra la utilización de los datos: un uso regular del análisis de datos para mejorar la evaluación,
planificación y monitoreo de las actividades de salud a todos los niveles. Los datos del sistema de información
deberían ser utilizados para evaluar los efectos de las decisiones realizadas y las medidas tomadas a través de la
observación de indicadores clave. Este aprendizaje deberá ser utilizado más adelante para la toma informada de
decisiones en planificaciones futuras. Por ejemplo cuando se descubren bajas tasas de inmunidad mediante un reporte
de inmunización proviniente del sistema de información, deberá efectuarse una campaña de vacunación extraordinaria.
Los efectos de la campaña podrán ser monitoreados y evaluados en base a reportes permanentemente actualizados, y
se tomarán decisiones informadas sobre dónde intensificar o suavizar la campaña. Posteriormente, el sistema podrá
proporcionar información sobre qué cantidad de dosis de vacunas es preciso solicitar a los proveedores.
Es preciso trabajar en un plan detallado de formación y acompañamiento para dar cabida a procesos de lanzamiento
a gran escala, ya que cubrir todos los distritos de un país representa un reto logístico en términos de organización de
workshops, formadores, participantes, equipamiento y hardware. Para acelerar el proceso, diversos equipos pueden
realizar formaciones en parelelo.
1.8. Formación
La mayor parte de los objetivos mencionados en la sección de lanzamiento depende en gran medida de una adecuada
capacitación de los usuarios. La formación de usuarios puede realizarse de muy diversas formas. Una actividad
muy eficaz, especialmente para comenzar, son los workshops de formación. Los usuarios tipo digitadores/tipeadores
distritales o provinciales, gestores distritales, personal de registro de datos y gestores de programas de salud se agrupan
y reciben formación conjunta. La formación debería ser una combinación de lecturas teóricas y de ejemplos prácticos en
los temas relevantes mencionados enla sección anterior como son la entrada de datos, validación y análisis. El número
de participantes debería ser manejable en función del número de establecimientos de salud y de formadores disponibles.
Se deberá proporcionar el hardware suficiente para que todos los participantes puedan realizar trabajos prácticos.
Otra actividad útil es la formación durante el trabajo, que tiene la ventaja de que los usuarios reciben acompañamiento
individual en su entorno normal de trabajo. Esto aporta la capacidad de apoyarlos en necesidades o cuestiones
individuales específicas y de resolver problemas relacionados con el hardware instalado. Además, recibir soporte
individual generalmente refuerza la motivación y el sentimiento de pertenencia en los usuarios.
El periodo entre un workshipo y la formación en el trabajo puede emplearse para asignar tareas de entrega posterior,
donde normalmente se pide a los usuarios que creen análisis coherentes para su distrito o provincia. Este trabajo puede
más tarde ser retroalimentado y utilizarse como base para la capacitación individual.
1.9. Descentralización de la gestión y la captura de datos
La migración de sistemas basados en papel o bases de datos primarias a sistemas de información de salud web en
toda regla, y de registrar datos agregados de distrito a datos de establecimientos de salud, supone nuevas posibilidades
para la gestión descentralizada de datos que deberían aprovecharse. En primer lugar, los establecimientos de salud
con hardware y conectividad suficientes deberían ser responsables de introducir sus propios datos. Esto reducirá
la carga de trabajo del personal de registro a nivel distrital, quien podrá utilizar el tiempo ganado para análisis
de datos, utilización de los datos, retroalimentación a los establecimientos y mejora de la calidad de los datos. En
segundo lugar, el mantenimiento de la jerarquía de establecimientos en términos de clasificación y de los servicios de
salud proporcionados en los establecimientos es una tarea que demanda recursos y que debería ser descentralizada y
realizada como un esfuerzo conjunto por todo el personal distrital más que por un único equipo nacional. Esto hará
que la información de los establecimientos sea más correcta y actualizada ya que el personal distrital tendrá mejor
3
Recomendaciones para implementaciones
nacionales de SIS
Revisión y extensión
conocimiento de su situación local, y tendrá también motivación para una gestión adecuada ya que ello afectará sus
indicadores de rendimiento y sus marcas de integridad de datos.
1.10. Revisión y extensión
Un SIS nacional es un organismo en crecimiento que necesita mantenimiento. A medida que aumenta el uso del sistema,
surgirán más requisitos y necesidades de los actores existentes y otros nuevos como son el personal distrital de registro
y el personal de programas de salud. Es recomendable mantener reuniones regulares de revisión que incorporen a
dichos actores, y donde las herramientas de captura de datos, como son los elementos de datos y formularios, y las
herramientas de análisis, como son los indicadores y reportes, se revisen y se añadan potenciales herramientas nuevas.
Además, los nuevos requisitos de funcionamiento deben gestionarse y se deben asegurar recursos apropiados para el
desarrollo software. Estas actividades regulares para apoyar la extensión y mejora del sistema son vitales para mantener
el momentum actual y los procesos de aprendizaje, así como para mejorar la sostenibilidad del proyecto a largo plazo.
4
Principios conceptuales de diseño
Todos los metadatos pueden añadirse y
modificarse a través del interfaz de usuario
Capítulo 2. Principios conceptuales de
diseño
Este capítulo pretende servir de introducción a algunos de los principios conceptuales clave de diseño que alberga el
software DHIS 2. La comprensión y toma de conciencia sobre estos principios ayudará a los implementadores a hacer
un uso óptimo del software al personalizar una base de datos local. Si bien este capítulo solo se centra en los principios,
los capítulos siguientes detallan cómo éstos repercuten en el proceso de diseño de la base de datos
En este capítulo se presentan los siguientes principios de diseño:
• Que todos los metadatos puedan añadirse y modificarse a través del interfaz de usuario
• Que un modelo de datos flexible soporte que diferentes fuentes de datos puedan ser integradas en un único repositorio
de datos
• Que la entrada de datos != Salida de datos
• Que el análisis de datos y reportes estén basados en indicadores
• Que los datos de establecimientos de salud se mantengan desagregados en la base de datos
• Que el análisis de datos esté soportado para cualquier nivel del sistema de salud
A continuación cada principio se describe en mayor detalle en las respectivas secciones.
2.1. Todos los metadatos pueden añadirse y modificarse a través del
interfaz de usuario
La aplicación DHIS 2 trae un set de herramientas genéricas para la recolección de datos, validación, elaboración de
reportes y análisis de datos. Sin embargo, los contenidos de la base de datos, tales como qué datos recolectar, de dónde
vienen los datos, o en qué formato, depende del contexto de uso de esa información. Antes de poder utilizar estos
metadatos es preciso ingresarlos en la aplicación, lo cual puede hacerse a través del interfaz de usuario y no requiere
programación. Esto permite involucrar más directamente a los expertos de ese ámbito, que son quienes entienden los
detalles del SIS que el software debe soportar.
El software separa los metadatos importantes que describen los datos en bruto que son almacenados en la base de datos,
que son los metadatos críticos que no debieran cambiar mucho a lo largo del tiempo (para evitar la corrupción de datos),
y los metadatos de alto nivel como las fórmulas de indicadores, las reglas de validación y los grupos de agregación, así
como las diferentes capas (layouts) para recogida de formularios y reportes, que no son tan críticos. En este alto nivel
los metadatos pueden añadirse y modificarse en el tiempo sin interferir con los datos en bruto, soportando un proceso
permanente de personalización. Es típico añadir nuevos atributos a medida que el equipo local de implementación
va aprendiendo a dominar más funcionalidades de la aplicación, y que los usuarios van introduciendo gradualmente
análisis de datos y reportes más avanzados.
2.2. Un modelo de datos flexible soporta que diferentes fuentes de datos
puedan ser integradas en un único repositorio de datos
El diseño de DHIS 2 sigue una aproximación integral del SIS, y soporta la integración de muchas fuentes de datos
diversas en una misma base de datos, en ocasiones denominada repositorio integrado de datos o data warehouse
El hecho de que DHIS 2 sea una especie de herramienta esqueleto sin formularios o reports predefinidos significa que
puede soportar una buena cantidad de diferentes fuentes de datos agregados. Tampoco hay nada que limite realmente
su uso al ámbito de la salud, aunque su uso en otros sectores es aún muy restringido. Mientras los datos sean recogidos
por una orgunit, descritos como elementos de datos (probablemente con una desagregación en categorías), y puedan
5
Principios conceptuales de diseño
Entrada de datos != Salida de datos
representarse con una frecuencia y periodos predefinidos, esos datos pueden recolectarse y procesarse en DHIS 2. Esta
flexibilidad hace que DHIS 2 sea una herramienta potente para montar sistemas integrados que aúnen herramientas de
recolección, de indicadores y de reportes de múltiples programas de salud, departamentos e iniciativas. Una vez que
los datos se definen y luego se recogen o importan en una base de datos de DHIS 2, pueden analizarse en correlación
con otros datos cualesquiera de la misma base de datos, sin importar cómo o quién introdujo los datos. Además de
soportar el análisis y reporte integrado de datos, este enfoque integrado también ayuda a racionalizar la recolección
de datos y a reducir los duplicados.
2.3. Entrada de datos != Salida de datos
En DHIS 2 hay tres dimensiones que describen los datos agregados que se están recogiendo y almacenando enla base de
datos: DÓNDE - la unidad organizativa, QUÉ - el elemento de datos, y CUÁNDO - el periodo. La unidad organizativa,
el elemento de datos y el periodo constitutyen las tres dimensiones nucleares necesarias para describir cualquier valor
de un dato en DHIS 2, ya se encuentr en un formulario de recogida de datos, en un gráfico, en un mapa, o en un reporte
sumarístico agregado. Cuando los datos se recogen en formularios electrónicos, que a veces son imágenes especulares
de los formularios en papel utilizados en los establecimientos, cada campo de entrada del formulario queda descrito
utilizando estas tres dimensiones. El formulario en sí mismo es tan solo una herramienta para organizar la recolección
de datos y no describe los valores de datos individuales que se están recogiendo o guardando en la base de datos.
Ser capaces de describir cada valor de datos independientemente mediante una definición de Elemento de Datos (por
ejemplo, 'Dosis de sarampión suministradas < 1 año') permite una importante flexibilidad a la hora de procesar, validar
y analizar los datos, permitiendo comparar datos en diversos formularios y programas de salud.
Este enfoque de diseño o de modelo de datos marca la diferencia entre DHIS y muchas otras aplicaciones software de
SIS que tratan los formularios de recogida de datos como la unidad clave del análisis. Esto es muy típico en sistemas
hechos a la medida de las necesidades de programas verticales de salud y en la mentalidad tradicional de que el
formulario de entrada de datos agregados es ya también la salida de reporte o de análisis.
La figura siguiente muestra cómo el diseño granular fino de DHIS, construido sobre el concepto de Elementos de
Datos, es diferente y cómo la entrada (recogida de datos) está separada de la salida (análisis de datos), permitiendo
un análisis y diseminación de datos más flexible y variada. En el ejemplo, el elemento de dato 'Dosis de sarampión
suministradas < 1 año' es registrado como parte de un formulario de registro de Inmunización Infantil, pero puede
utilizarse individualmente para construir un Indicador (una fórmula) llamada 'Cobertura de sarampión < 1 año', donde
se combina con el elemento de datos llamado 'Población < 1 año', que se registra en un formulario distinto. El valor
de este indicador calculado puede utilizarse luego en el análisis de datos de varias herramientas de reporte en DHIS 2,
como por ejemplo en reportes personalizados con gráficos, tablas dinámicas, o en un mapa en el módulo SIG.
6
Principios conceptuales de diseño
Análisis de datos y reportes basados en
indicadores
2.4. Análisis de datos y reportes basados en indicadores
Aquello que hemos llamado previamente Elemento de Datos es la dimensión clave que describe qué se está registrando
(en otros contextos puede nombrarse somo indicador). En DHIS 2 distinguimos entre Elementos de Datos, que
describen los datos en bruto, como los recuentos, y los Indicadores, que parten de fórmulas y describen valores
calculados, como por ejemplo cobertura o tasa de incidencia que se utilizan para en el análisis. Los valores de los
indicadores no se registran como los valores de datos, sino que se calculan enla aplicación a partir de fórmulas definidas
por los usuarios. Estas fórmulas constan de un factor (ej. 1, 100, 1000, 200 000), y de un numerador y un denominador,
que son expresiones construidas con uno o más elementos de datos. Por ejemplo, el indicador 'Cobertura de sarampión
< 1 año' se define con una fórmula de factor 100, un numerador ('Dosis de sarampión suministradas a niños menores
de 1 año') y n denominador ('Población diana menores de 1 año'). El indicador 'Tasa de exclusión DPT1 a DPT3' es
una fórmula de 100 % x ('Dosis suministradas DPT1' - 'Dosis suministradas DPT3') / ('Dosis suministradas DPT1').
Estas fórmulas pueden añadirse y editarse a través del interfaz de usuario por usuarios con una capacitación básica, ya
que son bastante sencillos de configurar y no interfieren con los valores de datos almacenados en la base de datos (de
modo que añadir o modificar un indicador no es una operación crítica).
Los indicadores son tal vez la característica más potente de DHIS 2 y todas las herramientas de reporte soportan
el manejo de indicadores, como se muestra por ejemplo en el reporte personalizado de la figura anterior. Tener la
capacidad de utilizar datos de población en el denominador permite comparaciones de desempeño en salud entre
diversas áreas geográficas con distintas poblaciones diana, lo cual resulta más útil que mirar únicamente los números en
bruto. La tabla siguiente utiliza tanto valores de datos en bruto (las dosis) como los valores de indicadores (la cobertura)
para diferentes vacunas. Comparando por ejemplo las dos primeras unidades organizativas de la lista, distrito de Taita
Taveta y distrito de Kilifi, en inmunización DPR-1, podemos observar que mientras los números en bruto (659 vs
2088) indican que se suministraron muchas más dosis en Kilifi, las tasas de cobertura (92.2 % vs 47.5 %) muestran
que Taita Taveta está realizando un mejor trabajo en la inmunización de su población diana menores de 1 año. Si
observamos ahora la última columna (Inmunización completada %), que indica la integridad de registros del formulario
7
Principios conceptuales de diseño
Mantener los datos de establecimientos
desagregados en la base de datos
de inmunización para el mismo periodo, vemos que los números son más o menos los mismos para los dos distritos
comparados, lo cual apunta a que es razonable comparar las tasas de cobertura entre estos dos distritos.
2.5. Mantener los datos de establecimientos desagregados en la base de
datos
Cuando se recogen datos y se almacenan en DHIS 2, éstos quedarán desagregados en la base de datos con el mismo
nivel de detalle con el cual fueron registrados. Ésta es la mayor ventaja de tener un sistema de base de datos para SIS
similar a lo esperado de un sistema en papel o incluso en hojas de cálculo. El sistema se diseña para almacenar gran
cantidad de datos y siempre permite exámenes a fondo hasta el nivel más fino posible de detalle, que solo está limitado
por la manera en que los datos fueron registrados o importados en la base de datos DHIS 2.
Desde la perspectiva de un SIS nacional, es deseable guardar los datos desagregados por nivel de establecimiento de
salud, que generalmente es el nivel más bajo en la jerarquía organizativa. Esto puede hacerse incluso sin informatizar
este nivel, mediante un sistema híbrido informático y en papel. Por ejemplo, los datos pueden ser enviados en
papel desde los establecimientos de salud a las oficinas distritales (en formularios mensuales resumidos para un
establecimiento específico), y luego en la oficina distrital ya introducen todos los datos de establecimiento en DHIS
2 mediante formularios electrónicos de recogida de datos, establecimiento por establecimiento. Esto permitirá a los
equipos distritales de gestión de salud realizar análisis de datos por establecimiento y por ejemplo compartir los reportes
impresos de realimentación generados en DHIS 2, incluidas comparativas entre establecimientos, con los responsables
de los establecimientos en cada distrito.
2.6. Soporte de análisis de datos a cualquier nivel del sistema de salud
Aunque el propio nombre de DHIS apunta a un enfoque de 'distrito', la aplicación ofrece las mismas herramientas
y funcionalidades a todos los niveles del sistema de salud. En todas las herramientas de reporte los usuarios pueden
seleccionar qué unidad organizativa o qué nivel de orgunit desean analizar y los datos mostrados se agregarán
automáticamente en el nivel seleccionado. DHIS 2 utiliza la jerarquía de unidades organizativas para agregar datos
hacia arriba y nos da los datos para cualquier orgunit en esta jerarquía. La mayoría de reportes se lanzan de manera que
se pedirá a los usuarios que seleccionen una unidad organizativa y así permitir la reutilización de las mismas capas de
reporte para todos los niveles. O si se desea, las capas de reporte pueden diseñarse a la medida de un nivel específico
cualquiera en el sistema de salud en caso de que las necesidades difieran entre diferentes niveles.
En el módulo SIG los usuarios pueden analizar los datos por ejemplo a nivel subnacional y entonces pinchando en
el mapa (por ejemplo en un departamento o provincia) examinar a fondo el siguiente nivel, y continuar de este modo
descendiendo hacia la fuente de datos a nivel de establecimiento. Una funcionalidad similar de profundización está
disponible en las tablas dinámicas que están enlazadas con la base de datos DHIS 2.
Para acelerar el rendimiento y reducir el tiempo de respuesta al generar salidas de datos agregadas, que pueden incluir
numerosos cálculos (por ejemplo juntar 8000 establecimientos), DHIS 2 realiza un precálculo de todos los valores
agregados posibles y los guarda en lo que se denomina datamart. El datamart puede programarse para ser ejecutado
(reconstruirse) en intervalos de tiempo determinados, por ejemplo cada noche.
8
Instalación de una nueva base de datos
Estrategias para empezar
Capítulo 3. Instalación de una nueva
base de datos
La aplicación DHIS 2 viene con un set de herramientas para la recogida de datos, validación, reporte y análisis, pero
los contenidos de la base de datos, como son qué datos registrar, de dónde vienen los datos, y en qué formato, dependen
del contexto en que usemos la aplicación. Tendremos que insertar estos metadatos en la aplicación antes de poder
usarlos, y esto es posible hacerlo mediante el interfaz de usuario sin necesidad de programación. Lo que sí se necesita
es conocer en profundidad el contexto local del SIS así como comprender los principios de diseño de DHIS 2 (véase
el capítulo "Principios conceptuales de diseño en DHIS 2"). Esto es lo que llamamos proceso inicial para el diseño y
personalización de la base de datos. Este capítulo da una perspectiva general del proceso de personalización y explica
brevemente los pasos requeridos, con el objetivo de ofrecer a los implementadores una visión de lo que requiere este
proceso. Otros capítulos de este manual entran con mayor detalle en algunos de estos pasos concretos.
3.1. Estrategias para empezar
La sección siguiente describe una lista de consejos para arrancar con buen pie en el desarrollo de una nueva base de
datos.
1. Montar cuanto antes una base de datos demostrativa, que incluya ejemplos de reportes, gráficas, dashboard, SIG,
formularios de entrada de datos. Utilizar datos reales, idealmente a nivel nacional, pero no necesariamente datos
a nivel de establecimientos de salud.
2. Poner la base de datos demostrativa accesible desde Internet. Una manera de acelerar este proceso puede ser
alojarla en un servidor web con un proveedor de servicios externo, incluso si es solo temporal. Esto crea una buena
plataforma colaborativa y una herramienta estupenda de difusión para lograr la aprobación y participación de los
diferentes actores relevantes para el SIS.
3. Realizar a continuación un proceso de diseño de la base de datos más elaborado. Si es posible, algunas partes de
la demo pueden reutilizarse.
4. Asegurarse de que contamos con un equipo local multidisciplinar, con capacidades y formación diversas: salud
pública, administración de sistemas, gestión de TIC y gestión de proyectos.
5. Utilizar la fase de personalización y diseño de la base de datos como un proceso de aprendizaje y de formación para
cultivar capacidades locales mediante "aprender haciendo".
6. El equipo nacional de implementación deberá liderar el proceso de diseño de la base de datos pero siempre apoyado
y guiado por implementadores más experimentados.
3.2. ¿Un proceso controlado o un proceso abierto?
Dado que el proceso de personalización de DHIS 2 suele ser y debe ser un proceso colaborativo, es importante tener
en mente qué partes de la base de datos son más críticas que otras, por ejemplo para evitar que usuarios no capacitados
corrompan los datos. Normalmente es mucho más crítico personalizar una base de datos que ya tiene valores de datos,
que trabajar con metadatos en una base de datos "vacía". Aunque parezca extraño, mucha de la personalización tiene
lugar después del primer registro de datos o de la primera importación. Es entonces cuando por ejemplo se añaden
nuevas reglas de validación, indicadores y capas de reporte.
El error más crítico que se puede cometer aquí es modificar los metadatos que describen directamente los valores
de datos, que como hemos visto anteriormente, son los elementos de datos y las unidades organizativas. Cuando
modificamos estas definiciones es importante pensar en cómo afectarán los cambios al significado de los valores de
datos que ya estaban en el sistema (recogidos utilizando las definiciones anteriores). Es recomendable limitar quién
puede editar estos metadatos fundamentales, mediante la gestión de roles de usuario, para restringir el acceso al equipo
experto de personalización.
Otras partes del sistema que no están directamente acopladas a los valores de datos son mucho menos críticas y podemos
experimentar con ellas. Es más, en las fases incipientes de implementación, deberíamos animar a los usuarios a probar
cosas nuevas y así provocar el aprendizaje. Esta premisa es válida para los grupos, las reglas de validación, las fórmulas
9
Instalación de una nueva base de datos
Pasos para elaborar una base de datos
de indicadores, las gráficas y los reportes. Todos ellos pueden borrarse o modificarse posteriormente con facilidad sin
afectar a los valores de datos, de modo que no son partes críticas del proceso de personalización.
Por supuesto, cuando posteriormente llevamos el proceso de personalización a fase de producción, deberemos ser
todavía más cautos al permitir acceso a la edición de metadatos, ya que cualquier cambio, incluso en los menos críticos,
puede afectar a cómo se agregan o se presentan los datos en reportes (aunque los datos en bruto por debajo estén
correctos y a salvo). .
3.3. Pasos para elaborar una base de datos
Esta sección describe los pasos concretos para elaborar una base de datos desde el principio.
3.3.1. Jerarquía organizativa
La jerarquía organizativa define la organización en DHIS 2: los establecimientos de salud, las áreas administrativas y
otras áreas geográficas utilizadas en la recolección y el análisis de datos. Esta dimensión de los datos se define como una
jerarquía con una unidad raíz (ej. Ministerio de Salud) y diversos niveles y nodos debajo. Cada nodo en esta jerarquía
es lo que en DHIS 2 llamamos unidad organizativa. El diseño de esta jerarquía determinará las unidades geográficas
de análisis disponibles a los usuarios al momento en que los datos son registrados y agregados en esta estructura.
Solo puede haber una jerarquía organizativa en el sistema, de modo que deberemos considerar cuidadosamente cómo
estructurarla.
Es posible modelar jerarquías adicionales (tales como límites administrativos paralelos al Sector Salud) utilizando
grupos organizativos y sets de grupo, pero la jerarquía organizativa es el vehículo principal para la agregación de datos
en una dimensión geográfica. Normalmente las jerarquías organizativas nacionales en Salud Pública tienen entre 4 y
6 niveles, pero DHIS soporta cualquier cantidad de niveles. La jerarquía se construye con relaciones padre-hijo, por
ejemplo: una unidad País o Ministerio de Salud (la raíz) puede tener 8 unidades hijo (provincias), y cada provincia (en
nivel 2) puede tener a su vez 10 ó 15 distritos como nodos hijo. Generalmente los establecimientos de salud estarán
colocados en el nivel más bajo, pero también podemos colocarlos en niveles más altos como sucederá con los hospitales
provinciales o nacionales, de modo que es posible tener árboles organizativos asimétricos (ej. un nodo hoja puede estar
colocado en el nivel 2 mientras la mayoría de nodos hoja se encuentran en el nivel 5).
3.3.2. Elementos de datos
El Elemento de Datos es probablemente el bloque más fundamental de una base de datos en DHIS2. Representa la
dimensión qué, ya que explica qué se está recopilando o analizando. En algunos contextos esto está referido a un
indicador, para en DHIS2 llamamos elemento de datos a esta unidad de colección y análisis. El elemento de datos a
menudo representa un conteo de algo, y su nombre describe qué es aquello que se está contando, por ejemplo "Dosis
entregadas de BCG" o "Casos de Malaria". Cuando los datos son recopilados, validados, analizados, reportados o
presentados, lo que describe el QUÉ de los datos son los elementos de datos o expresiones construidas a partir de
elementos de datos. Como tales, los elementos de datos se vuelven importantes para todos los aspectos del sistema y
deciden no sólo cómo se recopilan los datos, sino algo más importante: cómo los valores de datos se representan en la
base de datos, lo cual de nuevo afecta a cómo los datos son analizados y presentados.
La mejor práctica en el diseño de elementos de datos es pensar en los elementos de datos como una unidad de análisis
de datos y no sólo como un campo en el formulario de entrada de datos. Cada elemento de datos tiene vida propia en
la base de datos, completamente separado del formulario, y los reportes y otras salidas se basan en elementos de datos
y expresiones o fórmulas compuestas por elementos de datos y no en los formularios de colección de datos. De modo
que las necesidades del análisis de datos son las que deberían dirigir este proceso, y no el aspecto y función amigables
del formulario de colección de datos.
3.3.3. Sets de datos y formularios de entrada de datos
Toda la entrada de datos en DHIS 2 se organiza mediante la utilización de sets de datos. Un set de datos es una colección
de elementos de datos agrupados juntos para la recopilación de datos, y en el caso de instalaciones distribuidas también
10
Instalación de una nueva base de datos
Reglas de validación
define pedazos de datos para exportarlos o importarlos entre instancias de DHIS 2 (por ejemplo de una instalatión
local en una oficina distrital a un servidor nacional). Los sets de datos no están vinculados directamente a los valores
de datos, solo mediante sus elementos de datos y frecuencias, y como tales los sets de datos pueden ser modificados,
eliminados o añadidos en cualquier momento sin que esto afecte a los datos en bruto previamente capturados en el
sistema, pero tales cambios afectarán por su puesto a cómo se registrarán nuevos datos.
Una vez hemos asignado un set de datos a una unidad organizativa, ese set de datos estará disponible en Entrada de
Datos (del menú Servicios) para la unidad asignada y para los periodos válidos de acuerdo al tipo de periodo del set
de datos. Entonces, se mostrará un formulario de entrada de datos por defecto, que es simplemente una lista de los
elementos de datos pertenecientes al set de datos junto a una columna para introducir los valores. Si nuestro set de datos
contiene elementos de datos con categorías como grupos de edad o género, entonces se generarán automáticamente
columnas adicionales en el formulario por defecto en base a estas categorías. Además del formulario de entrada de datos
por defecto basado en listado, existen dos alternativas: el formulario basado en secciones y el formulario personalizado.
Los formularios por secciones permiten un poco más de flexibilidad cuando queremos utilizar formularios tabulares,
y además son rápidos y sencillos de diseñar. A menudo sucederá que nuestro formulario de entrada de datos precisa
múltiples tablas con subtítulos, y a veces necesitamos deshabilitar (poner en gris) algunos campos de la tabla (por
ejemplo cuando algunas categorías no aplican para todos los elementos de datos); estas funciones están soportadas en
los formularios por secciones. Cuando el formulario que queremos diseñar es demasiado complicado para los modelos
por defecto o por secciones, entonces nuestra última opción es usar el formulario personalizado. Este nos llevará más
tiempo, pero da una flexibilidad total en términos de diseño. DHIS 2 viene ya con un editor HTML (Editor FcK) para
el diseñador de formularios y podemos diseñar el formulario usando este interfaz de usuario o bien pegar directamente
nuestro código HTML (usando la ventana Fuente en el editor).
3.3.4. Reglas de validación
Una vez que hayamos configurado la parte de entrada de datos del sistema y comenzado a recoger datos, entonces
es momento de definir chequeos de calidad de los datos que ayuden a mejorar la calidad de los datos que se están
recopilando. Podemos añadir tantas reglas de validación como queramos, que estarán compuestas por expresiones
a izquierda y derecha de un operador matemático, que a su vez están formadas por elementos de datos. Las reglas
típicas consisten en comparar los subtotales con los totales de algo. Por ejemplo, si tenemos dos elementos de datos
"Test VIH realizados" y "Test VIH resultado positivo", entonces sabemos que en el mismo formulario (es decir, para
el mismo periodo y unidad organizativa) el número total de tests deberá ser siempre igual o mayor que el número
de tests positivos. Estas reglas deberían ser reglas absolutas, que significa que son matemáticamente correctas y no
simplemente asunciones o "casi siempre correctas". Las reglas se pueden ejecutar en la entrada de datos, después
de rellenar cada formulario, o como un proceso por tandas testeando múltiples formularios de una vez, por ejemplo
para todos los establecimientos durante el mes de reporte previo. Los resultados de los tests de validación mostrarán
un listado con todas las infracciones y con los valores detallados de cada lado de la expresión donde se produjo la
infracción para facilitar que regresemos a la entrada de datos y corrijamos los valores.
3.3.5. Indicadores
Los indicadores representan seguramente la herramienta más poderosa de análisis incluida en DHIS 2. Mientras los
elementos de datos representan los datos en bruto (conteos) que son recopilados, los indicadores representan fórmulas
que proporcionan tasas cobertura, tasas de incidencia, ratios y otras unidades de análisis calculadas. Un indicador se
compone de un factor (por ejemplo 1, 10, 100, 10 000), un numerador y un denominador, los dos últimos siendo
expresiones obtenidas a partir de uno o varios elementos de datos. A modo de ejemplo, el indicador "Cobertura BCG <1
año" queda definido por una fórmula con factor 100, numerador el número de "dosis BCG entregadas a niños menores
de 1 año", y denominador la "población diana menor de 1 año". El indicador "Tasa de exclusión de DPT1 a DPT3" es
una fórmula de 100 % x ("Dosis entregadas DPT1"-"Dosis entregadas DPT3") / ("Dosis entregadas DPT1")
La mayoría de los módulos de reporte en DHIS 2 soportan tanto elementos de datos como indicadores y podemos
incluso combinarlos en reportes personalizados. Pero la diferencia más importante y la ventaja de los indicadores frente
a los datos en bruto (los valores de los datos en los elementos de datos) es la capacidad para comparar datos a través
de áreas geográficas distintas (por ejemplo, áreas muy pobladas frente a áreas rurales) ya que la población diana puede
utilizarse como denominador.
11
Instalación de una nueva base de datos
Tablas de reporte e informes
Es posible añadir, modificar y eliminar indicadores en cualquier momento sin interferir en los valores de los datos que
ya se encuentran en la base de datos.
3.3.6. Tablas de reporte e informes
Una manera muy flexible de presentar los datos que se han recopilado son los reportes estándar en DHIS 2. Los datos
pueden ser agregados por unidad organizativa o cualquier nivel de orgunit, por elemento de datos, por indicadores,
así como a lo largo del tiempo (por ejemplo, mensual, trimestral, anualmente). Las tablas de reportes son fuentes
de datos personalizadas para los reportes estándar y se pueden definir de manera flexible en el interfaz de usuario y
posteriormente acceder a ellas con diseñadores externos de reportes como iReport o BIRT. Estos diseños de reporte
se pueden configurar para ser accesibles fácilmente "one-click" con unos parámetros predefinidos de modo que los
usuarios puedan lanzar los mismos reportes, por ejemplo, cada mes cuando se introducen nuevos datos, y también
pueden ser relevantes a usuarios a todos los niveles ya que la unidad organizativa puede seleccionarse al momento
de lanzar el reporte.
3.3.7. SIG (Mapas)
En el módulo integrado de SIG podemos mostrar fácilmente nuestros datos en mapas, tanto en polígonos (áreas) como
en puntos (establecimientos de salud), y tanto los elementos de datos como los indicadores. Si añadimos al sistema
las coordenadas de nuestras unidades organizativas, podemos rápidamente comenzar a trabajar con este módulo.
Recomendamos ver la sección SIG para más detalles sobre cómo configurar este módulo.
3.3.8. Gráficas y dashboard
Una de las maneras más sencillas de mostrar nuestros datos de indicadores es utilizar gráficas. Una pantalla de diálogo
amigable nos guiará a través de la creación de varios tipos de gráficas con data de indicadores, unidades organizativas
y periodos a nuestra elección. Estas gráficas pueden añadirse fácilmente a una de las cuatro secciones del dashboard
destinadas a gráficas, y así las tendremos disponibles directamente al entrar en nuestra sesión. Para esto deberemos
fijar el módulo dashboard como el módulo de inicio en la configuración de usuario.
12
Estrategias de despliegue
Despliegue Desconectado (Offline)
Capítulo 4. Estrategias de despliegue
DHIS 2 es una aplicación para trabajar en red y puede accederse desde Internet, desde una intranet local y como sistema
instalado localmente. Las alternativas de despliegue de DHIS 2 se definen en este capítulo como: offline, online o
híbridas. En las secciones siguientes discutiremos su significado y diferencias.
4.1. Despliegue Desconectado (Offline)
Un despligue offline implica que instalamos muchas instancias autónomas offline para los usuarios finales,
generalmente a nivel de distrito. El sistema lo mantienen principalmente los usuarios, trabajadores de salud en distrito,
que introducen los datos y generan reportes utilizando su servidor local. Típicamente hay también un equipo de
superusuarios a nivel nacional que mantiene el sistema y realizar visitas regularmente a los despliegues en distritos.
Los usuarios envían los datos hacia arriba en la jerarquía produciendo ficheros de intercambio de datos que se envían
electrónicamente por email o físicamente por correo convencional o viajes del personal. Notemos que aunque haya una
conexión reducida a Intenret para enviar emails, puede no ser suficiente para que el sistema sea online. Esta forma de
despliegue tiene el beneficio claro de que funciona cuando no disponemos de una conectividad de Internet apropiada.
Por otro lado hay algunos retos significativos en esta forma de desplique, que se describen a continuación.
• Hardware: Tener en funcionamiento sistemas autónomos requiere un hardware más avanzado en términos de
instalar servidores y suministro eléctrico fiable, generalmente a nivel de distrito, en todo el país. Esto requiere una
financiación apropiada para la adquisición de equipos y la planificación de mantenimiento a largo plazo.
• Plataforma software: Las instalaciones locales implican una necesidad importante de mantenimiento. De la
experiencia de HISP, el mayor reto son los viruses y otros malwares que tienden a infectar las instalaciones locales
a largo plazo. La razón principal para esto es que los usuarios utilizan dispositivos de memoria externa USB para
transportar los ficheros de intercambio de datos y documentos entre computadoras privadas, otras computadoras de
red y el sistema en el que funciona la aplicación DHIS. Mantener sofware antivirus y parches de sistema operativo
actualizados en un entorno offline es dificultoso y una mala práctica en términos de seguridad muy común entre
los usuarios. Tal vez la mejor manera de evitar esto es lanzar un servidor dedicado para la aplicación donde no se
utilicen memorias externas y se utilice un sistema operativo basado en Linux, que no sea susceptible de infecciones
de virus como lo es MS Windows.
• Aplicación software: Ser capaces de distribuir nuevas funcionalidades y resolución de bugs a los usuarios del
software de información de salud es esencial para el mantenimiento y la mejora progresiva del sistema. Delegar en
los usuarios finales la tarea de actualizar el software implica que ellos reciban una formación extensiva y un altísimo
nivel de competencias de aquel lado, ya que las actualizaciones software pueden incluir alguna tarea técnicamente
ariesgada. Delegar en el equipo nacional de superusuarios la tarea de mantener el software directamente, implicará
muchos viajes.
• Mantenimiento de la base de datos: Un requisito previo para lograr un sistema eficiente es que todos los usuarios
introduzcan datos con un set estandarizado de metadatos (elementos de datos, formularios, etc.). Aquí sucede algo
parecido al punto anteriormente comentado sobre actualizaciones de software: la distribución de cambios en el set de
metadatos en gran número de instalaciones offline requiere usuarios finales muy competentes si las actualizaciones
se envían digitalmente o bien un equipo de superusuarios muy bien organizado. Si hay un fallo al mantener la
sincronización del set de metadatos, conllevará la pérdida de capacidad para enviar datos desde los distritos y/o
una base de datos nacional inconsistente, ya que los datos introducidos por ejemplo a nivel de distrito, no serán
compatibles con los datos a nivel nacional.
4.2. Despliegue Conectado (Online)
Un despliegue online implica que una sola instancia de la aplicación DHIS se instala en un servidor conectado a
Internet. Todos los usuarios (clientes) se conectan con el servidor central online a través de Internet utilizando un
navegador web. Este estilo de implementación suele beneficiarse de las grandes inversiones y extensiones de las redes
de comunicaciones de acceso: móviles (celular) y de banda ancha en países en desarrollo. Esto posibilita el acceso a
servidores online incluso en las áreas más rurales utilizando modems de Internet móvil (también llamadas dongles).
13
Estrategias de despliegue
Despliegue Híbrido
Esta forma de despliegue online tiene implicaciones muy positivas en el proceso de implementación y en el
mantenimiento de la aplicación en comparación con el estilo tradicional desconectado:
• Hardware: Los requisitos hardware del lado del usuario se limitan a una computadora o portátil (laptop)
razonablemente modernos, y conexión a Internet a través de línea fija o módem celular. No hay necesidad de tener
servidores especializados del lado del usuario, sino que cualquier computadora que pueda navegar es suficiente.
• Plataforma software: Los usuarios solo necesitan un navegador web para conectarse al servidor online. Hoy en día
todos los sistemas operativos populares vienen con un navegador web ya instalado y no hay ningún requisito especial
sobre qué tipo o versión de navegador. Lo que esto significa es que si hay problemas graves como infecciones de
virus o corrupción del software en esa computadora, siempre podremos recurrir a reformatear e instalar de nuevo
el sistema operativo o comprar una computadora nueva. En tal caso, el usuario podrá seguir introduciendo datos
donde lo dejó y no se habrá perdido ningún dato.
• Aplicación software: El estilo de despliegue online, es decir, basado en un servidor central, significa que podemos
actualizar y mantener la aplicación de manera centralizada. Cuando salen nuevas versiones de DHIS con nuevas
funcionalidades y resoluciones de bugs, esto puede aplicarse únicamente al servidor online. Y todos los cambios
se reflejarán en el lado del cliente la próxima vez que los usuarios se conecten al servidor a través de Internet.
Obviamente, esto tiene un impacto enormemente positivo en el proceso de mejorar el sistema ya que las nuevas
funcionalidades se distribuyen inmediatamente a los usuarios, todos los usuarios estarán siemrpe accediendo a la
misma versión de la aplicación, y los bugs y complicaciones pueden resolverse e implantarse al momento.
• Mantenimiento de la base de datos: De forma similar al punto anteior, los cambios en los metadatos se hacen en
el servidor online de forma centralizada y se propagan automáticamente a todos los clientes la próxima vez que se
conecten al servidor. Esto efectivamente elimina los vastos problemas relacionados con mantener un set de metadatos
actualizado y estandarizado, como sucede en el despliegue offline. Por ejemplo es muy conveniente este estilo
durante la fase inicial de desarrollo de la base de datos y durante los procesos anuales de revisión de la base de datos,
ya uqe los usuarios estarán accediendo a una base de datos consistente y estandarizada incluso cuando en ella se
están produciendo cambios frecuentes.
Este enfoque puede ser problemático en los casos en los que la conexión a Internet es volatil o insuficiente durante
largos periodos de tiempo. Sin embargo, DHIS 2 dispone de algunas características que permiten que el requisito de
conexión a Internet solo sea necesario en momentos concretos para que el sistema funcione bien, como la herramienta
MyDatamart que se explica en un capítulo específico de este Manual.
4.3. Despliegue Híbrido
De la discusión de los puntos anteriores, uno puede darse cuenta de que el estilo de despliegue online es más favorable
que el despliegue desconectado, pero requiere conexión a Internet allá donde se use. Es importante tomar en cuenta
que los estilos mencionados también pueden coexistir en un un despliegue común. Es perfectamente factible tener
despliegues online y offline en un mismo país. La norma general sería que los distritos y establecimientos deberían
acceder al sistema online a través de Internet siempre que exista conexión suficiente, y habrá sistemas offline en
aquellos distritos donde no se dé el caso.
Es difícil definir con precisión cómo es una conexión a Internet suficiente pero podemos poner como regla práctica
que la velocidad de descarga debería ser mínimo 10 Kbyte/seg y la disponibilidad devería ser como mínimo el 70%
del tiempo.
En este sentido los modems de Internet por celular que se puedan conectar a una computadora o portátil para acceder
a la red celular son una solución factible y suficiente. La cobertura de Internet móvil está aumentando rápidamente en
todo el mundo, con frecuencia ofreciendo una conectividad buena a precios asequibles y es una alternativa a las redes
locales y poco mantenidas de líneas fijas de Internet. Puede resultar un esfuerzo que vale la pena el contactar con las
compañías de red móvil nacional y negocias suscripciones de postpago y beneficios potenciales de economía de escala.
Es conveniente estudiar la cobertura de red para cada operador de red de telecomunicaciones en el país concreto, a la
hora de decidir qué tipo de despliegue arrancar, ya que podrá ser diferente en distintas regiones del país.
14
Estrategias de despliegue
Alojamiento de servidor
4.4. Alojamiento de servidor
El enfoque de despliegue online plantea la cuestión de dónde y cómo alojar el servidor que ejecutará la aplicación
DHIS2. Típicamente hay varias opciones posibles:
1. Alojamiento interno en el Ministerio de Salud
2. Alojamiento en un centro gubernamental de datos
3. alojamiento a través de una compañía externa de hosting
La razón principal para elegir la primera de las opciones es a menudo la motivación política de tener "propiedad
física" de la base de datos. Muchos perciben esto como algo importante de cara a "poseer" y controlar los datos. Existe
también el deseo de desarrollar capacidad local para la administración del servidor relacionada con la sostenibilidad
del proyecto. Esto suele darse en iniciativas lideradas por donantes que perciben así la misión más concreta y servicial.
En cuanto a la segunda opción, en algunos lugares se construye un centro gubernamental de datos con la visión de
promover y mejorar el uso y acceso a los datos públicos. Otra razón puede ser que la proliferación de entornos internos
de servidos demanda muchos recursos y es más eficiente establecer una infraestructura y capacidad centralizadas.
Sobre el alojamiento externo, hay recientemente un movimiento hacia la externalización de la operación y
administración de recursos informáticos a proveedores externos, donde se accede a esos recursos a través de la red, en
lo que se llama popularmente "cloud computing" o "computación en la nube". Esos recursos generalmente se acceden
a través de Internet utilizando un navegador web.
El objetivo primordial de un despligue de servidor online es proporcionar un acceso estable a largo plazo y de alto
rendimiento a los servicios ofrecidos. Cuando decidamos qué opción elegir para un entorno de servidor, deberemos
considerar varios aspectos:
1. La capacidad humana de administración y operación del servidor. Debe haber personal con habilidades genéricas
para la administración de servidor y en las tecnologías específicas de la aplicación que provee servicios. Ejemplos
de estas tecnologías son los servidores web y las plataformas de gestión de bases de datos.
2. Soluciones fiables para copias de seguridad automatizadas, incluido un servidor local off y backup remoto.
3. Conectividad estable y buen ancho de banda para el tráfico hacia y desde el servidor.
4. Fuente de alimentación eléctrica estable, incluida una solución de backup.
5. Entorno seguro para el servirod físico en términos de acceso, robo y fuego.
6. Presencia de un plan de recuperación ante desastres. Este plan debe contener una estrategia realista para asegurar
que el servicio solo sufrirá caídas breves en los casos de fallo hardware, caída de la red y otros.
7. Hardware viable, potente y robusto.
Todos estos aspectos deben cubrirse para crear un entorno de alojamiento apropiado. El requisito hardware se ha puesto
en último lugar deliberadamente debido a que hay una tendencia clara a prestarle demasiada atención, habiendo otros
factores más cruciales.
Volviendo a las tres principales opciones de alojamiento, la experiencia de misiones de implementación en países en
desarrollo sugiere que los aspectos citados rara vez están presentes en las opciones uno y dos a nivel viable. Alcanzar
un nivel aceptable en todos esos aspectos es desafiante en términos de recursos humanos y dinero, especialmente
al comparar con la tercera opción. Tiene el beneficio de que acomoda los aspectos políticos mencionados y crea
capacidades locales para la administración de servidor, aunque por otro lado esto se puede lograr por otras vías.
La opción tres - alojamiento externo - tiene la ventaja de que soporta todos los aspectos mencionados a un coste
asequible. Muchos proveedores de hosting - de servidores virtuales o de servicios en la nube - ofrecen servicios fiables
para lanzar la mayoría de aplicaciones posibles. Un ejemplo de estos proveedores son los servidores web de Linode y
Amazon. La administración de esos servidores se realiza a través de una conexión de red, lo que sucede también muchas
veces en el caso de la administración de un servidor local. La ubicación física del sercidor en este caso es irrelevante ya
que esos proveedores ofrecen servicios en muchas partes del mundo. Esta solución se está convirtiendo en un estándar
para el alojamiento de los servicios de aplicaciones. El aspecto de crear capacidad local para la administración de
servidor es compatible con esta opción ya que un equipo local TIC puede asumir la tarea de mantenimiento del servidor
alojado externamente.
15
Estrategias de despliegue
Alojamiento de servidor
Una alternativa para combinar las ventajas del alojamiento externo con la necesidad de hosting local y propiedad física
es usar un proveedor de hosting externo para el sistema de transacción primario, y copiar (mirror) este servidor a un
servidor local no-crítico que se use para solo-lectura como el análisis de datos y que se acceda por una intranet.
16
DHIS 2 es un Data Warehouse
Data warehouse frente a sistemas funcionales
Capítulo 5. DHIS 2 es un Data Warehouse
En este capítulo se discute el rol y el lugar de la aplicación DHIS 2 en un contesto de arquitectura de sistema. Se
muestra que DHIS 2 puede servir la propósito tanto de un data warehouse como de un sistema funcional.
5.1. Data warehouse frente a sistemas funcionales
Un data warehouse, almacén de datos, suele entenderse como una base de datos utilizada para análisis. Típicamente
los datos se cargan desde diversos sistemas funcionales u transaccionales. Antes de que los datos se carguen en el
data warehouse pasan normalmente por varios estadíos donde se limpia de anomalías y redundancia y se transforma
para encajar en la estructura global de la base de datos integrada. Entonces, los datos se disponibilizan para el análisis,
también conocido como minería de datos y procesado analítico online. El diseño del almacén de datos está optimizado
para acelerar la entrega y análisis de datos. Para mejorar el funcionamiento, el almacenamiento de los datos suele ser
redundante en el sentido de que los datos se guardan tanto en su forma granular como agregada.
Un sistema transaccional (o sistema funcional desde la perspectiva de almacén de datos) es un sistema que recopila,
guarda y modifica datos de bajo nivel. Este sistema se usa generalmente en el día a día para la entrada y validación de
datos. Su diseño se optimiza para una inserción rápisa y rendimiento en la actualización.
Hay numerosos beneficios de mantener un data warehouse, tales como:
• Consistencia: Ofrece un modelo común de datos a todos los datos relevantes y actúa como abstracción sobre un
gran número de potenciales fuentes de datos y sistemas de alimentación, lo cual facilita mucho realizar el análisis.
• Fiabilidad: Está separado de las fuentes donde se originan los datos y por tanto no le afecta si se dañan o pierden
datos en los sistemas funcionales.
• Rendimiento de análisis: Está diseñado para el máximo rendimiento de devolución y análisis de datos en
comparación con sistemas funcionales, generalmente optimizados para la captura de los datos.
Sin embargo, hay también retos significativos en utilizar un data warehouse:
• Coste elevado: Hay un coste elevado asociado a mover los datos de varias fuentes a un almacén común de datos,
especialmente cuando los sistemas funcionales de origen no son de naturaleza similar. A menudo sistemas a largo
plazo (llamodos sistemas heredados) ponen fuertes restricciones al proceso de transformación de datos.
• Validez de los datos: El proceso de mover datos al data warehouse suele ser complejo y por tanto no se realiza
regularmente, en intervalos frecuentes. Esto deja a los usuarios de datos con datos obsoletos e irrelevantes
inadecuados para la planificación y la toma de decisiones informada.
Debido a las dificultades mencionadas, recientemente se ha hecho popular combinar las funciones de data warehouse y
de sistema funcional, bien en un único sistema que realiza ambas tareas o bien en sistemas integrados alojados juntos.
Con esta solución, el sistema tiene funcionalidades para captura de datos y validación, así como para análisis de datos
17
DHIS 2 es un Data Warehouse
Estrategia de agregación en DHIS 2
y gestiona el proceso de convertir datos atómicos de bajo nivel en fatos agregados adecuados para el análisis. Esto fija
grandes estándares para el sistema y su diseño, y debe ofrecer un rendimiento apropiada para ambas funciones; sin
embargo, los avances en hardware y en procesado paralelo hacen cada vez más viable este enfoque.
En este sentido, la aplicación DHIS 2 está diseñada para servir como herramienta tanto para la captura, validación,
análisis y presentación de los datos. Incluye módulos para todos estos aspectos, incluidas funcionalidades de entrada de
datos y un amplio abanico de herramientas de análisis como reportes, gráficas, mapas, tablas dinámicas y dashboard.
Además, DHIS 2 es parte de un grupo de sistemas de información en salud interoperable que cubre un amplio rango de
necesidades y que son todos software libre. DHIS 2 implementa el estándar para intercambio de datos y metadatos en
el ámbito de la salud llamado SDMX-HD. Hay muchos ejemplos de sistemas funcionales que también implementan
este estándar y potencialmente pueden incorporar datos a DHIS 2:
• iHRIS: Sistema de gestión de datos de recursos humanos. Ejemplos de datos que son relevantes a un almacén de
datos nacional, capturados por este sistema son "número de doctores", "número de enfermeros" y "número total de
personal". Estos datos son interesantes para comparar en base al desempeño por distrito.
• OpenMRS: Sistema de registro clínico utilizado en hospitales. Este sistema puede potencialemnte agregar y exportar
data sobre enfermedades de pacientes ingresados al data warehouse nacional.
• OpenELIS: Sistema de información de laboratorio. Este sistema puede generar y exportar datos de la cantidad y el
resultado de tests de laboratorio.
5.2. Estrategia de agregación en DHIS 2
Las herramientas de análisis en DHIS 2 leen datos agregados de las tablas datamart. Un datamart es un depósito de
datos optimizado para garantizar las peticiones más comunes de los usuarios para el análisis. El datamart en DHIS
2 contiene datos agregados en la dimensión espacial (la jerarquía de unidades organizativas), dimensión temporal
(en múltiples periodos) y para fórmulas de indicadores (las expresiones matemáticas que incorporan los elementos de
datos). Rescatar los datos directamente de datamarts da buen rendimiento incluso en entornos altamente concurrentes,
ya que la mayoría de las peticiones de análisis pueden servirse en una única petición simple a la base de datos contra
el datamart. El motor de agregación en DHIS 2 es capaz de procesar datos de bajo nivel del orden de muchos millones
y gestionar la mayor parte de bases de datos de nivel nacional, y puede decirse que ofrece acceso casi en tiempo real
para agregar los datos.
DHIS 2 permite configurar tareas programadas de agregación que típicamente se refrescan y propagan los datamart con
datos agregados cada noche. Podemos elegir entre agregar los datos de los últimos 12 meses cada noche, o agregar los
18
DHIS 2 es un Data Warehouse
La propuesta de almacenamiento de datos
datos de los últimos 6 meses cada noche y de los últimos 6 a 12 meses cada sábado. Las tareas programadas se pueden
configurar en "Agendar" en el módulo de "Administración de datos". También es posible ejecutar tareas arbitrarias de
datamart en "Datamart" en el módulo de "Reportes".
5.3. La propuesta de almacenamiento de datos
Hay dos propuestas líderes para almacenar datos en un datawarehouse, que son la normalizada y la dimensional.
DHIS 2 tiene un poco de la primera pero mucho de la segunda. En la propuesta dimensional los datos se particionan
en dimensiones y hechos. Generalmente los hechos se refieren a datos numéricos transaccionales, mientras las
dimensiones son los datos de referencia que dan contexto y significado a los datos. Las reglas estrictas de esta propuesta
facilitan que los usuarios comprendan la estructura de data warehouse y dan buenos resultados, ya que unas pocas
tablas pueden combinarse para producir análisis significativos, mientras por otro lado puede que hagan el sistema
menos flexible y difícil de cambiar.
En DHIS los hechos corresponden al objeto valor de los datos en el modelo de datos. El valor de los datos captura
los datos como números, sí/no o texto. Las dimensiones obligatorias que dan significado a los hechos son los
elementos de datos, la jerarquía de unidades organizativas y periodo. Estas dimensiones se dicen obligatorias porque
deben proporcionarse para todos los registros de datos almacenados. DHIS 2 también tiene un modelo dimensional
personalizable, que posibilita representar cualquier tipo de dimensionalidad. Este modelo debe definirse antes de la
captura de datos. DHIS 2 también tiene un modelo flexible de grupos y sets de grupos, que hace posible añadir
dimensionalidad personalizada a las dimensiones obligatorias después de que se haya realizado la captura de datos.
Podremos leer más sobre dimensionalidad en DHIS 2 en el capítulo del mismo nombre.
19
Capacitación de usuarios
Qué capacitación se necesita
Capítulo 6. Capacitación de usuarios
En este capítulo se cubren los temas siguientes:
• Qué capacitación se necesita
• Estrategias de formación
• Materiales y cursos
6.1. Qué capacitación se necesita
En un sistema extenso como es un sistema nacional de información de salud, hay diferentes roles para personas distintas.
Las diversas tareas suelen depender de dos factores: qué hará esa persona en el sistema (por ejemplo registrar datos,
analizarlos, mantener la base de datos..) y dónde estará esa persona (en un establecimiento de salud, en una oficina
distrital, a nivel nacional). Nuestra primera labor es entonces definir a los diferentes usuarios. Las tareas más comunes
son:
• Entrada de datos
• Procesado de análisis de datos, preparación de reportes y otros productos de información
• Mantenimiento de la base de datos - gestión de cambios en la base de datos
La entrada de datos normalmente está descentralizada en los niveles más bajos, como en los distritos. El procesado de
datos tiene lugar a todos los niveles, mientras el mantenimiento de la base de datos es centralizado. La siguiente tabla
da un ejemplo de los grupos de usuarios y qué tareas suelen tener:
Notemos que muchas de las tareas no están directamente ligadas al uso de DHIS 2. El análisis de datos, la garantía
de calidad de datos, la preparación de retroalimentación y la planificación de revisiones regulares son todas tareas
integrales de funcionamiento del sistema, y deben cubrirse en una estrategia educativa.
6.2. Estrategias de capacitación
Para cubrir el amplio abanico de tareas y usuarios listado arriba, es imprescindible plantear una estrategia de
capacitación. La mayoría de usuarios estarán en niveles bajos; introduciendo y usando los datos. Solo unos pocos
tendrán que conocer la base de datos en profundidad, generalmente a nivel nacional. Los siguientes son trucos útiles
para estrategias de capacitación a usuarios finales.
6.2.1. Formación de formadores
Dado que la cantidad de unidades y personal aumenta exponencialmente para cada nivel (un país puede tener provincias,
cada una con muchos distritos, cada una con muchos establecimientos), la formación de formadores es el primer paso.
El número de formadores puede variar dependiendo de la velocidad de implementación prevista. Como se describe a
continuación, ambos workshops y formaciones in-situ son útiles, y para esta última será necesaria mucha gente.
Los formadores deberían estar al menos al nivel de usuarios avanzados, para conocer cómo está diseñada la base de
datos, cómo isntalar y resolver problemas en DHIS2, y otros asuntos sobre epidemiología, como por ejemplo conceptos
útiles para monitoreo y evaluación de servicios de salud. A medida que las capacidades del personal aumentan, los
formadores también necesitarán actualizar sus habilidades.
6.2.2. Workshops y formación in-situ
La experiencia nos ha mostrado que la formación tanto en sesiones de workshops como en situaciones in-situ de trabajo
real son complementarias. Los workshops son mejores para formar a muchos al mismo tiempo, y son útiles para las
posteriores sesiones de capacitación. Preferentemente se debería capacitar al mismo tipo de usuarios.
21
Capacitación de usuarios
Formación continua
La formación in-sity tiene lugar en el lugar de trabajo del personal. Es útil haber realizado una sesión formativa
más organizada como un workshop anteriormente, de modo que la formación in-situ puede enfocarse en los asuntos
especiales de cada personal en particular. Un ejemplo podría ser una formación de distrito, donde los oficiales de
información en el distrito y el personal clínico de distrito sea capacitado conjuntamente. La comunicación entre
diferentes usuarios es importante en el sentido de que conforma un entendimiento común de qué se necesita y qué
es posible. La formación normalmente puede centrarse en requisitos locales como la generación de salida de datos
(reportes, gráficas, mapas) que sean útiles para el soporte a decisiones locales.
6.2.3. Formación continua
La formación no es algo separado. Una estrategia de formación en varios niveles pretendería proveer formación
regularmente a medida que las habilidades del personal mejoran. Por ejemplo, un workshop en entrada de datos y
validación debería seguirse de otro workshop en generación de reportes y análisis de datos. También deberá ofrecerse
formación regular a personal de nueva incorporación, y cuando se realicen cambios grandes en el sistema, como el
rediseño de todos los formularios de recolección de datos.
6.3. Materiales y cursos
Hay material disponible para formación y cursos en inglés y también en español. La fuente principal son los tres
manuales disponibles en el repositorio de documentación de DHIS2, que puede encontrarse aquí.
La documentación de usuario cubre el origen y propósito de DHIS2 junto con instrucciones y explicaciones sobre cómo
realizar la entrada de datos, el mantenimiento del sistema, la configuración de metadatos, importación y exportación de
datos, agregación, reportes y otros temas relacionados con el uso del software. La documentación de desarrolladores
cubre la arquitectura técnica, diseño de cada módulo y uso de las plataformas de desarrollo detrás de DHIS2. La guía
de implementación está enfocada a implementadores y superusuarios, y trata materias como el diseño del sistema,
el desarrollo de la base de datos, la armonización de datos, análisis, despliegue, recursos humanos necesarios y la
integración con otros sistemas. El manual de usuario final es una versión ligera de la documentación de usuario pensada
para usuarios como los digitadores distritales y el personal de registro de datos. Todos ellos pueden abrirse y descargarse
como PDF y HTML, y se actualizan diariamente con la versión más reciente de los usuarios de DHIS2 a nivel mundial.
La elaboración de estas guías depende de la contribución de todos los usuarios. Para información sobre cómo añadir
contenido, seguiremos el apéndice de documentación en la Documentación de Usuario. Ahí encontramos también
información sobre cómo generar documentación localizada, incluido versionado en diferentes idiomas.
Desde 2011, los workshops regionales y cursos se realizan al menos una vez al año por la comunidad DHIS2. El objetivo
es tener equipos técnicos nacionales trabajando en la personalización e implementación de DHIS2. Las sesiones
también incluyen formación y construcción de capacidades de estos equipos en el país. La formación a usuarios finales,
por ejemplo la formación de oficiales de distrito clínicos y digitadores, deberían hacerla estos equipos en cada país.
22
Integración
Integración e interoperabilidad
Capítulo 7. Integración
Este capítulo trata los temas siguientes:
• Integración e interoperabilidad
• Beneficios de la integración
• ¿Qué facilita la integración y la interoperabilidad?
• Arquitectura de un SIS interoperable
A continuación cada tema se discute en detalle.
7.1. Integración e interoperabilidad
En un país normalmente hay muchos sistemas de información de salud diferentes y aislados. Las razones de que esto sea
así son diversas, tanto técnicas como organizativas. Aquí pondremos el foco en qué beneficios puede traer la intefración
de estos sistemas, y por qué esto debería ser prioritario. Antes de empezar, algunas aclaraciones:
• Cuando hablamos de integración, pensamos en el proceso de hacer que diferentes sistemas de información parezcan
uno solo, es decir, que los datos de cada uno de ellos estén disponibles para todos los usuarios relevantes así como que
haya armonía entre las definiciones y dimensiones dadas de modo que sea posible combinar los datos de manera útil.
• Un concepto relacionado es la interoperabilidad, que es una estrategia para alcanzar la integración. A propósito
de DHIS 2, decimos que es interoperable con otras aplicaciones software si es capaz de compartir datos ellas. Por
ejemplo, DHIS2 y OpenMRS son interoperables porque ambas tienen el soporte para compartir definiciones de datos
y datos propiamente dichos entre ellas.
Entonces, para decir que algo es integrado significa que comparten algo y que están disponibles desde un mismo lugar,
mientras que interoperabilidad normalmente quiere decir que son capaces de hacer esta compartición electrónicamente.
DHIS2 suele usarse como un data warehouse integrado, ya que contiene datos (agregados) procedentes de diversas
fuentes, como Salud Materno-infantil, Programa de Malaria, datos censales, y datos de stocks y recursos humanos. Estas
fuentes de datos comparten la misma plataforma, DHIS2, y están disponibles desde el mismo lugar. Estos subsistemas
se consideran por tanto integrados en un solo sistema. La interoperabilidad podrá ser una manera útil de integrar también
fuentes de datos disponibles en otras aplicaciones software. Por ejemplo, si los datos censales se guardan en alguna
otra base de datos, la interoperabilidad entre esta base de datos y DHIS2 significaría que los datos censales estarán
accesibles en ambas (aunque almacenados en un único lugar).
7.2. Beneficios de la integración
Hay muchos beneficios potenciales relacionados con la integración de sistemas. Los más importantes son:
• Cálculo de indicadores: muchos indicadores se basan en numeradores y denominadores de diferentes fuentes de
datos. Algunos ejemplos incluyen tasas de mortalidad, con algunos datos de mortalidad como numerador y datos
poblacionales como denominador, cobertura de personal y tasas de carga de trabajo del personal (datos de recursos
humanos, y datos de población y de plantilla), tasas de inmunización y similares. Para que estos sean calculados,
necesitamos ambos datos de numerador y denominador, y por tanto deberían estar integrados en un único data
warehouse. Cuanto mayor sea el número de fuentes de datos que estén integradas, mayor cantidad de indicadores
podrán generarse desde el repositorio central.
• Reducción del procesado y entrada manual de datos: con diferentes datos en el mismo lugar, no hay necesidad
de extraer y procesar los indicadores manualmente, o de reinsertar los datos en el data warehouse. Especialmente
la interoperabilidad entre sistemas de diferentes tipos de datos (como registros de pacientes y almacenes de datos
agregados) permite que los softwares de los subsistemas calculen y compartan datos electrónicamente. Esto reduce la
cantidad de pasos manuales implicados en el procesado de datos, lo que contribuye a mejorar la calidad de los datos.
• Hay razones organizativas para la integración. Si todos los datos pueden manejarse desde una unidad del Ministerio
de Salud, en lugar de tener varios subsistemas mantenidos por los programas de salud, esta unidad puede
23
Integración
Qué facilita la integración y la
interoperabilidad
profesionalizarse. Con personal que tiene como única responsabilidad la gestión, procesado y análisis de datos,
pueden desarrollarse habilidades más especializadas y se puede racionalizar el manejo de información.
7.3. Qué facilita la integración y la interoperabilidad
Para este fin, hay que avanzar en tres niveles:
• La motivación y voluntad de integrar (a nivel organizativo)
• Las definiciones estándar (a nivel lingüístico)
• El estándar de almacenamiento e intercambio electrónico (a nivel técnico)
El primer nivel es un tema recurrente en esta guía, y toma como punto de partida que se ha tomado ya una decisión
sobre la integración de datos. Sin embargo, es un asunto importante y normalmente el más complejo de resolver dado
el rango de actores involucrados en el sector salud. Unas políticas nacionales claras sobre la integración de datos, la
propiedad de los datos, las rutinas de recolección, procesado y compartición de datos, deberían fijarse para atender esta
cuestión. A menudo puede producirse algún periodo de alteración del flujo normal de datos, así que debería juzgarse
la perspectiva a laro plazo de un sistema más eficiente frente a esta alteración a corto plazo. La integración es por tanto
un proceso por pasos, donde hay que medir bien para que el proceso sea lo más suave posible.
A nivel de lenguaje, hay una necesidad de consistencia en las definiciones. Si tenemos dos fuentes de datos para
los mismos datos, deben poder compararse. Por ejemplo, si recogemos datos de malaria de clínicas estándar y de
hosppitales, estos datos deberán describir lo mismo si necesitamos combinarlos para cantidades totales e indicadores.
Si un hospital está reportando casos de malaria por sexo pero no por edad, y otras clínicas están reportando por grupo
de edad pero no por sexo, estos datos no se pueden analizar de acuerdo a ninguna de estas dimensiones, aunque es
posible calcular el número total de casos. Entonces, es preciso acordar definiciones uniformes.
Además de las definiciones uniformes en varios subsistemas, hay que adoptar estándares de intercambio de datos si
los datos se comparten electrónicamente. Las diversas aplicaciones software necesitarán esto para poder entenderse
mutuamente. DHIS2 soporta varios formatos de importación y exportación de datos, pero existe un formato estándar
soportado por la OMS que se llama SDMX-HD (Statistical Data and Metadata Exchange - Health Domain). También
otras aplicaciones software lo sopoertan, y esto permite la compartición de definiciones de datos y agregar datos entre
ellas. Para DHIS2, esto quiere decir que puede importar datos agregados proporcionados por otras aplicaciones, como
OpenMRS (para la gestión de pacientes) e iHIS (para la gestión de recursos humanos).
7.4. Arquitectura de SIS interoperables
Dado que hay muchos casos de uso distintos de información de salud, tales como monitoreo y evaluación, presupuesto,
gestión y seguimiento de pacientes, gestión logística, seguros, gestión de recursos humanos, et, hay muchos tipos de
aplicaciones software que funcionan en el Sector Salud. Más allá del tema de abordar la interoperabilidad y planificar
o tener una visión de las diversas aplicaciones software interoperables y sus características específicas, y la cuestión
de qué datos deberían compartir entre sí, está el tema de construir una arquitectura para la información de salud.
El rol de la arquitectura es hacer las veces de plan de coordinación del desarrollo e interoperabilidad de los diversos
subsistemas que hay en un sistema amplio de información de salud. Es recomendable elaborar un plan para los varios
componentes incluso si todavía no está funcionando ningún software, para ser capaces de ver adecuadamente los
requisitos de compartición de datos. Estos requisitos deberían ser parte de cualquier especificación del software que
se desarrolle o compre con este propósito.
A continuación hay una ilustración sencilla de una arquitectura, con un foco en el data warehouse para datos
agregados. Las diversas cajas representan casos de uso, como la gestión logística, el seguimiento de pacientes de TB,
la gestión general de pacientes, etc. Todos estos compartirán datos agregados con DHIS2. Notemos que las flechas
son bidireccionales, porque hay también una sincronización de metadatos (definiciones), para asegurarnos de que
se comparten los datos correctos. También se muestra un ejemplo de aplicaciones de datos logísticos y financieeros
compartiendo datos, ya que hay fuertes vínculos entre la adquisición de medicamentos y la gestión del presupuesto
para ello. Hay muchas instancias de compartición de datos; la arquitectura nos ayuda a planificar mejor que esto se
implemente como un ecosistema creciente de aplicaciones software.
24
Integración
Arquitectura de SIS interoperables
25
Instalación
Montaje del servidor
Capítulo 8. Instalación
El capítulo de instalación proporciona información sobre cómo instalar DHIS 2 en diversos contextos, incluidos un
servidor central online, una red local offline, una aplicación independiente y un paquete autocontenido denominado
DHIS 2 Live.
DHIS 2 funciona en toda plataforma para la cual exista una versión 6 o superior del Entorno de Ejecución de Java
(Java Runtime Environment), lo que incluye los sistemas operativos más populares como son Windows, Linux y
Mac. DHIS 2 funciona con sistemas de bases de datos relacionales como PostgreSQL, MySQL, H2 y Derby. DHIS
2 está empaquetado como un fichero estándar Java Web Archive (fichero WAR) y por tanto se ejecuta en cualquier
contenedor Servlet como Tomcat o Jetty.
El equipo DHIS 2 recomienda el sistema operativo Ubuntu 12.04 LTS, el sistema de base de datos PostgreSQL y el
contenedor Servlet Tomcat como el entorno preferido para las instalaciones en servidor. Los sistemas mencionados
pueden considerarse líderes de mercado en sus respectivos dominios y han sido probados intensivamente durante
muchos años.
Este capítulo ofrece una guía para montar la citada pila de tecnologías (Ubuntu-PostgreSQL-Tomcat). Sin embargo,
esta guía debe leerse como un itinerario para montar y poner en marcha DHIS 2, y no como una documentación
exhaustiva sobre el entorno mencionado. Para una lectura en profundidad, recomendamos seguir la documentación
oficial de Ubuntu, PostgreSQL y Tomcat.
8.1. Montaje del servidor
Esta sección describe cómo montar una instancia de servidor de DHIS 2 en Ubuntu 12.04 64 bit con PostgreSQL
como sistema de base de datos y con Tomcat como contenedor Servlet. El término invocar indica la ejecución de un
determinado comando en el terminal.
Para un servidor nacional los requisitos hardware son un procesador quad-core 2GHz o superior y 12GB de RAM o
superior. Nótese que se requiere un sistema operativo de 64 bits para utilizar más de 4 GB de RAM, por lo que se
recomienda la edición Ubuntu 12.04 de 64 bits.
En esta guía asumiremos que 4 GB se asignan a PostgreSQL y 7GB de RAM se asignan a Tomcat. ¡Si estás utilizando
una configuración distinta por favor ajusta los valores sugeridos en consecuencia!. Los pasos que marcaremos como
opcional, como el paso de ajuste de rendimiento, pueden realizarse en un momento posterior.
Crear nuevo usuario (opcional)
Tal vez queramos crear un usuario dedicado para ejecutar DHIS - no es recomendable ejecutarlo como usuario root.
Creamos un nuevo usuario llamado dhis invocando useradd -d /home/dhis -m dhis -s /bin/bash
A continuación habilitamos al usuario para realizar operaciones como root temporalmente invocando adduser dhis
admin
Si no hay grupo admin en el sistema, crearemos dicho grupo primero invocando groupadd admin
Después invocamos passwd dhis para fijar la contraseña de esta nueva cuenta de usuario. Nos aseguraremos de
poner una contraseña fuerte con al menos 15 caracteres aleatorios.
Tal vez queramos deshabilitar el login remoto para la cuenta de root, logrando así mayor seguridad, invocando sudo
passwd -l root
Ajuste del núcleo del sistema operativo
Estas configuraciones son opcionales excepto para la configuración de la memoria compartida, que es un requisito para
la asignación de memoria para PostgreSQL. Abrimos el fichero de configuración del núcleo o kernel invocando sudo
nano /etc/sysctl.conf Al final del fichero añadiremos las líneas siguientes y guardaremos el fichero.
27
Instalación
Montaje del servidor
kernel.shmmax = 1073741824
net.core.rmem_max = 8388608
net.core.wmem_max = 8388608
Hacemos que los cambios tengan efecto invocando sudo sysctl -p
Instalar Java
Instalamos Java invocando lo siguiente:
sudo apt-get install openjdk-7-jdk
sudo update-alternatives --install /usr/bin/java java /usr/lib/jvm/java-7-openjdk/bin/java 1
sudo update-alternatives --set java /usr/lib/jvm/java-7-openjdk/bin/java
A continuación es importante chequear que la ruta de los binarios de Java es correcta, ya que puede cambiar de un
sistema a otro, por ejemplo en sistemas AMD podríamos encontrar algo como ../java-7-openjdk-amd64/... Chequeamos
a continuación que nuestra instalación está bien invocando java -version
Instalar PostgreSQL
Instalamos PostgreSQL invocando sudo apt-get install postgresql-9.1
Cambiamos al usuario de postgres invocando sudo su postgres
Creaamos ahora un usuario sin privilegios llamado dhis invocando createuser -SDRP dhis Introducimos una
contraseña segura cuando aparece el prompt. Creamos una base de datos invocando createdb -O dhis dhis2
Regresamos a nuestra sesión de usuario invocando exit
Ahora ya tenemos un usuario PostgreSQL llamado dhis y una base de datos llamada dhis2.
Continuamos ajustando el rendimiento abriendo el fichero siguiente invocando
sudo nano /etc/postgresql/9.1/main/postgresql.conf
y fijando las propiedades siguientes:
shared_buffers = 512MB
Esto determina cuánta memoria PostgreSQL puede utilizarse para almacenar datos de consultas. Se ajusta muy pequeña
por defecto porque depende de la memoria compartida del núcleo, que es reducida en algunos sistemas operativos.
effective_cache_size = 3500MB
Es una estimación de cuánta memoria está disponible para almacenar (no para asignar) y es usada por PostgreSQL para
determinar si un plan de consultas se adecuará a la memoria o no (aquí una configuración demasiado grande podría
resultar en un comportamiento impredecible y lento).
checkpoint_segments = 32
PostgreSQL graba las nuevas transacciones en un fichero de log llamado WAL en segmentos de tamaño 16MB. Cuando
se graba una cantidad de segmentos dada sucede un checkpoint. Configurar esta cifra en un valor mayor nos permite
por tanto mejorar el rendimiento de sistemas de escritura pesada como DHIS 2.
checkpoint_completion_target = 0.8
Determina el porcentaje de segmentos completos antes de que aparezca un checkpoint. Fijar este número en un valor
alto amplía por tanto la transcripción y reduce la sobrecarga de escritura promedio.
wal_buffers = 4MB
28
Instalación
Montaje del servidor
Fija la memoria utilizada para buffer durante el proceso de escritura WAL. Aumentar este valor puede mejorar el
rendimiento en sistemas de escritura pesada.
synchronous_commit = off
Especifica si las asignaciones de transacción van a esperar a que se escriban los registros WAL en el disco antes de
regresar al cliente o no. Fijar esto en off mejora el rendimiento considerablemente. También implica que habrá un
pequeño retardo entre la transacción reportada con éxito al cliente y que esté realmente guardada, pero el estado de la
base de datos no puede corromperse y es una buena alternativa en sistemas de producción intensiva y escritura pesada
como DHIS 2.
wal_writer_delay = 10000ms
Especifica el retraso entre operaciones de escritura WAL. Fijar esto a un valor grande mejora el rendimiento en sistemas
de escritura pesada ya que potencialmente pueden ejecutarse muchas operaciones de escritura en un único envío al
disco.
Reiniciar PostgreSQL invocando sudo /etc/init.d/postgresql restart
Fijar la configuración de la base de datos
La información de conexión de la base de datos llega a DHIS 2 a través de un fichero de configuración llamado
hibernate.properties. Creamos este fichero y lo guardamos en una ubicación adecuada. El fichero correspondiente al
montaje anterior tiene las siguientes propiedades:
hibernate.dialect = org.hibernate.dialect.PostgreSQLDialect
hibernate.connection.driver_class = org.postgresql.Driver
hibernate.connection.url = jdbc:postgresql:dhis2
hibernate.connection.username = dhis
hibernate.connection.password = xxxx
hibernate.hbm2ddl.auto = update
Un error frecuente es dejar un espacio en blanco después del último valor de propiedad - asegúrate de que no hay
espacios en blanco al final de ninguna línea en este fichero. También debemos recordar que este fichero contiene la
contraseña en claro de nuestra base de datos dhis2 de modo que deberemos protegerlo de accesos no autorizados.
Para hacer esto invocamos chmod 0600 hibernate.properties que garantiza que solo el usuario dhis que es
propietario del fichero puede leer o escribir en él.
Instalar Tomcat
Descarga la distribución binaria de Tomcat de http://tomcat.apache.org/download-70.cgi. Una herramienta útil para
descargar ficheros desde la web es wget. Extraemos el fichero en una ubicación adecuada. Esta guía asume que hemos
navegado al directorio root del fichero extraido.
Limpiamos las aplicaciones web preinstaladas invocando rm -rf webapps/* Descargamos el último fichero WAR
de DHIS 2 desde http://dhis2.org/download, lo movemos al directorio webapps y lo renombramos como ROOT.war
Abrimos el fichero bin/setclasspath.sh y añadimos las líneas que siguen. Lo primero será fijar la ubicación de nuestro
Java Runtime Environment, lo segundo será dedicar memoria a Tomcat y lo tercero será fijar la ubicación en la que
DHIS 2 buscará el fichero de configuración hibernate.properties. Es importante aquí que chequeemos que la ruta a la
ubicación del JDK es correcta. Notemos que deberemos ajustar esto a nuestro entorno:
export JAVA_HOME='/usr/lib/jvm/java-7-openjdk'
export JAVA_OPTS='-Xmx6000m -Xms3000m -XX:MaxPermSize=800m -XX:PermSize=400m'
export DHIS2_HOME='/home/dhis/config'
Si necesitamos cambiar el puerto en el que Tomcat escucha las peticiones, podemos abrir el fichero de configuración de
Tomcat /conf/server.xml, encontrar el elemento <Connector> que no está comentado y cambiar el valor de su atributo
puerto por el número de puerto deseado.
El log será nuestra primera fuente de información cuando queramos monitorear el comportamiento de Tomcat.
Podemos ver fácilmente el log invocando tail -f logs/catalina.out
29
Instalación
Configuración de proxy inverso
Ejecutar DHIS 2
Para terminar haremos ejecutable el script de arranque invocando chmod 755 bin/* Ahora podemos arrancar
DHIs 2 invocando bin/startup.sh Podemos monitorear el log invocando tail -f logs/catalina.out
Podemos detener DHIS 2 invocando bin/shutdown.sh Finalemente, asumiendo que el fichero WAR se llama ahora
ROOT.war, podemos acceder a nuestra instancia DHIS a través del navegador web en http://localhost:8080.
8.2. Configuración de proxy inverso
Un proxy inverso es un servidor proxy que funciona en representación de un servidor. Utilizar un proxy inverso
combinado con un contenedor Servlet es algo opcional en DHIS, pero tiene numerosas ventajas:
• Las peticiones pueden mapearse y ser pasadas a múltiples contenedores Servlet - esto hace el sistema más flexible
y facilita la ejecución de múltiples instancias de DHIS en el mismo servidor. También posibilita que cambiemos la
configuración interna del servidor sin que ello repercuta a los clientes.
• La aplicación DHIS puede funcionar como un usuario no root en un puerto distinto del 80, lo que limita las
consecuencias de un ataque de suplantación de sesión.
• El proxy inverso puede funcionar como un solo servidor SSL y podemos configurarlo para inspeccionar las
peticiones en busca de contenido malicioso, peticiones y respuestas de log y también proporcionar mensajes de error
no sensibles mejorando la seguridad en general.
8.2.1. Instalación básica de nginx
Recomendamos utilizar nginx (http://wiki.nginx.org) como proxy inverso debido a su reducida huella de memoria y a
su facilidad de uso. Para obtener la versión más actualizada recomendamos su instalación desde las fuentes:
sudo apt-get install make gcc libpcre3 libpcre3-dev zlibc zlib1g zlib1g-dev libssl-dev openssl
wget http://nginx.org/download/nginx-1.0.14.tar.gz
tar xzvf nginx-1.0.14.tar.gz
cd nginx-1.0.14
/configure --with-http_ssl_module
make
sudo make install
Ahora podemos iniciar y detener nginx con los comandos siguientes:
sudo /usr/local/nginx/sbin/nginx
sudo /usr/local/nginx/sbin/nginx -s stop
Ahora que hemos instalado nginx continuaremos configurando el proxy regular de peticiones a nuestra instancia de
Tomcat, que asumimos que se ejecuta en http://localhost:8080. Para configurar nginx podemos abrir el fichero de
configuración invocando:
sudo nano /usr/local/nginx/conf/nginx.conf
La configuración de nginx se monta en torno a una jerarquía de bloques que incluye http, servidor y ubicación,
donde cada bloque hereda los parámetros configurados en los bloques padre. El código siguiente configura nginx
para pasar por proxy (redireccionar) las peticiones del puerto 80 (que es el puerto que nginx escucha por defecto) a
nuestra instancia de Tomcat. Con esto también conseguimos que nginx sirva peticiones de contenido estático como son
javascript, hojas de estilo e imágenes, e instruya a los clientes para guardarlas en caché durante 4 días, de modo que
se reduce la carga de Tomcat y se mejora el rendimiento en general. Por eso, añadiremos la configuración siguiente
en el fichero nginx.conf:
server {
listen
80;
client_max_body_size 10M; # Default 1M, change it!
30
Instalación
Habilitando SSL en nginx
# Serve static content
# Root points to your DHIS webapp location, update it!
location ~ (\.js$|\.css$|\.gif$|\.woff$|\.ttf$|\.eot$|^/images/|^/icons/|^/dhis-web-commons/.*\
root
/home/dhis/tomcat/webapps/ROOT;
expires 4d;
}
# Proxy pass to servlet container
location / {
proxy_pass
proxy_redirect
proxy_set_header
proxy_set_header
proxy_set_header
}
http://localhost:8080/;
off;
Host
$host;
X-Real-IP
$remote_addr;
X-Forwarded-For $proxy_add_x_forwarded_for;
}
Ahora podemos acceder a nuestra instancia DHIS en http://localhost. Ahora que el proxy inverso ya está funcionando,
podemos mejorar la seguridad del sistema haciendo que Tomcat solo escuche conexiones locales. En el fichero /conf/
server.xml podemos añadir un atributo de dirección: address, con el valor de localhost al elemento Connector de HTTP
1.1 de la siguiente manera:
<Connector address="localhost" protocol="HTTP/1.1" ... >
Importante
El bloque de ubicación para contenido estático es esencial, ya que los navegadores web no cachean contenido
estático por defecto sobre SSL. Solo cachean este tipo de contenido en el lado del cliente si el servidor web
lo indica explícitamente.
8.2.2. Habilitando SSL en nginx
Para mejorar la seguridad es recomendable configurar el servidor donde funciona DHIS para que se comunique con
los clientes mediante una conexión encriptada y para identificarse con los clientes mediante un certificado válido. Esto
es posible utilizando SSL, que es un protocolo de comunicación criptográfica que funciona sobre TCP/IP.
Para configurar nginx de manera que utilice SSL, necesitaremos un certificado SSL apropiado emitido por un proveedor
SSL. El coste del certificado depende enormemente de la fortaleza del encriptado. Un certificado asequible de Rapid
SSL Online debería ser suficiente para la mayoría de propósitos. Para generar la petición de firma del certificado
(CSR, certificate signing request) podemos invocar el comando siguiente. Cuando se nos pregunta por Common Name,
introduciremos el nombre de dominio completo para el sitio web que queremos asegurar.
openssl req -new -newkey rsa:2048 -nodes -keyout server.key -out server.csr
Una vez tenemos nuestros ficheros de certificado (.pem y .key) necesitaremos colocarlos en una ubicación que sea
accesible por nginx. Una buena ubicación para esto puede ser el mismo directorio donde se encuentra el fichero
nginx.conf.
A continuación se muestra un bloque de un servidor nginx donde los ficheros de certificado son server.crt y server.key.
Dado que las conexiones SSL generalmente aparecen en el puerto 443 (HTTPS), pasamos las peticiones de ese puerto
(443) a la instancia DHIS que está funcionando en http://localhost:8080. El primer bloque de servidor reescribirá todas
las peticiones que conectan al puerto 80 y forzará el uso de HTTPS/SSL. Debemos recordar reemplazar <server-ip>
con la IP de nuestro servidor. Estos bloques deberán reemplazar el bloque que vimos en la sección anterior.
# Rewrite block to force use of SSL
server {
listen
rewrite
80;
^ https://<server-ip>$request_uri? permanent;
31
Instalación
Scripts de control para nginx
}
# SSL server block
server {
listen
443;
client_max_body_size 10M;
ssl
ssl_certificate
ssl_certificate_key
on;
server.crt;
server.key;
ssl_session_timeout
5m;
ssl_protocols
ssl_ciphers
ssl_prefer_server_ciphers
SSLv2 SSLv3 TLSv1;
HIGH:!aNULL:!MD5;
on;
# Root points to your DHIS webapp location, update it!
location ~ (\.js$|\.css$|\.gif$|\.woff$|\.ttf$|\.eot$|^/images/|^/icons/|^/dhis-web-commons/.*\
root
/home/dhis/tomcat/webapps/ROOT;
expires 4d;
}
location / {
proxy_pass
proxy_redirect
proxy_set_header
proxy_set_header
proxy_set_header
http://localhost:8080/;
off;
Host
$host;
X-Real-IP
$remote_addr;
X-Forwarded-For $proxy_add_x_forwarded_for;
}
}
8.2.3. Scripts de control para nginx
En determinadas situaciones puede suceder que un servidor se reinicie inesperadamente. Por eso es preferible que
Tomcat y nginx arranquen automáticamente cuando el servidor arranca. Para lograr esto, lo primero es crear scripts
de inicialización: init. Crearemos un fichero nuevo llamado tomcat y pegaremos en él el contenido que se muestra a
continuación (es importante que ajustemos la variable HOME a nuestro entorno):
#!/bin/sh
#Tomcat init script
HOME=/home/dhis/tomcat/bin
case $1 in
start)
sh ${HOME}/startup.sh
;;
stop)
sh ${HOME}/shutdown.sh
;;
restart)
sh ${HOME}/shutdown.sh
sleep 5
sh ${HOME}/startup.sh
;;
esac
exit 0
Crearemos también un nuevo fichero llamado nginx y pegaremos en él el contenido siguiente:
32
Instalación
Colocar recursos disponibles con nginx
#!/bin/sh
#nginx init script
DAEMON=/usr/local/nginx/sbin/nginx
case $1 in
start)
start-stop-daemon
;;
stop)
start-stop-daemon
;;
restart)
start-stop-daemon
sleep 1
start-stop-daemon
;;
esac
exit 0
--start --exec $DAEMON
--stop --exec $DAEMON
--stop --exec $DAEMON
--start --exec $DAEMON
Moveremos ambos scripts al directorio de scripts init y los convertiremos en ejecutables invocando:
sudo mv tomcat nginx /etc/init.d
sudo chmod +x /etc/init.d/nginx /etc/init.d/tomcat
A continuación comprobaremos que los scripts serán invocados durante el encendido y apagado del sistema:
sudo /usr/sbin/update-rc.d -f nginx defaults 80
sudo /usr/sbin/update-rc.d -f tomcat defaults 81
Ahora Tomcat y nginx se iniciarán cuando el servidor arranque y se detendrán cuando el sistema se apague. Si
posteriormente necesitamos revertir esto, podremos reemplazar defaults por remove e invocar los comandos
anteriores de nuevo.
8.2.4. Colocar recursos disponibles con nginx
Hacer los recursos disponibles públicamente
En algunos escenarios es deseable que determinados recursos estén disponibles públicamente en la Web sin necesidad
de autenticación. Un ejemplo de esto es cuando queremos poner recursos del API Web relacionados con el análisis
de datos disponibles en un portal Web. El siguiente ejemplo permitirá acceso a gráficas, mapas, reportes, tablas de
reportes y recursos de documentos mediante una autenticación básica e insertando una cabecera HTTP de Autorización
en la petición. Esto eliminará la cabecera de "Cookie" de la petición y la cabecera "Set-Cookie" de la respuesta
para evitar cambiar el usuario logueado actualmente. Es recomendable crear un usuario específico para este fin, al
que demos solo las mínimas autorizaciones requeridas. El valor de Autorización puede construirse codificando en
Base64 el nombre de usuario seguido de dos puntos y de la contraseña, y anteponiendo "Basic" a todo, concretamente
"Basic base64_encode(username:password)". De este modo chequeará el método HTTP utilizado para las peticiones
y devolverá 405 Método no permitido si detecta algo diferente de GET.
location ~ ^/api/(charts|maps|reports|reportTables|documents)/ {
if ($request_method != GET) {
return 405;
}
proxy_pass
proxy_redirect
proxy_set_header
proxy_set_header
proxy_set_header
proxy_set_header
proxy_set_header
proxy_hide_header
http://localhost:8080;
off;
Host
$host;
X-Real-IP
$remote_addr;
X-Forwarded-For
$proxy_add_x_forwarded_for;
Authorization
"Basic YWRtaW46ZGlzdHJpY3Q=";
Cookie
"";
Set-Cookie;
33
Instalación
Configuración básica de proxy inverso con
Apache
}
8.2.5. Configuración básica de proxy inverso con Apache
El servidor Apache HTTP es el más común.
Importante
Utilizar nginx es la opción preferida de proxy inverso con DHIS2 y no deberíamos tratar de instalar nginx y
Apache en el mismo servidor. Si hemos instalado nginx deberemos ignorar esta sección.
El servidor Apache HTTP es el tipo de servidor HTTP más utilizado en la actualidad. Dependiendo de la naturaleza
exacta de nuestro despliegue, puede que necesitemos usar Apache como proxy inverso en nuestro servidor DHIS2. En
esta sección describiremos cómo implementar una configuración sencilla de proxy inverso con Apache.
Primero necesitamos instalar unos pocos módulos de programas para Apache y habilitarlos.
sudo apt-get install apache2 libapache2-mod-proxy-html libapache2-mod-jk
a2enmod proxy proxy_ajp proxy_connect
Definiremos un conector AJP que el servidor Apache HTTP utilizará para conectarse con Tomcat. El fichero
server.xml de Tomcat debería estar ubicado en el directorio /conf/ de nuestra instalación Tomcat. Tendremos que
asegurarnos de que esta línea no está comentada (podemos fijar el puerto a donde queramos que esté libre):
<Connector port="8009" protocol="AJP/1.3" redirectPort="8443" />
Ahora, necesitamos hacer los ajustes en el servidor Apache HTTP que generará respuestas en el puerto 80 y las pasará
al servidor Tomcat a través de un conector AJP. Editaremos el fichero /etc/apache2/mods-enabled/proxy.conf
de modo que se asemeje al ejemplo siguiente. Nos aseguraremos de que el puerto definido en el fichero de configuración
coincide con el de Tomcat.
<IfModule mod_proxy.c>
ProxyRequests Off
ProxyPass /dhis ajp://localhost:8009/dhis
ProxyPassReverse /dhis ajp://localhost:8009/dhis
<Location "/dhis">
Order allow,deny
Allow from all
</Location>
</IfModule>
ahora podemos reiniciar Tomcat y el servidor Apache HTTP, y entonces nuestra instancia DHIS2 está accesible en
http://miservidor/dhis donde miservidor es el nombre de dominio de nuestro servidor.
8.2.6. Balanceo de carga básico con Apache y Tomcat
El balanceo de carga puede emplearse para distribuir la carga del sistema de forma más equilibrada entre las múltiples
instancias de Tomcat, en situaciones en las que el tráfico de los usuarios es demasiado grande para ser cubierta por una
sola instancia de servidor. En este ejemplo, crearemos una arquitectura sencilla balanceada utilizando "sticky sessions"
para distribuir a los usuarios entre dos instancias de Tomcat.
En primer lugar, necesitamos al menos dos instancias de Tomcat ejecutando DHIS2, que estén conectadas a la misma
base de datos. Hay varias arquitecturas posibles, como ejecutar los servidores de aplicación (Tomcat) en máquinas
separadas (virtuales) conectadas a un único servidor de bases de datos, o como ejecutar múltiples instancias de Tomcat
y una base de datos en una máquina de gran capacidad en situaciones en las que no hay problemas de entrada/sailda,
pero cuando el uso de CPU de una instancia de Tomcat limita el rendimiento total del sistema. En este escenario,
configuraremos para conectar dos instancias Tomcat funcionando en la misma máquina con una única base de datos
34
Instalación
Encriptado básico SSL con Apache
mediante un proxy inverso balanceado. Apache se ocupará de los detalles de definir qué instancia de Tomcat responde
a cada cliente particular.
El primer paso es configurar nuestras instancias Tomcat. Las secciones previas han detallado cómo podemos hacer
esto. Es importante recordar que ambas instancias Tomcat deberían estar configuradas para utilizar el mismo servidor
de base de datos. Algunas modificaciones necesitan hacerse en el fichero server.xml para cada instancia de Tomcat, que
se utilizará para identificar de forma única cada instancia. Deberíamos extraer dos copias de Tomcat en el directorio
que escojamos. Modificaremos el fichero server.xml de modo que las líneas siguientes sean únicas para cada instancia:
<Server port="8005" shutdown="SHUTDOWN">
...
<Connector port="8009" protocol="AJP/1.3" redirectPort="8444" />
...
<Engine name="Catalina" defaultHost="localhost" jvmRoute="jvm1">
Aquí los parámetros importantes son el puerto de servidor, el puerto de conector AJP, y el identificador jvmRoute. El
identificador jvmRoute se adjuntará al JSESSIONID de manera que Apache sabrá qué instancia de Tomcat debe ser
enrutada a una sesión concreta. Los parámetros deben ser únicos para cada instancia de Tomcat. Después de configurar
Tomcat, montaremos DHIS2 de acuerdo al procedimiento normal explicado en otras secciones de este manual.
A continuación, configuraremos el servidor Apache HTTP para realizar balanceo de carga. Las peticiones entrantes
de clientes se asignarán a una de las instancias con una sticky session. Modificamos el fichero /etc/apache2/
apache2.conf (u otro fichero apropiado dependiendo de nuestra configuración exacta) para difinir un proxy
balanceador de carga y una ruta de proxy y de proxy inverso. Notemos que los números de puerto y los parámetros
de route deben coincidir con el puerto Tomcat y los parámetros jvmRoute que definimos anteriormente en la
configuración de Tomcat.
<Proxy balancer://dhiscluster>
Order Allow,Deny
Allow from all
</Proxy>
<Proxy balancer://dhiscluster>
BalancerMember ajp://127.0.0.1:8009/dhis route=dhis1
BalancerMember ajp://127.0.0.1:9009/dhis route=dhis2
ProxySet lbmethod=byrequests
ProxySet stickysession=JSESSIONID
</Proxy>
ProxyVia Off
ProxyPass /dhis/ balancer://dhiscluster/ stickysession=JSESSIONID nofailover=on
ProxyPassReverse /dhis/ balancer://dhiscluster/ stickysession=JSESSIONID|jsessionid
Finalmente, arrancaremos ambas instancias Tomcat, y reiniciaremos el Apache HTTP.
Este ejemplo demuestra cómo implementar un sistema sencillo de balanceo de carga con sticky sessions utilizando
un servidor Apache HTTP.
8.2.7. Encriptado básico SSL con Apache
Utilizando Apache y el montaje de proxy inverso definido en la sección anterior, podemos implementar fácilmente
transferencias encriptadas de datos entre los clientes y el servidor sobre HTTPS. Esta sección describe cómo usar
certificados autofirmados, aunque el mismo procedimiento podría servir también si tenemos certificados firmados por
terceros.
Primero (como root), generaremos los ficheros de claves privadas necesarios y la Petición de Firma de Certificado
(CSR, Certificate Signing Request).
35
Instalación
Instalación de DHIS 2 Live
mkdir /etc/apache2/ssl
cd /etc/apache2/ssl
openssl genrsa -des3 -out server.key 1024
openssl req -new -key server.key -out server.csr
Necesitaremos eliminar la contraseña de la clave, ya que si no lo hacemos Apache no será capaz de usarla.
cp server.key server.key.org
openssl rsa -in server.key.org -out server.key
A continuación, generamos un certificado autofirmado que será válido por un año.
openssl x509 -req -days 365 -in server.csr -signkey \ server.key -out server.crt
ahora, configuraremos Apache habilitando los módulos SSL y creando un sitio por defecto.
a2enmod ssl
a2ensite default-ssl
Ahora, necesitamos editar el fihero SSL por defecto (ubicado en /etc/apache2/sites-enabled/default-ssl)
para habilitar la funcionalidad de transferencias SSL en Apache.
<VirtualHost *:443>
ServerAdmin [email protected]
SSLEngine On
SSLCertificateFile /etc/apache2/ssl/server.crt
SSLCertificateKeyFile /etc/apache2/ssl/server.key
...
Nos aseguraremos de cambiar la sección *:80 de este fichero al puerto *:443, que es el puerto SSL utilizado por
defecto. También, comprobaremos el cambio de ServerAdmin por el email del webmaster. Finalmente, tendremos que
asegurarnos de que el hostname está correctamente indicado en /etc/hosts. Simplemente, bajo la línea de localhost,
añadiremos la dirección IP del servidor y el nombre de dominio.
127.0.0.1 localhost
XXX.XX.XXX.XXX foo.mydomain.org
Ahora, reiniciaremos Apache:
/etc/init.d/apache2 restart
Y deberíamos ser capaces de ver https://foo.mydomain.org/dhis.
8.3. Instalación de DHIS 2 Live
El paquete DHIS 2 Live es muy cómodo de instalar y ejecutar. Está pensado para ejemplos demostrativos, para usuarios
que quieren explorar el sistema y para instalaciones pequeñas, offline típicamente en distritos o establecimientos de
salud. Solo requiere el Entorno de Ejecución de Java (Java Runtime Environment) y funciona en todos los navegadores
web excepto Internet Explorer 7 o versiones anteriores.
Para instalarlo comenzaremos descargando DHIS 2 Live de la página http://dhis2.org y extrayendo el archivo en alguna
ubicación. En Windows pincharemos en el archivo ejecutable. En Linux invocamos el script startup.sh
Después del proceso de arranque, nuestro navegador web por defecto estará apuntando automáticamente a http://
localhost:8082, donde se encuentra la aplicación. En la mayoría de sistemas operativos aparecerá un menú de sistema
donde podremos arrancar y detener el servidor, así como iniciar nuevas sesiones de navegador. Notemos que si el
servidor está funcionando no hay necesidad de arrancarlo de nuevo, sino simplemente abrir la aplicación desde el
menú de sistema.
DHIS 2 Live se ejecuta en un contenedor Servlet Jetty embebido y con una base de datos H2 embebida. Sin embargo,
podremos configurarlo para funcionar con otros sistemas de bases de datos como PostgreSQL. Encontraremos una
36
Instalación
Copias de seguridad (Backup)
explicación detallada sobre la configuración de una base de datos en la sección anterior sobre instalación en servidor.
El fichero de configuración hibernate.properties se encuentra en la carpeta conf. Es importante acordarnos de reiniciar
el paquete Live para que los cambios tengan efecto. El puerto del servidor es 8082 por defecto. Esto también podemos
cambiarlo modificando el valor correspondiente en el fichero de configuración jetty.port que se encuentra en el
directorio conf.
8.4. Copias de seguridad (Backup)
Es indispensable hacer copias de seguridad automatizadas de las bases de datos de sistemas de información en
producción. Ignorar esto puede traer consecuencias desagradables. Las copias de seguridad tienen dos propósitos
principales: el primero es la recuperar los datos en caso de que suceda una pérdida de datos, el segundo es archivar
los datos durante un periodo de tiempo histórico.
Las copias de seguridad son fundamentales en un plan de recuperación del desastre. Incluso cuando un plan como
este debería cubrir también otros asuntos, la base de datos es el componente clave a considerar porque es ahí donde
se guardan todos los datos utilizados en la aplicación DHIS 2. Las otras partes de la infraestructura TIC en torno a la
aplicación se pueden restaurar en base a componentes estándar.
Por supuesto hay muchas maneras de configurar copias de seguridad; sin embargo, a continuación describimos una
configuración donde la base de datos se copia en un fichero dump y se guarda en el sistema de ficheros. Esto puede
considerarse una copia de seguridad completa. La copia de seguridad se realiza con el cron, que es un programador
temporal en los sistemas operativos Unix/Linux.
Podemos descargar ambos ficheros de la página http://dhis2.com/download/pg_backup.zip
El cron se configura con dos ficheros. El primero es un script de backup que realiza la tarea misma de hacer la copia
de seguridad de la base de datos. Utiliza un programa PostgreSQL llamado pg_dump para crear la copia de la base de
datos. El segundo es un fichero crontab que lanza el script de backup cada día a las 23:00. Notemos que este script hace
la copia de seguridad de la base de datos y la guarda en un fichero en el disco local. Es muy recomendable guardar una
copia de esto también fuera del servidor donde se aloja la aplicación. Esto podemos conseguirlo con la herramienta
scp. Deberemos asegurarnos de que hemos fijado la fecha y hora del sistema correctamente en nuestro servidor.
8.5. Trabajando con la base de datos PostgreSQL
Algunas operaciones frecuentes al gestionar una instancia DHIS son las copias y restauraciones de bases de datos.
Para realizar una copia (dump) de nuestra base de datos, asumiendo la configuración mencionada en la sección de
instalación, podemos invocar lo siguiente:
pg_dump dhis2 -U dhis -f dhis2.sql
El primer argumento (dhis2) se refiere al nombre de la base de datos. El segundo argumento (dhis) se refiere al usuario
de la base de datos. El último argumento (dhis2.sql) es el nombre de fichero de la copia. Si queremos comprimir el
fichero copiado inmediatemente podemos hacer lo siguiente:
pg_dump dhis2 -U dhis | gzip > dhis2.sql.gz
Para restaurar esta copia en otro sistema, primero necesitamos crear una base de datos vacía como se describe en
la sección de instalación. También necesitamos descomprimir la copia si habíamos creado una versión comprimida.
Podemos invocar entonces:
psql -d dhis2 -U dhis -f dhis2.sql
8.6. Usando los Servicios Web Amazon
Los Servicios Web Amazon (AWS) ofrecen recursos virtuales de cloud-computing que permiten a desarrolladores e
implementadores escalar rápidamente una aplicación, tanto horizontal como verticalmente, de forma eficaz en cuanto
a costes. AWS ofrece múltiples sistemas operativos y tamaños de instancias dependiendo de la naturaleza concreta
37
Instalación
Usando los Servicios Web Amazon
del despliegue. Esta sección descrie un montaje sencillo con el sistema AWS Elastic Cloud Compute (EC2) utilizando
Amazon AMI Basic 32 bit, que se basa en la distribución Red Hat Linux.
Podemos estimar el coste de una instancia AWS usando el "Simple Monthly Calculator". Los costes de AWS se basan
directamente en su uso. A medida que crece el uso de nuestra aplicación, podemos proveer con nuevos servidores.
1. Necesitaremos una cuenta AWS existente. Si aún no tenemos una, podemos crearla aquí. Una vez hayamos creado
y habilitado nuestra cuenta, nos logueamos en la consola AWS.
2. Cuando estemos logueados, seleccionamos la pestaña "EC2". A continuación, seleccionamos una región donde
instanciar nuestra instancia. Los usuarios en Europa y África, probablemente podrán usar la región EU West,
mientras usuarios en Asia deberán usar probablemente la de regiones Asia Pacífico (sea Singapur o Tokio), y los
usuarios de Latinoamérica dberán usar la región de las Américas. La selección de la región apropiada reducirá la
latencia entre servidor y clientes.
3. Haremos click en el enlace de "Instancias" en el menú de la derecha, y luego en el botón "Lanzar Instancias".
Seleccionamos uno de los AMIs para nuestro servidor. Es recomendable usar cualquiera de los AMIs básicos de
Amazon (sea el de 32 ó 64 bits), pero podemos elegir el AMI que sea más adecuado en nuestro caso.
4. A continuación necesitaremos seleccionar el tamaño de nuestra instancia. El tamaño seleccionado dependerá del
número de usuarios anticipados. Seleccionar el tamaño "Micro" nos permitirá probar DHIS 2 en el entorno AWS
durante un periodo de un año, sin coste si usamos uno de los AMIs"Free tier eligible".
5. Cuando hayamos seleccionado el tamaño de instancia, podremos seleccionar un ID específico de kernel y de disco
RAM. Si no tenemos un criterio en particular, simplemente usamos los valores por defecto y seguimos al siguiente
paso.
6. A continuación, añadimos las parejas de claves para facilitarnos la identificación de la instancia. Esto son
simplemente metadatos para nuestro propio manejo.
7. Ahora necesitaremos una pareja de claves que nos permita acceder remotamente a nuestra instancia. Si tenemos una
pareja de claves ya creada podemos usarla, si no, podemos crear una nueva.
8. Pasaremos a asignar un grupo de seguridad a la instancia. Los grupos de seguridad se pueden usar para exponer
ciertos servicios (SSH, HTTP, Tomcat, etc) en Internet. Con grupos de seguridad, podemos controlar qué puertos
38
Instalación
Usando los Servicios Web Amazon
se abrirán a ciertos rangos de red. Para DHIS 2, normalmente necesitaremos abrir al menos el puerto 22 (SSH) y el
puerto 80 (HTTP) a Internet o a rangos de direcciones específicos.
9. Finalmente, podremos revisar y lanzar nuestra instancia.
10.Una vez hemos lanzado la instancia, podremos conectarnos via PuTTY o cualquier cliente SSH a la instancia
utilizando el DNS público de la misma, que aparece listado en el panel de control de EC2. Necesitaremos instalar
unos cuantos paquetes si estamos usando el AMI por defecto de Amazon.
yum install jdk.i586 postgresql-server.i686 apache-tomcat-apis.
noarch tomcat-native.i686 httpd.i686
11.Cuando hayamos instalado estos paquetes, podremos seguir las instrucciones detalladas en la sección 8.1 de Montaje
de un servidor.
39
Soporte
Página principal: dhis2.org
Capítulo 9. Soporte
La comunidad DHIS 2 utiliza un conjunto de plataformas colaborativas y de coordinación para la información y para
proveer descargas, documentación, desarrollo, código fuente, especificaciones de funcionalidades, seguimiento de
bugs. Este capítulo explica todo esto en detalle.
9.1. Página principal: dhis2.org
La página principal de DHIS 2 se encuentra en http://dhis2.org La página de descargas contiene descargas del paquete
DHIS 2 Live, ficheros WAR, el cliente móvil, un paquete Debian, el código fuente, bases de datos de ejemplo y una
herramienta de edición de las traducciones del interfaz de usuario de la aplicación. Notemos que la última versión
se mantiene hasta que la aparece la siguiente y están disponibles tanto la versión actual más reciente como la última
generación del branch. Recomendamos comprobar regularmente la página de descargas y actualizar el servidor online
con la última versión del branch. La revisión de versiones se puede encontrar también en Ayuda - Acerca de en DHIS 2.
La página de documentación contiene instrucciones para la instalación, documentación de usuario, esta guía de
implementación, presentaciones, Javadocs, registro de cambios, roadmap y una guía sobre cómo contribuir en la
documentación. La documentación de usuario está enfocada a aspectos prácticos del uso de DHIS 2, como cómo crear
elementos de datos y reportes. Esta guía de implementación cubre los aspectos de más alto nivel de la implementación,
desarrollo de la base de datos y mantenimiento de DHIS 2. El registro de cambios y la sección de roadmap contienen
enlaces a las páginas respectivas en el sitio de Launchpad que se describe más adelante.
Las páginas de funcionalidad y características dan una visión escueta con capturas de pantalla de las principales
funciones y características de DHIS 2. Se puede también acceder a una demo de DHIS 2 en el menú demo. Estas
páginas pueden utilizarse cuando queremos dar una rápida introducción al sistema a los diversos actores del proyecto.
La página Acerca de contiene información sobre la licencia de publicación de DHIS 2, sobre cómo inscribirse a las
listas de correo y tener acceso al código fuente y más.
9.2. Plataforma colaborativa: launchpad.net/dhis2
DHIS 2 utiliza Launchpad como la principal plataforma colaborativa. Se accede al sitio en http://lanchpad.net/dhis2
Launchpad se utiliza para alojar el código fuente, las especificaciones técnicas, el seguimiento de bugs y notificaciones.
El sistema de control de versiones Bazaar está estrechamente integrado con Launchpad y se requiere para verificar
y actualizar el código fuente.
Los diversos branch de código fuente incluido trunk y release se pueden encontrar via web en http://
code.launchpad.net/dhis2
si queremos sugerir que sean implementadas nuevas funcionalidades en DHIs 2 podemos compartir nuestras propuestas
en la lista de correo de desarrolladores e incluso escribir una especificación, que se denomina blueprints en Launchpad.
El blueprint será considerado por el equipo troncal de desarrollo y si se acepta, se le asignará un desarrollador, revisor
y una versión de publicación. Se puede acceder y añadir blueprints via web en http://blueprints.launchpad.net/dhis2
Si encontramos un bug en DHIS 2 podemos también reportarlo en Launchpad navegando a http://bugs.launchpad.net/
dhis2 Nuestro reporte de bug será investigado por el equipo de desarrollo y se le asignará un estatus. Si se valida,
será asignado a un desarrollador y revisor y eventualmente será solucionado. Notemos que la resolución de bugs se
incorpora en el trunk y en el branch más reciente publicado - de modo que realizar un buen testeo y retroalimentación
a los equipos de desarrollo revierte en mejor calidad de nuestro software.
41
Unidades Organizativas
Diseño de la jerarquía de unidades
organizativas
Capítulo 10. Unidades Organizativas
En DHIS 2 la ubicación de los datos, el contexto geográfico, se representa como unidades organizativas. Las unidades
organizativas pueden ser un establecimiento de salud, un departamento o subunidad que provee servicios de salud o
una unidad administrativa que representa un área geográfica (ej. un distrito).
Las unidades organizativas se encuentran en una jerarquía, también llamada aquí árbol. La jerarquía refleja la estructura
administrativa en salud y sus niveles. Los típicos niveles en esta jerarquía son el nacional, provincial, distrital y de
establecimiento. En DHIS 2 hay una única jerarquía organizativa así que la manera en que la definimos y mapeamos
en la realidad requiere una cuidadosa atención, revisando qué áreas geográficas y niveles se definen en la jerarquía
principal tendrán mayor impacto en la usabilidad y rendimiento de la aplicación. Adicionalmente, hay formas de cubrir
jerarquías y niveles alternativos, tal y como se explica más adelante en la sección denominada Grupos de unidades
organizativas y sets de grupos.
10.1. Diseño de la jerarquía de unidades organizativas
El proceso de diseñar una jerarquía de unidades organizativas con sensatez debería tomar en cuenta varios aspectos:
• Incluir todos los establecimientos que reportan datos de salud: Todos los establecimientos de salud que contribuyen
a la recolección de datos nacionales deberían incluirse en el sistema. Los establecimientos de todo tipo deberían
incorporarse, incluyendo los privados, públicos, ONG y religiosos. A menudo los establecimientos privados
constituyen un porcentaje no despreciable del total de establecimientos en un país y siguen políticas de reporte
de datos impuestas, lo que significa que incorporar datos de esos establecimientos es necesario para hacernos una
imagen agregada realista a nivel nacional.
• Enfatizar la jerarquía administrativa en salud Generalmente un país tiene múltiples jerarquías administrativas que
muchas veces no están bien coordinadas o armonizadas. Cuando consideramos qué enfatizar al diseñar la base de
datos de DHIS 2 debemos tener en mente qué áreas son las más interesantes y serán más solicitadas para el análisis
de datos. DHIS gestiona primordialmente datos de salud y realiza análisis basándose en la estructura administrativa
de salud. Esto impica que incluso si hubiera que hacer ajustes para satisfacer áreas financieras o del gobierno local,
el punto de partida de la jerarquía de unidades organizativas de DHIS serían las áreas administrativas en salud.
• Limitar el número de niveles en la jerarquía de unidades organizativas: Para satisfacer los requisitos de análisis
provinientes de diversos cuerpos organizativos como el gobierno local y el tesoro, es tentador inluir todas estas áreas
como unidades organizativas en la base de datos de DHIS 2. Sin embargo, por consideraciones de rendimiento uno
debería intentar limitar los niveles de la jerarquía de unidades organizativas al menor número posible. La jerarquía
se utiliza como base para la agregación de datos que se presentan en cualquiera de las herramientas de reporte, así
que cuando se producen datos agregados para niveles más altos, la aplicación DHIS 2 debe buscar y juntar datos
registrados para todas las unidades organizativas ubicadas más abajo en la jerarquía. Entonces, aumentar el número
de unidades organizativas repercutirá negativamente en el rendimento de la aplicación y un número excesivamente
grande puede convertirse en un problema importante.
Además, una parte central en la mayoría de herramientas de análisis en DHIS 2 se basa en seleccionar dinámicamente
la unidad "padre" de aquellas que se quieren incluir en el análisis. Por ejemplo, si queremos seleccionar una provincia
e incluir los distritos de esa provincia en el reporte. Si el nivel de distrito es el nivel más interesante desde el
punto de vista del análisis y existen muchos niveles jerárquicos entre este y el nivel provincial, este tipo de reporte
se renderizará inútilmente. Cuando construimos la jerarquía, deberíamos fijarnos en los niveles que se utilizarán
frecuentemente en reportes y en análisis de datos y dejar fuera los niveles que raramente o nunca se usan ya que esto
tiene un impacto tanto en el rendimiento como en la usabilidad de la aplicación.
• Evitar relaciones uno-a-uno: Otro principio referente para diseñar la jerarquía es evitar conectar niveles que tienen
ratios padre-hijo cercanos al uno-a-uno, lo que quiere decir que por ejemplo un distrito (padre) debería tener de
media más de una municipalidad (hijo) en el nivel inferior para que tenga sentido añadir esta municipalidad a la
jerarquía. Los ratios padre-hijo de 1:4 o más son mucho más útiles para el propósito de análisis de datos ya que nos
permite mirar por ejemplo, cómo los datos de un distrito se distribuyen en las diferentes subáreas y cómo varían.
Estos ejercicios de recorrido vertical son poco útiles cuando el nivel inferior tiene la misma población objetivo y los
mismos establecimientos prestadores de servicios que la unidad padre.
43
Unidades Organizativas
Grupos de unidades organizativas y sets de
grupos
A la hora de mapear la realidad en la jerarquía de unidades organizativas de DHIS 2 puede ser difícil saltar niveles
geográficos y puede conllevar resistencias entre ciertos actores, pero deberemos tener en mente que en realidad hay
formas de producir reportes basados en niveles geográficos que no son parte de la jerarquía organizativa en DHIS
2, como se explica en la sección siguiente.
10.2. Grupos de unidades organizativas y sets de grupos
En DHIS 2, las unidades organizativas pueden agruparse en grupos de unidades organizativas, y estos grupos pueden
a su vez asociarse en sets de grupos. Juntos pueden emular una jerarquía organizativa alternativa que puede usarse a
la hora de crear reportes y otras salidas de datos. Además de representar ubicaciones geográficas alternativas que no
están en la jerarquía principal, estos grupos son útiles para asignar esquemas de clasificación a los establecimientos
de salud, por ejemplo basados en el tipo o propietario de los establecimientos. Se pueden definir tantos grupos y sets
de grupos como deseemos en la aplicación a través del interfaz de usuario, y todos ellos se definen localmente para
cada base de datos DHIS 2.
Este ejemplo lo ilustra mejor: generalmente queremos proveer análisis en base a la propiedad de los establecimientos
(público, privado, etc). En ese caso podemos crear un grupo para cada tipo de propiedad, por ejemplo "Ministerio de
Salud", "Privado" y "ONG". Todos los establecimientos en la base de datos deben clasificarse y ser asignados a uno y
solo uno de estos grupos. A continuación crearíamos un set de grupos llamado "Propiedad" al que se asignan los tres
grupos anteriores, como se ilustra en esta figura.
De forma similar podemos crear un set de grupos para un nivel administrativo adicional, por ejemplo municipios.
Todos los municipios han de definirse como grupos de unidades organizativas y asignarlos a un set de grupos llamdo
"Municipios". El paso final sería asignar todos los establecimientos a uno y solo uno de los grupos de municipio.
Esto permite a DHIS 2 producir reportes agregados por cada municipio (añadiendo conjuntamente datos de todos los
establecimientos incluidos) sin tener que incluir el nivel de municipio en la jerarquía organizativa principal. El mismo
camino puede seguirse para cualquier nivel administrativo o geográfico adicional que sea necesario, con un set de
grupo por nivel adicional. Antes de continuar y diseñar esto en DHIS 2, es importante mapear las áreas de niveles
geográficos adicionales y los establecimientos por cada área.
Una cualidad esencial del concepto de set de grupos en DHIS 2 que debemos comprender es la exclusividad, que implica
que una unidad organizativa puede ser miembro de solo uno de los grupos en un set de grupos. Infringir esta norma
podría conllevar la duplicación de datos al agregar datos de establecimientos de salud por parte de distintos grupos, ya
que un establecimiento que es asignado a dos grupos en el mismo set de grupos sería contabilizado dos veces.
Con esta estructura presente, DHIS 2 puede proporcionar datos agregados para cada tipo de propiedad de unidad
organizativa mediante el "Reporte de set de grupos de unidades organizativas" en el módulo de "Reporte" o mediante
la herramienta de terceros de las tablas dinámicas Excel. Por ejemplo podremos ver y comparar tasas de uso agregadas
por los diferentes tipos de propiedad (ej. Ministerio, Privado, ONG). además, DHIS 2 puede sacar estadísticas de
distribución de los establecimientos en el "Reporte de set de grupos de unidades organizativas" del módulo de
"Reporte". Por ejempo, podemos ver cuántos establecimientos hay bajo una determinada unidad organizativa de la
jerarquía para cada tipo de propiedad. En el módulo SIG, dado que las coordenadas de los establecimientos de salud
44
Unidades Organizativas
Grupos de unidades organizativas y sets de
grupos
se han registrado en el sistema, podremos ver las ubicaciones de los diferentes tipos de establecimientos de salud (con
símbolos distintos según su tipo), y también combinar esta información con otra capa de mapa que muestre indicadores,
por ejemplo, por distrito.
45
Elementos de datos y dimensiones
personalizados
Elementos de datos
Capítulo 11. Elementos de datos y
dimensiones personalizados
En este capítulo comenzaremos discutiendo una base importante del sistema: el elemento de datos. A continuación
veremos el modelo de categorías y cómo puede usarse para lograr una estructura muy personalizada de metadatos para
almacenar los datos.
11.1. Elementos de datos
El elemento de datos es, junto con la unidad organizativa, el bloque más importante de la base de datos de DHIS 2.
Representa la dimensión qué y explica qué es lo que se registra y analiza. En algunos contextos ponen al indicador en
este lugar, sin embargo en DHIS 2 este elemento de metadatos para el registro y análisis de los datos es lo que llamamos
elemento de datos. El elemento de datos frecuentemente representa el conteo de algún evento y su nombre describe
qué es lo que se cuenta, por ejemplo "Dosis entregadas BCG" o "Casos de Malaria". Cuando se recopilan, validan,
analizan o presentan los datos, son los elementos de datos o las expresiones construidas con elementos de datos los
que describen sobre qué fenómeno, evento o caso se registran datos. Por ello el elemento de datos toma importancia
en todos los aspectos del sistema y decide no sólo cómo se colectan los datos sino, todavía más importante, cómo se
representan los datos en la base de datos y cómo pueden analizarse y presentarse los datos.
Un principio importante tras el diseño de elementos de datos es pensar en elementos de datos como descripciones
autocontenidas de un fenómeno o evento y no como un campo del formulario de entrada de datos. Cada elemento de
dato existe autónomamente en la base de datos, completamente separado e independiente del formulario de registro.
Es importante considerar que los elementos de datos se usan directamente en los reportes, gráficas y otras herramientas
de análisis de datos, en los cuales el contexto de cualquier formulario de entrada de datos no es accesible ni relevante.
En otras palabras, debe ser posible identificar claramente qué evento representa un elemento de dato solo con mirar su
nombre. Basándonos en esto podemos derivar una regla práctica si decimos que el nombre del elemento de dato debe
poder mantenerse por sí mismo y describir el valor del dato también fuera del contexto de su formulario de registro.
Pongamos por caso un elemento de dato llamado "Malaria", que sería preciso visto en un formulario de entrada de
datos que captura datos de inmunización, en un formulario de registro de stocks de vacunas o en un formulario de
datos de pacientes no ingresados. Cuando lo vemos en un reporte, sin embargo, fuera del contexto del formulario, es
imposible saber a qué evento representa este elemento de dato. Si el elemento de dato se hubiera llamado "Casos de
Malaria", "Dosis recibidas del stock de Malaria" o "Dosis entregadas de Malaria" estaría claro desde la perspectiva de
cualquier usuario qué es lo que el reporte está tratando de expresar. En este caso estamos tratando con tres elementos
de datos diferentes con semánticas completamente distintas.
11.2. Categorías y dimensiones personalizadas
Hay determinados requisitos en la captura de datos que necesitan una definición más ajustada de la dimensión que
describe el evento contabilizado. Por ejemplo, si queremos registrar el número de "Casos de Malaria" subdivididos en
género y grupos de edad, como "femenino", "masculino" y "< 5 años" y "> 5 años". Lo que caracteriza esto es que la
subdivisión generalmente se repite para un número de elementos de datos "base": digamos que queremos reutilizar esta
subdivisión para otros elementos de datos como "TB" y "VIH". Para hacer los metadatos más dinámicos, reutilizables
y adecuados para el análisis tiene sentido definir las enfermedades mencionadas como elementos de datos y crear un
modelo separado para los atributos de subdivisión. Podemos conseguir esto utilizando el modelo de categorías que se
describe a continuación.
El modelo de categorías tiene tres elementos principales que se describen mejor usando el ejemplo anterior:
1. La opción de categoría, que corresponde a "femenino", "masculino" y "< 5 años" y "> 5 años".
2. La categoría, que corresponde a "género" y "grupo de edad".
3. La combinación de categorías, que podría llamarse "género y grupo de edad" en el ejemplo anterior y tendría
asignadas ambas categorías mencionadas.
47
Elementos de datos y dimensiones
personalizados
Grupos de elementos de datos
Este modelo de categorías es de hecho autosuficiente pero en DHIS 2 está flexiblemente emparejado con el elemento
de datos. Flexiblemente emparejado aquí significa que hay una asociación entre elemento de dato y combinación de
categorías, pero esta asociación puede cambiar en cualquier momento sin perder ningún dato. Sin embargo, no es
recomendable cambiar esto a menudo ya que quita valor a la base de datos en general porque reduce la continuidad de
los datos. Notemos que no hay un límite duro en el número de opciones de categoría en una categoría o en el número
de categorías en una combinación de categorías, pero hay un límite natural donde la estructura se vuelve desordenada
y rígida.
Es posible usar una pareja de elemento de datos y combinación de categorías para representar cualquier nivel de
subdivisión. Es importante comprender que lo que en realidad está sucediendo es que estamos asignando a los datos una
cierta cantidad de dimensiones personalizadas. Al igual que el elemento de dato representa una dimensión obligaroria
de los valores de datos, las categorías le añaden a su vez dimensiones personalizadas. En el ejemplo anterior podemos
hacer un análisis mediante las herramientas de salida de DHIS2 basándonos tanto en "género" como en "grupos de
edad" para esos elementos de datos, de la misma forma en que podemos realizar análisis basándonos en elementos de
datos, unidades organizativas y periodos.
Este modelo de categorías puede utilizarse tanto en el diseño de formularios de entrada de datos como en el análisis y
los reportes de tables. Para los propósitos de análisis, DHIS 2 puede producir automáticamente subtotales y totales de
cada elemento de dato asociado a una combinación de categorías. La norma para este cálculo es que todas las opciones
de categoría deberían sumar un total significativo. El ejemplo anterior muestra un total significativo ya que al resumir
"Casos de Malaria" registrados para "femenino < 5 años" y "masculino < 5 años", "femenino > 5 años" y "masculino
> 5 años" obtendremos el número total de "Casos de Malaria".
Para el propósito de la captura de datos, DHIS 2 puede generar automáticamente formularios de entrada de datos
tabulares donde los elementos de datos se representen como filas y las combinaciones de opciones de categoría se
representen como columnas. Esto nos llevará en muchos casos a completar formularios con un esfuerzo mínimo. Por
ejemplo, puede suceder que queramos crear rápidamente formularios de entrada de datos utilizando categorías que no
se adhieren a la norma de total significativo. Aún así, nosotros consideramos esto una alternativa mejor que mantener
dos modelos independientes y separados para la entrada y la salida de datos.
Un punto importante sobre el modelo de categorías es que los valores de los datos persisten y se asocian con una
combinación de opciones de categoría. Esto implica que añadir o eliminar categorías de una combinación de categorías
renderiza estas combinaciones de forma inválida y deben realizarse operaciones de bajo nivel con la base de datos para
corregirlas. Por ello es recomendable considerar premeditadamente qué subdivisiones son necesarias y no cambiarlas
con demasiada frecuencia.
11.3. Grupos de elementos de datos
Podemos modelar las propiedades comunes de los elementos de datos mediante lo que llamamos grupos de elementos
de datos. Los grupos son completamente flexibles en el sentido de que son definidos por el usuario, tanto sus nombres
como sus agrupaciones. Los grupos son útiles para navegar y presentar los datos, y también pueden usarse para agregar
los valores capturados para los elementos de datos en el grupo. Los grupos están flexiblemente emparejados con
elementos de datos y no ligados directamente a los valores de los datos, lo que significa que pueden ser modificados
y añadidos en cualquier momento sin interferir en los datos de bajo nivel.
48
Sets de datos y formularios
¿Qué es un set de datos?
Capítulo 12. Sets de datos y formularios
Este capítulo cubre los sets de datos y formularios, qué tipos de formularios están disponibles y describe buenas
prácticas en el proceso de cambiar de fomularios en papel a formularios electrónicos.
12.1. ¿Qué es un set de datos?
Toda entrada de datos en DHIS 2 está organizada mediante el uso de sets de datos. Un set de datos es una colección de
elementos de datos agrupados para registrar datos, y en el caso de instalaciones distribuidas también definen montones
de datos para exportar e importar entre instancias de DHIS 2 (por ejemplo, de una instalación local en oficina distrital
al servidor nacional). Los sets de datos no están directamente ligados a los valores de los datos, solo a través de sus
elementos de datos y frecuencias, y por tanto un set de datos puede ser modificado, eliminado o añadido en cualquier
momento sin que ello afecte a los datos en bruto anteriormente capturados en el sistema, aunque estos cambios por
supuesto siempre afectarán a cómo se recopilan nuevos datos.
Un set de datos tiene un tipo de periodo que controla la frecuencia de recogida de datos, que puede ser diaria, semanal,
mensual, trimestral, semestral o anual. Tanto los elementos de datos a incluir en el data set como el tipo de periodo
son definidos por el usuario, junto con un nombre, un nombre corto, y un código. Si se necesitan campos calculados
en el formulario de registro (y no sólo en los reportes), entonces se pueden asignar indicadores al set de datos también,
pero éstos solo pueden usarse en formularios personalizados (ver más abajo).
Para utilizar un set de datos para recopilar datos para una unidad organizativa específica el usuario debe asignar la
unidad organizativa al set de datos. Este mecanismo controla qué unidades organizativas pueden utilizar qué sets
de datos, y al mismo tiempo define los valores objetivo para la completitud de los datos (por ejemplo, cuántos
establecimientos de salud se espera que envíen el set de datos RCH cada mes en un distrito).
Un elemento de dato puede pertenecer a múltiples sets de datos, pero esto requiere pensar cuidadosamente ya que
puede conllevar que se registren datos superpuestos e inconstantes si, por ejemplo, damos diferentes frecuencias a los
sets de datos y éstos son utilizados por las mismas unidades organizativas.
12.2. ¿Qué es un formulario de entrada de datos?
Una vez hemos asignado un set de datos a una unidad organizativa, ese set de datos quedará disponibile en "Entrada
de Datos" (en menú Servicios) de cara a las unidades organizativas que le hemos asignado y en los periodos válidos
de acuerdo al tipo de periodo del set de datos. Entonces se mostrará un formulario de entrada de datos por defecto, que
simplemente será un listado de los elementos de datos pertenecientes al set de datos junto a una columna para meter los
valores. Si nuestro set de datos contiene elementos de datos con categorías como grupos de edad o género, entonces
se generarán automáticamente columnas adicionales en el formulario en base a las categorías. Además del formulario
de entrada por defecto tipo lista hay otras dos alternativas: el formulario de secciones y el formulario personalizado.
12.2.1. Tipos de formularios de entrada de datos
DHIS 2 permite actualmente tres tipos diferentes de formularios que se describen a continuación:
12.2.1.1. Formularios por defecto
Un formulario de entrada de datos por defecto es sencillamente un listado de los elementos de datos que pertenecen
al set de datos junto a una columna para insertar los valores. Si nuestro set de datos continene elementos de datos
con una combinación de categorías personalizada, como los grupos de edad o género, entonces se añadirán columnas
automáticamente al formulario en base a las distintas opciones/dimensiones. Si utilizamos más de una combinación de
categorías en el set de datos obtendremos una tabla por cada combinación de categorías en el formulario por defecto,
con diferentes encabezados de columna para las opciones.
49
Sets de datos y formularios
Lecciones aprendidas: de los formularios en
papel a los formularios electrónicos
12.2.1.2. Formularios de Sección
Los formularios por secciones son un poco más flexibles cuando queremos hacer formularios tabulares, y son rápidos
y sencillos de diseñar. A menudo nuestro formulario de entrada de datos necesita mútiples tablas con subtítulos, y a
veces necesitamos deshabilitar (colorear en gris) unos pocos campos de la tabla (por ejemplo, categorías que no se
aplican a todos los elementos de datos); estas dos funciones están soportadas en los formularios por secciones. Después
de definir un set de datos podemos definir sus secciones con subsets de elementos de datos, un encabezado y posibles
campos en gris en la tabla de la sección. El orden de las secciones en un set de datos también puede definirse. En
"Entrada de Datos" podemos comenzar usando el formulario de sección (debería aparecer automáticamente cuando
hay secciones disponibles para el set de datos seleccionado). Debería ser posible reproducir la mayoría de formularios
tabulares con los formularios por secciones. Utilizar los formularios por secciones o por defecto nos hace la vida más
fácil ya que no hay necesidad de mantener un diseño fijo de formulario que incluye referencias a los elementos de datos.
Si estos dos tipos de formularios no cumplen con nuestros requisitos, entonces la tercera opción es ya completamente
flexible, aunque lleva más tiempo, y son los formularios personalizados de entrada de datos.
12.2.1.3. Formularios personalizados
Cuando el formulario que queremos diseñar es demasiado complicado para el estilo por defecto o los formularios
por secciones, entonces nuestra última opción es ya usar un formulario personalizado. Esto nos llevará más tiempo,
pero nos da total flexibilidad en términos de diseño. En DHIS 2 hay un editor HTML (CK Editor) en el diseñador
de formularios, que nos permite tanto diseñar el formular en el IU o pegar nuestro código html directamente (usando
la ventana "fuente" del editor). En el formulario personalizado podemos insertar texto estático o campos de datos
(vinculados a elementos de datos y combinaciones de opciones de categorías) en cualquier posición del formulario y
tenemos total libertad para diseñar la apariencia del formulario. Una vez hemos añadido el formulario personalizado a
un set de datos, quedará disponible en la entrada de datos y podrá ser usado inmediatamente.
Cuando manejamos un formulario personalizado es posible utilizar campos calculados para mostrar por ejemplo totales
u otros cálculos basados en los datos que se están capturando en el formulario. Esto puede ser útil cuando ligiamos
con formularios logísticos o de stock que necesitan balanceo de ítems, número de items necesarios para el próximo
periodo, etc. Para hacer esto, el usuario deberá definir previamente las expresiones calculadas como indicatores y luego
asignar estos indicadores al set de datos en cuestión. En el diseñador de formularios personalizados el usuario puede
asignar indicadores al formulario de la misma manera en que se asignan elementos de datos. La única limitación a
la expresión calculada es que todos los elementos de datos incluidos den la expresión deben estar disponibles en el
mismo set de datos, ya que los cálculos se hacen sobre la marcha dentro del formulario, y no se basan en valores de
datos almacenados anteriormente en la base de datos.
12.3. Lecciones aprendidas: de los formularios en papel a los formularios
electrónicos
Cuando introducimos un sistema electrónico de información en salud, el sistema que es reemplazado generalmente se
basa en buena medida en reportes en papel. El proceso de migrar a la captura y análisis electrónicos implica algunos
retos. Las siguientes secciones sugieren buenas prácticas sobre cómo afrontarlos y superarlos.
12.3.1. Identificar elementos de datos autónomos
Generalmente el diseño de un set de datos en DHIS 2 se basa en algunos requisitos de los formularios en papel que
se estaban manejando hasta ese momento. La lógica de los formularios en papel no es la misma que el modelo de
elementos de datos y set de datos de DHIS. Por ejemplo, frecuentemente un campo de un formulario tabular en papel
se describe tanto en encabezados de columnas y en texto en cada fila, y a veces también con algún título introductorio
de la tabla que proporciona mayor contexto. En la base de datos esto se captura para un elemento de dato atómico sin
referencia a una posición en formato de tabla visual, así que es importante asegurarnos de que el elemento de dato con
sus categorías opcionales capture el significado completo de cada campo individual en el formulario en papel.
50
Sets de datos y formularios
Dejar los cálculos y las repeticiones a la
computadora: capturar solo datos en bruto
12.3.2. Dejar los cálculos y las repeticiones a la computadora: capturar solo
datos en bruto
Otro asunto importante a tener en mente a la hora de diseñar sets de datos es que el set de datos y el correspondiente
formulario (que es en realidad el set de datos con una apariencia concreta) es una herramienta de colección de datos
y no una herramienta de reporte o análisis. Hay otras herramientas mucho más sofisticadas para la salida de datos
y generación de reportes en DHIS 2 que los formularios de entrada de datos. Los formularios en papel a menudo
se diseñan teniendo en cuenta tanto el registro como el reporte de datos, y por esta razón podremos ver cosas como
valores acumulados (además de valores mensuales), repeticiones de datos anuales (los mismos datos poblacionales
reportados cada mes) o incluso valores de indicadores como tasas de cobertura en el mismo formulario que los datos
mensuales en bruto. Cuando almacenamos datos en bruto en la base de datos DHIS 2 cada mes y tenemos todo el
poder de procesado necesario en una herramienta computacional, entonces no hay ya ninguna necesidad (de hecho
sería erróneo y podría causar inconsistencias) registrar valores como los anteriores calculados manualmente. Solo
querremos capturar datos en bruto en nuestros formularios y dejar los cálculos a la computadora, y la presentación de
esos valores a las herramientas de reporte de DHIS. Mediante las funcionalidades de los reportes de sets de datos, todos
los formularios tabulares por secciones tendrán automáticamente columnas extra en el extremo derecho para aportar
valores de subtotal y total para cada fila (elemento de dato).
51
Calidad de los datos
Cómo medir la calidad de los datos
Capítulo 13. Calidad de los datos
Este capítulo discute los diversos aspectos relacionados con la calidad de los datos.
13.1. Cómo medir la calidad de los datos
¿Los datos están completos, es decir, hay integridad? ¿Se han recopilado a tiempo? ¿Son correctos? Estas son cuestiones
que es preciso que nos preguntamos a la hora de analizar los datos. Una baja calidad de datos puede tomar muchas
formas; no solo figuras incorrectas, sino también falta de integridad, o que los datos sean demasiado antiguos (para
tener un uso significativo).
13.2. Causas de una baja calidad de datos
Hay muchas causas posibles de que lleguemos a tener una baja calidad de datos, entre las que se encuentran:
• Que se recojan cantidades excesivas de datos: demasiados datos a recopilar nos lleva a tener menos tiempo para
hacerlo, y a buscar "atajos" para terminar los reportes.
• Que haya muchos pasos manuales: mover figuras, sumatorios, etc. entre diferentes formularios en papel
• Que las definiciones no sean claras: interpretando erróneamente los campos a rellenar
• Que la información apenas se use: entonces no hay motivación para mejorar la calidad
• Que los sistemas de información estén fragmentados: produciendo duplicados en los reportes
13.3. Cómo mejorar la calidad de los datos
Mejorar la calidad de los datos es una tarea a largo plazo, y muchas de las medidas que podemos tomar son en realidad
de naturaleza organizativa. Sin embargo, la calidad de los datos debería considerarse un asunto clave desde el comienzo
de cualquier proceso de implementación, y hay algunas cosas que pueden trabajarse a la vez, como sucede en los
chequeos en DHIS2. Algunas tácticas de mejora de la calidad de datos son:
• Realizar cambios en los formularios de colección de datos, armonizar los formularios
• Promover el uso de la información anivel local, en el lugar donde se recogen los datos
• Desarrollar rutinas de chequeo de la calidad de los datos
• Incluir el tema de calidad de datos en las capacitaciones de usuarios
• Implementar chequeos de calidad de datos en DHIS2
13.4. Cómo utilizar DHIS 2 para mejorar la calidad de los datos
DHIS2 tiene numerosas funcionalidades que pueden ayudar al trabajo de mejorar la calidad de los datos: la validación
durante la entrada de datos para asegurarnos de que los datos se registran en el formato adecuado y pertenecen a un
rango razonable, reglas de validación definidas por el usuario en base a relaciones matemáticas entre los datos que
se capturan (por ejemplo comparando cantidades subtotales con totales), funciones de análisis de outliers (valores
atípicos), así como reportes de cobertura e integridad de datos.
De manera más indirecta, muchos de los principios de diseño de DHIS contribuyen a mejorar la calidad de los datos,
como por ejemplo la idea de armonizar los datos en un Data Warehouse integrado, permitir el acceso a los datos y a
las herramientas de análisis a nivel local, y ofrecer un amplio abanico de herramientas para el análisis y la difusión de
los datos. Si contamos con procesos de recolección de datos más estructurados y armonizados y con un uso reforzado
de la información a todos los niveles, la calidad de los datos mejorará. A continuación mostramos una panorámica de
las funcionalidades que afectan más directamente a las calidad de los datos:
53
Calidad de los datos
Validación en la introducción de datos
13.4.1. Validación en la introducción de datos
La manera más básica de chequear la calidad de los datos en DHIS 2 es asegurarnos de que los datos que estamos
capturando están en el formato correcto. DHIS 2 mostrará un mensaje a los usuarios indicando si el valor introducido
no está en un formato adecuado y no almacenará el valor hasta que se cambie a un valor aceptable. Por ejemplo, no se
podrá meter texto en un campo numérico. Los diferentes tipos de valores de datos que se soportan en DHIS 2 vienen
explicados en el Manual de Usuario, en el capítulo acerca de elementos de datos.
13.4.2. Rangos Máximo y Mínimo
Para detener el tipeo de errores en la entrada de datos (por ejemplo, tipear '1000' en lugar de '100'), DHIS 2 chequea que
el valor que se introduce esté dentro de un rango razonable. Este rango está basado en los datos recopilados previamente
por un mismo establecimiento de salud para un mismo elemento de dato, y consiste en un valor mínimo y máximo. Tan
pronto como el usuario introduzca un valor fuera del rango, se le alertará de que el valor no es aceptado. Para poder
calcular rangos razonables, el sistema necesita tener registrados datos de al menos seis meses (periodos).
13.4.3. Reglas de validación
Una regla de validación está basada en una expresión matemática que define la relación entre ciertos elementos de
datos. La expresión tiene una parte izquierda y una derecha, y un operador que determina si la primera debe ser menor
que, igual que o mayor que la segunda. La expresión forma una condición que debería confirmar que se cumplen
determinados criterios lógicos. Por ejemolo, una regla de validación podría confirmar que el número total de vacunas
entregadas a niños y niñas es menor que o igual que el número total de niños y niñas.
Las reglas de validación pueden definirse mediante el interfaz de usuario y lanzarse después para chequear los datos
existentes en el sistema. Al lanzar reglas de validación, el usuario puede especificar las unidades organizativas y los
periodos para los que chequear datos, ya que lanzar un chequeo sobre todos los datos existentes puede llevar mucho
tiempo y ni siquiera ser relevante para ese usuario. Cuando los chequeos terminan, se presenta un reporte al usuario
con las infracciones de validación explicando qué valores de datos necesitan corregirse.
Los chequeos de reglas de validación también están incorporados al proceso de entrada de datos, de modo que cuando
el usuario ha completado un formulario es posible lanzar las reglas para chequear los datos de ese único formulario,
antes de cerrarlo.
13.4.4. Análisis de outliers (valores atípicos)
El análisis de outliers basado en la desviación típica ofrece un mecanismo para revelar qué valores están numéricamente
alejados del resto de los datos. Estos son los outliers o valores atípicos. Los outliers pueden aparecer por casualidad,
pero a menudo indican un error de medida o una distribución fuertemente alargada (que deriva en cifras muy elevadas).
En el primer caso, uno desea descartar esos datos, mientras en el segundo hay que ser cautos al utilizar herramientas o
interpretaciones que asumen una distribución normal de los datos. El análisis está basado en una distribución normal
estándar.
13.4.5. Reportes de integridad y de puntualidad
Los reportes de integridad muestran cuántos sets de datos (formularios) han sido presentados por cada unidad
organizativa y periodo. Podemos utilizar uno de los tres métodos disponibles para calcular la integridad: (1) con el
botón de integridad en la entrada de datos, (2) con un set definido de elementos de datos obligatorios, o (3) con el total
de valores de datos registrados para un set de datos.
Los reportes de integridad también muestran qué unidades organizativas en una región (área) están reportando a tiempo
y el porcentaje de establecimientos de salud puntuales en un área determinada. El cálculo de puntualidad se basa en un
parámetro de sistema llamado "Días tras el fin de periodo" que califica temporalmente el envío de los datos.
54
Indicadores
Qué es un indicador
Capítulo 14. Indicadores
Este capítulo cubre los siguientes temas:
• Qué es un indicador
• Propósito de los indicadores
• Colección de datos guiada por indicadores
• Gestión de indicadores en DHIS 2
A continuación se detalla cada tema.
14.1. Qué es un indicador
En DHIs 2 el indicador es el elemento central del análisis de datos. Un indicador representa una fórmula calculada
basada en elementos de datos, es decir, no es sólo una figura sino una proporción en relación a algo. Tiene un numerador
que representa los elementos de datos medidos, y un denominador donde los elementos de datos se miden en proporción
de. Por tanto, los indicadores se componen de fórmulas de estos elementos de datos, más un factor (1, 100, 100 000)
para fijar la medida correcta. Por ejemplo, el indicador "Cobertura BCG < 1 año" se define por una fórmula con
factor 100 (para obtener el porcentaje), numerador ("Dosis de BCG entregadas a menores de 1año") y un denominador
("Población diana menor de 1 año"). El indicador "Tasa de exclusión DPT1 a DPT3" es una fórmula de 100 % x ("Dosis
entregadas DPT1"- "Dosis DPT3 entregadas") / ("Dosis DPT1 entregadas").
Indicador = numerador / denominador x factor
Tabla 14.1. Ejemplos de indicadores
Indicador
Fórmula
Numerador
Denominador
Factor
Totalmente
inmunizados <1 año
Totalmente
inmunizados/
Población < 1 año x
100
Totalmente
inmunizados
Población < 1
100 (Porcentaje)
Tasa de Mortalidad
Materna
Muertes maternas/
Nacidos vivos x 100
000
Muertes maternas
Nacidos vivos
100 000 (la tasa de
MM se mide en 100
000)
14.2. El propósito de los indicadores
Los indicadores son mucho más útiles para el análisis que los datos en bruto. Dado que son proporciones, podemos
compararlos en el tiempo y en el espacio, lo cual es muy importante porque las unidades de análisis y comparación,
como los distritos, varían en tamaño y cambian con el paso del tiempo. Un distrito con 100 casos de una enfermedad
concreta puede tener mayor tasa de incidencia que un distrito con 1000 casos, si este último distrito está más de 10
veces más poblado que el anterior. Un indicador que mide la tasa de incidencia relativa a la población total puede
compararse sin importar qué población neta es en realidad.
Los indicadores por tanto permiten las comparaciones, y son la herramienta principal para analizar datos. DHIS2
debería proveer indicadores relevantes de análisis a todos los programas de salud, no solo los datos en bruto. La mayoría
de módulos de reporte en DHIS 2 soporta tanto elementos de datos como indicadores y podemos combinarlos en
reportes personalizados.
14.3. Recolección de datos por indicadores
Dado que los indicadores son más adecuados para el análisis que los elementos de datos, el cálculo de indicadores
debería ser el motor fundamental de la recogida de datos. Una situación usual es que muchos datos se registran sin
55
Indicadores
Gestión de indicadores
ser luego utilizados para ningún indicador, lo que reduce significativamente la usabilidad de los datos. O bien los
elementos de datos capturados se incluyen en indicadores utilizados para la gestión de la información de salud o bien
probablemente no deberán si quiera recolectarse.
Para el propósito de la implementación, deberemos definir e implementar en DHIS2 una lista de indicadores usados
para la gestión. Para el análisis, la capacitación de usuarios deberá enfocarse en el manejo de indicadores y porqué son
más adecuados para este propósito que los elementos de datos.
14.4. Gestión de indicadores
Podemos añadir, eliminar o modificar indicadores en cualquier momento en DHIS2 sin que ello afecte a los datos. Los
indicadores no se guardan como valores en DHIS2, sino como fórmulas, que se calculan siempre que el usuario las
necesite. Por tanto un cambio en las fórmulas solo conlleva que se llama a diferentes elementos de datos a la hora de
usar el indicador para el análisis, pero sin cambios en los valores de los datos subyacentes. Para tener más información
sobre cómo gestionar indicadores, visitar el capítulo de indicadores en la Documentación de Usuario de DHIS2.
56
Los usuarios y sus roles
Usuarios
Capítulo 15. Los usuarios y sus roles
DHIS 2 incluye una solución avanzada para la gestión detallada de usuarios y de los roles de los usuarios. El sistema
es completamente flexible en cuanto al número y tipo de usuarios y roles permitidos.
15.1. Usuarios
Un usuario en el contexto DHIS 2 es una persona que utiliza el software. Cada usuario en DHIS 2 tiene una cuenta de
usuario que se identifica con un nombre de usuario. La cuenta de usuario permite al usuario autenticarse en los servicios
del sistema y recibir autorización para acceder a ellos. Para loguearse (autenticarse) el usuario deberá introducir una
combinación válida de nombre de usuario y contraseña. Si la combinación coincide con la pareja registrada en la base
de datos, se permitirá el acceso al usuario.
Además, un usuario debería dar también su nombre, apellidos, email y número de teléfono de contacto. ESta
información es importante para luego trabajar correctamente creando nuevos usuarios, ya que ciertas funciones en
DHIS 2 necesitan enviar emails para notificar a los usuarios sobre eventos importantes. También es útil poder
comunicarse directamente con usuarios por email y teléfono para discutir asuntos de gestión de datos o para identificar
potenciales problemas con el sistema.
Un usuario en DHIS 2 está asociado a una unidad organizativa. Esto implica que cuando creamos una nueva cuenta
de usuario esa cuenta debería estar asociada a la ubicación donde trabaja el usuario. Por ejemplo, cuando creamos una
cuenta de usuario para un digitador de datos en un distrito, esa cuenta de usuario debería estar vinculada a ese distrito
concreto donde trabaja. El enlace entre la cuenta de usuario y la unidad organizativa tiene muchas implicaciones en
la operatividad del sistema:
• En el módulo de entrada de datos, un usuario solo puede introducir datos sobre la unidad organizativa que tiene
asociada y las unidades organizativas más abajo en la jerarquía. Por ejemplo, un digitador de datos en un distrito
puede registrar datos solo para su distrito y los establecimientos que pertenecen a ese distrito.
• En el módulo de usuario, un usuario solo puede crear nuevos usuarios en la unidad organizativa que tiene asociada
o en las unidades inferiores a esa en la jerarquía.
• En el módulo de reportes, un usuario solo puede ver reportes sobre su unidad organizativa e hijos. (Esto es algo que
consideramos positivo abrir para permitir reportes comparativos entre unidades.)
Un rol de usuario en DHIS 2 está asociado también a un set de roles de usuario. Estos roles se tratan en la sesión
siguiente.
15.2. Roles de usuario
Un rol de usuario en el contexto de DHIS 2 es un grupo de autorización. Una autorización en este sentido significa el
permiso para realizar una o varias tareas específicas. Por ejemplo, un rol de usuario puede contener autorizaciones para
crear un nuevo elemento de datos, actualizar una unidad organizativa o ver un reporte. Estos grupos de autorizaciones
constituyen un rol de usuario.
En el sistema de salud los usuarios están agrupados lógicamente respecto de las tareas que realizan y el puesto que
ocupan. Algunos ejemplos de esos puestos son:
1. Gestores nacionales de salud
2. Oficiales del sistema de información de salud nacional
3. Gestores provinciales de salud
4. Oficiales distritales de información y registros de salud
5. Oficiales por establecimiento de información y registros de salud
6. Operadores de entrada de datos (digitadores)
57
Los usuarios y sus roles
Roles de usuario
Cuando creamos roles de usuario debemos tener en cuenta estos puestos del sistema de salud y muchas veces tendrá
sentido crear roles de usuario específicos para cada uno de estos puestos. El proceso de creación de roles de usuario
debería estar alineado con el proceso de decisión de qué usuarios realizan qué tareas en el sistema.
Primero, definiremos qué usuarios deberían cubrir el rol de administradores del sistema. Generalmente serán parte
de los miembros de la división del SIS nacional y tendrán autorizaciones totales en el sistema. Segundo, crearemos
un rol de usuario aproximadamente para cada posición. Aquí debereemos hacer una consideración cuidadosa de qué
autorizaciones damos a cada rol. Una regla importante es que cada sol debería darse solo a las autorizaciones necesarias
para realizar bien su trabajo, no más. Cuando operamos un sistema de información extenso y centralizado existe
la necesidad de coordinar el trabajo entre todas las personas involucradas. Y esto es más fácil si solo aquellos que
supuestamente realizarán una tarea tienen autorización para hacerla.
Este ejemplo puede resaltar este asunto: la tarea de configurar la estructura básica (los metadatos) del sistema es crítica
para el sistema y solo deberían realizarla los administradores. Esto significa que el rol de usuario administrador del
sistema debería tener autorización para añadir, actualizar y eliminar elementos centrales del sistema como son los
elementos de datos, indicadores y sets de datos. Si permitiéramos a otros usuarios fuera del equipo de administradores
moidificar estos elementos, tendríamos fuertes problemas de coordinación.
Los gestores nacionales y provinciales de salud a menudo están encargados del análisis y monitoreo de los datos. Así
que este grupo de usuarios debería ser autorizado a acceder y usar el módulo de reportes, de SIG, de calidad de datos y
de dashboard. Sin embargo, no necesitarían autorización para introducir datos o actualizar elementos de datos o sets de
datos. Los oficiales distritales de información muchas veces están a cargo de registrar en el sistema los datos que vienen
de los establecimientos de salud que no pueden hacerlo directemente, y también de monitorear, evaluar y analizar los
datos. Esto implica que estos usuarios necesitan acceso a todos los módulos de análisis y validación mencionados antes
además de la autorización para acceder y usar el módulo de entrada de datos.
Adicionalmente, un rol de usuario está asociado con una colección de sets de datos. Esto afecta al módulo de entrada
de datos en que el usuario solo puede introducir datos de los sets de datos registrados para su rol de usuairo. Muchas
veces esto es útil en situaciones en que queremos permitir a los oficiales de determinados programas de salud registrar
los datos solo de sus formularios relevantes.
Un usuario puede tener asociados uno o cualquier cantidad de roles de usuario. En el caso de tener muchos roles de
usuario, el usuario es privilegiado en el conjunto de todas las autorizaciones y sets de datos incluidos en los roles.
Esto significa que los roles de usuario pueden mezclarse y ajustarse para propósitos especiales en lugar de crear adhoc otros roles nuevos.
Una parte importante de la gestión de usuarios es controlar a qué usuarios permitir crear nuevos usuarios con qué
autorizaciones. En DHIS 2 podemos controlar qué usuarios pueden realizrar esta tarea. En este proceso el principio
clave es que un usuario solo puede dar autorización y acceso a sets de datos que ese propio usuario tiene. Los usuarios
a nivel nacional, provincial y distrital suelen ser pocos y pueden ser creados y gestionados por los administradores
del sistema directamente. Si la mayoría de establecimientos de salud registran sus datos directamente en el sistema,
el número de usuarios puede hacerse inmanejable. La experiencia sugiere delegar y descentralizar esta labor en los
oficiales de distrito para que el proceso sea más eficiente y apoye mejor a los usuarios de los establecimientos.
58
Una perspectiva general de las herramientas
de análisis de datos
Herramientas de análisis de datos
Capítulo 16. Una perspectiva general de
las herramientas de análisis de datos
Este capítulo da una panorámica a las herramientas disponibles para el análisis de datos en DHIs 2 junto con una
descripción del propósito y ventajas de cada una. Si buscamos una guía detallada sobre cómo usar cada una de ellas,
recomendamos seguir leyendo el Manual de Usuario después de este capítulo.
16.1. Herramientas de análisis de datos
La sección siguiente da una descripción de cada herramienta.
16.1.1. Reportes estándar
Los reportes estándar son informes con diseños predefinidos. Esto significa que los reportes están accesibles fácilmente
en pocos clicks y los usuarios con cualquier nivel de destreza pueden utilizarlos. El reporte puede contener estadísticas
en forma de tablas y gráficas y se pueden confeccionar para la mayoría de necesidades. La solución de reportes en
DHIS2 se basa en los JasperReports y los reportes normalmente se diseñan con el editor iReport. Incluso cuando el
diseño del reporte es fijo, es posible cargar datos dinámicamente en el reporte de cualquier unidad organizativa y de
diversos periodos de tiempo.
16.1.2. Reportes de sets de datos
Los reportes de sets de datos muestran el diseño de los formularios de entrada de datos como reportes ingresados con
datos agregados (en contraposición a los datos capturados de bajo nivel). Este reporte es fácilmente accesible para
todo tipo de usuarios y nos acerca rápidamente los datos agregados. A menudo existen requisitos heredados de otros
sistemas para ver los formularios de entrada de datos como reportes, y lo podemos realizar con esta herramienta. El
reporte de sets de datos soporta todo tipo de formularios de entrada de datos incluidos los formularios de secciones
y personalizados.
16.1.3. Reportes de completitud de datos
El reporte de completitud de datos produce estadísticas para el grado de completitud o integridad de los formularios de
datos. Los datos estadísticos se pueden analizar por sets de datos individuales o por una lista de unidades organizativas
con un "padre" común en la jerarquía. Nos da un porcentaje del total completado y de los registros completados
puntualmente. Podemos usar varias definiciones de completitud en base a las estadísticas: primero basándonos en el
número de sets de datos marcados manualmente como "Completo" por el usuario que introduce los datos; segundo,
basándonos en si todos los elementos de datos marcados como obligatorios se han rellenado en un set de datos; tercero,
basándonos en el porcentaje del número de campos rellenados sobre el número total de campos del set de datos.
16.1.4. Reportes estáticos
Los reportes estáticos ofrecen dos métodos para enlazar con los recursos existentes en la interfaz de usuario. Primero, da
la posibilidad de enlazar a un recurso en Internet mediante la URL. Segundo, da la opción de subir archivos al sistema
y enlazarlos. El tipo de ficheros que se pueden subir puede ser un documento, imagen o video. Algunos ejemplos
de documentos a enlazar son informes estadísticos de salud, documentos normativos y planes anuales de acción. Las
URL pueden apuntar a sitios web relevantes como la página principal del Ministerio de Salud, fuentes de información
relacionadas con la salud. Además se puede usar como interfaz para herramientas de análisis web de terceros, enlazando
a sus recursos específicos. Un ejemplo es enlazar una URL de un reporte entregado por la plataforma de reporte BIRT.
59
Una perspectiva general de las herramientas
de análisis de datos
Reportes de distribución de unidades
organizativas
16.1.5. Reportes de distribución de unidades organizativas
El reporte de distribución de unidades organizativas muestra estadísticas de los establecimientos (unidades
organizativas) en la jerarquía basándose en su clasificación. La clasificación se basa en grupos de unidades
organizativas y sets de grupos. Por ejemplo los establecimientos pueden clasificarse por su tipo si los asignamos a un
grupo del set de grupos relativo al tipo de unidad organizativa (hospital, centro de salud, etc). El reporte de distribución
produce el número de establecimientos de cada clase y puede ser generado para todas las unidades organizativas y
para todos los sets de grupo del sistema.
16.1.6. Tablas de reporte
Las tablas de reporte se basan en datos agregados en formato tabular. Una tabla de reporte puede usarse como un
informe independiente o como fuente de datos para el diseño de otros reportes estándar más sofisticados. El formato
tabular puede cruzarse con el número de dimensiones que queramos, y que aparecerán como columnas. Puede contener
indicadores y elementos de datos, datos agregados y datos de completitud de los sets de datos. Puede contener también
periodos relativos que permiten que el reporte pueda ser reutilizado cuando queramos. Puede contener parámetros
seleccionables por el usuario para las unidades organizativas y periodos para permitir que el reporte se reutilice en
todas las unidades organizativas de la jerarquía. La tabla de reporte puede estar limitada a los resultados superiores y
se puede ordenar en orden creciente o decreciente. Cuando generamos una tabla de reporte, podremos descargar los
datos como fichero PDF, Excel, CSV y reporte Jasper.
16.1.7. Gráficas
El componente gráfico ofrece una gran variedad de gráficas incluyendo los diagramas de barras, de puntos y tarta
estándar. Las gráficas pueden contener indicadores, elementos de datos, periodos y unidades organizativas en ambos
ejes x e y, así como una línea fija horizontal de umbral. Las gráficas pueden verse directamente como parte del panel
de control (dashboard), tal y como explicaremos más adelante.
16.1.8. Tablas Web dinámicas
Las tablas web dinámicas ofrecen un rápido acceso a datos estadísticos en formato tabular y permiten "pivotar" tantas
dimensiones como queramos: indicadores, elementos de datos, unidades organizativas y periodos para que aparezcan
en las columnas y filas y así crear vistas separadas. Cada celda de la tabla se puede visualizar como un diagrama de
barras.
16.1.9. SIG
El módulo SIG (Sistema de Información Geográfica) permite visualizar datos agregados en los mapas. El módulo SIG
puede hacer mapeo temático de polígonos, como provincias y distritos, y de puntos, como establecimientos de salud, en
distintas capas. Estas capas pueden mostrarse a la vez y pueden combinarse con otras capas personalizadas. Podemos
navegar fácilmente por el histórico de vistas de mapas, guardadas para acceder posteriormente o guardadas en el disco
como ficheros imagen. El módulo SIG tiene separaciones de clases automáticas y fijas para el mapeo temático, sets
de leyendas predefinidos y automáticos, permite mostrar etiquetas (nombres) de los elementos geográficos y permite
medir la distancia entre dos puntos del mapa. Podemos ver el mapeo de cualquier indicador o elemento de datos, y para
cualquier nivel de la jerarquía de unidades organizativas. Hay también una capa especial para mostrar establecimientos
en el mapa donde cada uno se representa con un símbolo según su tipo.
16.1.10. Tablas My Datamart y tablas dinámicas Excel
El propósito de la herramienta My Datamart es permitir a los usuarios un acceso total a los datos agregados incluso con
conexiones a Internet poco fiables. Esta herramienta está formada por una aplicación ligera de cliente que se instala en
las computadoras de los usuarios. Este cliente se conecta al servidor central online que ejecuta la instancia de DHIS 2,
descarga los datos agregados y los almacena en una base de datos en la computadora local. Esta base de datos puede
usarse para conectar herramientas de terceros como tablas dinámicas de MS Excel, que es una herramienta potente para
60
Una perspectiva general de las herramientas
de análisis de datos
Tablas My Datamart y tablas dinámicas
Excel
el análisis y la visualización de datos. Esta solución implica que se requieren periodos cortos de conexión a Internet
para sincroniczar la base de datos cliente con la base de datos central online, y que después de este proceso los datos
están disponibles localmente independientemente de la conectividad. Para conocer My Datamart en profundidad, ver
el capítulo dedicado expresamente al tema.
61
Tablas dinámicas y la herramienta
MyDatamart
Diseño de tablas dinámicas
Capítulo 17. Tablas dinámicas y la
herramienta MyDatamart
La tabla dinámica Excel (véase la imagen de pantalla a continuación) es una potente y dinámica herramienta de análisis
que podemos enlazar automáticamente con los datos en DHIS 2. Mientras la mayoría de herramientas de reporte en
DHIS 2 están limitadas en cuántos datos pueden presentar a la vez, las tablas dinámicas están diseñadas para mostrar
buenas vistas con múltiples elementos de datos o indicadores, y unidades organizativas y periods (véase el ejemplo
abajo). Es más, las características dinámicas de pitovar y examinar a fondo son muy distintas de las de hojas de datos
estáticas o reportes web, y esto las convierte en una herramienta muy útil a los usuarios de información que quieren
hacer análisis más profundos y manejar las vistas de los datos de forma más dinámica. Combinando esto con las
conocidas capacidades gráficas de Excel, la herramienta de tablas dinámicas se ha convertido por mucho tiempo en
una herramienta de análisis muy popular entre los usuarios más avanzados de DHIS.
Con el cambio reciente hacia despliegues online, las tablas dinámicas offline en Excel también son una alternativa
útil a las herramientas de reporte online, ya que permiten el análisis local de los datos sin conexión a Internet, lo que
puede ser una ventaja en conexiones inestables o costosas. Así, Internet solo es necesario para descargar nuevos datos
del servidor online, y tan pronto como los datos estén en local, trabajar con tablas dinámicas no requiere conexión.
La herramienta MyDatamart, que se explica en detalle más abajo, ayuda a los usuarios a mantener un fichero local de
datos (una pequeña base de datos) que se actualiza por Internet contra el servidor online, y que entonces puede usarse
como fuente de datos offline para cargar datos a las tablas dinámicas.
17.1. Diseño de tablas dinámicas
Normalmente un fichero de tabla dinámica Excel configurado para DHIS 2 contiene múltiples hojas de trabajo con
una tabla dinámica por página. Una tabla puede estar formada por valores de datos en bruto (elementos de datos)
o valores de indicadores, y generalmente se nombrará según el nivel de la jerarquía de unidades organizativas en
el que están agregados los datos fuente, así como el tipo de periodo (frecuencia, por ejemplo mensual, anual) de
los datos. Un fichero de tablas dinámicas estándar en DHIS 2 incluye las siguientes tablas dinámicas: indicadores
distritales, datos distritales mensuales, datos distritales anuales, indicadores por establecimiento, datos mensuales por
establecimiento, datos anuales por establecimiento. Además puede haber más tablas especializadas que se enfocan en
programas específicos y/o en otros tipos de periodos.
63
Tablas dinámicas y la herramienta
MyDatamart
Conectando con la base de datos de DHIS 2
Una caractarerística bien popular de las tablas de datos es la capacidad para arrastrar y mover los campos entre
las tres páginas/filtros de posiciones, filas y columnas, y así cambiar totalmente la vista de los datos. Podemos ver
estos datos como dimensiones de los valores de datos y representar las dimensiones en el modelo de datos DHIS;
unidad organizativa (un campo por nivel), elementos de datos o indicadores, periodos, y también listados extendidos
dinámicamente de dimensiones adicionales que representan sets de grupos de unidades organizativas/indicatores/
elementos de datos y categorías de elementos de datos (véase otros capítulos de esta guía para más detalle). De hecho
una tabla dinámica es yna herramienta excelente para representar las muchas dimensiones creadas en DHIS 2, y facilita
enormemente acercarnos o alejarnos de cada dimensión, por ejemplo mirar a valores de datos en bruto por grupos
individuales de edad o simplemente por sus totales, o en combinación con otras dimensiones como género. Todas las
dimensiones creadas en DHIs 2 se reflejarán en la lista de campos disponibles de cada tabla dinámica, y entonces está
en mano del usuairo seleccionar con cuáles quiere trabajar.
Es importante entender que los valores en las tablas dinámicas no son editables y que todos los nombres y números se
cargan directamente desde la base de datos de DHIS 2, lo cual se diferencia de una hoja de cálculo normal. Para poder
editarlos, tendremos que copiar los contenidos de una tabla dinámica en una hoja de cálculo normal, pero esto rara
vez es necesario ya que todos los nombres pueden editarse en DHIs 2 (y por tanto reflejarse en la tabla dinámica en
la siguiente actualización). Los nombres (etiquetas) de cada campo sin embargo son editables, pero no sus contenidos
(valores).
17.2. Conectando con la base de datos de DHIS 2
Cada tabla dinámica tiene una conexión con la base de datos de DHIS 2 y utiliza una fuente dinámica (petición SQL)
en la base de datos para hacerse con los datos. Estas peticiones jalan todos los datos de las tablas datamart, de modo que
es importante tener el datamart actualizado todo el tiempo para cargar los datos más recientes en las tablas dinámicas.
Una tabla dinámica puede conectarse a la base de datos de la computadora local o de un servidor remoto. Esto lo
hace muy apropiado para una red local donde hay solo una base de datos compartida y múltiples computadoras cliente
utilizando tablas dinámicas. Excel también puede conectarse a bases de datos sobre Linux. La conexión con la base
de datos utilizada en las tablas dinámicas se especifica en una fuente de datos ODBC en las computadoras Windows
que ejecutan tablas dinámicas.
En despliegues online recomendamos que la conexión a los datos de DHIS 2 se haga utilizando la herramienta
MyDatamart, que crea y actualiza un fichero de datos local (base de datos) a la que Excel puede conectarse. La
herramienta MyDatamart se detalla a continuación.
17.3. Manejando grandes cantidades de datos
La cantidad de datos en una base de datos de DHIS 2 puede sobrepasar fácilmente las capacidades de Excel. una tabla
con cerca de un millón de valores (filas de datos) tiende a reaccionar peor ante actualizaciones (refresco) y operaciones
dinámicas, y en algunas computadoras Excel dará errores de memoria al manear tablas de estos tamaños. Normalmente,
cuanto más potente sea la computadora, más datos puede manejar, pero la cota superior parece estar en torno a un
millón de filas incluso en las computadoras más modernas.
Para afrontar este problema la configuración estándar de tablas dinámicas en DHIS divide los datos en muchas
tablas dinámicas. Hay diferentes formas de dividir los datos: por nivel de agregación de unidad organizativa (según
profundidad), por cobertura o área limítrofe de unidad organizativa (según extensión), por periodo (por ejemplo un año
de datos de una vez), o por grupos de elementos de datos o de indicadores (por ejemplo por programas o temas de salud).
La aproximación más eficiente es agregar por el menor nivel en la jerarquía de unidades organizativas, ya que reduce
la cantidad de data por el factor del número de establecimientos de salud en un país. Normalmente no hay necesidad de
mirar en todos los establecimientos de salud de un país al mismo tiempo, sino solo en un área limitada (un municipio o
provincia). Y cuando hay la necesidad de datos de todo el país, éstos pueden darse con agregados por distrito o similar.
En una oficina de distrito o provincia los usuarios generalmente tendrán datos de nivel de establecimiento de salud
solo para su propio área, y entonces para las áreas colindantes se agregarán uno o dos niveles para reducir el tamaño
de los datos, pero todavía permitiendo la comparación, divididos por ejemplo en dos tablas: datos de establecimiento
y datos de distrito, y similares para los valores de indicadores. Dividir los datos por periodo o por grupos de elementos
de datos o indicadores funciona más o menos de la misma manera, y podemos hacerlo en combinación con la división
64
Tablas dinámicas y la herramienta
MyDatamart
La herramienta MyDatamart
por unidades organizativas o en lugar de ésta. Por ejemplo, es posible analizar para un programa de salud concreto
unos pocos elementos de datos a nivel de establecimiento de salud para todo el país. Esta división se controla mediante
las vistas dinámicas en la base de datos donde especificamos qué valores de datos usar.
17.4. La herramienta MyDatamart
Al utilizar despliegues online y un solo servidor central (y base de datos) el uso local de tablas dinámicas se hace más
difícil, ya que Excel conecta directamente a la base de datos para buscar los datos. Esto significa que Excel (y cualquier
computadora que utilice DHIS2) necesitaría detalles de conexión y acceso a la base de datos en el servidor, lo cual no
siempre queremos. Es más, la operación de refresco (actualización de la tabla dinámica) en Excel vacía completamente
la tabla antes de recargar todos los datos de nuevo (los viejos y los nuevos), lo que conlleva descargas grandes y
con duplicados a través de Internet siempre que conectemos con el servidor online. La solución a estos problemas
ha sido montar y mantener una "copia" actualizada de la base de datos central en cada oficina local donde utilicen
tablasd dinámicas Excel. Estas bases de datos locales se llaman datamarts y se montan específicamente para hacer de
fuentes de datos para herramientas de análisis de datos como Excel. La herramienta MyDatamart es una aplicación de
reciente desarrollo (mayo de 2011) que crea un fichero de datamart en una computadora local y ayuda a los usuarios a
actualizarla contra el servidor central. Las tablas dinámicas en Excel conectan solo con el datamart local y no necesitan
saber nada acerca del servidor central.
La utilización de MyDatamart reduce dramáticamente el tamaño de descargas cuando necesitamos actualizar de forma
rutinaria los ficheros locales Excel contra el servidor central, en comparación con una conexión directa desde Excel.
También hace que los usuarios locales se sientan más cómodos teniendo una copia de sus datos en su computadora
local y no dependan de una conexión a Internet o del estado del servidor central para accederlos. La figura siguiente
muestra el diagrama de flujo del datamart.
65
Tablas dinámicas y la herramienta
MyDatamart
Utilizando tablas dinámicas Excel y
MyDatamart - un ejemplo práctico
17.5. Utilizando tablas dinámicas Excel y MyDatamart - un ejemplo
práctico
Los detalles de utilización de la herramienta MyDatamart se explican en un manual de usuario a parte, y esta sección
solo pretende explicar el típico diagrama de flujo que tenemos al usar la herramienta junto con las tablas dinámicas.
17.5.1. Descargar y lanzar la herramienta MyDatamart por primera vez
MyDatamart es una herramienta pequeña fácil de descargar y ejecutar de inmediato. Descargaremos mydatamart.exe
en el Escritorio y lo ejecutaremos haciendo doble click en el fichero. Lo primero que necesitamos es crear un nuevo
fichero datamart, y luego tipear los detalles de login necesarios para acceder al servidor central (UTL, nombre de
usuario, contraseña). La herramienta se conectará al servidor (en este punto necesitamos la conexión a Internet) y
verificará la información de autenticación. El siguiente paso es descargar todos los metadatos del servidor, es decir
unidades organizativas, elementos de datos, indicadores, grupos, etc. Esto puede demorarse un tiempo dependiendo de
las especificaciones técnicas de la computadora local y de la velocidad de la conexión, pero es un paso que rara vez
necesitaremos repetir después de esta primera descarga. Una vez que la herramienta conoce la jerarquía de unidades
organizativas podemos especificar a qué unidad organizativa "pertenecemos" y el nivel de análisis que nos interesa.
Estos son los parámetros de configuración que limitarán la información de qué unidades organizativas descargaremos.
Lo siguiente es descargar los datos del servidor, y especificar qué periodos descargar.
17.5.2. Crear y distribuir las tablas dinámicas
Lo primero que necesitamos es descargar e instalar un driver (controlador) ODBC para SQLite, que es el servidor de
base de datos que ejecuta el datamart local. Las conexiones a la base de datos de las tablas dinámicas dependerán de
este driver y fallarán si no lo instalamos.
El siguiente paso es crear las tablas dinámicas. Esta es una tarea única, ya que el fichero podrá luego reutilizarse como
plantilla en otras ubicaciones que se conecten a la misma base de datos central. La herramienta MyDatamart puede
producir un fichero Excel plantilla que tenga definidas todas las conexiones necesarias a la base de datos. Esto ayudará
enormemente en el proceso y buena parte del trabajo aquí está en seleccionar qué campos usar en qué tabla y darle
nombres apropiados. El manual de usuario tiene instrucciones detalladas sobre cómo crear una tabla dinámica usando
conexiones MyDatamart.
Una vez que el fichero plantilla de Excel está disponible es cuestión de distribuirlo en todas las oficinas locales que
utilizarán tablas dinámicas y asegurarnos de que las conexiones definidas son válidas en todas esas computadoras
locales. Los detalles de conexión en Excel dependen de que el driver ODBC esté disponible y del nombre y ubicación
del fichero datamart. Podemos unificar todos los ficheros locales datamart (por nombre y ubicación, por ejemplo: "C:
\dhis2\dhis2.dmart"), o podemos usar la herramienta MyDatamart para actualizar los detalles de conexión en un fichero
Excel existente para que encaje con la ubicación del fichero local datamart.
17.5.3. Actualizar MyDatamart
Siempre que haya nuevos datos disponibles en el servidor central, por ejemplo, cada mes, los usuarios tendrán que
abrir la herramienta MyDatamart, loguearse en el servidor, y seleccionar los meses para descargar. Una vez que la
descarga ha terminado los datos están disponibles localmente en el fichero datamart.
17.5.4. Actualizar las tablas dinámicas
Cuando el fichero datamart se ha actualizado, los usuarios pueden actualizar las tablas dinámicas utilizando la función
Refresco, una vez por cada tabla. Es importante que recordemos guardar el fichero Excel antes de refrescar todas las
tablas.
66
Tablas dinámicas y la herramienta
MyDatamart
Repetimos los pasos 3 y 4 cuando haya
nuevos datos disponibles en el servidor
central
17.5.5. Repetimos los pasos 3 y 4 cuando haya nuevos datos disponibles en el
servidor central
Siempre que haya nuevos datos en el servidor repetiremos los pasos 3 y 4 (los últimos) para actualizar las tablas
dinámicas y poder tener acceso a los datos más recientes.
67
DHIS como plataforma
Capítulo 18. DHIS como plataforma
DHIS puede verse como una plataforma de muchos niveles. En primer lugar, la base de datos de la aplicación está
diseñada atómicamente teniendo en mente la flexibilidad. Las estructuras de datos como los elementos de datos, las
unidades organizativas, los formularios y los roles de usuario pueden definirse de forma totalmente libre desde el
interfaz de usuario de la aplicación. Esto hace posible que el sistema se pueda adaptar a multitud de contextos locales y
casos de uso. Hemos visto que DHIS soporta los grandes requisitos de captura rutinaria de datos y análisis necesarios
en implementaciones a nivel de país. También es posible que DHIS sirva como sistema de gestión para ámbitos como
la logística, laboratorios y contabilidad.
En segundo lugar, debido al diseño modular de DHIS se puede ampliar con módulos adicionales de software. Estos
módulos pueden convivir con los módulos centrales de DHIS y también integrarse en el portal web de DHIS y en el
sistema de menú. Esta es una característica muy potente ya que permite extender el sistema con funcionalidades extra
cuando sea necesario, normalmente para requisitos específicos del país como se apuntó anteriormente.
La otra cara de la extensibilidad modular del software es que pone ciertos límites al proceso de desarrollo software.
Los desarrolladores que crean funcionalidad extra están acotados a la tecnología DHIS en términos de lenguaje de
programación y entornos software, además de las restricciones puestas en el diseño de módulos por la solución de portal
web DHIS. Además, estos módulos han de incluirse en el software DHIS cuando el software se monta y despliega en
le servidor web, y no dinámicamente con el servidor en marcha.
Para salvar estas limitaciones y lograr un engranaje holgado entre la capa de servicio de DHIS y los aparatos software
adicionales, el equipo de desarrollo de DHIS decidió crear un API Web. El API Web cumple con las normas de estilo
de arquitectura REST. Esto implica que:
• El API web nos proporciona un interfaz navegable y comprensible a las computadoras del modelo de datos completo
de DHIS. Así por ejemplo, podemos acceder al listado completo de elementos de datos, y luego navegar usando
el hipervínculo hacia el elemento de datos que nos interesa, y luego navegar usando el hipervínculo a la lista de
formularios a los que pertenece ese hipervínculo. Los clientes solo podrán hacer transiciones de estado utilizando
los hipervínculos que se embeben dinámicamente en las respuestas del servidor.
• Podemos acceder a los datos a través de un interfaz uniforme (URLs) utilizando un protocolo conocido. No hay
formatos o protocolos de transporte pripios, sino solo el protocolo HTTP que está bien probado y extendido, y es la
piedra angular de la Web hoy en día. Esto implica que los desarrolladores de terceros pueden desarrollar software
utilizando el modelo de datos DHIS y sus datos sin conocer la tecnología específica de DHIS o cumpliendo los
requisitos de diseño de DHIS.
• Todos los datos incluyendo los metadatos, reportes, mapas y gráficas, conocidos como recursos en terminología
REST, pueden recuperarse en los formatos de representación más populares de la Web, como HTML, XML, JSON,
PDF y PNG. Estos formatos son ampliamente soportados en aplicaciones y lenguajes de programación y dan un
amplio margen de opciones de implementación a los desarrolladores externos.
69
DHIS como plataforma
Portales Web
Hay muchos escenarios donde las soluciones software adicionales pueden conectarse con el API Web de DHIS.
18.1. Portales Web
Para empezar, los portales web se montan sobre el API Web. Un portal web en este sentido es un sitio web que
funciona como punto de acceso a la información de una cantidad potencialmente muy grande de fuentes de datos, que
normalmente comparten una temática común. El rol del portal web es hacer que estas fuentes de datos estén disponibles
fácilmente, de forma estructurada en una pantalla común y ofrecer a los usuarios unas visualizaciones comprensibles
de los datos.
Repositorio de datos agregados: un portal web enfocado al sector salud puede usar DHIS como la principal fuente
para datos agregados. El portal puede conectarse al API Web y comunicarse con recursos relevantes como los mapas,
gráficas, reportes, tablas y documentos estáticos. Estas vistas de datos permiten visualizar datos agregados basados
en peticiones sobre las dimensiones de unidad organizativa, indicados o periodo. El portal puede añadir valor a la
accesibilidad de información de múltiples formas. Puede estructurarse de manera amigable y acercar la información a
usuarios poco experimentados. Puede también aportar aproximaciones diversas a los datos, incluido:
• Temático - agrupando indicadores por tema. Ejemplos de temas pueden ser inmunización, salud materna,
enfermedades de notificación obligatoria y salud ambiental.
• Geográfico - agrupando los datos por provincias. Esto facilitaría la comparación de rendimiento y carga de trabajo.
Combinación y mezcla: El portal web no está limitado a cargar datos de un solo API Web - puede conectarse también
a tantos APIs como queramos y podemos usarlo para combinar datos de sistemas auxiliares dentro del ámbito de la
salud. Si está disponible el portal puede cargar datos especializados de seguimiento de sistemas logísticos y gestión
de fármacos ARV, de sistemas de gestión de cobros en establecimientos de salud y de sistemas de laboratorio que
monitorizan tests de enfermedades transmisibles. Podemos presentar los datos de todas estas fuentes de forma coherente
y significativa para lograr un mejor conocimiento de la situación del sector salud.
Repositorio de documentos: El portal web puede funcionar como repositorio de documentos en sí mismo (también
conocido como sistema de gestión de contenidos). Podemos subir y gestionar los documentos relevantes como los
70
DHIS como plataforma
Aplicaciones (Apps)
reportes publicados, datos de vigilancia, planes operativos anuales y preguntas frecuentes, en términos de propiedad,
control de versión y clasificación. Esto convierte el portal en un punto central para compartir y colaborar en la
documentación. La aparición de soluciones de repositorios y CMS de alta calidad, de software libre, como Alfresco y
Drupal, hace que esta aproximación sea factible y persuasiva.
Gestión del conocimiento: se refiere a prácticas para identificar, materializar y distribuir entendimiento y experiencia.
En nuestro contexto se relaciona con todos los aspectos de implementación y uso del sistema de información, como son:
• El diseño de la base de datos
• Uso del sistema de información y guía práctica de uso
• Líneas de acción en la formación de usuarios
• Utilización, análisis e interpretación de los datos
El conocimiento y el aprendizaje en estas áreas podemos materializarlo en la forma de planes, manuales, artículos,
libros, presentaciones de diapositivas, texto de ayuda insertado en la aplicación, sitios web de e-learning, foros,
preguntas frecuentes y mucho más. Es siempre importante que todos estos recursos se publiquen y sean accesibles
desde el portal Web.
Foro: El portal web puede alojar un foro de discusiones entre usuarios profesionales. La temática puede variar desde
ayuda en la realización de operaciones básicas en el SIS a discusiones sobre temas de análisis o interpretación de los
datos. Estos foros pueden también servir como una fuente interactiva de información y evolucionar de forma natural
hasta convertirse en un archivo muy valioso.
18.2. Aplicaciones (Apps)
En segundo lugar, los clientes de software de terceros que se ejecute en dispositivos como son los teléfonos móviles,
smartphones y tabletas pueden conectarse también al API Web de DHIS y leer y escribir los recursos relevantes.
Por ejemplo, los desarrolladores de terceros pueden crear clientes que funcionen con sistema operativo Android en
dispositivos móviles entregados a trabajadores comunitarios de salud que necesitan registrar el seguimiento de las
visitas, datos vitales en cada encuentro y recibir recordatorios de hitos o citas para la atención al paciente cuando viajan
a las comunidades. Estas aplicaciones de cliente pueden interactuar con los recursos del paciente y plan de actividades
publicados en el API Web de DHIS. Los desarrolladores no serán dependientes de tener un conocimiento profundo
del funcionamiento internod de DHIS, sino solo habilidades básicas para programación HTTP/Web y unas nociones
sobre el modelo de datos en DHIS. De hecho, comprender el modelo de datos de DHIS se facilita por la naturaleza
navegable del API Web.
18.3. Sistemas de Información
En tercer lugar, los desarrolladores de sistemas de información que deseen crear nuevas formas de visualizar y presentar
datos agregados pueden usar el API Web de DHIS como una capa de servicio en su sistema. El esfuerzo requerido para
desarrollar nuevos sistemas de información y mantenerlos en el tiempo con frecuencia está subestimado. En lugar de
comenzar de cero, es posible construir una aplicación sobre el API Web. Y la atención de los desarrolladores puede
centrarse en hacer representaciones y visualizaciones nuevas, innovativas y creativas, en la forma de por ejemplo los
componentes de dashboard, SIG y gráficas.
71
Conceptos para la adaptación local
Utilizando el servidor de traducción DHIS2
Capítulo 19. Conceptos para la
adaptación local
La localización implica la adaptación de una aplicación en otro ámbito local. Cuando implementamos DHIS2 en
un determinado país, será preciso asignar los recursos adecuados para traducir la apliación cuando sea necesario.
Deberemos considerar la traducción de elementos de la interfaz de usuario, mensajes, apariencia, formatos de fecha y
hora, moneda y otros aspectos. DHIS2 soporta la internacionalización del interfaz de usuario (i18n) mediante el uso
de strings de propiedad de Java. Cada elemento del interfaz de usuario tiene asignado una clave específica, que está
enlazada a un valor.
Como ejemplo consideraremos las siguientes parejas de clave/valor.
org_unit_tree=Árbol de unidades organizativas
error_occurred=Se produjo un error
En inglés la misma pareja de clave/valor sería así:
org_unit_tree=Organisation Unit Tree
error_occurred=An error has occurred.
Es importante resaltar que las claves (lo que precede al símbolo "=") son iguales en ambos casos, pero los valores (lo
que sigue al "=") está en el lenguaje correspondiente. Cada una de estas parejas de clave/valor necesitaría ser traducida
del lenguaje original (inglés) al lenguaje local (español). Cuando el usuario selecciona el español como lenguaje para
el interfaz de usuario, todos los strings aparecerán en español en lugar de en el idioma por defecto (inglés). Todos los
strings que no se hayan traducido aparecerán en inglés.
Hay diversos mecanismos para contextualizar o localizar DHIS2, dos de los cuales se explican en las secciones
siguientes. El portal Web es una herramienta muy útil para traducciones colaborativas de múltiples personas, aunque
se necesita una conexión online para utilizar este recurso. Una herramienta especial es el Editor de Recursos DHIS
i18n, que se ha desarrollado específicamente par facilitar la traducción de la aplicación de un lenguaje a otro y puede
usarse offline una vez que ya hemos obtenido una copia del código fuente de DHIS2.
19.1. Utilizando el servidor de traducción DHIS2
Existe una solución web para facilitar la traducción de DHIS2 en muchos lenguajes distintos. Podemos acceder
simplemente navegando a http://translate.dhis2.net y registrándonos con una cuenta con nombre de usuario, email y
contraseña. El servidor nos enviará entonces un email de confirmación que podremos usar para activar nuestra cuenta.
Cuando la hayamos activado, pulsamos en el enlace "Entrar" en la página principal del sitio, e introducimos el nombre
de usuario y contraseña.
La primera vez que nos logueamos, deberemos seleccionar nuestra configuración de personal pinchando en "Mi cuenta>Configuración". Aquí podemos seleccionar el lenguaje del interfaz, proyectos en los que colaborar, y lenguajes para
traducir. Nos aseguraremos de pinchar en "Guardar" después de hacer los cambios.
Para empezar a traducir, nos aseguraremos de estar logueados, y vamos al link "Inicio" en la esquina superior derecha.
Seleccionamos el proyecto (por ejemplo DHIS2) y hacemos click en el lenguaje que queremos traducir. El número de
palabras que necesitan traducción se mostrará bajo el campo "Resumen". Hacemos click en uno de los módulos (por
ejemplo dhis-2) y exploramos las carpetas para encontrar un módulo que necesita traducción (por ejemplo dhis-web>dhis-web-caseentry). Luego hacemos click en el texto de "Resumen" que pone algo como "194 words need attention".
Nos enlazará con la pareja clave/valor que requiere traducción.
73
Conceptos para la adaptación local
Herramienta DHIS2 i18n
En este caso, necesitamos traducir la frase "Por nombre" de inglés a español. Introducimos la traducción enla ventana
bajo la frase de referencia. Si no estamos seguros de que la traducción sea correcta o necesita revisión, podemos
marcarlo como "Fuzzy". Una vez que hayamos completado la traducción, presionamos en "Submit". El equipo de
desarrollo de DHIS2 incorporará entonces nuestras traducciones al código fuente de forma regular.
19.2. Herramienta DHIS2 i18n
1. Haremos click en "Explorar" cuando arranca la aplicación y seleccionamos la ruta a nuestra copia local del árbol
de código fuente de DHIS2 seguido de OK.
2. A continuación, seleccionamos la ubicación de destino donde guardaremos los strings traducidos.
3. Selecccionamos uno de los módulos del lado izquierdo para traducir, por ejemplo dhis-web-caseentry.
74
Conceptos para la adaptación local
Detalles a tener en mente
Una vez hemos seleccionado un módulo, haremos click en una clave concreta del panel izquierdo. El valor de
referencia de esa clave se mostrará en el panel del lado inferior derecho, y el valor de la traducción se mostrará en
el lado superior derecho. Si el valor no existe, simplemente añadiremos la traducción ahí mismo.
4. Cuando hemos terminado de traducir, nos aseguramos de pulsar el botón "Guardar".
19.3. Detalles a tener en mente
Hay ciertos strings como "yyyy-MM-dd" que se usan para el formato de fecha y hora en la aplicación. En general, no
deberían cambiarse, pero hay situaciones en que necesitamos adaptarlos localmente. Consultaremos este enlace para
más información.
No es necesario traducir un string del lenguaje original (inglés) si el string traducido es el mismo. Podemos dejarlo en
blanco. Por defecto, DHIS2 utilizará los valores en inglés para todos los strings que no han sido traducidos.
Todos los strings traducidos deben introducirse en formato UTF-8. Si estamos utilizando el portal de traducción, nos
aseguraremos de que la configuración del navegador están fijadas a UTF-8 al momento de traducir.
Algunas variables especiales (por ejemplo {0}) utilizan llaves. Esto significa que la variable se sustituye por un número
u otro valor en la aplicación. Deberemos ubicar la notación de esta variable en la posición correcta.
75
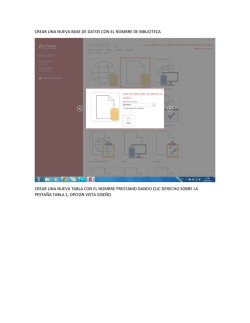
© Copyright 2026